AsyncAPI vs OpenAPI: Comparing the Two Leading API Specs
AsyncAPI and OpenAPI are different ways of defining application programming interfaces (APIs), also commonly known
AWS Customers often utilize Amazon Managed Streaming for Apache Kafka (Amazon MSK) for streaming data in near-real-time. These data streams often originate from a multitude of source applications and flow to many consumers forming event-driven systems. As companies design and build those, their ability to keep track of, catalog and share event streams is critical to the success of their business.
Amazon MSK makes it easy to run Apache Kafka clusters on AWS with a fully managed solution, and PubSub+ Event Portal makes it easy to discover and catalog event streams, data schemas and applications that interact with MSK. This post will explain the different ways that Event Portal can benefit Amazon MSK users and their business as they take better advantage of streaming.
Amazon MSK is a fully managed streaming service that automatically configures and maintains Apache Kafka clusters for you. Amazon MSK lets you focus on building your streaming solutions and supports familiar Apache Kafka ecosystem tools (such as MirrorMaker, Kafka Connect, and Kafka streams) and helps avoid the challenges of managing the Apache Kafka infrastructure and operations. The focus of MSK and Amazon is really around the operationalization of Kafka via best practices through design, defaults, and automation and let you free from managing its infrastructure components.
As you focus on building your streaming solutions – which in many cases can be developed as custom applications deployed to AWS or as integrations to existing AWS services – it can be tricky to reverse engineer what has already been developed and catalog existing events that you can reuse as part of new business capabilities. This is where Solace comes to the rescue!
Solace has been helping enterprises of all sizes become “event-driven” for nearly two decades. The knowledge we gained enabling everything from real-time market data distribution in capital markets data (RBC) to live updates of aircraft positions for air traffic control (FAA) led to the creation of PubSub+ Event Portal.
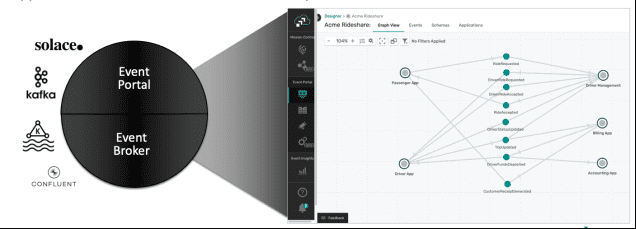
Figure 1: PubSub+ Event Portal is a single place to design, discover, catalog, visualize, secure, share and manage all events within your ecosystem.
Through those experiences, and many others, we recognized an emerging pattern. The return on investment or value of an event-driven and streaming platform would plateau in organizations if they were not able to reuse this real-time data. In some cases, organizations attempted to create their own catalog, which would become stale, out of sync and obsolete (just like how Confluence pages tend to go stale). This problem gets worse as people leave the team that created each streaming use case. This is reflected by the following graph:
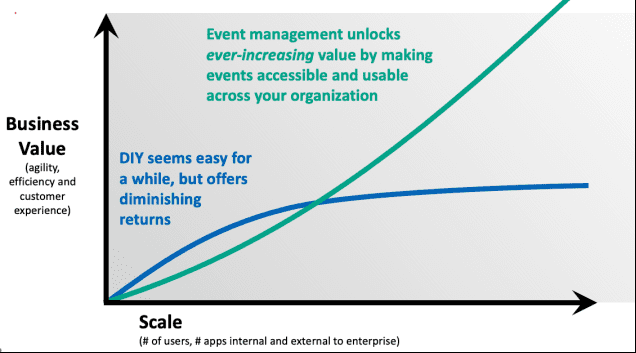
Organizations that recognize the value of managing, governing, and exposing real-time streams as data products are able to achieve ever-increasing value and demonstrate ROI, all while benefiting from democratization of data, controlling access to sensitive data, and preventing operational outages caused by application updates and retirements.
But the tricky bit is not simply providing a mechanism to expose your event streams, it’s in discovering what you have, documenting it understandably and correctly, keeping track of relationships in the highly decoupled paradigm of event-driven architecture and finally, exposing high value event streams and keeping it all synchronized and reflective of reality.
Let’s assume you already have several use cases creating and consuming data streams, leveraging Amazon MSK as your event broker. If someone outside of your team asked you: “What data streams are available and what are their data structures and attributes?” how would you answer? If you’re like me, my mind would begin racing as I attempt to point them to internal documentation, that may or may not even be up to date! To make it even worse, every other team would have the same problem.
This is why we created a discovery agent within Event Portal that can scan your Amazon MSK cluster so you can reverse engineer and document what you actually have versus what you think you have. It’s as simple as running the discovery agent and providing your MSK credentials – from there it takes care of scanning the cluster for its topics, consumer groups and (if you use schema registry) its schemas.
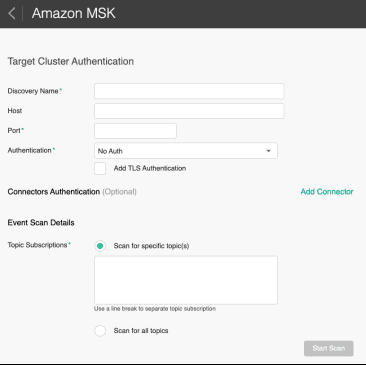
It ensures the relationships from topics to schema and topics to consumer groups are maintained and creates a “scan file” that contains all the discovered data. This file can then be uploaded into Event Portal where you further enhance the model and document the events, schemas and applications.
The resulting relationships can then be displayed using a graph view as shown below which shows the Amazon MSK Lab: Clickstream as an example:

Simply put, if one cannot find the event stream it does not exist, at least to that specific user or team. The decoupled nature of event streaming is both an asset and a liability in that applications stream data, and it’s up to others to find it, evaluate its value and applicability to their use case. PubSub+ Event Portal provides a rich catalog that supports keyword search. Let’s say you are analyzing clickstream data and are looking for the data attribute “departmentName”. You could simply go to Event Portal and search for that keyword within events, schemas and applications. Our search engine will return you not just that there was a match (department aggregation event schema), but indicate whether the match was within the topic name, schema content, description field, etc.
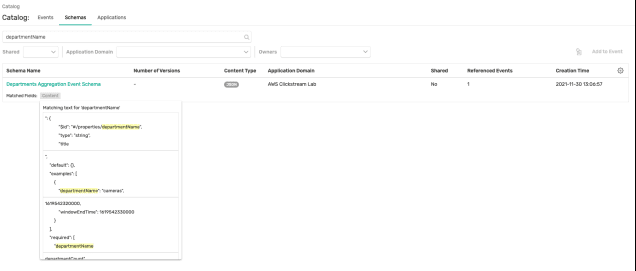
In this case, let’s say you found your keyword in a schema. It is possible that the schema is used by multiple events (i.e. Kafka topics), and now the key is to understand which event best represents the business moment that satisfies your use case. Without Event Portal it would be difficult or impossible to understand the relationships and business context. Event Portal manages and exposes relationships and dependencies, so you can see, for example in the case below, there is only one event (stream) referencing the schema, called Departments Aggregation Event Type, and you can also see which applications are subscribing and publishing this event stream:
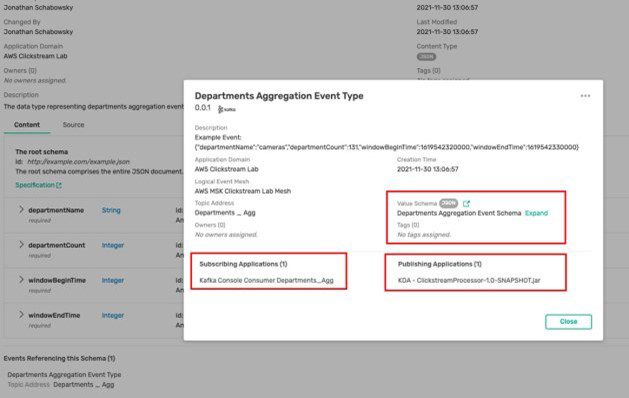
And Event Portal keeps all this information secure by providing a flexible role-based access control (RBAC) mechanism so that only the streams that you want to share are searchable and discoverable. The other streams are kept private and secure as you want them to be.
Sometimes a catalog is good enough if you are just exposing event streams between software teams within the same company or line of business. But what if you want to expose to more audiences? Audiences that may not fully understand how the underlying applications and systems work, and nor should they! The API world, largely built upon REST APIs, solved this by the ability to expose key APIs as “API products”. Leading companies expose these API products across their businesses and in B2B scenarios to enable wide adoption through ease of use. A well-organized API is worth its weight in gold! Think of flight information being exposed by the FAA to external applications to help you know when to pick up your partner from the airport.
The same concept holds true in the streaming world! By grouping event streams into event API products, organizations can curate how these events are composed/grouped together and exposed to their intended audiences. These event API products can then be exported into the AsyncAPI v2.x specification (AsyncAPI is the event streaming corollary to OpenAPI). This specification can then be uploaded into several different API Management Solutions or hosted on a custom developer portal. The choice of where/how you expose is up to you, the ability to easily create the event API product is provided by Event Portal, making use of the catalog of event streams running on MSK.
As mentioned earlier, relationship management is key for event streaming use cases. Why? If you want to see a dysfunctional relationship manifest itself technically, look no further than a data stream provider/producer changing or retiring a data schema without notifying downstream consumers! Because of decoupling, stream producers often do not know if any consumers even exist, let alone who they are and how to contact them. While this decoupling is a huge asset at runtime, it can make for a tricky situation to manage for us humans. Changes to event streams and data schemas should be proactively communicated to stake holders. And just because it’s not a “breaking change” does not mean it’s not important! In fact, we have seen cases where data attributes were added that were important for downstream consumer use-cases and they were completely unaware the data was there, simply because it wasn’t when they initially created the application AND it was never communicated.
At its heart PubSub+ Event Portal has a data model that supports an application producing or consuming to any number of event streams. Each event stream can have payload schemas associated. This allows for the data team to change schemas, understand which event streams used older versions of that schema and notify consumers and producers of these changes, all through the power of relationships!
Below is an example showing how a user could review the impacts of a change to the ClickStreamEventType. In this case, the only subscriber is the KafkaClickSteamClient-1.0-SNAPSHOT which is owned by Darryl MacRae. Obviously, this owner should be consulted if a change is going to be proposed:
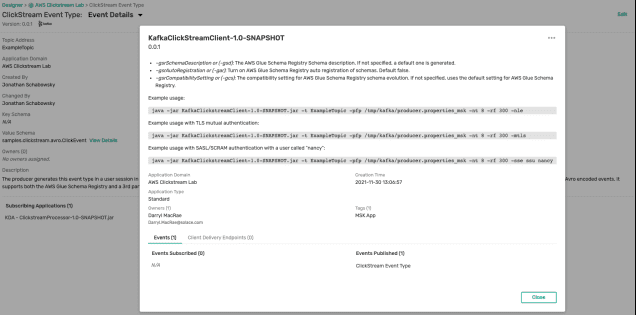
Capabilities are added, streams are deprecated, it’s a fact of life. How can you be sure that the changes are being properly managed and documented? Well, if you’re using a design first paradigm and you are using Event Portal and MSK to its full capability, you won’t ever have a problem. Right? Wrong.
People like to or have to take short cuts, forget to update documentation, it’s simply human nature. The minute humans are, well human, you no longer can be sure your documentation is up to date without a time consuming, manual, and error prone reverse engineering exercise. Which even if undertaken, only ensures correctness for that moment in time. More and more use cases are being solved using MSK and Streaming so that moment will be by the minute.
Remember earlier in this blog where we did our initial discovery so that we could reverse engineer what we already had running in Amazon MSK? Well, to ensure things are all synchronized, you can simply run the discovery agent again (and even on a periodic schedule) and add any new topics, consumer groups or schemas that are new! This helps to make sure that the information in Event Portal is as accurate as possible. We will be continually enhancing this feature to look for more and more types of changes so stay tuned!

PubSub+ Event Portal makes it easy to design, discover, catalog, secure, share and manage event streams running on Amazon MSK by providing a user-friendly interface with rich visualizations and a RESTful API that enables automation. Whether you are just starting with Amazon MSK and designing your first streaming use case or an MSK expert with thousands of topics and consumer groups, Event Portal will ensure that developers and architects have tooling that allows you to find, govern and critically reuse your streaming data assets to enable near-real-time data streaming success.
Explore other posts from category: For Architects



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.
You Also Might Be Interested In…