There’s quite a bit of buzz about change data capture (CDC) these days! I have been in numerous client meetings where CDC has come up lately, way more than before. So, what is CDC, why might you be interested in it, and what does it have to do with event-driven architecture? I’ll explain!
Introducing Change Data Capture (CDC)
A popular use case for CDC is replicating databases across datacenters. This is becoming increasingly common as companies look to adopt cloud and a hybrid-cloud environment. In this way CDC is closely linked to event-driven architecture (EDA) which is why CDC is becoming more common as businesses realize the importance of event-enabling their architecture to meet customer demand and improve overall customer experience with EDA. It is in their interest to ensure data is captured, analyzed, and acted upon in real-time. Gone are the days of batch processing where valuable data would sit for hours or days and lose its value over time. In this brave new world, data is analyzed in real-time while it is most valuable. A flight passenger has no use for an alert notifying them of a flight delay 5 hours later.
Coming back to CDC: It is a design pattern used to identify changes in data so that actions can be taken on those changes in real time. Databases are everywhere and we are all used to storing plenty of data in databases where it rests. We frequently query this data as well as watch it change over time. Records get inserted, deleted and updated. And while the new information provides very valuable information, there is additional value in tracking changes to these database objects in real-time.
Imagine a Customers table which tracks all of the active customers who are currently using a software company’s products. As more and more customers purchase more products over time, new rows are inserted and this table grows. Occasionally, customer information needs to be updated, such as their contact information, which leads to rows being updated in the Customers table.
While this is all very valuable information, it is still static and shows you a point-in-time view of the. You can query the table to get the contact information for a customer, but it doesn’t tell you when and how this information has changed over time. This is where CDC comes in. Its goal is to event-enable databases by turning all databases changes into events. Bingo!
With events, we can respond to them in real time and build downstream pipeline that can react to these events. For example, as soon as a new customer is added, we would like to send a thank-you email to them. This can be done via CDC. A new row is inserted for the new customer which is turned into an event, published to an event broker, subscribed to by some number of downstream processes, one of which is responsible for sending a thank-you email.
Let’s see what this looks like with an architecture diagram!
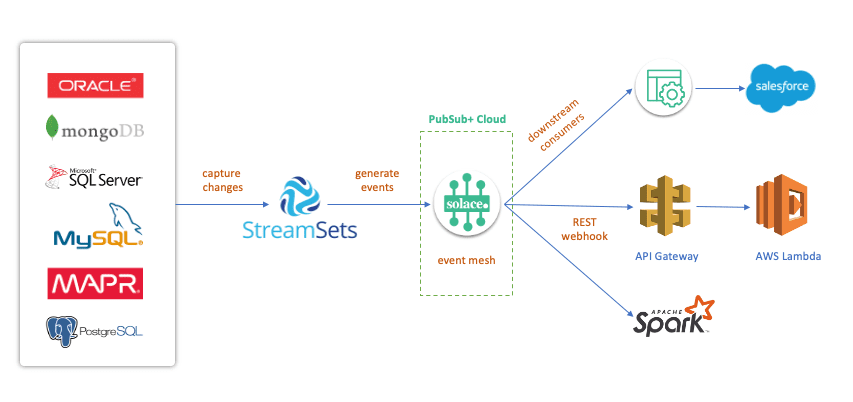
In this diagram, we have different databases where our records might be stored. We can event-enable these databases using CDC connectors provided by StreamSets. StreamSets is an enterprise data integration platform with multiple CDC connectors to databases such as Microsoft SQL Server, Oracle, MySQL, and PostgreSQL. StreamSets will generate events and publish them to Solace’s PubSub+ Event Broker.
PubSub+ is an enterprise grade event broker widely deployed by companies across industries to event-enable their systems. It supports open APIs and multiple protocols which makes it extremely easy to integrate with other technologies without any additional proxies. Once an event is published to a PubSub+ event broker, it can be independently consumed by multiple consumers. You can have a microservice using Java API to process the event, enrich it and then write it to Salesforce. Events can also be pushed out to downstream services such as AWS’s API Gateway via REST webhooks (all natively built into Solace PubSub+) and then consumed by additional AWS services such as Lambda. Finally, you can leverage Apache Spark for analytics.
Setting up the Components for CDC + EDA
Now that we know how the different components work, let’s test it out! I will show how you can event-enable your Microsoft SQL Server leveraging Streamsets’ CDC connector and Solace PubSub+ Event Broker.
For this demo, I chose StreamSets as my CDC source, but this is one of several options for CDC such as Qlik Replicate, Oracle Golden Gate, Striim, and Debezium, to name a few.
Microsoft SQL Server
I set up a dev instance of MS SQL Server on an AWS EC2 instance via docker. I followed instructions from here. Basically, set up Docker and run the following commands:
docker pull mcr.microsoft.com/mssql/server:2019-latest docker run -d --name example_sql_server -e 'ACCEPT_EULA=Y' -e 'SA_PASSWORD=Strong.Pwd-123' -e MSSQL_AGENT_ENABLED=True -p 1433:1433 mcr.microsoft.com/mssql/server:2019-latest
Once you have the docker container running, you will need to install MS SQL CLI. There are different ones available for the OS you are using. For an EC2 instance, you can install the CLI using this command:
yum install mssql-tools unixODBC-devel
Once it’s installed, you can log in:
sqlcmd -U sa -P Strong.Pwd-123 -H <hostname>
Next, we will create a database called demo and a table called Persons.
1> create database demo; 2> go 1> CREATE TABLE Persons ( 2>. PersonID int, 3> LastName varchar(255), 4> FirstName varchar(255), 5> Address varchar(255), 6> City varchar(255) 7> );
Now that the db and table have been created, we need to enable them for CDC so that MS SQL Server knows we want changes to be tracked. You have to enable CDC at database level and then at table level.
# CDC for DB USE demo GO EXEC sys.sp_cdc_enable_db GO # CDC for Persons table USE demo GO EXEC sys.sp_cdc_enable_table @source_schema = N'dbo', @source_name = N'Peresons', @role_name = NULL, @filegroup_name = NULL, @supports_net_changes = 0 GO
That’s it for MS SQL for now. Next, we move on to StreamSets.
StreamSets
There are different ways to deploy StreamSets. For this demo, I am using their free-tier SaaS offering which you can sign up for here. There is a lot of tutorials available to learn how you can build a pipeline using different input sources and destinations. You can even use components to transform payloads. For our demo, though, we will keep it simple and publish the event as it is to Solace PubSub+.
Click on Set Up >>Deployments and create a new Deployment with the following additional libraries: JMS, and SQL Server 2019 Big Data Cluster Enterprise Library. Follow rest of the instructions to get to the docker installation instructions. For example:
docker run -d -e STREAMSETS_DEPLOYMENT_SCH_URL=https://na01.hub.streamsets.com -e STREAMSETS_DEPLOYMENT_ID=b62044de-16b8-42e5-9d68-c2ed632e86b0:7bc55376-2098-11ec-a5fe-ffa35ee1d0b0 -e STREAMSETS_DEPLOYMENT_TOKEN=eyJ0eXAiOiJKV1QiLCJhbGciOiJub25lIn0.eyJzIjoiYTJjYmI4YjAzMTJhNTFmZWIxNGEzMTNjMzhkOWE2ZDg5YzljZDk0MzYzOTM5ZGFkZjAzNjFiYmVmNDQ3MDFlMjFlMDU4MjJjZGEwNjI0ZWQ0MTg2Y2M5ODA1YjhhN2M0NjVmOTEzOWIyMDBmMmJiMmQ2MGEwN2FlNmIwMmM2YzciLCJ2IjoxLCJpc3MiOiJuYTAxIiwianRpIjoiN2Q4ZmJiYTEtYWUyYS00NDhlLWIxNTYtZWU3ZWIwZmI4MTA2IiwibyI6IjdiYzU1Mzc2LTIwOTgtMTFlYy1hNWZlLWZmYTM1ZWUxZDBiMCJ9. streamsets/datacollector:4.1.0
Run the docker command on your local machine.
Once you have it running, go back to StreamSets and click on Set Up >> Engines. You will see an engine running here:

Click on that engine and click on External Resources on the following page. This is where you can upload additional libraries/resources for your data collector. We will need to upload Solace’s JMS library here to be able to use StreamSet’s JMS Producer.
Download Solace’s JMS API from their downloads page, unzip it, and navigate to lib directory. You will find the necessary jars there.
Go back to StreamSets, click on External Libraries and click on the + sign.
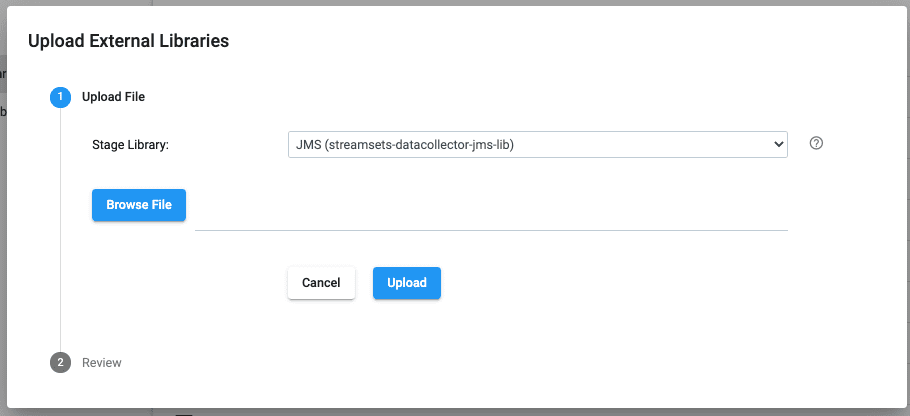
Select JMS (streamsets-datacollector-jms-lib) from the dropdown menu next to Stage Library.
Next, upload all the jars that you just downloaded.

You will be asked to restart the engine/collector for changes to take effect.
Now it’s time to build a pipeline. Go to Build and click on Pipelines. Create a new pipeline. You can then add components to it. Here is what your pipeline needs to look like:
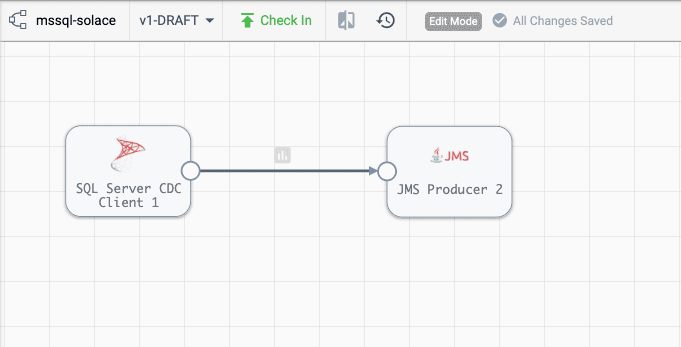
It has two components: SQL Server CDC Client and JMS Producer.
Configure the SQL Server CDC Client with the following properties (keep others as default):
JDBC: Connection: None JDBC Connection String: jdbc:sqlserver://<host>:<port>;database=demo Fetch Size: 255 Max Batch Size (Records): 255 CDC: Capture Instance Name: % Credentials: Username: sa Password: Strong.Pwd-123
Next, configure the JMS Producer:
JMS: Connection: None JMS Initial Context Factory: com.solacesystems.jndi.SolJNDIInitialContextFactory JNDI Connection Factory: /jms/cf/default JMS Provider URL: tcp://<pubsub_broker_host>:55555 JMS Destination Name: cdc/demo/sqlserver JMS Destination Type: Topic Additional JMS property: Solace_VPN_NAME: <pubsub_vpn_name> Credentials: Username: <pubsub_username> Password: <pubsub_password> Data Format: Data Format: JSON JSON Content: Multiple JSON Objects
Now that our pipeline is ready, it is time to set up our Solace PubSub+ Event Broker.
Solace PubSub+ Event Broker
Just like StreamSets, there are numerous ways to deploy PubSub+ Event Broker. Pick the one that’s the easiest for you. I prefer to spin up a free instance using my trial account on PubSub+ Cloud. You can sign up for an account here.
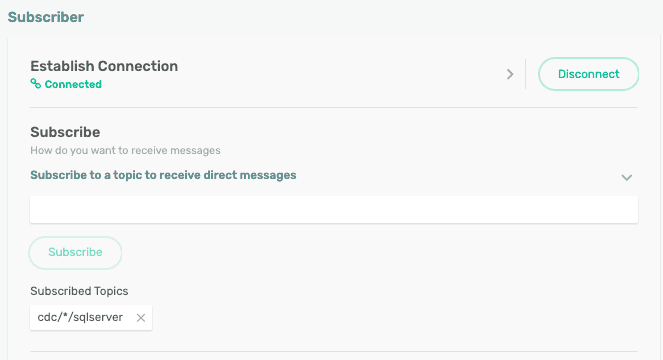
Once you have a service running, go to the “Try Me!” tab and connect to the Subscriber app. Here we will subscribe to the topic that our JMS Producer was configured to publish events to in the previous step: cdc/demo/sqlserver.
PubSub+ supports dynamic hierarchical topics which allow subscribers to filter events using wildcards. For example, I might have multiple CDC sources (Oracle, MS SQL, etc.) publishing to different topics such as cdc/demo/. I might have one downstream subscriber subscribing to cdc/*/sqlserver and another subscribing to cdc/*/oracle. You can learn more about Solace topics here.
Demo Time!
Phew, now that we have everything set up, it’s demo time! Let’s run our StreamSets pipeline by clicking on Test Run on the top-right side and then clicking on Start Pipeline.
Now, go back to your SQL Server instance and run a SQL statement to insert a row.
Insert into Persons Values ('007', 'Bond', 'James', 'Main St', 'London')
(Side note: I cannot wait to watch the latest Bond movie No Time To Die!)
Soon after running that statement, you will see some data in the Realtime Summary section of StreamSets.
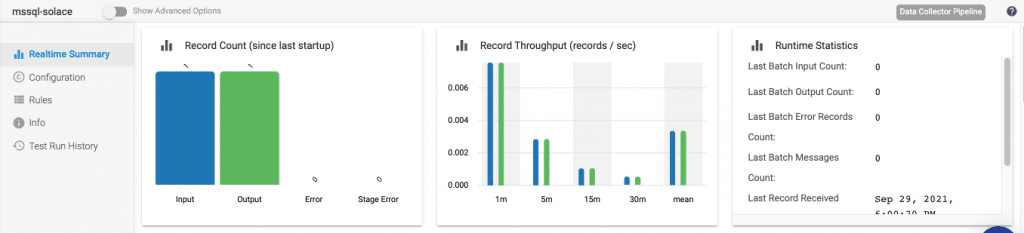
It shows that there was 1 Input and 1 Output which means our change (inserting row) was picked up by our pipeline! Awesome!
Now, let’s go to our PubSub+ broker and see if our Subscriber picked up a message. And, of course, it did!
2021-09-29 18:03:20:847 [Topic cdc/demo/sqlserver]
Delivery Mode: Direct
Sender Timestamp: 2021-09-29 18:03:20:840
Priority: 4
Destination: [Topic cdc/demo/sqlserver]
AppMessageID: ID:172.17.0.3936317c32cd41500:7
SendTimestamp: 1632953000840 (Wed Sep 29 2021 18:03:20 GMT-0400 (Eastern Daylight Time))
Class Of Service: COS1
DeliveryMode: DIRECT
Message Id: 2
XML: len=88
7b 22 50 65 72 73 6f 6e 49 44 22 3a 37 2c 22 4c {"PersonID":7,"L
61 73 74 4e 61 6d 65 22 3a 22 42 6f 6e 64 22 2c astName":"Bond",
22 46 69 72 73 74 4e 61 6d 65 22 3a 22 4a 61 6d "FirstName":"Jam
65 73 22 2c 22 41 64 64 72 65 73 73 22 3a 22 4d es","Address":"M
61 69 6e 20 53 74 22 2c 22 43 69 74 79 22 3a 22 ain.St","City":"
4c 6f 6e 64 6f 6e 22 7d London"}
As you can see in the payload, it picked up the new row that was inserted into the database. You can use this event as a trigger for numerous downstream processes. One such process can be one that sends a Welcome email to new customers. I am sure James Bond would love that!
Conclusion
I hope I’ve helped you understand how you can leverage StreamSets and Solace PubSub+ to build a CDC pipeline that event-enables your databases! If you have any questions or comments about this blog post or topic, post them to the Solace Developer Community.
Explore other posts from category: For Developers



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.