Imagine an airline managing a fleet of planes that constantly send real-time updates about their status, such as engine performance, fuel levels, weather conditions, and potential maintenance issues. Instead of relying on ground staff to manually monitor and respond to this data, an AI-driven system evaluates each incoming update. For instance, if an engine sensor reports unusual vibrations mid-flight, the system instantly alerts the maintenance crew to prepare for inspection at the plane’s destination. Meanwhile, if a weather delay affects a specific route, the system notifies the relevant crew members and adjusts passenger information accordingly.
Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.
This seamless and efficient flow of information is made possible by combining artificial intelligence (AI) with event-driven architecture (EDA) to ensure that every piece of data is analyzed and addressed in real-time, keeping flight operations safe and efficient.
In this piece, we’ll break down some of the often complex but incredibly helpful technologies like EDA, retrieval-augmented generation (RAG), and large language models (LLMs), and how you can use them with Solace Event Broker to build smarter applications that work with live, real-time data. Don’t worry if that sounds a bit heavy right now – we’ll walk through everything step-by-step with simple analogies to make it easy to grasp.
What’s Event-Driven Architecture Anyway?
Think of EDA as the central nervous system of your application infrastructure. Just like your nervous system instantly conveys stimuli so you can sense and respond to a wide variety of situations, EDA allows software systems to sense and respond to events in real-time. An event could be anything – a new customer signing up, a transaction being processed, or a sensor detecting a temperature change.
In technical terms, EDA is all about events triggering actions. When an event occurs, the system reacts immediately, ensuring that processes are handled efficiently and without unnecessary delays. This real-time responsiveness is crucial for applications that need to stay up-to-date and react quickly to changing conditions.
EDA with the publish/subscribe pattern offers an alternative to traditional point-to-point integration options such as HTTP/REST, which tends to limit scale and performance.
Introducing LLMs and RAG:
Your AI-Powered Helpers
Now let’s bring LLMs and RAG into the picture. These might sound like fancy terms, but let’s break them down:
Large Language Models
Imagine having a super knowledgeable colleague who has read countless books, articles, and reports. This colleague can help you draft emails, generate reports, answer questions, and more. That’s what LLMs like OpenAI’s GPT-4 do in the digital world. They are AI models trained on vast amounts of textual data, capable of generating human-like text based on the input they receive.
LLMs are used for various tasks like text generation, summarization, translation, transformation, and answering complex questions. They excel at understanding context and producing coherent, relevant responses. However, even the best LLMs can sometimes get things wrong or “hallucinate” – generating incorrect or fabricated information because they rely solely on their training data.
Retrieval-Augmented Generation
Think of RAG as an intelligent research assistant for your knowledgeable colleague. While LLMs generate responses based on their training, RAG enhances their capabilities by allowing them to access external information sources in real time.
RAG does three important things:
- Prevents Hallucinations: By retrieving relevant information from external databases or documents, RAG can provide better guardrails so the AI’s responses are more accurate and grounded in real data.
- Accesses Up-to-Date and Proprietary Data: RAG enables AI systems to fetch and utilize data that wasn’t part of the original training set, such as user-specific or company-proprietary information.
- References the Source of Data: RAG can point to the original source of the retrieved information, such as PDFs, Word documents, or databases. This is especially useful when users need to verify the accuracy of information or review the details in the source material.
For example, if your AI needs to answer a question about your company’s latest features, RAG can pull the most recent data from your internal databases, ensuring the response is accurate and relevant, and even provide a reference to the specific document where this data was found.
Solace Event Broker:
The Real-Time Switchboard
Now that we have LLMs (the knowledgeable colleague) and RAG (the intelligent research assistant), let’s talk about how Solace Event Broker fits into all of this.
Remember how we talked about managing information flow in the airline example? Solace Event Brokers act as the air traffic control system of an airline, ensuring that crucial flight data, maintenance reports, and pilot communications are routed to the right teams instantly. They handle all the communication between different parts of your AI system, keeping everything updated in real time. When Solace brokers and micro-integrations are used, real-time enterprise context can become the data source for RAG.
In technical terms, Solace brokers act as intermediaries that facilitate the flow of data between different components of your AI system – such as data sources and LLMs. This setup ensures that when new data arrives, it’s efficiently routed to the right component in real time, rather than relying on direct point-to-point connections. This publish/subscribe approach makes the system more scalable, adaptable, and capable of handling dynamic, real-time data exchange.
Solace-AI-Connector:
Bridging AI and Event-Driven Systems
Solace-ai-connector is a lightweight but powerful tool that makes it easier to integrate AI, particularly models like LLMs, and implement concepts like RAG, with Solace brokers. Think of it as the bridge that connects your AI models to real-time data streams from Solace brokers.
By using this connector, you can build flows that consume events from Solace Platform, process them with AI (such as LLMs and RAG), and then send the results back to Solace Platform. This seamless integration allows your AI system to work with live, ever-changing data, making the whole setup dynamic and adaptable.
For example, imagine that your customer support bot is powered by an LLM. With the solace-ai-connector, customer queries are processed in real time as events flow through the Solace broker. The connector can fetch relevant information using RAG, generate responses with the LLM, and send them back through the broker without skipping a beat. This allows for real-time interaction with up-to-date data.
The connector is designed for scalability and can be easily configured to handle more events as your application grows. You can use built-in components or even create custom ones, making it flexible for various use cases.
Under the Hood:
How This Works in AI Systems
To help you understand how all these pieces come together to ensure fast, relevant, and up-to-date responses, I’ll provide here an example that breaks the process down into two distinct flows.
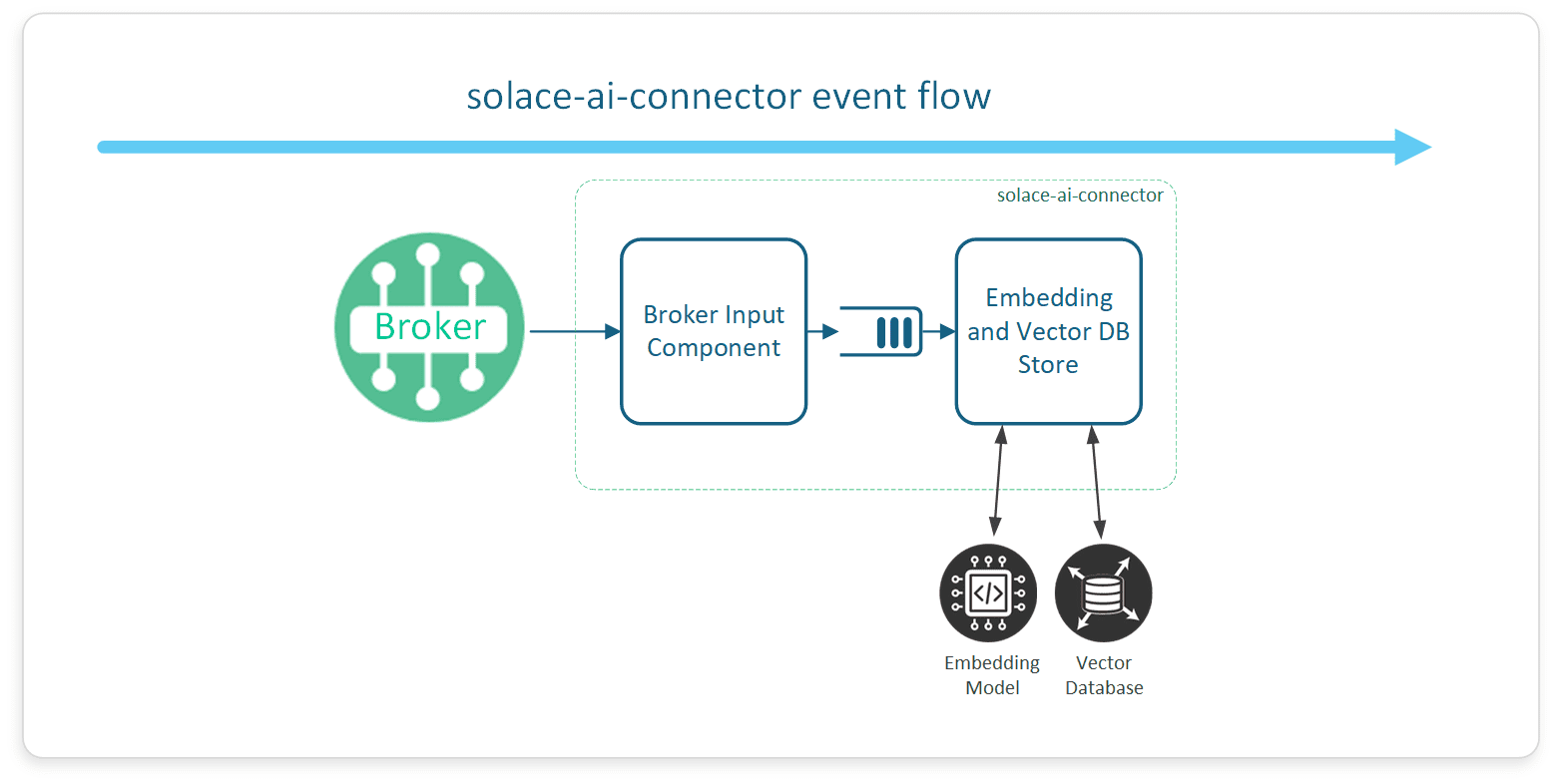
Flow 1: Preparing the Data for Use – Ingestion
Data Comes in Through Solace Platform
In our airline example, let’s say the fleet’s maintenance logs, pilot reports, and repair manuals are constantly updated. These documents and reports are published to specific topics in the Solace broker, which acts like an intelligent air traffic controller that ensures every update reaches the right system. For example, when a new maintenance report is filed about an engine issue, this data is published and routed to relevant AI systems that can process the information.
Embedding the Data
To help the AI system retrieve relevant information quickly, these maintenance reports and documents are converted into embeddings – unique numerical representations that capture the meaning and context of the data. This process is like turning the query into a set of coordinates on a map, where similar messages are grouped together.
The embedding step is crucial because it enables the AI to understand the content of each document, making it easier to locate information about specific issues, like past cases of engine vibration problems.
Storing the Embeddings in a Vector Database
These embeddings are crucial for RAG, as they help the system efficiently search for related content stored in a vector database. Think of the vector database as an organized filing cabinet that stores these embeddings based on their meaning, making retrieval quick and efficient. Once the query is converted into an embedding, it’s stored in the vector database, ready for future retrieval. This storage allows the system to rapidly search through vast collections of similar queries or documents to find the most relevant information when needed.
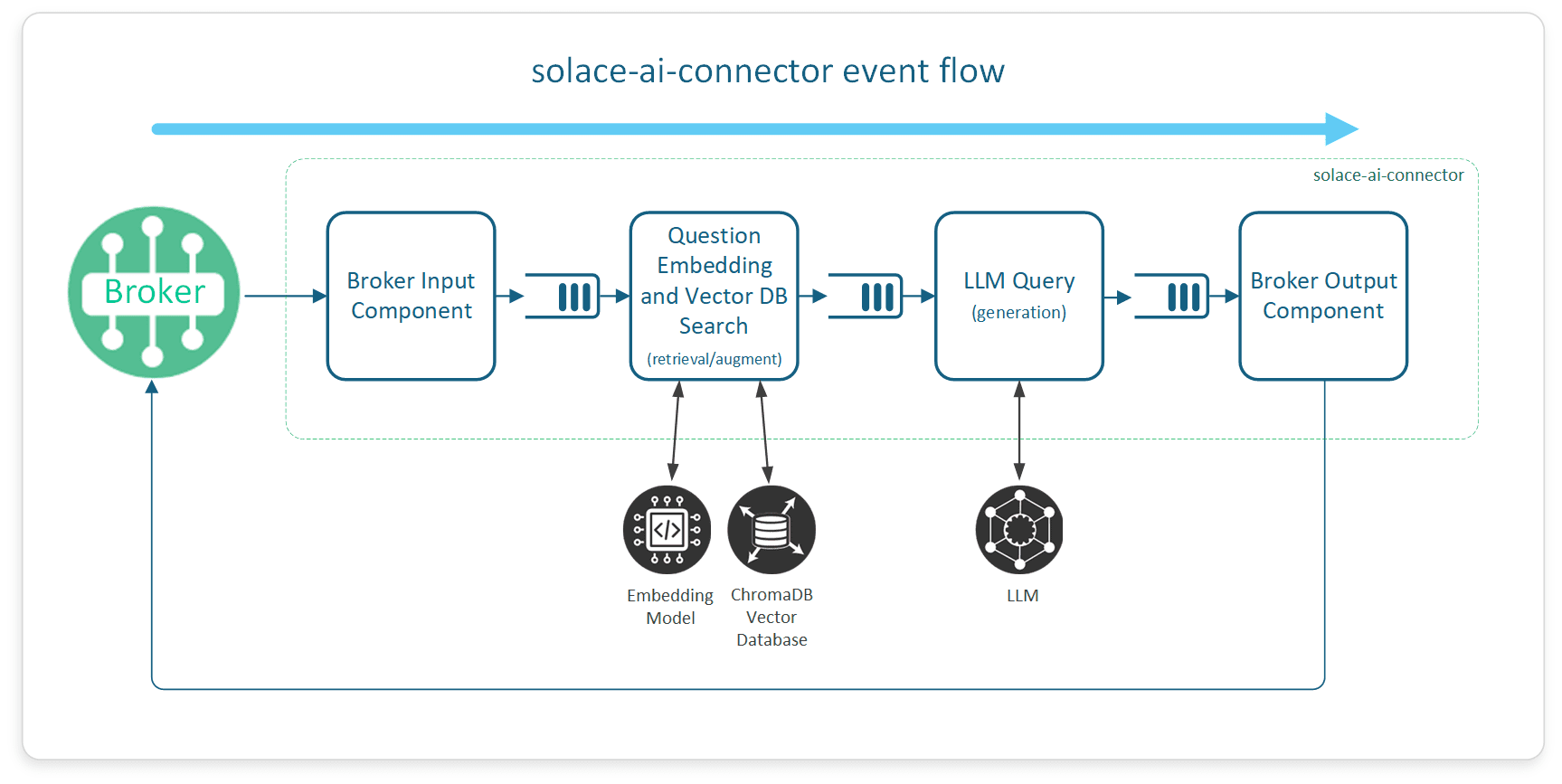
Flow 2: Answering Questions in Real Time – Generation
Retrieving Information with RAG
Now, imagine a maintenance engineer asks, “What were the findings of the last engine inspection for Flight 123?” Instead of the LLM generating a response based on general knowledge, the system uses RAG to search the vector database for relevant information, pulling in the latest maintenance reports, historical inspection records, and troubleshooting guides specific to that aircraft model. This ensures that the response is not only accurate but also backed by verifiable sources.
Real-Time Response Generation
Finally, the LLM uses the retrieved information to generate a comprehensive context-aware response, explaining what was done during the last inspection and suggesting potential next steps. Thanks to Solace Platform, this entire process happens in real-time, ensuring that the maintenance engineer receives the necessary information instantly, enabling swift decision-making and actions to keep the fleet operational.
This flow makes the AI system feel responsive, informed, and always ready to provide accurate answers.
How Solace-AI-Connector Fits In
In the bigger picture, solace-ai-connector plays a crucial role by making sure that your AI-powered applications are always connected to the latest data. Whether you’re working with customer interactions, IoT data, or financial transactions, this connector ensures your AI models process and respond to real-time events efficiently. It’s the piece that brings together the powerful capabilities of LLMs, embeddings, vector databases, and Solace’s event brokers.
Try It Yourself: Run a RAG Example
Want to see how this all works in action? You can try it yourself by running a RAG example using solace-ai-connector.
Follow this guide to get started: Running a RAG example with Solace AI Connector
In this example, you’ll see how to set up a pipeline that processes real-time events, ingests and embeds new data, retrieves relevant data using RAG, and generates responses with an LLM. It’s a perfect hands-on way to understand how these technologies work together!
Explore other posts from categories: Artificial Intelligence | For Architects | For Developers



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.