I was recently privileged to host a webinar in which Forrester Research Principal Analyst David Mooter explained four common challenges companies face when implementing Kafka at scale, and my colleague, Solace’s Field CTO Jonathan Schabowsky sharing some stories about real companies who’ve overcome them.
In this blog post, I’ve summarized some highlights from the webinar that I think will be useful for anyone working with Kafka and looking to make the most of their Kafka infrastructure. You can also skip my summary and watch the webinar on-demand here.
David Mooter, Principal Analyst, Forrester Research
David opened by giving a quick overview of Kafka before explaining that companies tend to face one or more of these four challenges as they grow their Kafka estate to cover more, and more mission-critical, use cases:
- Managing their infrastructure
- Managing load and scaling
- Mitigating topic sprawl
- Cataloging data and event streams
Challenge 1: Managing Infrastructure
David opened by explaining that the management of Kafka has become less difficult – you don’t need Zookeeper anymore, for example – but it’s still pretty complicated when you are talking about enterprise scale deployments.
He explained that he used to run a team that used Kafka for browser analytics, analyzing web clicks, so brief outages weren’t a big deal, but as they started using Kafka for mission critical activities where lost messages weren’t acceptable, things got tricky.
For sake of example, he shared the “active/active” topology that Uber used to ensure high availability of messages flowing through a pair of datacenters, whereby all messages were not only made available to local readers, but to “global read clusters” that receive all data on all topics. They had to code jobs to manage the handover in the event of a failure, and there was still no guarantee that messages would be delivered in sequence depending on when each read cluster received them.
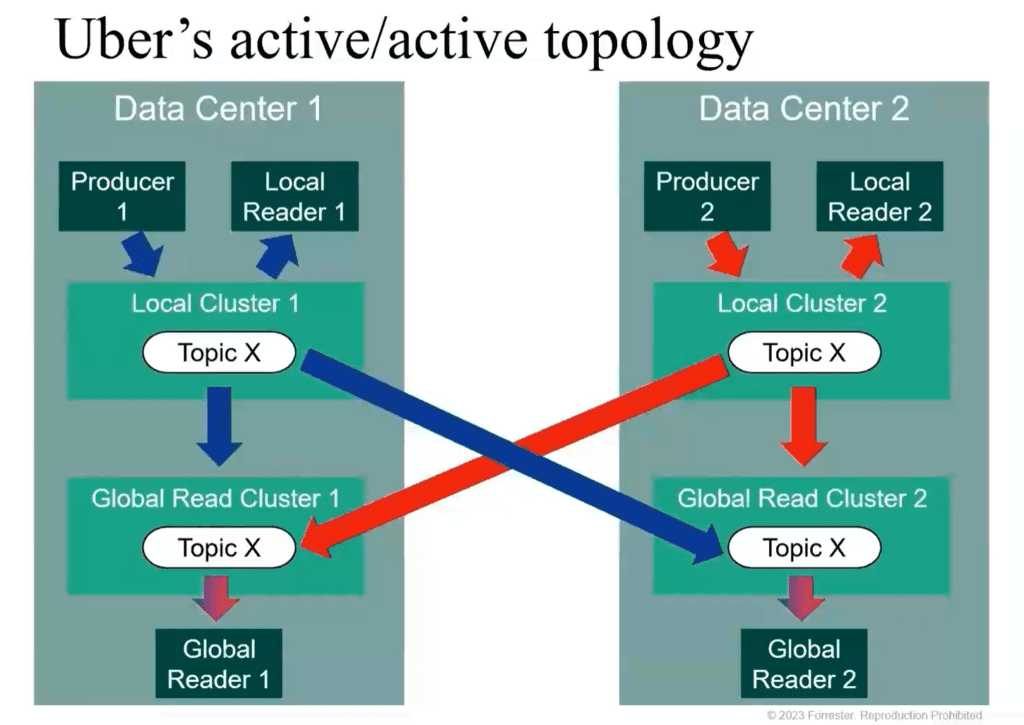
His Advice? Put thought into how you’ll manage complexity as your messaging needs get more complicated. Like how you’ll manage disaster recovery, offsets, duplicate messages, and the need for idempotency, i.e. making sure that recipients ignore duplicate messages.
Challenge 2: Managing Load and Scaling
David then explained why it’s important to hire experienced Kafka engineers to make sure your clusters can handle high throughput as the volume of data being ingested grows, because doing so requires careful hardware provisioning, optimization and scaling. They’ll also know how to best deal with the tradeoffs associated with “at least once”, “at most once” and “exactly once” delivery, which have significant impact on throughput.
Engineers familiar with Kafka are also best equipped to set your system up for effective cloud-native auto scaling in Kafka as a service situations, and put in place a thoughtful proactive strategy for partitioning.
He gave an example of how partitioning affects parallelism.
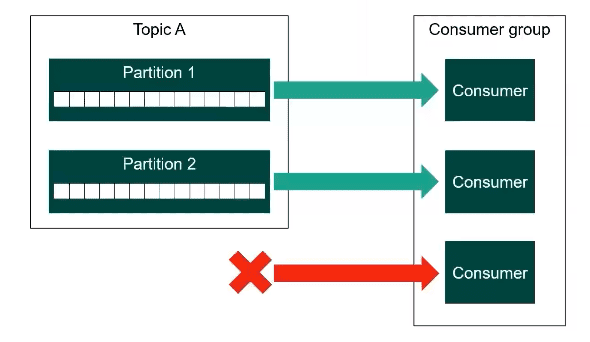
Getting the partitioning strategy for a topic wrong can be very hard to fix, and usually entails the need to start over by creating a new topic and migrating all of your producers and consumers to the new topic.
Challenge 3: Topic Sprawl
He next talked about the challenge of topic sprawl – not knowing what apps are consuming data from what topics, or not knowing which topics are published on which clusters, which he called “shadow topics.” The key to eliminating shadow topics is to use a topic discovery tool, like how you’d use an API discovery tool. Another important tool to have in your arsenal is a visualizaton tool that shows what services communicate with which topics.
Challenge 4: Cataloging Data
Another common challenge, related to topic sprawl, is not having reliably up to date documentation about which topics are available. Many companies have producer-centric registries, but not a catalog that consumers can use to identify and subscribe to useful topics. Such catalogs are particularly powerful when event streams are built with AsyncAPI to foster easy reuse, as David highlighted by sharing examples of event streams exposed by eBay and SAP.
David’s Wrapup
David closed out his talk with the observation that APIs and EDA are converging, in that the biggest value of both APIs and EDA is that they enable modular business transformation, because you start thinking of your company’s IT infrastructure in terms of discrete, flexible, reusable capabilities instead of applications that perform a specific function. The main difference being whether the services are something you request, or a stream of information you ask to receive. His recommendation is that you establish common processes for the lifecycle management and governance of your APIs and EDA assets.
With that point made, he handed things over to Jonathan so he could share some stories about how he’s seen companies overcome exactly the challenges he described.
Jonathan Schabowsky, Field CTO, Solace
Jonathan then explained that the convergence of APIs and EDA that David talked about is something we see all the time in our customer base. He gave three examples:
A large retailer that’s had to transform their business since COVID, because of the need to support new interaction models for buying in-store and online, delivering or picking things up, accepting returns, etc., all of which is ripe for event-driven interactions. To support that shift they’ve had to find ways to organize the events that enable those features, and expose them across their own organization and network of stores, suppliers and fulfillment partners.
The second example he gave was the aviation space, with thousands of planes taking off, flying and landing all the time, generating all kinds of information about boarding, location, luggage, takeoffs and arrivals, and more. They need to capture data about all that activity and disseminate it to all of the systems and people and stakeholders that use it to derive insights and make decisions that conserve fuel, satisfy passengers and more.
His third example was in the financial services space, where initiatives like open banking and “fin tech” that sees institutions exchanging sensitive information in real-time. This puts new pressures on FSIs to govern their data, understand who is consuming which events from a regulatory perspective so they can ensure compliance.
Jonathan then explained that Solace believes that to truly capitalize on Kafka you need an effective strategy for event management, i.e. one that lets you answer the following questions with a resounding yes:
- Do you know your Kafka system? Distributions, number of clusters, and topics?
- Do all your topics have access controls based on the data?
- Can your team check the impact of changes they make?
- Can your team easily find events to reuse?
He finished up his talk by sharing a tool that we’ve developed to help companies assess how effectively they are managing Kafka, a “Kafkatosis Risk Assessment” you can take for yourself at https://solace.typeform.com/kafkatosis
Hopefully you won’t end up at “high risk” but you’re sure to learn a little about the kinds of things that indicate ways to make more of your Kafka estate along the way.

Questions and Answers
We closed out the informative webinar by fielding questions from the audience, with David and Jonathan each taking their crack at a few that were posed, including:
- Are there tools that can catalog both RESTful APIs and Kafka events?
- How efficient is Kafka for processing sensor data?
- Are there emerging specs like OpenAPI for Kafka streams?
If you’ve read this far, I highly recommend you watch the entire webinar to get the full story straight from the horses’ mouths!
Explore other posts from category: For Architects



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.