How the PubSub+ Connector for Kafka Enables Fine-Grained Filtering, Protocol Conversion, and Scalable Delivery
Kafka is often used to aggregate massive amounts of log data and stream it to
A growing number of companies we’ve been working with are trying to enable real-time connectivity between their Kafka clusters and non-Kafka applications and systems. While helping them do so we’ve seen them struggle with these 6 challenges:
The solution to these challenges is a new digital backbone called “Kafka mesh” – an event mesh focused on connecting Kafka deployments with the rest of your enterprise. I sat down with our Chief Technology Solutions Officer Sumeet Puri to get his perspective on Kafka mesh and how companies can use one to overcome these 6 challenges as they connect their Kafka deployments with their operational world. You can also watch the video below to hear Sumeet’s perspective on Kafka Mesh.
Sumeet: A Kafka mesh is an efficient way of enabling real-time connectivity between Kafka deployments and anything and everything else in an enterprise. The enterprises we work with have distributed IT and OT and they are using a wide variety of technologies, new and old. There are MQTT devices, REST endpoints, MQs, iPaaS, ESBs, and many different Kafka deployments. In some cases, clients actually have multiple flavours of Kafka running as well, like Apache Kafka, Amazon MSK, and Azure Event Hubs. So a Kafka mesh is a way to efficiently connect and move data through all those technologies.
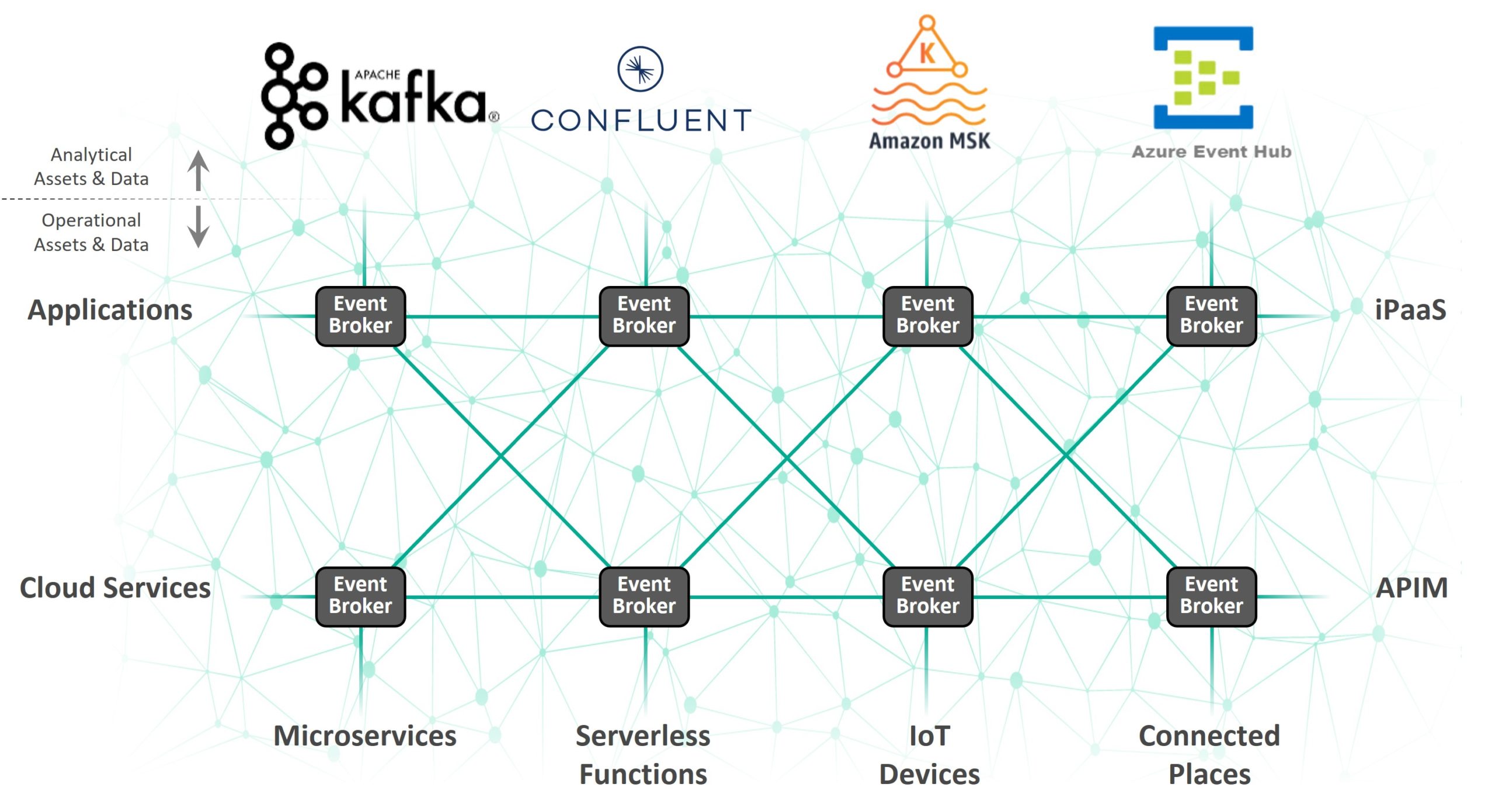
In terms of how this is built and run, you deploy event brokers in any environments you want to stream events to and from, and then you connect the event brokers to create an event mesh, which is a network of smart event brokers. Then different application teams can connect their applications/Kafka clusters to a local broker, and get real-time connectivity to everything else connected to the mesh. So all your Kafka deployments get intermediated by the brokers…by this mesh.
Sumeet: While Kafka was built for analytics and event sourcing, transactional systems need to provide those event streams, and that is the mesh part of the Kafka mesh. For example:
Those are some of the real-time, operational and customer-focused scenarios that a Kafka mesh will help companies address.
Sumeet: First and foremost, by ‘smart event brokers’ I mean brokers that support publish/subscribe, assured delivery, and multiple standards based protocols such as REST, AMQP, MQTT, JMS are built network up, to navigate the WAN smartly, and can be easily connected and that can dynamically route events between event producers and subscribers in distributed systems. So there is an intelligence built into the network, into the event mesh. That intelligence is based on the brokers in the network sharing a core technology and a common topic and subscription registry. For example, when a new event or event subscription is registered with one broker, all brokers in the system automatically know about that, and can work in concert to dynamically route those events within the mesh, as they occur.
Sumeet: Apache Kafka brokers and other open-source brokers don’t have those capabilities and that intelligence. They were built as distributed logs, i.e. very file system centric, rather than network centric. It’s a subtle, but critical architectural difference.
Even more importantly, those brokers don’t natively support the variety of open standard protocols and APIs that you will need to be able to create the event mesh. That’s critical to moving events between the variety of IT and OT that you may have in your system. Kafka does not support topics with wildcards – every topic is a static, flat topic, so dynamically learning filtered event streams across sites is impossible with the topics and partitions architecture of Kafka. And finally, these tools don’t offer enterprise-grade performance, robustness, reliability, and security, so if you use one you’ll need to consider the time and energy it’ll take to add those capabilities to your system.
Sumeet: Apache Kafka’s Mirror Maker is a tool used to replicate data between Kafka clusters. It’s a heavy, often manual process, and at any rate, its not a solution to the challenge of connecting and enabling real-time data movement between Kafka clusters and non-Kafka apps/services/devices from across your enterprise. It’s not dynamic topic aware, filtered or WAN optimized. Simply put, running Kafka clusters on factory floors, in retail stores, etc. just isn’t practical, so you can’t use Kafka itself as your primary event mesh.
Because of these inherent architectural weaknesses of log shipping, replication for Kafka has been re-written several times: Confluent Replicator, Mirror Maker (1.0 and 2.0), Ubers uReplicator, just to name a few. A Kafka mesh is a “network up” approach to integrating Kafka Clusters and enabling real-time integration of Kafka and non-Kafka assets across sites.
Sumeet: Confluent is the most mature (and most expensive) Kafka solution out there. While Confluent has Kafka Connectors and Replicator, Confluent’s architectural approach is not that of an event mesh, where topics are dynamically discovered and applied. With a Kafka mesh, when a consumer comes online and subscribes to a topic, the entire mesh automatically learns it, without the need for configuration.
Furthermore, Kafka mesh supports edge fanout. That means a single copy of an event will flow from the source site to the destination over a WAN link, event if there are multiple consumers on the far side. This becomes even more interesting with non-Confluent distributions of Kafka, for example, if the source event is on an on prem Confluent cluster, but the destination is in AWS, with Lambda, MSK and Kinesis all wanting the same event. In that case the Kafka mesh will send a single copy of the events from the source cluster to AWS, and fan out to all these consumers within AWS.
Then there’s the fact that a Kafka mesh relies on topic subscriptions that include wildcards, and over the WAN at that. Kafka does not itself support topics with wildcards. You need KSQL for filtering, which is an additional layer, and a security nightmare, as you will get events, and throw the unwanted ones away. Imagine if you could subscribe to “orders/>” to get all order, or “orders/*/us/>” to get all US order, and the Kafka mesh will give you a filtered stream over the WAN. The list of advantages is long, from fine grained topic ACLs to WAN optimization.
Sumeet: Most fundamentally, you need real-time connectivity across different flavors of Kafka running in different environments, and the ability to connect your Kafka clusters to REST endpoints, message queues, iPaaS environments, MQTT devices and more. You need sophisticated topics including wildcard support so you can perform fine-grained filtering and grant role-based access over a multi site network, with edge fanout. And you need a system that can automatically route events, so you don’t have to spend hours programming event-routing.
Sumeet: Just like an API portal lets users catalog and govern APIs, an event portal lets you do the same with your events, so it’s a great companion to any event mesh or Kafka mesh. The event portal needs the ability to scan and discover Kafka and non-Kafka event brokers, and catalog the topics, producers, consumers and schemas so new producers and consumers can know what is flowing over the mesh. As part of that, an event portal can create a visual view of event flows, i.e. which topics flow among which producers and consumers. This lets people more easily understand event flows so they can analyze and handle dependencies when pushing changes.
The future of APIs won’t be limited to request/reply, and an event portal can help you monetize your Kafka and non Kafka events via event API products. As data becomes a product, real time data will be offered as event streams, and event API products would be the mechanism to make it happen with standards like AsyncAPI, and an event portal can make all of that happen with the Kafka mesh!
I hope this Q&A with Sumeet has helped you understand the nature, advantages and requirements of a Kafka mesh. You can learn more about how PubSub+ Platform can augment and complement your Kafka deployments by reading the series of blog posts that starts with Why You Need to Look Beyond Kafka for Operational Use Cases.
Explore other posts from category: For Architects



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.