Why You Need to Look Beyond Kafka for Operational Use Cases, Part 1: The Need for Filtering and In-Order Delivery
Preface Over the last few years Apache Kafka has taken the world of analytics by

Over the last few years Apache Kafka has taken the world of analytics by storm, because it’s very good at its intended purpose of aggregating massive amounts of log data and streaming it to analytics engines and big data repositories. This popularity has led many developers to also use Kafka for operational use cases which have very different characteristics, and for which other tools are better suited.
This is the fourth in a series of four blog posts in which I’ll explain the ways in which an advanced event broker, specifically PubSub+, is better for use cases that involve the systems that run your business. The first three covered the need for filtering and in-order delivery, the importance of flexible filtering, and the finer points of security. My goal is not to dissuade you from using Kafka for the analytics uses cases it was designed for, but to help you understand the ways in which PubSub+ is a better fit for operational use cases that require the flexible, robust and secure distribution of events across cloud, on-premises and IoT environments.
One of the main goals of making applications event-driven is allowing data to move more freely between them. Decoupling producers and consumers, i.e. letting them interact in an asynchronous manner, frees data from the constraints of synchronous point-to-point connections so it can be used by multiple applications in parallel, no matter where those applications are deployed.
As organizations adopt event-driven architecture, there naturally comes a question on the desired scope of an event. How can they prevent silos of events that limit their usefulness while maintaining some governance, or visibility, into the flow of data throughout the organization? This is where an event mesh comes in.
Gartner says an event mesh “provides optimization and governance for distributed event interactions. Event-driven computing is central to the continuous agility of digital business. The distributed optimized network of event brokers facilitated by the event mesh infrastructure aims to enable a continuous digital business native experience.”1
With that in mind, let’s look at the technologies Solace and Kafka use to implement an event mesh. First, we need to break down the above definitions into a set of components or features that we can compare: support for open standards, security, scalability through flexible subscriptions, governance, WAN optimization, and dynamic message routing.
Analyst firm Intellyx describes the role an event mesh plays as follows: “Event mesh plays a critical role as an IT architecture layer that routes events from where they are produced to where they need to be consumed – regardless of the system, cloud, or protocols involved.“2
Kafka’s answer to this list is event and event metadata replication using Apache MirrorMaker. MirrorMaker was developed as part of the Apache Kafka project to provide geo-replication between clusters. Other tools like Apache MirrorMaker2, Confluent Replicator and Linkedin Brooklin have evolved Kafka data replication to address shortcomings such as:
All these tools rely on point-to-point data replication so fall short of what is required to implement an easily manageable, intelligent event mesh across your enterprise.
Solace, on the other hand, was designed to be the foundation of an enterprise-wide event mesh for demanding use cases such as those found in capital markets, and has a full set of built-in features that address all of the requirements including the dynamic routing of events or static bridging of events between clusters. From early on, Solace has been bringing the types of dynamic routing features that make the internet work to the event layer of your enterprise. This enterprise wide, event routing capability with dynamic subscription propagation is what makes Solace’s solution truly an event mesh.
Below we will compare and contrast the technical details of these two approaches and apply each technology to a series of use cases, comparing functionality and ease of use.
Kafka’s replication model is a lot like database replication, i.e. based on reading the transaction log of a source database and replaying it to a destination database. The foundational technology is a process that reads from a source database and writes to a destination. Kafka does the same thing; the replication process reads from a remote cluster and publishes to a local cluster.
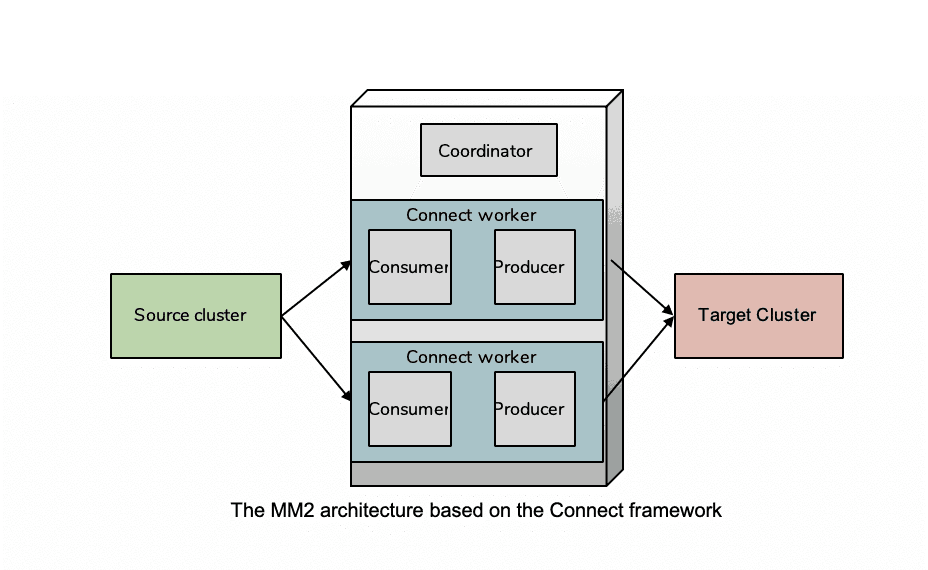
Reference: https://blog. cloudera. com/a-look-inside-kafka-mirrormaker-2/
This approach relies on configuration files that dictate which events are replicated between source and destination clusters, and has no real concept of meshed brokers, just a series of broker point-to-point links.
Solace’s dynamic message routing (DMR) capability takes an approach much more like IP routing which is more flexible, hierarchical and scalable than database replication. Solace consumer subscriptions are propagated across the routing control links to attract events across the data links. In this model there are no intermediary replication processes and no external configuration files that need to keep in sync with application needs – event brokers connect directly to each other. By simply adding subscriptions, applications can receive filtered events from anywhere in the event mesh no matter where they are produced.
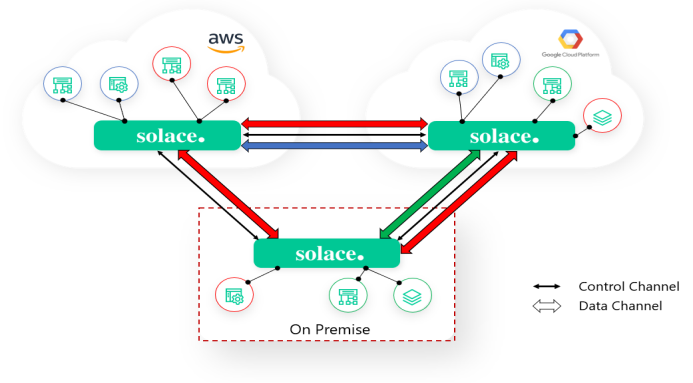
Reference: https://docs.solace.com/Overviews/DMR-Overview.htm
Kafka replication tools forward events between clusters based on static routes which are regex-based whitelists and blacklists. When replication tool providers mention “dynamic routes”, they are talking about being able to edit the whitelist or blacklist without restarting the replication tool, i. e. dynamically editing the static route lists, but manual configuration is still required. The effect of static routing is that data will be replicated to a remote cluster based on administratively set rules, not on the actual data needed within the remote cluster. Events matching the white list will be replicated, it does not matter if the end consumers have changed their subscription sets. Data might be replicated when it is no longer required at the remote site. Likewise, other data required might not be replicated if the white list is not kept up to date in real-time
The disadvantage is that there needs to be cross-functional coordination between the application teams and the replicator process administrator to ensure the correct data is being replicated from wherever it is being produced. It is difficult to tell if data is being replicated, which is an expensive function, but never consumed by any application. There is a place for static routes in simple topologies, for example hub and spoke topology where all events from a spoke event broker are sent to a single hub. These routes should be simple to implement and simple to understand.
Solace Dynamic Message Routing allows client subscriptions to be dynamically routed across the event mesh of Solace HA clusters. This is similar to IP routing and allows the injection of client subscriptions to determine if published events will be streamed to a remote HA cluster. So only the data that is required by the end consumers will be routed. If the consumers want additional events, the addition of new subscriptions locally will be propagated across the event mesh and attract events no matter where they are originally published. If the consumer no longer needs the events, they can remove their subscriptions and the removal will also be propagated throughout the brokers in the mesh.
This pruning back of subscriptions reduces the number of events flowing between clusters. This dynamic subscription propagation also supports message exchanges that require more dynamic event flows – such as request/reply, market data, gaming odds and some IoT event flow use cases. The dynamic nature of subscription propagation means there are no config files to keep in sync with client demands because the intelligent event mesh learns which subscribers are interested in what events and automatically propagates that throughout the event mesh. The advantage is that this allows the consumer demand to be the driver behind which events transit the event mesh.
Beyond the limitation of file-based static routes in Kafka defining which events are routed between clusters, Kafka’s coarse topics limit the ability to filter out the exact events needed per cluster and makes it very difficult to rebalance loads across clusters. There is no way in Kafka to replicate a subset of a Topic without adding data filtering applications to filter and re-publish – which have the disadvantages explained in my previous blog.
With Solace there are many different options on how to filter and route topics that are based on best practices. The fine-grained filtering allows filtering from application domain all the way down to ranges of event senders or event objects. Filtering might be location based or even object types. The point is with the event topic being descriptive of the event type and the event properties, any of these values can be used to make filtering decisions so only the events the consumer wants will be sent across to the remote cluster, and without the need to write, deploy and manage data filtering applications.
In order to keep events from looping between replicators, Kafka replication processes need to either prepend source cluster to the event topic (MirrorMaker2) or add additional headers (Confluent Replicator) to allow poison reverse blacklists so an event can’t be forwarded into a cluster from which it originated. In more complex topologies where events transit through an intermediary cluster, headers or prepended parts of the topic will be stacked. For example, for an event transiting clusters A -> B -> C, the record in C will have 2 provenance headers, one for B and one for A, or the topic will be: B. A. OriginalTopic. Depending on the replication tool it may be up to the consumer to deal with the modified topic.
Like IP routing, Solace’s dynamic message routing has a real set of routing protocols with rules on event streaming that would naturally prevent things like looping. These protocols understand mesh topologies and stream events from source cluster to destination cluster, and onward to the end consumer. This means producers and consumers see the event mesh as a truly single event streaming system and do not need to consider source and destination cluster impacts or limitations on topics. Consumers can influence where events stream within an event mesh by simply adding subscriptions in a new location and removing like subscriptions from an existing location.
With distribution events either based on a series of dispersed Kafka bridging configurations or with Solace dynamic message routing, it becomes difficult to understand exactly where events are being distributed. This visualization is a necessary step to gaining better data governance. Solace provides an event portal that offers this level of insight for both Solace and Kafka installations.
Cloud first for new applications
A common application modernization strategy is to cap expansion of applications in private datacenters and look at new applications or use cases as candidates to lead the move to public cloud infrastructure. This strategy typically leads to the requirement for hybrid cloud event distribution as the new cloud-based applications will likely need some of the resources or data presently used by existing on-premise applications and systems of record. In modern event driven systems, events are used and re-used across several applications and are not stove-piped to specific applications or use-cases.
Let’s build on the example I started using in my last blog post and show how to extend the architecture by adding new use cases in a cloud-first manner.
In this scenario, a large online retailer generates a raw feed of product order events that carry relevant information about each order through statuses New, Reserved, Paid, and Shipped, and that data is accessible so developers can build downstream applications and services that tap into it.
The architecture looks like this:
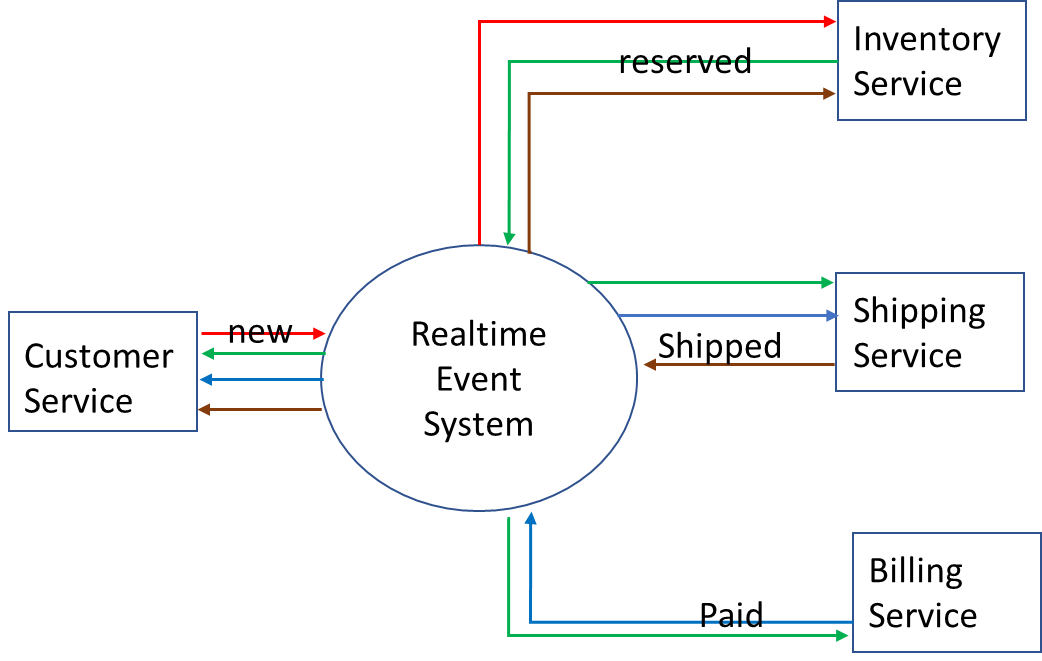
Now that this system is implemented we want to extend the data use by the following new cloud apps:
What this would look like from an architectural point of view:

As you have seen from my flexible topic blog, the topic structure for such a case would look like this:
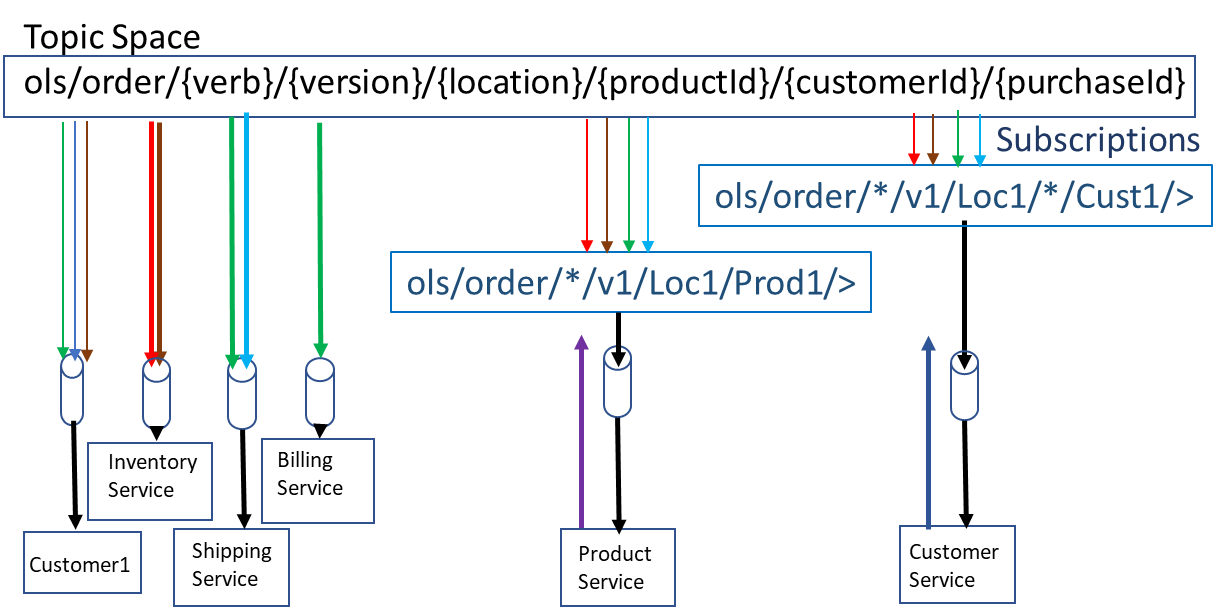
The public-cloud based services would add the subscriptions for the explicit customers or products that need to be analysed. This would allow for only the exact data required to be automatically drawn across the WAN and into the public cloud without needing to know where the publisher is. Also, it is very easy to have access controls to prevent certain products or customer info published across the WAN link. Any results could be published back on a new topic: ols/analysis/{verb}/{version}/{location}/{productId}/{customerId}.
Let’s look at how this would be implemented and maintained during the life cycle of the applications.
Solace dynamic message routing is freely bundled into the Solace PubSub+ Event Broker. Dynamic message routing needs to be configured once when setting up the inter-broker connections to form an event mesh, this video describes how this is done. There is simple configuration in one place to ensure the WAN links are secure and compressed. ACLs that would apply to who can produce which events and who can consume which events would remain the same. The ACLs would however have to be applied to the brokers where the producers and consumers connect.
From this point as each application subscribes to exactly the events it requires the events are transmitted over the WAN and delivered to them securely, in published order, without loss. There is no topic remapping as loop prevention is done for all topologies. This means the application would subscribe exactly as it would if it was in a shared datacenter.
As applications evolve, they can change subscriptions to attract more or fewer events as required. There is no intermediary application that needs to be kept in sync. The filtering and WAN transmission is done directly on the broker.
As new applications come online and add their own subscriptions. If they require the same events that are required by existing applications connected to this broker, then a single copy of the data will be sent across the WAN then fanned out locally. Inversely, any results sent back from cloud-based application will also be a single copy across the WAN which will minimize cloud egress costs.
The cloud-based applications can publish results for consumption anywhere in the event mesh as dynamic message routing is inherently bi-directional.
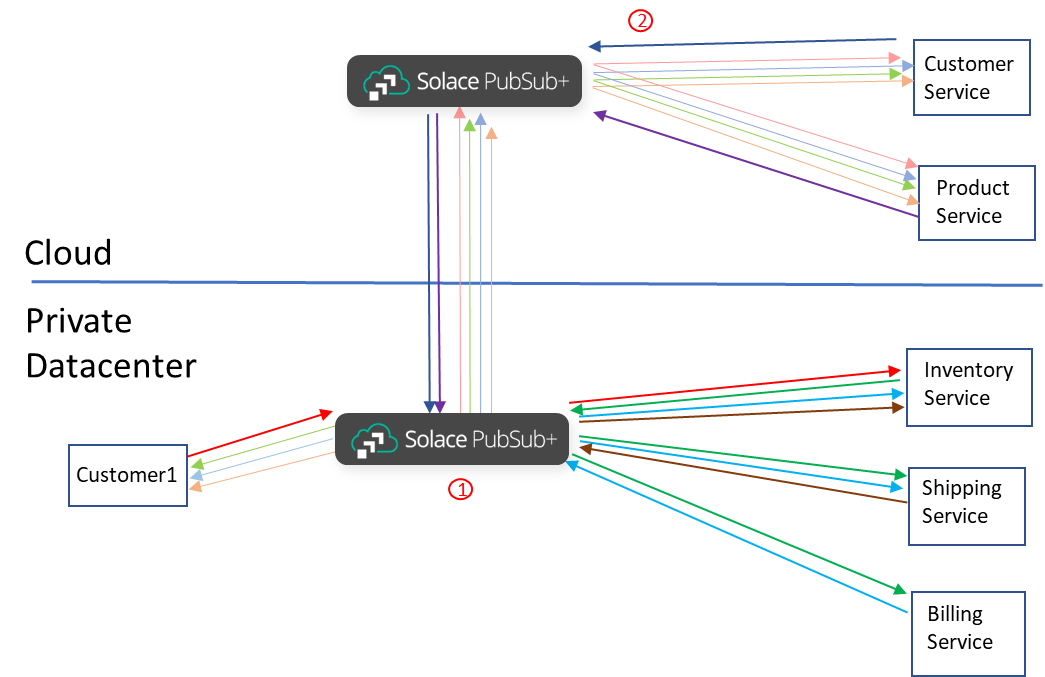
There are two major steps or components.
At this point we have simply expanded a solution that was in a private data center into one that has a single public cloud extension to allow things like burst absorption. But this could lead to new requirements that would require multi-cloud or multiple private site distribution of events to do things like move the customer connection point closer to the customers geo-location. This has been a growing trend; “93 percent of enterprises have a multi-cloud strategy; 87 percent have a hybrid cloud strategy” from the Flexera 2020 State of the Cloud Report.
As the complexity of the overall topology increases, the simplicity of the Solace solution really begins to show increased advantages.
In this example we split where the new Product Service application is running and added a third site that handles surge in customer connections.
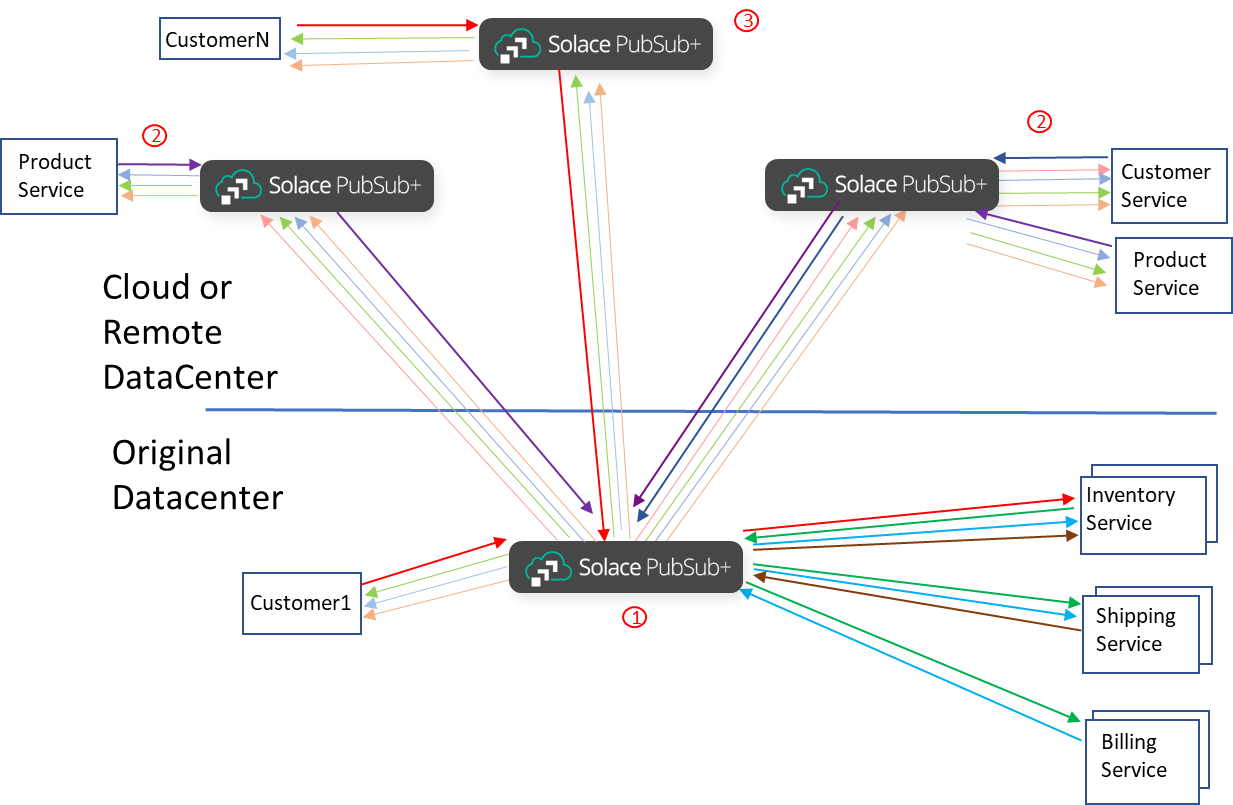
There are now three major steps or components.
As seen in the filtering blog post, the options are to send the entire contents of all required coarse topics to the remote cloud for the newly added cloud-based services and have them filter out the data they do not need or have a data filtering application in the source cluster work as an intermediary.
Having all data sent to the new cloud application may not be feasible for security reasons, but even if it is possible complete data replication would cause larger then needed WAN costs and requirements to over provision the cloud Kafka cluster compared to the actual requirements. This over provision might increase the cloud provider costs up to the point where the costs out-weigh the benefits of moving to the cloud in the first place.
Alternatively, data filtering applications could do additional filtering and re-publish required data onto new topics. But the data-filtering pattern does have it’s own issues. As the republished data needs to be sent on new topics it causes a multiplier in the number of topics and partitions needed, which degrades Kafka broker performance. Next the problem is that this data-filtering pattern adds operational complexity to the overall solution, chain dependencies and is detrimental to application agility. Finally, creating a new stream as a subset of the original stream to compensate for lack of filtering increases data management complexity, creates “golden source of truth” issues and can reduce reuse. More is not always better.
Taking the diagram that showed data-filtering solution for my filtering blog post (below), let’s look at how this would be implemented and maintained during the life cycle on the applications.
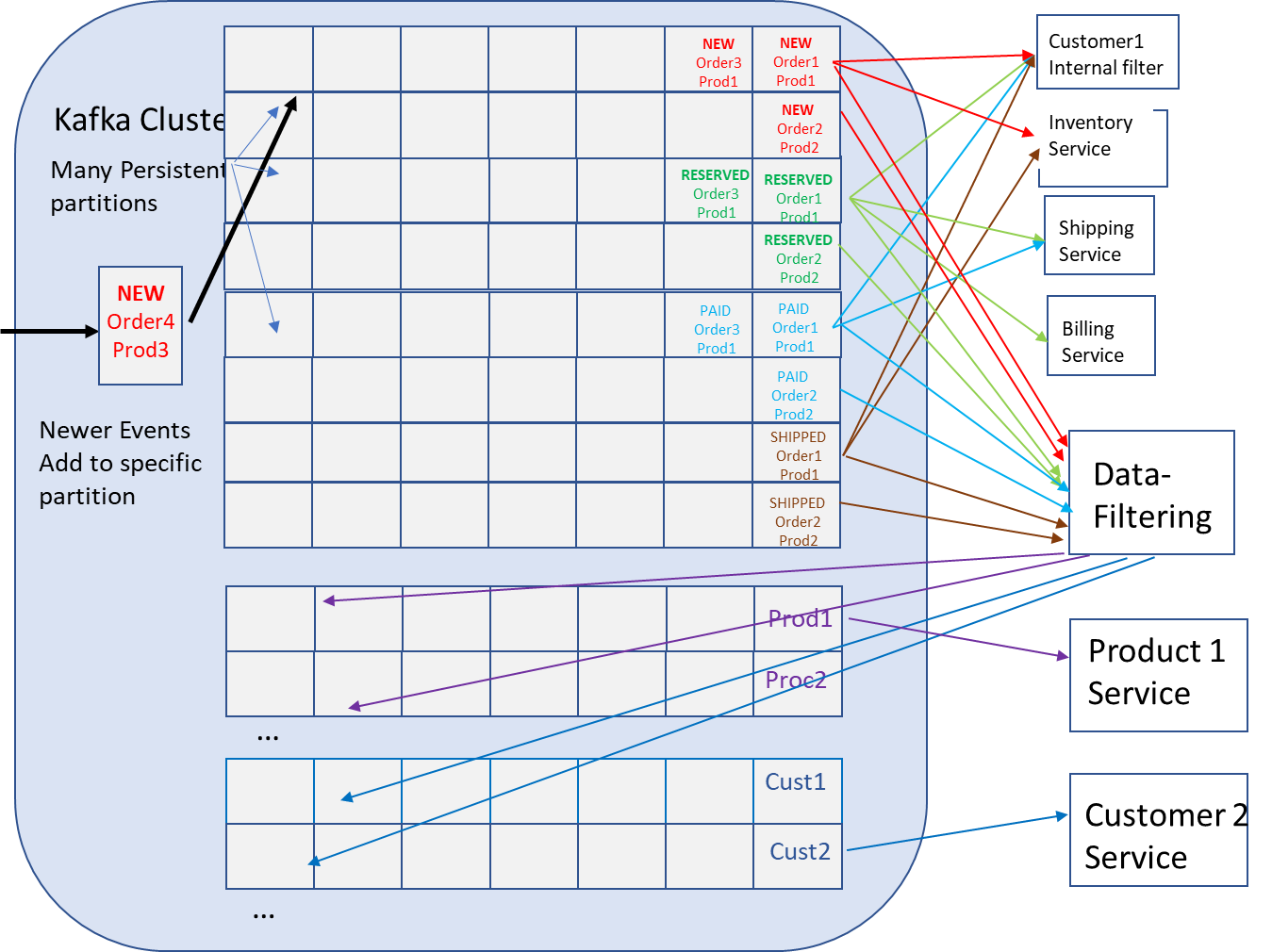
Mirror Maker 2 or some other Kafka data replication tool will need to be installed, configured and engineered for performance. It will also have to be maintained to ensure white and blacklists are correct based on what applications are deployed where and what events they need from where.
Data-filtering service may need to be built, deployed and managed to ensure correct filtering is done. This might require security policy related filtering to ensure only the correct data is re-published to the cloud. A decision on whether to replicate or filter would need to be determined for each new application.
Applications and white-list/black-list will have to be updated to handle any topic prefixing or manipulations the Mirror Maker2 imposes to prevent looping of events. The tools used to coordinate, communicate and track this for deployment workflows would likely need to be developed.
As applications evolve, source publishers, data-filtering applications and end applications need to be coordinated to use data. As the original publisher enriches its data what happens on all the data-filter applications, do they need to be enhanced as well? What happens when the downstream applications need a change to the data they receive? They cannot simply add a new subscription they need to figure out if they now need new source data, enhanced republished data or a new data-filter republished. Likewise, simply removing a subscription will not prune back the data flow. This shows how much the data-filtering pattern causes chain dependencies and is detrimental to application agility.
As new applications are added to the cloud platform and new attempts to reuse data that exists, the cycle of determining if all events from a topic need to be sent to the cloud applications then filter in the application or if data-filtering is required before WAN transmission continues. Keep in mind, as discussed in the filtering and in order blog post the requirement to keep order across events means that all the related events need to be in the same Topic/Partition. This could cause a large amount of data being published across the WAN even if it is not all required. The additional data-filtering does have its challenges and can cause duplicate copies of events. Let’s say one application needs all data published for product1 which is republished to topic “product1”, and another application needs all data published related to consumer2 which is republished to topic “consumer2”. Any data that is related to both product1 and consumer2 would be republished to both topics and sent multiple times across the WAN.
Any results that need to be published back would require yet another managed cluster of MirrorMaker2 on the local datacenter.
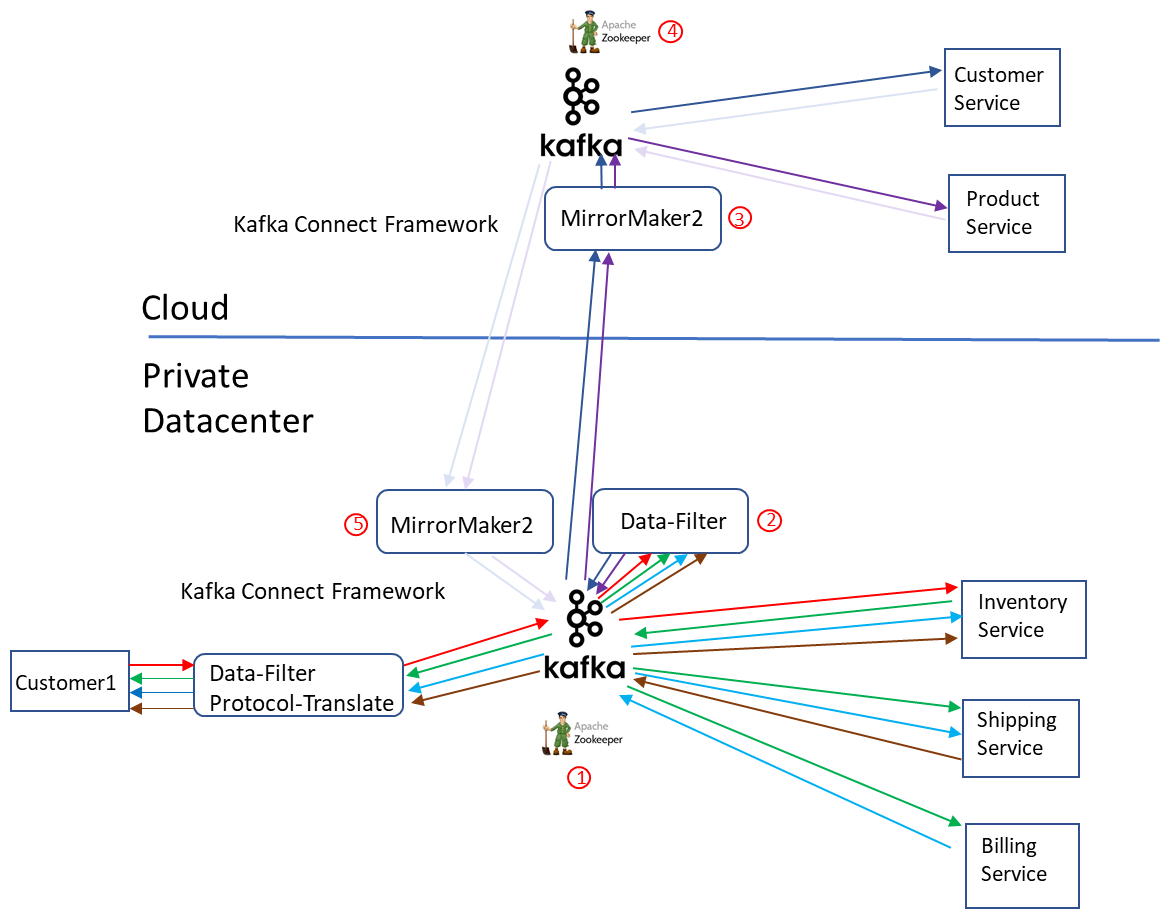
There are five major steps or components:
Again, we are going to expand past simple point-to-point pairing of Kafka clusters into a larger topology. Moving the Product Service application into multiple locations and adding surge capacity for Consumer connections.
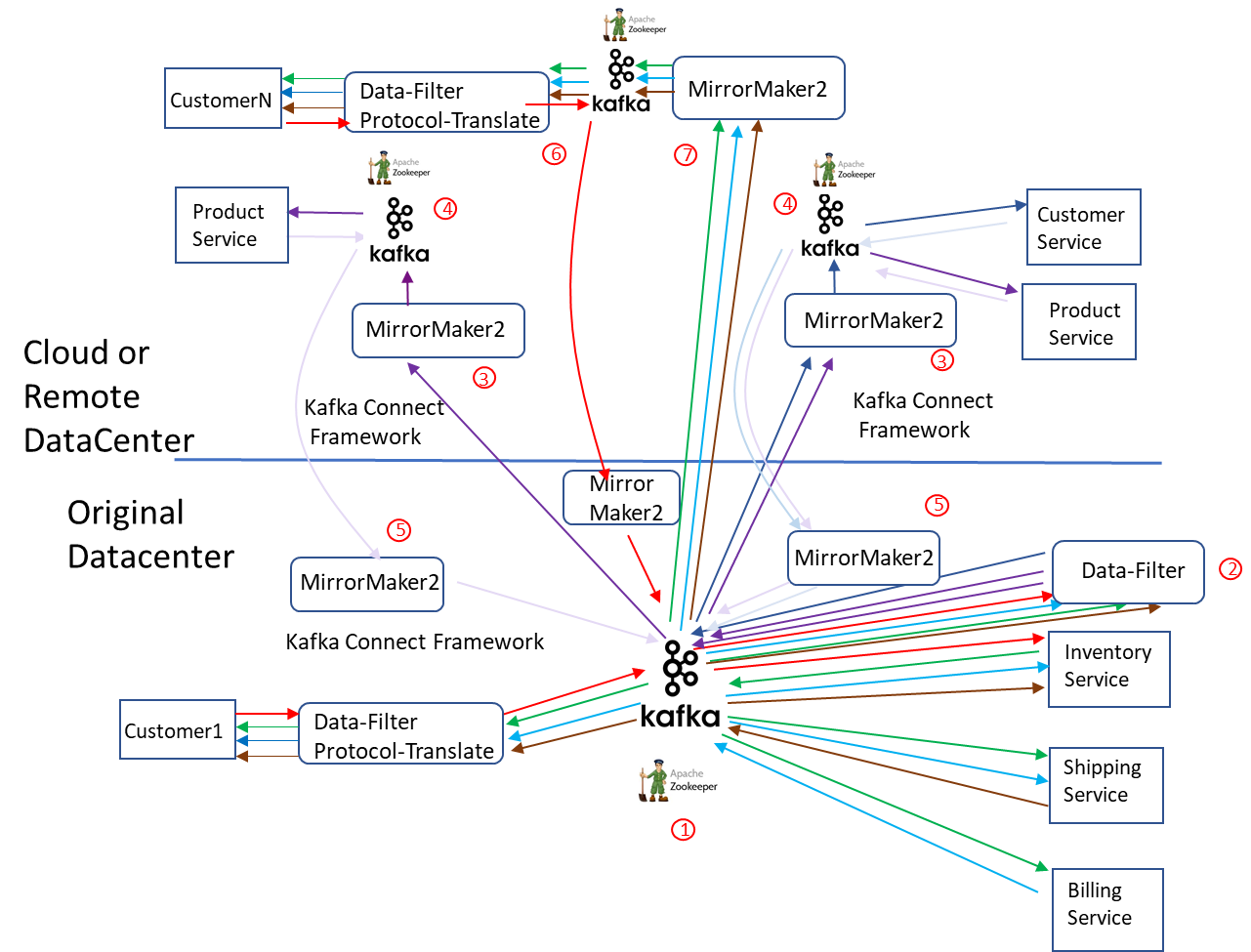
There are now seven major steps or components.
Though this current blog focuses on cloud migration, geo proximity data deployment after analytics, there are several other reasons that replication is required for Kafka clusters, this Cloudera blog lists a few more.
Isolation or Legal and Compliance: The general idea is there may be a need to physically separate a group of consumers from sensitive data, but some amount of data is needed in the more secure and less secure clusters and therefore replicated occurs with tight policies to control what data is replicated. Solace has more fine grain policy controls on data access and also has VPN namespace like separation that allow fencing of data within the broker.
Disaster Recovery: One of the most common enterprise use cases for cross-cluster replication is for guaranteeing business continuity in the presence of cluster or data center-wide outages. This would require application and the producers and consumers of the Kafka cluster to failover to the replica cluster. Though not discussed in this blog because of the complexity of the subject, I may write a disaster recovery blog in the future.
No matter what technology you use to build distributed event interactions, the fundamental requirement to efficiently stream data to where it is required in a form it can be consumed is a difficult problem to solve without a toolset to design, create, discover, catalog, share, visualize, secure and manage all the events in your enterprise. “The top challenge in cloud migration is understanding application dependencies” Flexera: 2020 State of the Cloud Report. This obviously includes access to the data the application requires and is why the advent of the event mesh has led Solace to build an event portal to solve the problem of optimizing event re-use. The product, called PubSub+ Event Portal, fosters the re-use of events by making them discoverable and visible while ensuring good data governance across the enterprise even as the Event distribution grows and the topologies become more complex.
A simple “replicate everything” approach might economically satisfy all event distribution requirements moving forward, but if not then a better solution is leaving the problem of event distribution to individual application teams. Applications will work around inflexible event distribution by replicating and republishing data. This leads to waste of resources, frail and complex eventing systems and data lineage/management complexities so it is important to understand your event distribution requirements.
An event mesh is optimized to limit the consumption of network resources while offering the most flexible solution to foster agile application development and deployment. The goal is to let producers and consumers connect anywhere in the event mesh and produce and consume the entitled data they require.
As applications move to distributed event interactions, policies and management tools will be required to allow application teams to discover and understand the events they need to produce and consume in order to fulfill their distributed functions.
1 Source: Gartner “The Key Trends in PaaS and Platform Architecture”, 28 February 2019, Yefim Natis, Fabrizio Biscotti, Massimo Pezzini, Paul Vincent
2Source: Intellyx “Event Mesh: Event-driven Architecture (EDA) for the Real-time Enterprise”, Nov 2019, Jason



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.
By submitting this form, you agree to Solace’s privacy policy: solace.com/privacy-policy/