Expanding Kafka beyond its natural boundaries as a single flavor, single region solution is now easy by building infrastructure called a Kafka mesh that lets you link any number of Kafka clusters and flavors across cloud, on-premises, multi-cloud, and hybrid cloud environments. This infrastructure will also strengthen integration with support for a variety of open protocols, API management tools, non-Kafka event streaming, and the integration of IoT devices. All of this is provided with effective filtering while preserving order to efficiently utilize your Kafka and network resources in real-time.
What is a Kafka Mesh?
A Kafka mesh is an event mesh specifically tailored to make Kafka clusters the primary sources and sinks for event flows. An event mesh is a network of event brokers that dynamically routes events and information from one publisher to any number of subscribing applications, devices and user interfaces.
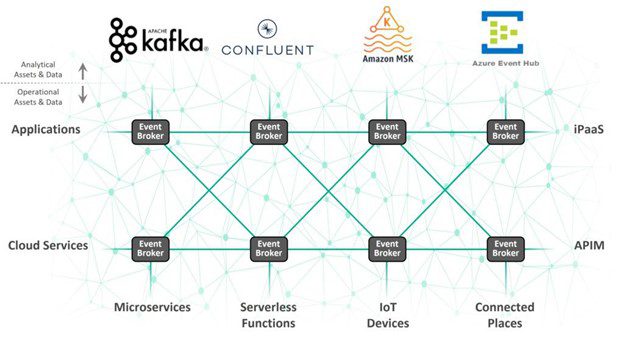
While the difference seems subtle, the key points are in the benefits you get routing data across an event mesh. A Kafka Mesh helps organizations in four ways.
- Bridges the many different flavors of Kafka that exist in most organizations. Flavors arise as different teams deploy Kafka clusters on prem and in different clouds and with different configurations. Using an Event Mesh does this in such a way that both order preservation and fine-grained filtering protect your Wide Area Network bandwidth and applications.
- Tames Kafka complexity that arises with moving data between Kafka instances. It allows topics to route events a lot more efficiently and with a lot less technical bloat than adding more Kafka topics.
- Enables Kafka to function in analytics use cases or in applications where a log broker is better suited while allowing the mesh to serve operational use cases where a queue-based broker is better suited.
- Lets applications more easily connect into Kafka by providing an integration layer that supports a wide variety of APIs and protocols.
A Kafka mesh is a mesh of event brokers that treats Kafka clusters as producers and consumers, letting Kafka work best where it is needed but routing events across the organization regardless of application or protocol. Deployments are becoming more and more hybrid and multi-cloud. On-premises applications and some cloud services may be using Kafka, but how do you move events between them and solve the problem with the rest of your technology stacks?
Why a Kafka Mesh? Six Challenges with Managing Kafka Complexity
Solving challenges with global Kafka deployments sounds straightforward, when you look at them one by one. But as complexity grows, they become interconnected and bridging technology with a Kafka mesh becomes an elegant solution to a complex problem.
Hybrid cloud deployments
Hybrid and multi-cloud deployments are very common for organizations. Whether they have different business units operating their own technology stacks, acquiring new businesses, or have a strategy that chooses best-of-breed services across clouds – this pattern is needed. It results in Kafka instances running in local clouds serving the specific purpose they were built for, but when needing to connect services it becomes a big operating challenge that Kafka alone, wasn’t designed for. Especially as different locations may operate different flavours of Kafka.
The methods used to solve this challenge includes tools like Mirrormaker or Replicator, Brooklin. These can work partition by partition or filter regex expressions, but in practice the implementation and management of this approach is not smooth and needs ongoing support.
Interoperating with API Management Solutions
With API-first adoption evolving into event-driven APIs with AsyncAPI, how do you stream Kafka into the API services front end? This is done with integrations that can talk to Kafka via request-reply, and Kafka wasn’t built for that model and this makes building those interactions complex to get right at the scale that most large applications need.
Streaming to and from Connected Devices
As the number of devices at the edge grows exponentially streaming and fan out becomes a big challenge. This is generally using MQTT and can be facilitated with MQTT brokers plugged into Kafka. This as the same challenges as API gateways where the challenge is that C&C is not inherently supported in Kafka. Kafka makes a good tool for capture and analyze for getting data into the cluster but not good for distributed systems like IoT field applications or factory floors – especially as they need to connect to cloud services.
Filtering while Preserving Order
This is a challenge for all transactional systems. Kafka was designed for big data type systems where order is important, but not always important. For example, if a new order comes and is followed by a new order cancellation then these must arrive in sequence for processing. In Kafka these are maintained by putting he events into the same partition and as a result you can’t do filtering. If this same customer makes multiple different orders in different countries, then you cannot filter a single partition for all orders coming from a certain location. The solution is workboards with SQLK, Kstreams and other technologies you need to build into your system.
Replicating Between Kafka Flavors
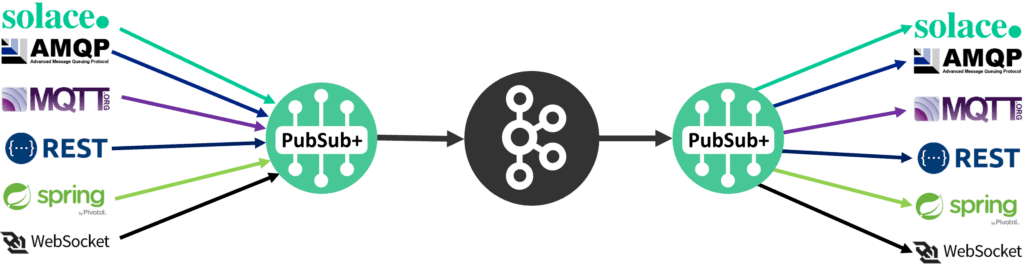
You may have AWS, Google Cloud, On premise, Confluent, and more. Each has their own replication tools and some may not have any, but you need to stream data between clusters in many applications. In essence, Kafka becomes a source and sink for the event mesh that routes the data between them and simplifies connecting the flavours. PubSub+ Event Broker is solving the problem of secure and lossless replication of specific topics across sites.
Managing Kafka and Non-Kafka Event Streams
While Kafka is used in a lot of new applications, most organizations have some legacy applications built in IBM MQ or have some applications build on other pub/sub technology like RabbitMQ or applications that use good old fashion databases. Kafka needs to interact with all of these requiring the development and maintenance of connectors, or the licensing of expensive connector frameworks.
How to Integrate Kafka Brokers into a Mesh with PubSub+ Platform
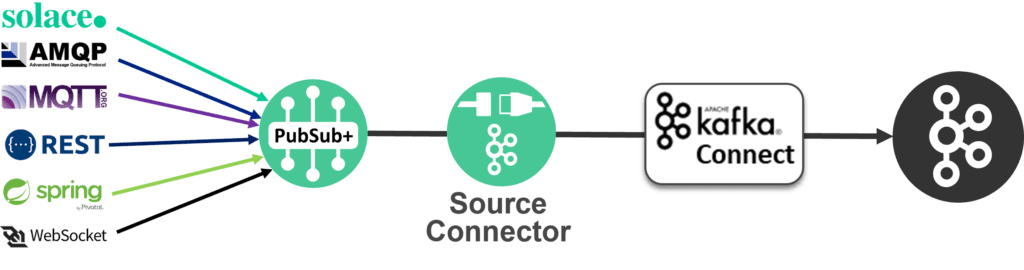
Solace offers two ways to connect to Kafka clusters: a Kafka bridge that’s integrated into PubSub+ Event Broker and set of connectors (for source and sink) that run in your Kafka Connect infrastructure.
Integrated Kafka Bridge
Solace PubSub+ Integrated Kafka Bridge works natively in the software event broker, and is the better option for most applications because it offers more operational simplicity and doesn’t need the third-party Kafka Connect layer. It can be configured directly in the event broker via the GUI, CLI or via the SEMP API, enabling bi-directional connectivity with no additional software to configure or manage. PubSub+ supports popular messaging APIs and protocols like AMQP, JMS, MQTT, REST, WebSocket and more so the connector can move any message to a topic (keyed or not keyed) on the Kafka broker.
Demo
Watch Rob Tomkins, principal product manager, as he demonstrates the Integrated Kafka Bridge in action:

Since the Integrated Kafka Bridge is integrated into the broker, alll necessary operations are native on the broker. The Kafka receiver takes the Kafka topic and modifies the metadata into a Solace Message Format (SMF) Topic and key. It also does the binary encapsulation of the payload. There is one receiver per Kafka cluster. In reverse the process is the same except that the Kafka sender generates XML or binary encapsulation. It supports most of the configurable topic features like ack mode or partitioning schemes.
For step-by-step instructions on how to use Integrated Kafka Bridge, please consult the technical documentation.
Source and Sink Connectors
- Solace PubSub+ Connector for Kafka Source uses the Kafka Connect API to consume PubSub+ queue or topic data events and stream them to a Kafka topic. The source connector uses Solace’s high performance Java API to move PubSub+ data events to the Kafka Broker.
Learn more or download it here.

- Solace PubSub+ Connector for Kafka Sink uses the Kafka Connect API to consume Kafka topic records, then stream the data events to PubSub+ event brokers as a topic and/or queue data event. From the sink connector, any Kafka topic (keyed or not keyed) sink record is instantly available for consumption by any consumer that uses one of the many languages, protocols or APIs that PubSub+ supports.
Learn more or download it here.