In previous blog posts I’ve introduced three ways of encoding message data: raw binary in the payload, some form of structured text such as JSON or structured data types. The last option I’d like to cover is making use of a third party data serialization system such as Apache Avro or Google Protocol Buffers (GPB).
These third party serialization systems offer some advantages that aren’t available with any of the other options: they give you an independent source for the structure of data. This source can be versioned and controlled just like any other source, but the changes are localized to the structure of the data, so changes can be made without changing or breaking any other code. Accessing the data is abstracted, providing a layer of automation which reduces the chances of errors in data access. For any large project with multiple developers using the same data format, this single source of data structure can have considerable benefits.
Is accessing the data as fast as reading data in a binary blob? Probably not, but the chances are the performance gains from using binary blobs are pretty marginal. Are they as easy to use and debug as Text messages? Well, if you write helper routines and applications, they could well be close to it.
How Data Serialization Systems Work
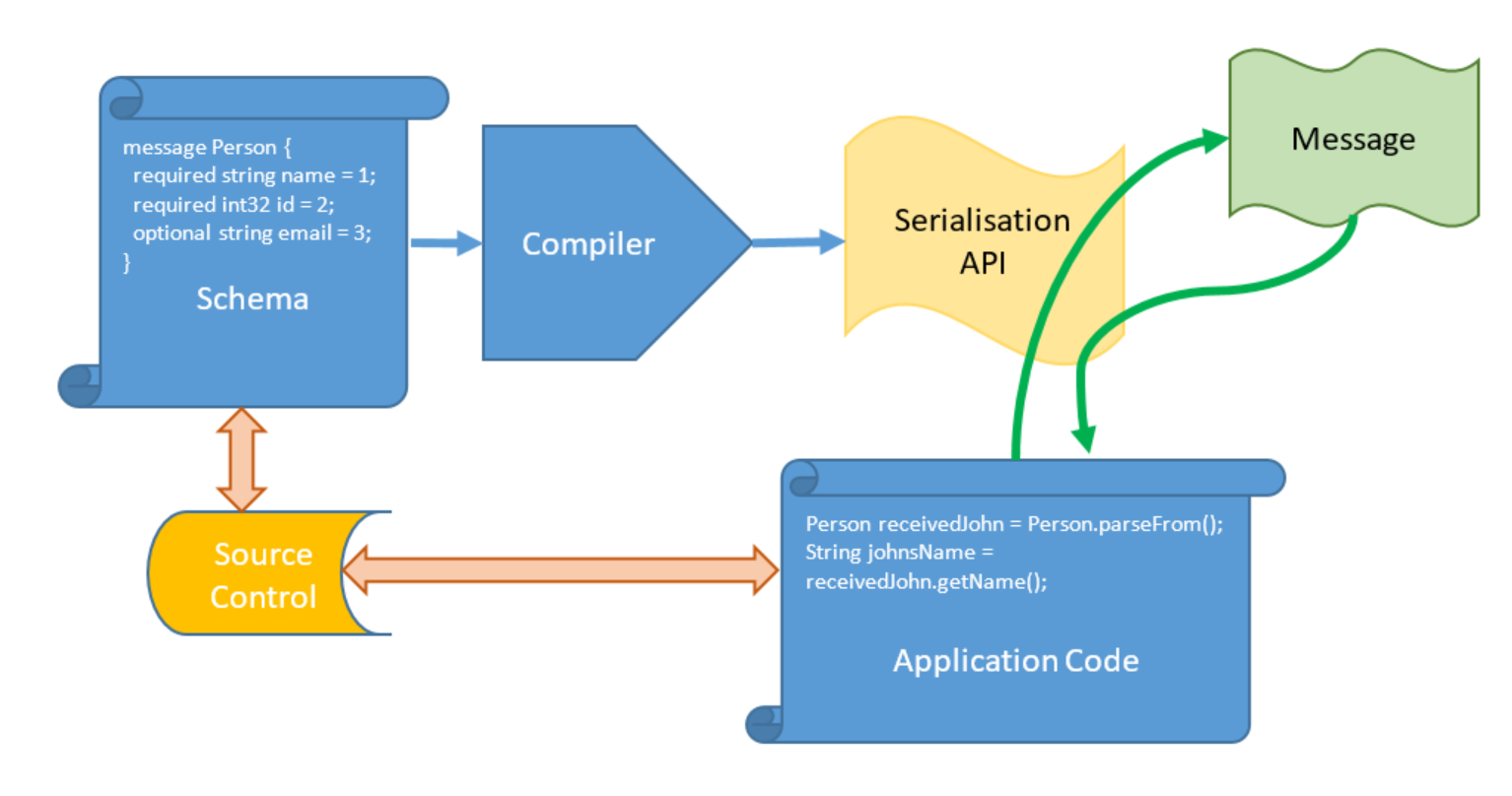
Data Serialization systems specify a data format language or schema that you write to describe the data format. The schema is then compiled, has its validity checked, and creates API calls (in whichever language you choose, GPB supports Java, C++, C#, GO and Python) to read data from and write data to the data format you’ve specified. In your code you don’t touch the serialized data directly, so your chances of accidentally breaking the structure by an injudicious read or write are slim: you only ever manipulate objects which are then serialized to the data format. Once received, the data is de-serialized back to an object with which you interact.
Some Example Packages
There are other serialization packages available, but two of the most popular GPB and Avro .
GPB emphasises speed and compactness. The source code is compiled so data types are fixed/static, and you have to manually assign field IDs. This example is shamelessly borrowed from the GPB website:
message Person {
required string name = 1;
required int32 id = 2;
optional string email = 3;
}
Apache Avro, on the other hand, emphasizes flexibility. Types are dynamic, fieldIds do not need to be assigned and reading and writing is accomplished via a JSON schema. Again, shamelessly borrowed from the Avro website:
{"namespace": "example.avro",
"type": "record",
"name": "User",
"fields": [
{"name": "name", "type": "string"},
{"name": "favorite_number", "type": ["int", "null"]},
{"name": "favorite_color", "type": ["string", "null"]}
]
}
Manipulating the data
Once the data structure is defined, the source code is compiled, which generates an API in our language of choice. This API allows us to manipulate the data. Google Protocol Buffers emphasise speed and compactness. The source code is compiled so data types are fixed, and you also have to manually assign field IDs (from the GPB website):
Person john = Person.newBuilder()
.setId(1234)
.setName("John Doe")
.setEmail("jdoe@example.com")
.build();
Serializing the data
OK, we’ve created some source code to describe the data, used that to automatically create an object definition, and created and populated an object representing our data. Now it’s time to do the actual serialization: take the object and create some bytes to represent it.
Your serialization package will provide various API calls for this, for instance GPB provides:
byte[] toByteArray(); void writeTo(OutputStream output);
So, for example, to use a byte array:
Person john = Person.newBuilder()
.setId(1234)
.setName("John Doe")
.setEmail("jdoe@example.com")
.build();
byte[] payload = john.toByteArray();
It’s now pretty simple to use this as the binary attachment to a Solace message:
BytesMessage msg = JCSMPFactory.onlyInstance().createMessage(BytesMessage.class); msg.setData(payload);
It’s as simple as that.
Getting the data back
When we receive the message we’ll need to make use of the de-serialization API to populate an object corresponding to our data, which we can then manipulate:
Person receivedJohn = Person.parseFrom(rcvdMsg.getData()); String johnsName = receivedJohn.getName();
And that’s it: GPBs hooked up to your Solace Messaging.
Other considerations
It’s worth thinking about how you’ll deploy and manage your data serialization package artefacts. Your data format will evolve over time. While the authors of the packages have recommendations (for instance, Google recommend you almost never use “required”), there are some things we can say with regard to messaging.
Tag the current data format with a version from your SCM system, and use this is in your topic:
/.../GPB/v1.2/...
With some clever scripting your build system should be able to populate this part of the topic string for you, so you never have to worry about data format version 1.3 arriving at code that’s expecting version 1.2.
This isn’t to say you shouldn’t put normal checks in your code to make sure it has been read correctly. If you want to be very conservative, you could put a version tag in the format:
required string version = <build script variable>;
This can then be checked on message reception. This is perhaps one instance where required is a good idea!
Conclusion
That’s it, pretty easy when you know how. Data Serialization Packages provide a compact, high performance way of managing data formats. The underlying format is abstracted, so that you never touch the data itself directly. And by having a separate source file for the format, you have a central, golden reference for what the data format should be.
Using these packages with messaging is pretty simple: just call the serialization API serialize call to create a message payload, then attach this to the message. On reception, simply deserialize via the API and you’ll have an object populated with the message.
Explore other posts from category: DevOps



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.