 Chris Wolski
Chris WolskiLire le communiqué de presse en
Si vous envisagez d’établir une connectivité en temps réel entre vos clusters Kafka et le reste de votre entreprise, y compris vos applications opérationnelles, appareils IoT, services cloud et anciens systèmes, alors cet article de blog s’adresse à vous.
Un nombre croissant d’entreprises avec lesquelles nous travaillons cherchent à mettre en place une connectivité en temps réel entre leurs clusters Kafka et leurs applications ainsi que leurs systèmes ne dépendant pas de Kafka. En les aidant à atteindre leur objectif, nous avons remarqué qu’elles se confrontaient à ces 6 difficultés :
- Déployer dans le hybrid cloud, c’est-à-dire connecter des clusters Kafka provenant du Cloud à des applications sur site.
- Fournir une connectivité en temps réel entre des clusters en back-end et des applications edge et appareils dans les magasins, entrepôts, centres de distribution, navires, usines, exploitations minières, etc.
- Diffuser des données à partir de millions d’appareils/véhicules vers des clusters Kafka en vue de les analyser, tout en fournissant un chemin d’accès de commande et de contrôle vers les appareils.
- Filtrer les flux de données Kafka tout en préservant l’ordre (bien souvent essentiel pour les micro services et les systèmes transactionnels) sans les frais liés à l’utilisation de KSQL.
- Connecter et répliquer des données/événements entre les différentes versions spécifiques de Kafka (Apache Kafka open source, Confluent, Amazon MSK, etc.) exécutées dans des environnements décentralisés.
- Normaliser des outils et mettre en œuvre des bonnes pratiques pour la gestion et la gouvernance des flux d’événements Kafka et non Kafka.
La solution à ces défis réside dans une nouvelle solution digitale capitale appelée « Kafka mesh » : il s’agit d’un maillage d’événements (également appelé Event Mesh) destiné à connecter les déploiements Kafka avec le reste de votre entreprise. Pour en savoir plus, je me suis entretenu avec Sumeet Puri, directeur solutions et technologies, pour connaître son avis sur le maillage Kafka (Kafka Mesh) et la manière dont les entreprises peuvent s’en servir pour surmonter les six difficultés qu’elles rencontrent lorsqu’elles connectent leurs déploiements Kafka au reste de leurs opérations. Vous pouvez également regarder la vidéo ci-dessous pour entendre le point de vue de Sumeet sur Kafka Mesh.
Chris Wolski : Qu’est-ce que le Kafka Mesh ?
Sumeet Puri : Un Kafka Mesh est un moyen efficace de permettre une connectivité en temps réel entre des déploiements Kafka et n’importe quel élément de votre entreprise. Les entreprises avec lesquelles nous travaillons possèdent et utilisent une grande variété de technologies de l’information (IT) et d’exploitation (OT) décentralisées, récentes ou anciennes. Il peut s’agir d’appareils MQTT, de terminaux REST, de MQs, d’iPaaS, d’ESBs et de toute une panoplie de déploiements Kafka. Dans certains cas, les clients exécutent aussi différentes versions de Kafka, comme Apache Kafka, Amazon MSK et Azure Event Hubs. Ainsi, un maillage Kafka permet de connecter et de diffuser efficacement les données entre toutes ces technologies.
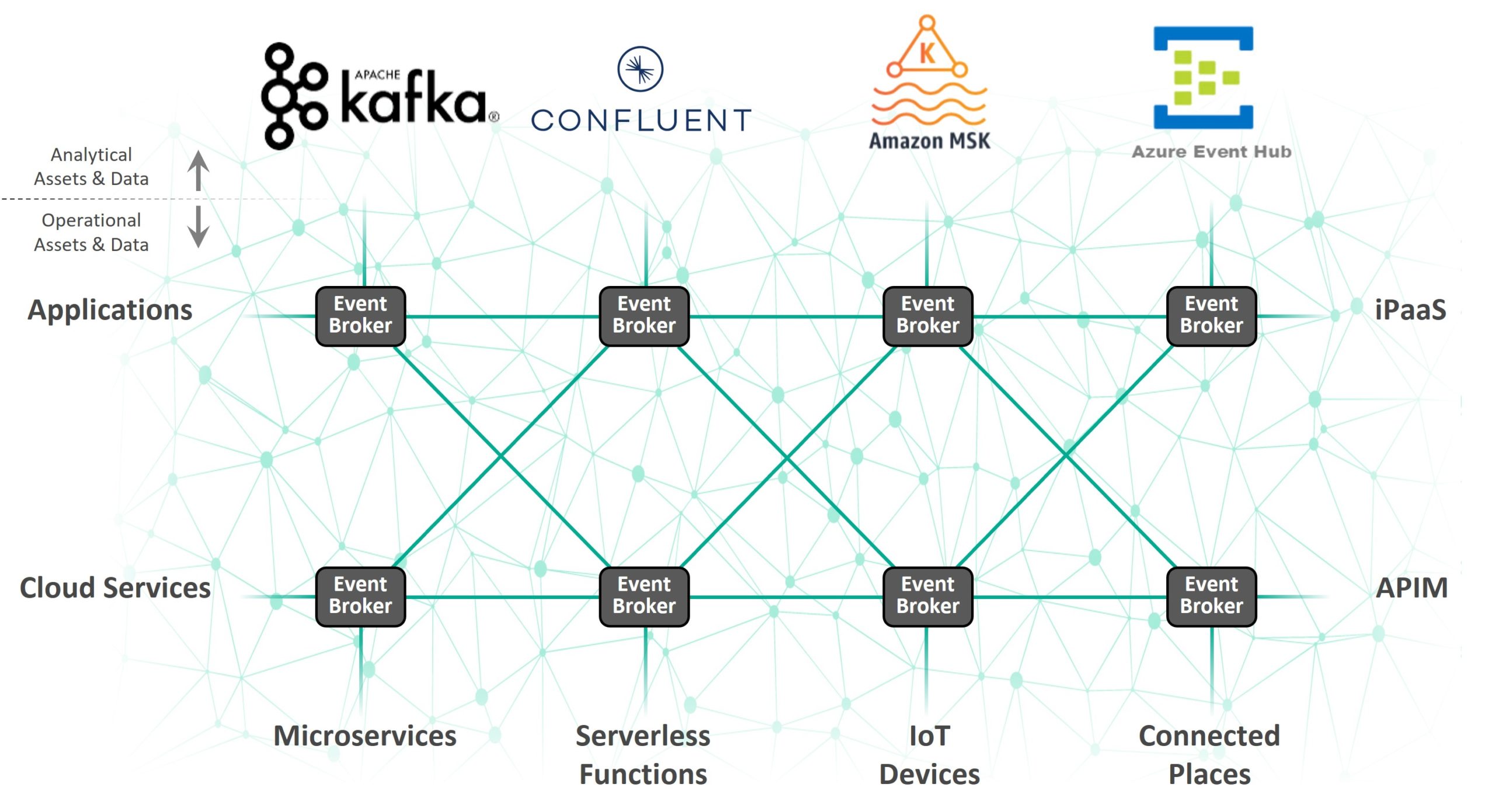
En ce qui concerne sa conception et son exécution, il vous suffit de déployer des brokers d’événements dans les environnements vers lesquels vous souhaitez diffuser des événements et où vous souhaitez en recevoir, puis de connecter ces brokers pour créer un maillage d’événements (Event Mesh), qui correspond à un réseau de brokers d’événements intelligents. Alors, différentes équipes en charge des applications peuvent connecter leurs applications/clusters Kafka à un broker local pour bénéficier d’une connectivité en temps réel avec tous les autres éléments reliés au maillage. Pour résumer, tous vos déploiements Kafka sont reliés par l’intermédiaire de brokers grâce à ce maillage.
Chris Wolski : Avez-vous des exemples de scénarios ou cas pratiques que le maillage Kafka permet de résoudre ?
Sumeet Puri : La solution Kafka a été conçue pour l’analyse et recherche d’événements, donc il faut que les systèmes transactionnels fournissent ces événements. C’est exactement ce à quoi sert le Kafka Mesh. Par exemple :
- Pour la gestion des commandes et des stocks, vous avez tout intérêt à ce que le temps de votre employé soit optimisé. Vous ne voulez pas que le personnel de votre entrepôt se tourne les pouces en attendant que les camions soient déchargés et vous ne voulez pas non plus qu’un client qui cherche à effectuer un achat soit forcé de regarder une icône tourner en attendant la confirmation de disponibilité d’un produit. Si vous vous reposez entièrement sur vos systèmes opérationnels, c’est-à-dire l’état actuel des choses, vous ne pouvez pas tirer profit de la capacité qu’ont vos systèmes analytiques à fournir des informations qui vous permettent d’intégrer la prédiction et les tendances à vos opérations.
- Le traitement des paiements dans lequel vous avez des paiements qui sont initiés, validés, traités et affichés sur des microservices, MQs, APIs et la libération de la dernière ligne droite vers Kafka pour l’analyse.
- La gestion des données principales, pour laquelle vous avez besoin que les données soient transmises à l’ensemble des systèmes et secteurs d’activité afin que les systèmes soient actualisés en temps réel, tandis que les clusters Kafka reçoivent également des copies de ces flux pour l’approvisionnement en événements.
- Les capteurs IoT transmettent d’importants flux d’événements de l’edge, d’un système central ou du cloud, vers des systèmes métier tels que SAP, et Kafka qui obtient une copie de ces flux pour les traiter et ingérer des Data Lakes.
- La relecture à partir du Kafka Event Store vers des systèmes transactionnels ou d’autres clusters Kafka sur différents sites : le cluster Kafka transmet le flux d’événements de relecture vers le maillage, qui le distribue de manière optimale à partir du cloud vers le edge puis sur site.
Ces exemples font partie des scénarios en temps réel, opérationnels et orientés clients que les entreprises peuvent résoudre grâce au Kafka Mesh.
Chris Wolski : Vous décrivez le maillage d’événements comme un réseau de brokers d’événements « intelligents ». Pouvez-vous nous expliquer ce que cela signifie ?
Sumeet Puri : Tout d’abord, lorsque je parle de « brokers d’événements intelligents », je parle de brokers qui prennent en charge les protocoles publication/souscription, de transmission garantie et des différents protocoles basés sur des normes comme REST, AMQP, MQTT et JMS construits en réseau, pour parcourir le WAN de manière intelligente. Des brokers qui peuvent être facilement connectés et capables d’acheminer des événements de manière dynamique entre ceux qui produisent les événements et les abonnés dans les systèmes décentralisés. Il existe donc une intelligence créée dans le réseau, dans le maillage d’événements. Cette intelligence repose sur les brokers du réseau qui partagent une technologie fondamentale ainsi qu’un registre de topics et d’inscriptions communs. Par exemple, lorsqu’une souscription d’événement ou un nouvel événement est enregistré par l’un des brokers, tous les brokers du système sont automatiquement alertés afin de travailler ensemble pour acheminer dynamiquement ces événements dans le maillage, à mesure qu’ils se produisent.
Chris Wolski : Pourquoi n’est-il pas possible de créer un maillage d’événements avec les brokers d’Apache Kafka ?
Sumeet Puri : Les brokers d’Apache Kafka et autres brokers open-source ne possèdent pas les mêmes fonctionnalités et la même intelligence. Ils ont été conçus pour servir de registres décentralisés, c’est-à-dire qu’ils sont fortement orientés systèmes de fichiers plutôt que réseau. Il s’agit d’une différence d’architecture subtile, mais significative.
Plus important encore, ces brokers ne prennent pas en charge nativement les différents protocoles et différents APIs dont vous aurez besoin pour créer le maillage d’événements. Il s’agit d’un point critique pour transmettre les événements entre les différentes technologies de l’information et d’exploitation que vous possédez dans votre système. Kafka ne prend pas en charge les topics contenant des caractères génériques : chaque topic est fixe, il est donc impossible d’avoir recours à l’apprentissage dynamique des flux d’événements filtrés sur les sites en utilisant l’architecture de topics et de partitions de Kafka. Enfin, ces outils n’offrent pas une grande performance, robustesse, fiabilité et sécurité de qualité professionnelle. Ainsi, si vous en utilisez un, vous devrez prendre en compte le temps et les efforts que l’ajout de toutes ces capacités à votre système vous demandera.
Chris Wolski : Qu’en est-il des outils de réplication des données comme MirrorMaker d’Apache Kafka ? Est-ce comparable au Kafka Mesh dont nous parlons ?
Sumeet Puri : L’outil MirrorMaker d’Apache Kafka permet de répliquer des données entre les clusters Kafka. Il implique un processus laborieux, bien souvent manuel et ne représente en aucun cas une solution permettant de faciliter la connexion et la transmission de données en temps réel entre les clusters Kafka et les autres applications/services/appareils à l’échelle de votre entreprise. Il n’est ni dynamique en termes de topics, ni filtré ou optimisé pour le WAN. Pour faire simple, exécuter des clusters Kafka dans les ateliers, en magasin, etc., n’a rien de pratique. Vous ne pouvez donc pas utiliser Kafka en tant que principal maillage d’événements.
En raison de ces faiblesses architecturales intrinsèques à l’envoi de registres, Kafka a repensé plusieurs fois la réplication : Confluent, Replicator, MirrorMaker (1.0 et 2.0), uReplicator d’Uber, pour n’en citer que quelques exemples. Un Kafka Mesh est une approche par mise en réseau de l’intégration de clusters Kafka et de facilitation de l’intégration en temps réel de ressources Kafka et non Kafka sur tous les sites.
Chris Wolski : Lorsque l’on parle de la gestion de Kafka, Confluent est toujours le sujet tabou. En quoi un Kafka Mesh peut-il rendre service aux utilisateurs de Confluent ?
Sumeet Puri : Confluent est la solution Kafka la plus aboutie (et la plus onéreuse) sur le marché. Confluent comprend Kafka Connectors et Replicator, mais son approche architecturale ne ressemble pas à celle d’un maillage d’événements, dans lequel des topics sont identifiés et appliqués de manière dynamique. En faisant appel à un Kafka Mesh, lorsqu’un consumer se connecte et s’abonne à un topic, l’intégralité du maillage le prend automatiquement en compte, sans qu’une configuration ne soit nécessaire.
En outre, le Kafka Mesh prend en charge le edge fanout. Cela signifie qu’une copie unique d’un événement sera diffusée du site source vers sa destination par le biais d’un lien WAN, même si plusieurs consommateurs se trouvent à l’autre bout. Tout cela devient d’autant plus intéressant avec les distributions de Kafka qui ne dépendent pas de Confluent. Par exemple, imaginons que l’événement source se situe sur un cluster Confluent sur site mais que la destination est sur AWS avec Lambda, MSK et Kinesis demandant tous le même événement. Alors le Kafka Mesh enverra à AWS une copie unique des événements à partir du cluster source, qui se déploiera ensuite vers tous ces consommateurs présents sur AWS.
Il est également utile de mentionner que le Kafka Mesh s’appuie sur des abonnements à des topics qui contiennent des caractères génériques et sur le WAN qui plus est. En soi, Kafka ne prend pas en charge les topics contenant des caractères génériques. Vous avez besoin du KSQL pour le filtrage, ce qui ajoute une couche supplémentaire et un véritable cauchemar en termes de sécurité, à mesure que vous allez recevoir des événements et rejeter ceux dont vous n’avez pas besoin. Imaginez si vous pouviez vous abonner à « orders/> » pour recevoir toutes les commandes ou « orders/*/us/> » pour recevoir toutes les commandes des États-Unis. Le Kafka Mesh vous fournira un flux filtré sur le WAN. La liste d’avantages est longue, qu’il s’agisse d’ACLs (Access Control List) de topics détaillés ou de l’optimisation WAN.
Chris Wolski : De quelles fonctionnalités avez-vous besoin pour construire un Kafka Mesh ?
Sumeet Puri : Plus fondamentalement, vous devez bénéficier d’une connectivité en temps réel entre différentes versions spécifiques de Kafka qui sont exécutées dans différents environnements, ainsi que de la capacité à connecter vos clusters Kafka à des terminaux REST, des files d’attente de messages, des environnements iPaaS, des appareils MQTT et autres. Vous avez besoin de topics complexes qui prennent en charge les caractères génériques afin que vous puissiez effectuer un filtrage précis et attribuer un accès en fonction du rôle sur un réseau multisite, avec un edge fanout. Il faut également un système capable d’acheminer automatiquement les événements, de sorte que vous n’ayez pas à passer des heures à programmer le routage d’événements.
Chris Wolski : Comment s’y retrouver avec un Kafka Mesh ? C’est-à-dire, comment gérer et gouverner tous les événements qui le traversent ?
Sumeet Puri : Tout comme un portail API permet aux utilisateurs de cataloguer et gouverner des APIs, un portail d’événements vous permet de faire la même chose avec vos événements. C’est donc une très bonne corde à ajouter à son arc lorsqu’on utilise un maillage d’événements ou un Kafka Mesh. Le portail d’événements doit pouvoir scanner et identifier des brokers d’événements Kafka et non Kafka, ainsi que créer des listes de topics, producers, consumers et schémas afin que de nouveaux producers et consumers puissent connaître ce qui circule dans le maillage. Dans ces conditions, un portail d’événements saura créer une représentation visuelle des flux d’événements, c’est-à-dire montrer quels topics passent par quels producers et consumers. Ainsi, il est plus facile de comprendre les flux d’événements en vue d’analyser et gérer les dépendances lorsque des modifications sont apportées.
Le futur des APIs ne se limitera pas aux requêtes et réponses, et un portail d’événements vous permet de monétiser vos événements Kafka et non Kafka par le biais de produits API d’événements. La donnée devenant un produit, les données en temps réel prendront le statut de flux d’événements et les produits API d’événements seraient le mécanisme permettant d’y parvenir avec des normes comme AsyncAPI. Tout cela est possible grâce à un portail d’événements et un Kafka Mesh.
Conclusion
J’espère que cet entretien avec Sumeet Puri vous a permis de comprendre la nature, les avantages et les exigences d’un Kafka Mresh. Pour en savoir plus sur la manière dont la plateforme PubSub+ peut améliorer et compléter vos déploiements Kafka, lisez cette série d’articles en commençant par Pourquoi ne faut-il pas se contenter de Kafka pour les cas d’utilisation opérationnels ?
