Note: For an update comparison of Solace and Kafka, click here.
This blog post is part of a series comparing Apache Kafka with Solace’s PubSub+ Event Broker. In this post, I’ll explain how pub/sub messaging pattern implementation differs in these two brokers. Check out the rest of the posts in the Solace vs. Kafka series:
- Solace PubSub+ vs Kafka: The Basics
- Solace PubSub+ vs Kafka: Filtering
- Solace PubSub+ vs Kafka: High Availability
- Solace PubSub+ vs Kafka: Multi-Site Architecture
Publish/Subscribe, commonly known as pub/sub, is a popular messaging pattern which is commonly used in today’s systems to help them efficiently distribute data and scale among other things. The pub/sub messaging pattern can be easily implemented through an event broker such as Solace PubSub+, Kafka, RabbitMQ, and ActiveMQ.
When you use an event broker, you have a set of applications known as producers and another set of applications known as consumers. Producers are responsible for publishing data to the broker and similarly, consumers are responsible for consuming data from the event broker. By introducing a broker to our architecture, we have removed the need for producers to directly communicate with the consumers. This ensures we have a loosely coupled architecture. Additionally, our broker now becomes responsible for managing connections, security, and subscription interests, instead of implementing this logic in the applications themselves.
Different event brokers implement the pub/sub messaging pattern differently. It is important to understand their implementations when deciding which event broker to use for your specific use case.
Pub/Sub in Kafka
To understand Kafka’s implementation of pub/sub, you need to understand topics, producers, and consumers.
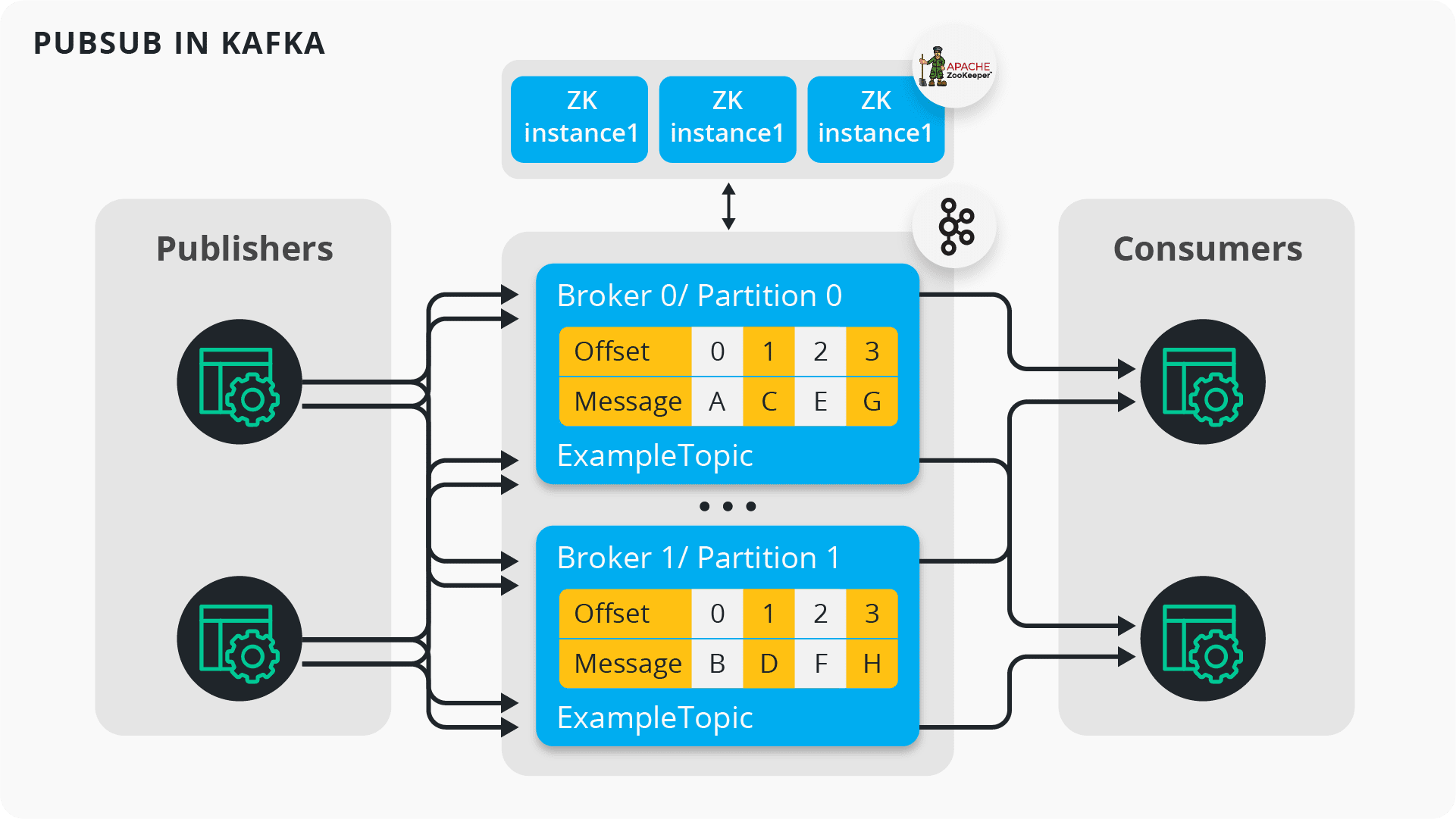
Topics
As described in part one, in Kafka messages are produced and consumed via topics. They are immutable log files, persisted on disk, to which data is appended sequentially. Given that Kafka is a distributed system, you need to create topics and decide how you want to partition and replicate them across your brokers. While topics can be created by default if they don’t exist, it is best practice to manually create them with appropriate settings before using them.
Producer
A Kafka producer can be programmed to write data to a topic. If the topic has 3 partitions, data will be written to all 3 partitions in a round-robin fashion. This leads to a significant problem. Because our data is scattered across multiple partitions, we don’t get ordering across partitions. Additionally, Kafka publisher applications batch writes to improve performance as they publish data to Kafka brokers.
Consumer
If we want to consume the data we just wrote to our topic, we will need to create a consumer application and connect to our Kafka cluster. Your Kafka consumer can easily subscribe to a topic and consume the necessary data. However, as mentioned earlier, there is an issue caused by topic partitions. Because our data was written to 3 partitions, we have lost message ordering. When our consumer subscribes to the topic and consumes the data, it will get unordered messages. Depending on your system, this can be a critical issue.
To overcome this issue, you will need to use a key when publishing data so that all the messages pertaining to a specific key will always go to the same partition and hence preserve ordering. However, as you may have guessed already, with this workaround, you lose simple the ability to have balanced parallelization resulting in some partitions overflowing while others will be lightly used.
Furthermore, in Kafka, messages are polled instead of pushed to the consumer. When you program your consumer application, you are expected to provide a timer to constantly poll for data. As you can imagine, this can be highly inefficient if your application is frequently polling for data, especially when there is no data available.
Pub/Sub in Solace PubSub+
Solace’s PubSub+ Event Broker is an enterprise-grade event broker which supports open APIs and protocols. It comes with numerous enterprise-grade features straight out-of-box such as high-availability, disaster recovery, and security so enterprises don’t have to implement them.
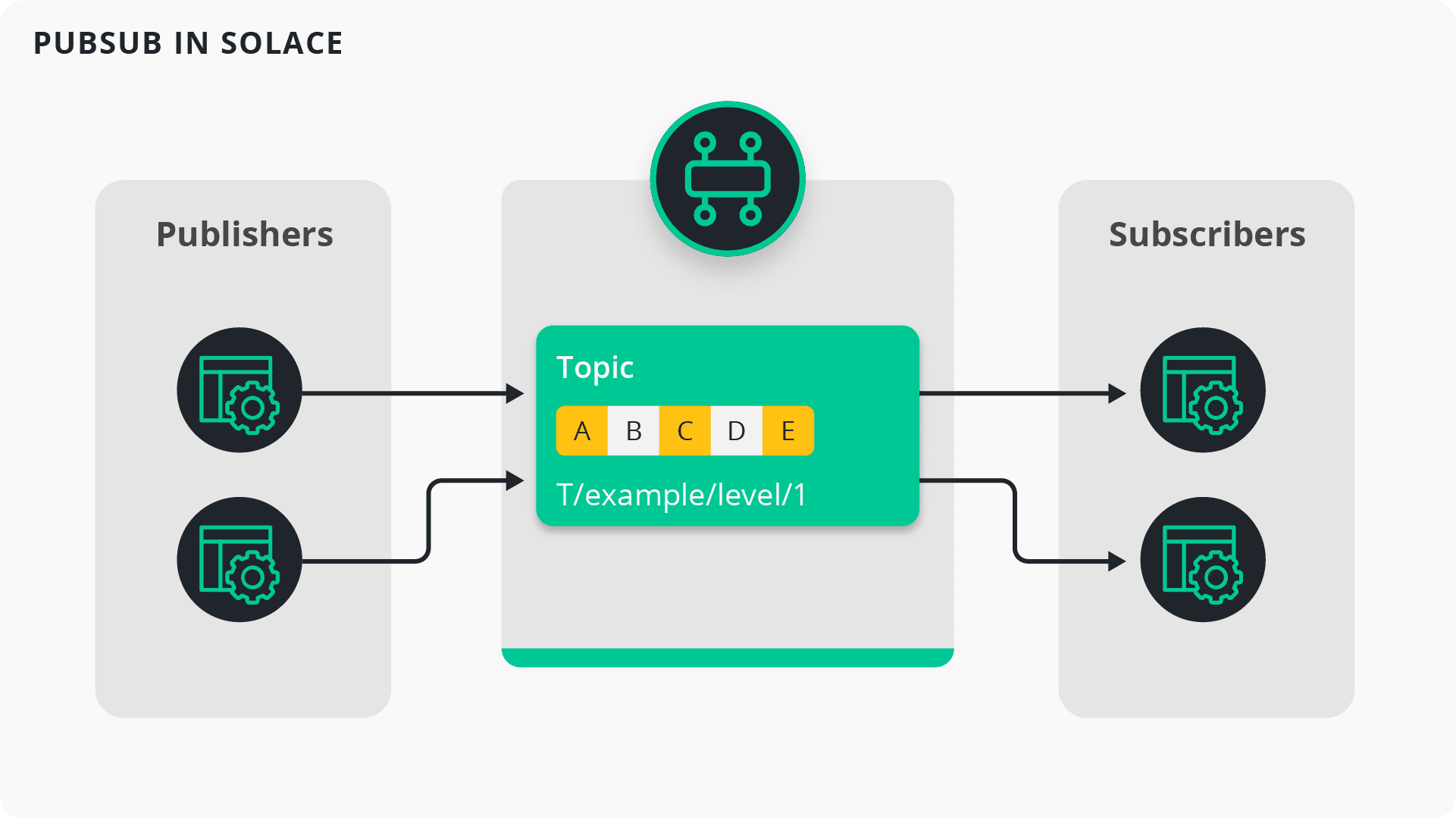
Topics
As you can see in the previous part, the topics of PubSub+ are very different from those of Kafka. Unlike Kafka’s topics, PubSub+ topics are dynamic and don’t need to be manually created. They are simply metadata that you use to describe your messages as you publish them. Additionally, PubSub+ topics are hierarchical, which means consumers can use wildcards to filter based on different levels in a topic.
Topic Hierarchy and Topic Architecture Best PracticesThe best practices in creating a sound event topic hierarchy that lets applications identify, attract, and consume the events they need
PubSub+ topics don’t need to be partitioned or replicated. The fact that they don’t need to be created and persisted to disk means that they barely require any maintenance. As your system scales, there is no need to rebalance your topics as you do in Kafka.
Publisher
PubSub+ publishers can be coded using any of the supported open APIs and protocols such as JMS, MQTT, AMQP, and REST. To publish data, your publisher application just needs to specify which topic to publish the data to. And that’s it.
Subscriber
Similar to Kafka, PubSub+ subscribers can be coded to consume from a topic by specifying the entire topic. Or you can subscribe to multiple topics using wildcards (* and >). Moreover, you can use these wildcards to dynamically filter data.
For example, if your publisher is publishing data for all US stocks from different exchanges to topics such as EQ/US/NYSE/AAPL and EQ/US/NASDAQ/FB, my consumer can subscribe to different datasets by subscribing to any of the following topics:
EQ/>– for all equities stocks*/*/NYSE/>– for all stocks traded on NYSE*/*/*/FB– for all messages for Facebook traded on different exchanges
It should be noted that with this approach PubSub+ Event Broker efficiently filters the datastreams to the clients as opposed to Kafka, where filtering happens on the client side or via an intermediary KStreams process. This saves both network bandwidth and compute resources on your consumer processes.
Furthermore, PubSub+ subscribers are push based instead of poll based. Messages will be pushed to subscribers rather than constantly poll for data.
Conclusion
To sum it up, the pub/sub messaging pattern implementation exists in both Solace PubSub+ and Kafka but they differ significantly. While PubSub+ Event Broker utilizes dynamic, hierarchical topics with wildcard support, Kafka uses flat topics partitioned across different brokers. Additionally, Solace PubSub+ Event Broker supports open APIs and protocols which prevents vendor lock-in whereas while Kafka is open-source, it does not support open APIs and protocols natively.
Check out the other posts in the Solace vs. Kafka series:
- Solace PubSub+ vs Kafka: The Basics
- Solace PubSub+ vs Kafka: Filtering
- Solace PubSub+ vs Kafka: High Availability
- Solace PubSub+ vs Kafka: Multi-Site Architecture
Explore other posts from categories: For Architects | For Developers



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.