
Most messaging systems claim they support redundancy, but it’s important to step back and consider the real requirements of high availability in your messaging system. If the switchover time is too long and unpredictable, does it still satisfy your high availability requirements?
Solace’s hardware has been designed with fully-integrated, tightly-coupled features for high availability and general networking robustness, such as redundant components, the automatic fail-over of paired devices, the isolation of control and data planes, and per-client queue management.
Traditional middleware products keep all of their state on disk, so in the event of a failure the standby broker must retrieve all state from disk before it can resume providing service. This can take minutes or tens of minutes depending on the amount of data stored. Solace uses a patented approach to maintain real-time state on both active and standby systems so activity switches happen in seconds rather than minutes.
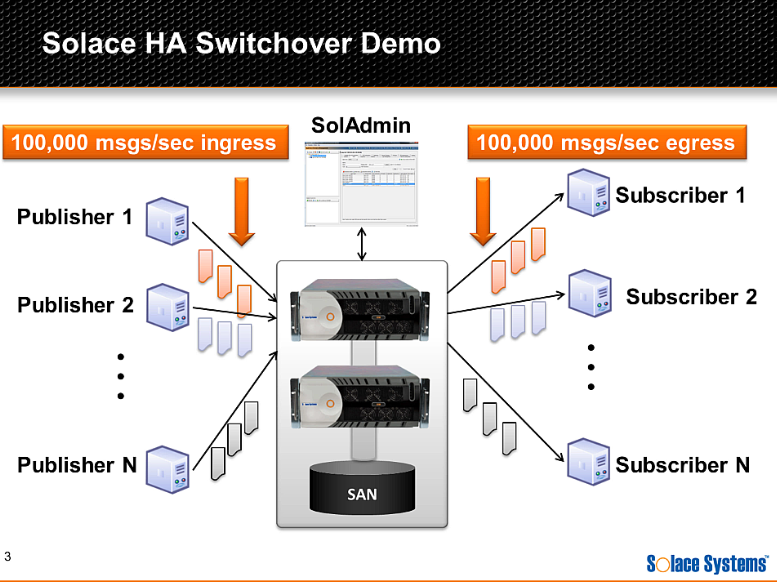 This video gives an introduction to the high availability (HA) functionality that’s baked in to every Solace appliance, shown in context of a guaranteed messaging implementation. My goal was to give viewers an understanding of the technical aspects that make up the HA feature, get into what differentiates Solace’s solution, and demonstrate how Solace’s appliance handles a failover with streaming clients sending a reasonably high rate of traffic through the appliance.
This video gives an introduction to the high availability (HA) functionality that’s baked in to every Solace appliance, shown in context of a guaranteed messaging implementation. My goal was to give viewers an understanding of the technical aspects that make up the HA feature, get into what differentiates Solace’s solution, and demonstrate how Solace’s appliance handles a failover with streaming clients sending a reasonably high rate of traffic through the appliance.
In the video I give a quick tour of the Solace HA configuration, and show the following:
- Setting up clients to send 100, 000 fully persistent messages per second
- Performing administrative activity switches
- Simulating a power failure of the primary appliance
For all scenarios I examine the actual outage time as measured by the clients, and demonstrate zero message loss. In summary, Solace provides full appliance redundancy within the datacenter by eliminating all potential single points of failure and enabling very fast failover.



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.
By submitting this form, you agree to Solace’s privacy policy: solace.com/privacy-policy/