Note: For an update comparison of Solace and Kafka, click here.
This blog post is part of a series of blog posts comparing Apache Kafka with Solace PubSub+ broker. Check out the other posts in the Solace vs. Kafka series:
- Solace PubSub+ vs Kafka: The Basics
- Solace PubSub+ vs Kafka: Implementation of the Publish-Subscribe Messaging Pattern
- Solace PubSub+ vs Kafka: Filtering
- Solace PubSub+ vs Kafka: Multi-Site Architecture
Overview of High Availability
In real life mission-critical systems, availability is a key factor for providing a good customer experience. One of the most frustrating feelings of the modern era is that when you are just one click away from that adrenaline rush of buying the product of your dream in your favorite commerce site, you receive a “service unavailable” error from either the ecommerce site or your bank!
That means achieving high availability when designing and building a system is a very common requirement for any organization. Nevertheless, one question that often gets forgotten in the process is: How can we achieve a robust high availability infrastructure that is simple enough that it will not become an operational nightmare or even a costly behemoth in the future?
And it’s important to remember that high availability can mean very different things for different businesses and use cases. Losing some events due to a failover for an analytics engine that is tracking mouse movements and clicks on a web page does not have the same kind of business impact as losing a purchase, trade or wire transfer, right?
How High Availability is Achieved with Apache Kafka
As described in the second part of this series, Kafka topics are split into partitions, and those partitions can be replicated across Kafka brokers grouped together as a “Kafka Cluster”. To achieve high availability with Kafka you replicate each topic partition across multiple brokers.
Kafka High Availability Basics
First, some facts about high availability in Kafka:
- The number of partitions doesn’t have to be equal to the number of brokers.
- Partitions are automatically distributed across available brokers based on the configured “replication factor”.
- At any time ONLY ONE broker can be the leader for a given partition.
- Publishers MUST write to the leader partition.
- Publisher sends data in a round-robin fashion to each one of the leader partitions.
- Messages on the “leader” partition get copied to “follower” partitions located on the other brokers.
- Message order is not guaranteed nor consistent across consumers (unless using keys, which will affect message throughput)
- Recommended Minimum number of brokers is 3.
- Recommended Minimum number of Zookeepers is 3 nodes.
- Recommended Minimum replication factor is 3.
Kafka High Availability in Depth

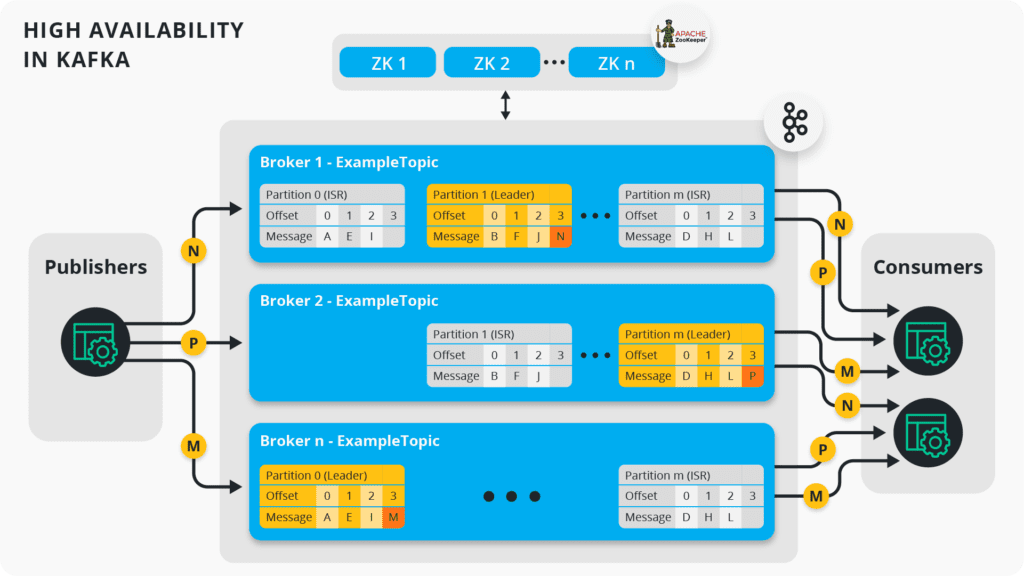
* ISR = In-Sync-Replica.
The first thing to notice is that as you add adding topics and load, you need to add more brokers to the cluster, making the system increasingly complicated and hard to manage and monitor. Moreover, disk memory and network costs can start to escalate quickly.
By default, Kafka provides an acknowledgment (ACK) to a publisher once the message has been stored on the leader partition, and it copies the message to the follower replicas afterwards. This default behavior may result in follower replicas lagging behind X number of messages (especially when combined with network latency or congestion), and in such scenario combined with a failure on the broker hosting the leader partition, one of the two things could happen based on the unclean.leader.election.enable config value:
- False (default) – The partition becomes unavailable, since there are not follower replicas that are In-Sync and thus no reads and writes can be done to it, beating the whole purpose of our HA setup.
- True – A follower partition is elected by the ZooKeeper as the new leader, and X number of messages gets lost.
Kafka provides another config to change the default acknowledge behavior of a publisher, the “acks” flag:
- acks = 0 – wait for no ack
- acks = 1- just wait for the leader partition to persist the message (default)
- acks = ALL – Wait for the message to be replicated on the number of brokers specified by the “replication factor”
To avoid the message loss scenario, the producer must be configured to send messages using the “acks = ALL” flag, but that forces the publisher to wait until the message is written on all the in-sync replicas of a given partition, which could greatly reduce the throughput, especially when combined with network latency or congestion.
How High Availability is Achieved with Solace PubSub+
As described in part 2 of this series, PubSub+ topics are simply metadata on a message that can be set dynamically by the publisher, so no partition concept or management is needed for a Solace topic.
Solace High Availability Basics
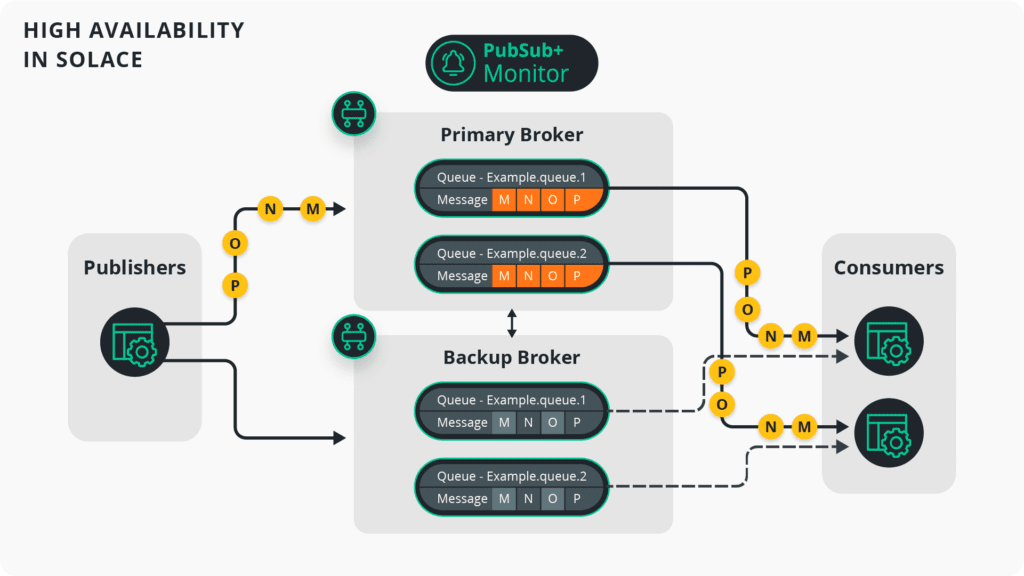
* Monitor Broker not needed for Solace appliances.
Here are some highlights about high availability in Solace:
- Required number of software brokers for HA is just 3.
- Publishers and consumers can independently specify their quality of service (QoS): Direct (Best Effort) or Persistent (Guaranteed).
- Clients establish connections only to the active (Primary) broker. There is no need to create or monitor multiple connections for a single client.
- Solace maintains a clean and simple failover strategy: Should the primary broker fail, the backup broker seamlessly switches its status from standby to active, allowing clients to automatically reconnect to the now active backup broker.
- Persistent messages are automatically synchronized between the active and standby brokers before sending an ACK to the publisher. There is no message loss by default.
- Once the failed broker comes back online, message reconciliation will happen in the background and automatically for Persistent messages.
- The Monitor Broker is just a small (1 CPU, 2 GB RAM) form factor node to avoid split-brain scenarios (not needed for Solace Appliances).
- Message order is preserved across all consumers regardless of their QoS.
Solace High Availability in Depth
For applications/use cases that can handle message loss, Solace provides direct messaging QoS which is unlike Kafka’s acks=0. PubSub+ Event Broker doesn’t even need to write a message to disk ̶ it pushes the message to subscribers directly from RAM right after receiving it, thus achieving extremely low latencies and high throughput on a single broker.
As described in part 1 of this series, consumer applications interested in receiving messages with the persistent QoS can either create queues or connect to queues that have been previously created. Both the queue and the persistent messages referenced by it will be automatically synchronized between the active and standby brokers. Once a message has been received and ACKed by a consumer, the message will be removed from the queue on both the active and standby brokers.
Regardless of the QoS of producers and subscribers, Solace PubSub+ Event Broker guarantees that messages will be sent to consumers in the same order they were received from the publishers.
Conclusion
Both Kafka and Solace provide mechanisms for achieving high availability on production environments, but it’s important to understand some key differences in the areas of complexity of configuration and deployment, and the performance overhead required to guarantee no message loss even in complex failure scenarios. The next post in this series will introduce multi-site architectures and explain their importance to today’s modern platforms.
Explore other posts from categories: For Architects | For Developers



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.