
You’re out of control. I hate to be the bearer of bad news, but sometimes we need to hear the truth. You know Apache Kafka, you love Apache Kafka, but as your projects and architecture have evolved, it has left you in an uncomfortable situation. Despite its real-time streaming benefits, the lack of tooling for Kafka service discovery, a reliable audit tool, or a topology visualizer has led you to a place I call “Kafka Hell”. Let me explain how you got here in 4 simple, detrimental, and unfortunately unavoidable steps.
- You learned of the benefits of EDA and/or Apache Kafka.
Whether you came at it from a pure technology perspective, or because your users/customers demanded real-time access to data/insights, you recognized the benefits of being more real-time. - You had some small project implementation and success.
You identified a use case you thought events would work well for, figured out the sources of information, and the new modern applications to go with it. Happy days! - You reused your existing event streams.
Within your team, you made use of the one-to-many distribution pattern (publish/subscribe) and built more applications reusing existing streams. Sweetness! - You lost control.
Then other developers started building event-driven applications and mayhem ensued. You had so many topics, partitions, consumer groups, connectors – all good things, but then the questions started: What streams are available? Which group or application should be able to consume which streams? Who owns each stream? How do you visualize this complexity? It’s a mess, am I right?
History Repeats Itself
As we moved away from SOAP-based web services and REST became the predominant methodology for application interactions, there was a moment when many organizations faced the same challenges we face today with EDA and Apache Kafka.
Back then, SOA’s maturity brought about tooling which supported the ability to author, manage, and govern your SOAP/WSDL-based APIs. The tooling was generally categorized as “Service Registry and Repository.” The user experience sucked, but I bet you know that already!
Enter REST. Organizations which were/are technical pioneers quickly adopted the RESTful methodology; but since the tooling ecosystem was immature, they faced challenges as they moved from a handful of RESTful services to a multitude of them.
Sound like what we face with Kafka today?
The answer to the original problem was the emergence of the “API management” ecosystem. Led by Mulesoft, Apigee, and Axway, API management tools provided the following key capabilities:
- Runtime Gateway: A server that acts as an API front end. It receives API requests, enforces throttling and security policies, passes requests to the back-end service, and then passes the response back to the requester. The gateway can provide functionality to support authentication, authorization, security, audit, and regulatory compliance.
- API Authoring and Publishing tools: A collection of tools that API providers use to document and define APIs (for instance, using the OpenAPI or RAML specifications); generate API documentation, govern API usage through access and usage policies for APIs; test and debug the execution of APIs, including security testing and automated generation of tests and test suites; deploy APIs into production, staging, and quality assurance environments; and coordinate the overall API lifecycle.
- External/Developer Portal: A community site, typically branded by an API provider. It encapsulates information and functionality in a single convenient source for API users. This includes: documentation, tutorials, sample code, software development kits, and interactive API console and sandboxes for trials. A portal allows the ability to register to APIs and manage subscription keys (such as OAuth2, Client ID, and Client Secret) and obtain support from the API provider and user community. In addition, it provides the linkage into productivity tooling that enables developers to easily generate consistent clients and service implementations.
- Reporting and Analytics: Performing analysis of API usage and load, such as: overall hits, completed transactions, number of data objects returned, amount of compute time, other resources consumed, volume of data transferred, etc. The information gathered by the reporting and analytics functionality can be used by the API provider to optimize the API offering within an organization’s overall continuous improvement process and for defining software service-level agreements for APIs.
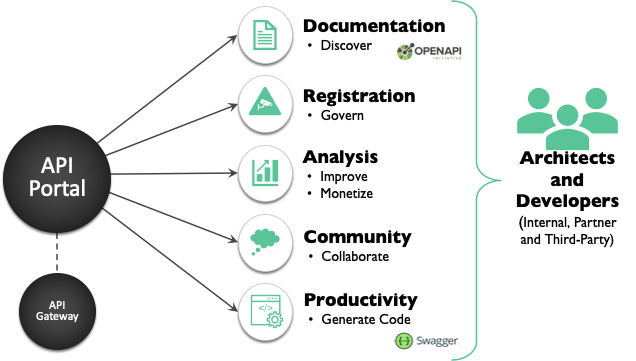
Without these functions, we would have had chaos. I truly believe the momentum behind RESTful APIs would have died a slow, agonizing death without a way to manage and govern the overwhelming quantity of APIs. This reality would have led to constantly breaking API clients, security leaks, loss of sensitive information, and interested parties generally flying blind with respect to existing services. It would have been a dark and gloomy time.
We Need to Manage and Govern Event Streams the Way We Do APIs
I bet if we all had a dollar for every time our parents said, “You need to grow up,” when we were younger, we would all be millionaires. But that is exactly what we need to do as it relates to event streams, whether you are using Apache Kafka, Confluent, MSK, or any other streaming technology. If we take our queues (no pun intended) from the success of API management – and the API-led movement in general – we have a long way to go in the asynchronous, event streaming space.
Over the last few years, I have poured a lot of my professional energy into working with organizations who have deployed Apache Kafka into production, and who I would consider to be technical leaders within their space. What I have heard time and time again is that the use of Apache Kafka has spread like wildfire to the point where they no longer know what they have, and the stream consumption patterns are nearly 1 to 1. This means that while data is being processed in real time (which is great), they are not getting a good return on their investment. A stream only being consumed once is literally a 1 to 1 exchange, but the real value of EDA lies in being able to easily reuse existing real-time data assets, and that can only be done if they are managed and governed appropriately.
Another common complaint about Apache Kafka is the inability to understand and visualize the way in which event streams are flowing. Choreographing the business processes and functions with Apache Kafka has become difficult without a topology visualizer. One architect described it as the “fog of war” – events are being fired everywhere, but nobody knows where they are going or what they are doing.
Events in large enterprises rarely originate from a Kafka-native application; they usually come from a variety of legacy applications (systems of record, old JEE apps, etc.) or from new, modern, IoT sensors and web apps. Thus, we need end-to-end visibility in order to properly understand the event-driven enterprise.
We need to adopt the methodology as described by the key capabilities of an API management platform, but for the Kafka event streaming paradigm. We already have the equivalent of the API Gateway which is your Kafka broker, but are sorely lacking stream authoring and publishing tools, external/developer portals, and the reporting and analytics capabilities found in API management solutions today. Ironically, I would claim the complexity and decoupling that you find in a large organization’s EDA/Kafka ecosystem is more complex and harder to manage than synchronous APIs which is why we need an “event management” capability now more than ever!

Technical Debt and the Need for Kafka Service Discovery
I hope by now you’ve bought into the idea that you need to govern and manage your Kafka event streams like you do your RESTful APIs. Your next question is most like likely, “Sounds great Jonathan, but I don’t know what I even have, and I surely don’t want to have to figure it out myself!” And to that, I say, “Preach!” I have walked in your shoes and recognize that technical documentation always gets out of date and is too often forgotten as an application continues to evolve. This is the technical debt problem that can spiral out of control as your use of EDA and Kafka grows over time.
So, that is exactly why it is a requirement to automate Kafka service discovery so you can introspect what topics, partitions, consumer groups, and connectors are configured so that you can begin down the road to managing them like you do for your other APIs. Without the ability to determine the reality (what’s going on in runtime is reality, whether you like it or not), you can document what you think you have but it will never be the source of truth you can depend on.
A reliable Kafka service discovery tool with the requirements I listed above will be that source of truth you need.
Once you have discovered what you have with a Kafka service discovery tool, you’ll need to find a way to keep it consistent as things inevitably change. There needs to be continuous probing to ensure that as the applications and architecture change, the documentation is kept up to date and continues to reflect the runtime reality. This means that on a periodic basis, the Kafka service discovery tool needs to be run in order to audit and find changes, enabling you to decide if the change was intended or not. This will ensure the Kafka event streams documentation (which applications are producing and consuming each event stream) and the schemas are always consistent.
Thus, the path to solving the technical debt dilemma and design consistency problem with Apache Kafka is a Kafka service discovery tool.
The Future of Kafka Service Discovery is here
I hope I’ve given you a little insight into why you are struggling to manage and understand your Kafka streams and what kind of tools the industry will need to solve these particular pain points. Recognizing the problem is the first step in solving it!
Solace has now developed the capabilities I outlined above, specifically for Kafka users: authoring, developer portal, metrics, service discovery, audit tool, etc in it’s event management solution: Event Portal for Apache Kafka. You can now manage and govern your Apache Kafka event streams like you do your APIs. And isn’t that exciting!
Get started with Event Portal for Apache Kafka with a 60-day free trial.




Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.
By submitting this form, you agree to Solace’s privacy policy: solace.com/privacy-policy/