Read the post in プレスリリースを読む 보도 자료 읽기
A common way of overcoming limitations in application performance is to parallelize computation. When the application in question is receiving events or data to process, this is known as consumer scaling. Consumer scaling refers to running multiple, parallel instances of a consumer application instance to allow concurrent processing of incoming messages or an event stream.
There are several different ways to achieve consumer scaling, the most notable being the enterprise integration pattern of competing consumers, a communication pattern that allows multiple consumers to process messages concurrently. This allows for the scaling of consumer processes, improving overall system performance through parallelization.
In Solace PubSub+, there are multiple ways of achieving consumer scaling, and choosing the right approach depends on your application requirements. Broadly speaking, these fall into two categories: round-robin delivery and sticky load-balancing. In this article I’ll explain the various choices available.
Round-Robin Delivery
The first and easiest method of implementing the competing consumers pattern for scaling is to load-balance incoming messages between all consumers in a round-robin fashion. This ensures a uniform, even distribution of the load across all consumers. This pattern is favourable when there is no requirement to maintain message order. Every message must be processed independently of all others; or if there is some dependency, the consumers have some shared state to coordinate this dependency (e.g. shared back-end database, in-memory data grid).
One major advantage of round-robin delivery is that it is dynamic, and almost infinitely scalable, with hundreds or even thousands of consumers able to join and have the events or messages spread across all of them; and consumers can be added or removed as the processing load dictates.
Shared Subscriptions – Non-Persistent QoS Round-Robin
For non-persistent (or Direct messaging) quality of service, Solace supports a feature called shared subscriptions, which allows multiple consumers to dynamically join and unjoin from a group. This pattern/feature is particularly useful for back-end components that are processing service requests and responding (request-reply), as this pattern commonly uses Direct, non-persistent QoS.
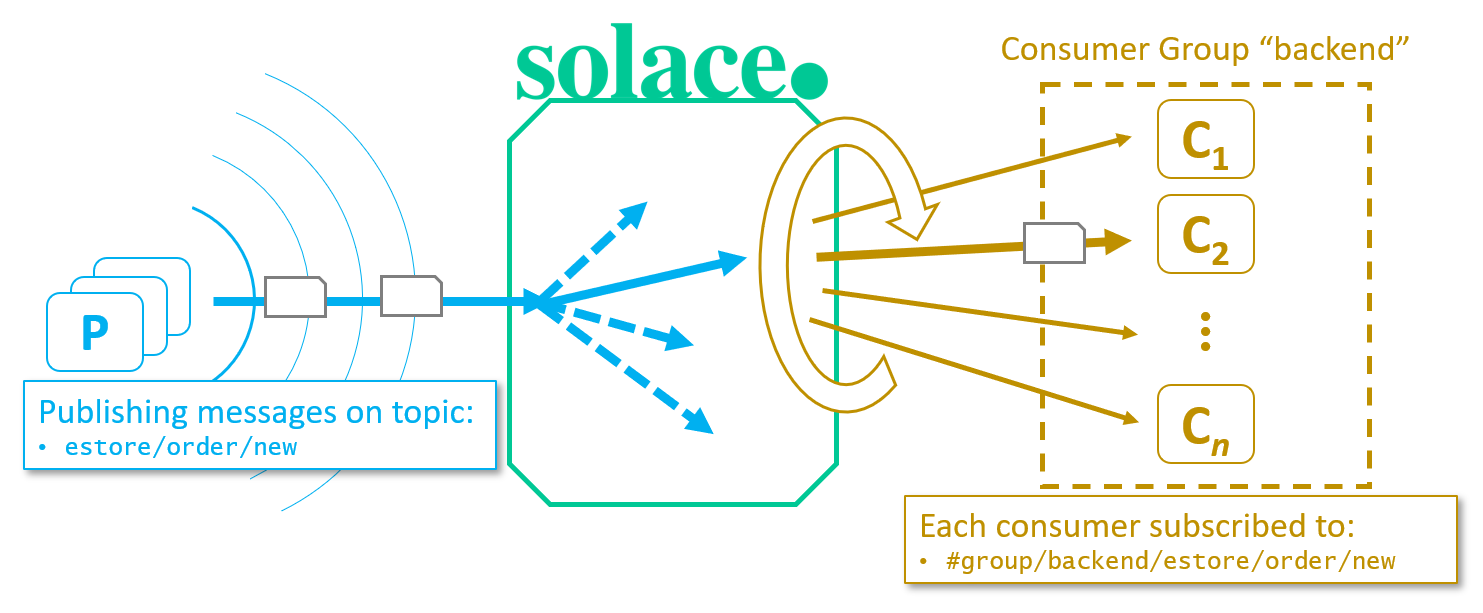
Fig 1: Non-Persistent Round-Robin delivery with Shared Subscriptions
To use the shared subscriptions feature, a consumer subscribes using a special topic to indicate which group it wishes to join, and the desired topic: #share/<ConsumerGroupName>/topicFilter>/, e.g.: #share/backend/estore/order/new would add a consumer to group “backend”, subscribed to estore/order/new. Whenever any publisher publishes on the topic estore/order/new, Solace PubSub+ will deliver a copy of that message to one consumer in the “backend” shared group.
Because this feature utilizes the publish-subscribe (pub/sub) pattern for message delivery, a second group of consumers could also be configured to receive a copy of the messages in parallel by subscribing with a different shared group name.
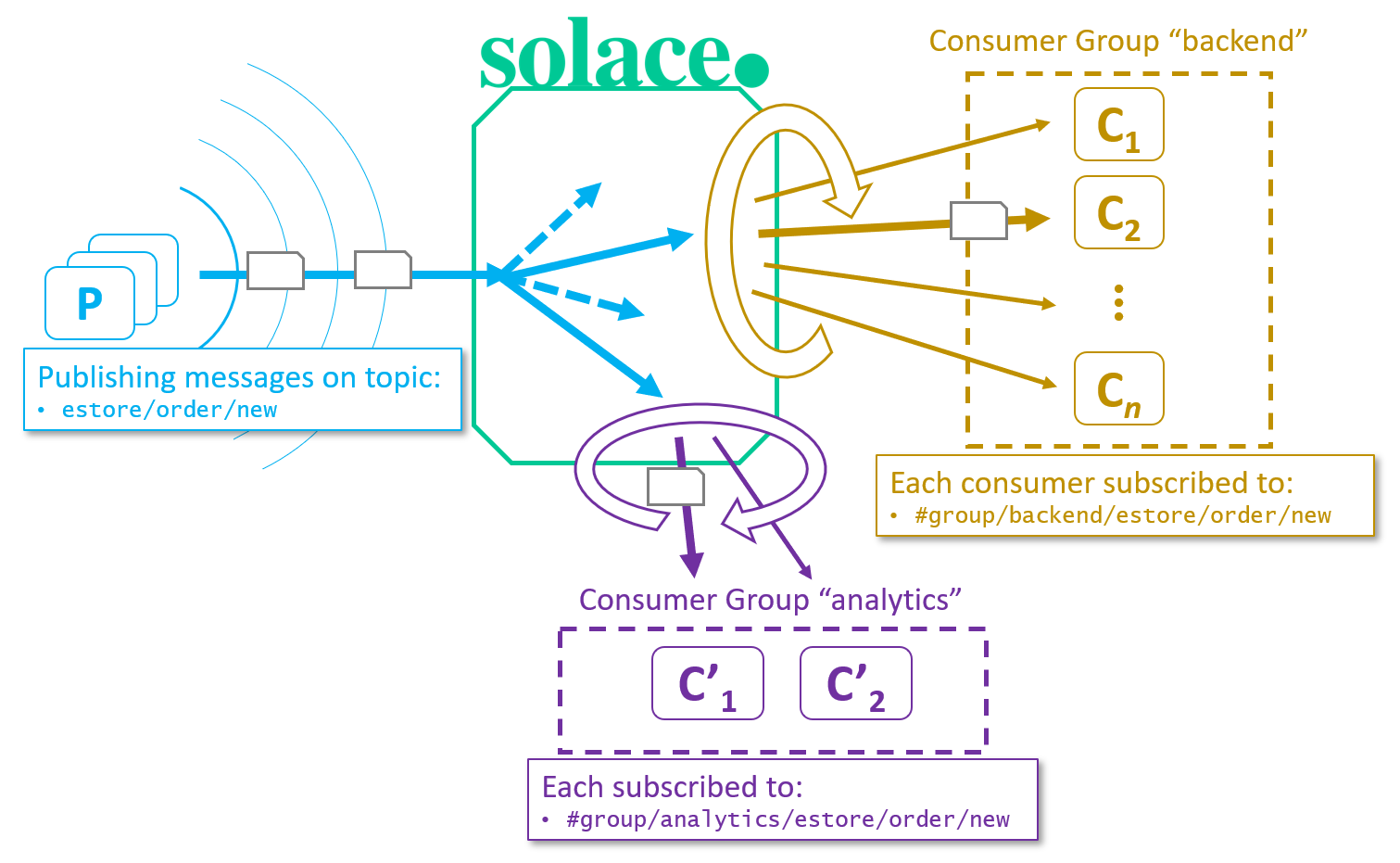
Fig 2: Multiple Shared Subscriptions Groups
As shown in the figure above, this would also deliver a copy of every estore/order/new message to one consumer in the “analytics” group as well, without having to change any code in the publishers or original consumers. This is the power of the publish-subscribe pattern.
Note that the concept of Shared Subscriptions is not a Solace-only feature. Though not part of the MQTT 3.1.1 spec, Shared Subscriptions are often used with the lightweight, pub/sub protocol MQTT for IoT applications. As Solace supports MQTT natively, the equivalent subscription pattern would be: $share/<ShareGroupName>/<topicFilter>.
For more information on configuring your application to use Shared Subscriptions, check out Shared Subscriptions in the Solace PubSub+ documentation.
Non-Exclusive Queue – Persistent QoS Round-Robin
For persistent (or Guaranteed messaging) quality of service, Solace utilizes a feature known as a “non-exclusive queue”. A queue is a persistent endpoint for storing data: all messages that land on the queue are persisted to disk and guaranteed to be delivered to a consumer, regardless of failure conditions (e.g. network outage, power outage, high-availability failover, etc.). And a non-exclusive queue allows multiple consumers to bind to it and to receive messages in a round-robin fashion.
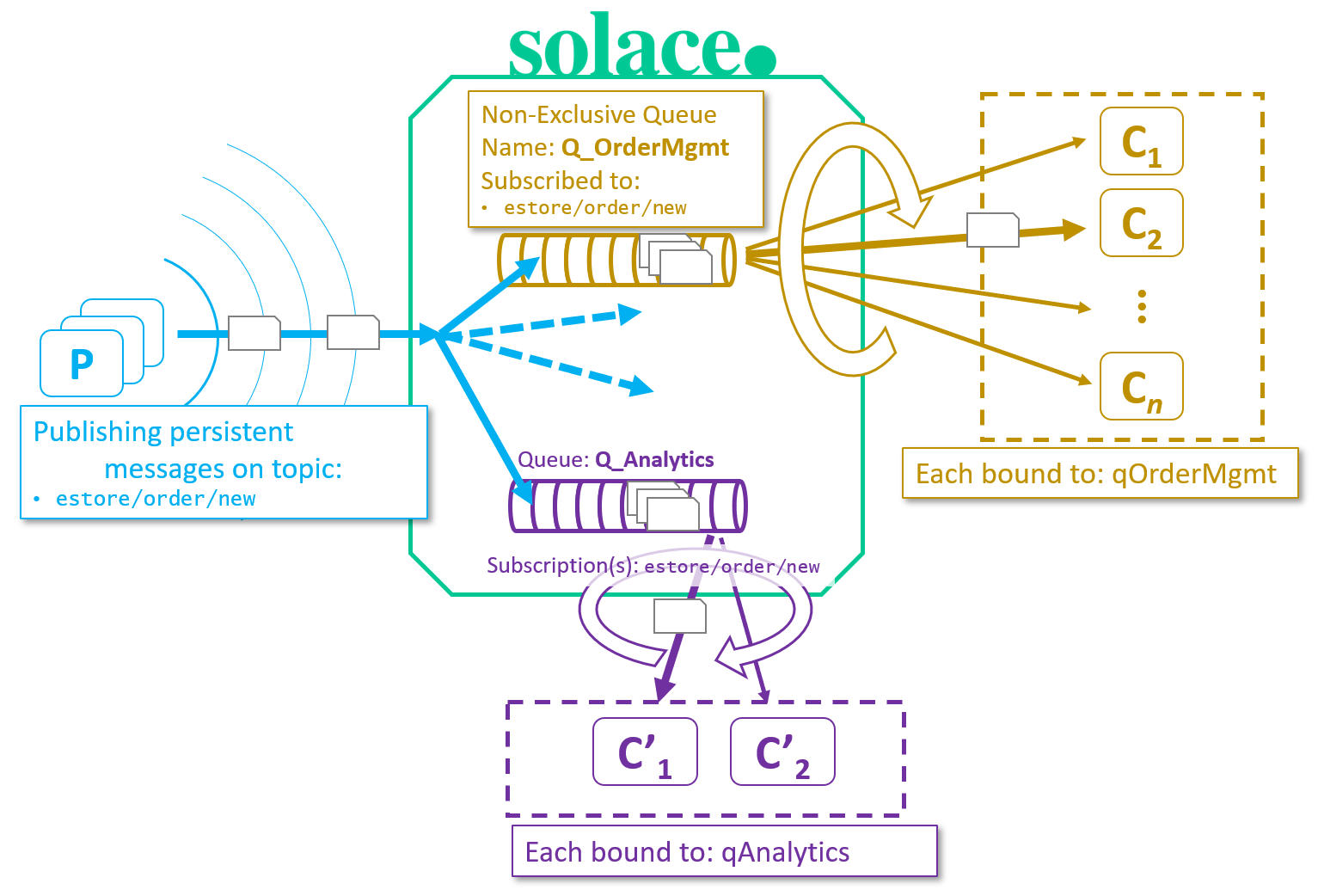
Fig 3: Persistent Round-Robin delivery with Non-Exclusive Queues
Non-exclusive queues also allow consumers to join/unjoin dynamically (to a maximum of 10,000 consumers), allowing processing to scale up and down with no impact to other consumers, such as a rebalance.
To use persistent round-robin delivery in Solace PubSub+, configure one non-exclusive queue per group, and subscribe each to the topic (or topics) required. In the above example, two queues are configured, and each subscribed to estore/order/new. Whenever a publisher sends a message that matches a queue’s subscription, a copy will get placed in that queue, and delivered to exactly one consumer in each group. (NOTE: Solace’s persistent store is referenced-based, so only a single copy of the message is ever persisted to disk). Consumers simply bind to their queue to receive messages and do not have to worry about subscribing Directly to the topic, because that is configured on the queue.
When a persistent consumer unbinds from the queue, it must first stop() its persistent Flow to stop receiving new messages, and then ensure that it has ACKnowledged all outstanding/in-flight messages that it has received. This ensures that other consumers do not receive redelivered messages when the consumer unbinds.
For more information on persistent consumers and receiving Guaranteed messages, check out Basic Operation of Guaranteed Messaging and Receiving Guaranteed Messages in the Solace PubSub+ documentation.
Sticky Load-Balancing, or Keyed/Hashed Delivery
It is sometimes required that published events or message data containing a particular attribute(s) – e.g. customer ID, order ID, product ID, etc. – are always processed in the original order that they were produced in. This requirement means all related messages are delivered to the same consumer. That is, messages contain a key such that subsequent messages with the same key are always delivered to the same consumer and processed in order. This ensures that changes or updates regarding the particular attribute are always processed sequentially.
The term “consumer groups” was popularized by Apache Kafka, a log shipping application. In Kafka, consumer groups are groups of consumers that form a “logical consumer” to read from a single topic. A consumer in a Kafka consumer group connects to one or more partitions inside a Kafka topic, and reads sequential log records from a partition file. When records (“messages”) are appended to a partition in a Kafka topic, the partition is chosen by a key attribute defined by the publisher.
This provides a form of “sticky load-balancing” such that records with the same key end up in the same partition and are therefore processed by the same consumer.
The same (and better) functionality can be achieved in Solace PubSub+ using a hierarchical topic structure, and Solace’s advanced topic filter capabilities.
Using Solace Topics for Partitioning
When defining your topic hierarchy or taxonomy, designate one level of the topic hierarchy as the partition key. For example, for an order entry system, your topic structure could be:
estore/order/[ORDER_ID_PARTITION_KEY]/more/specific/rest/of/topic
The key is typically a hash of an important attribute of the published data, as discussed above. In our example, the keyed attribute would be the Order ID, a large integer. Let us assume for simplicity that the partition key is <Order ID modulo 8>: an integer between 0…7, giving 8 possible values, for 8 possible partitions. Make the total number of partitions as large as you would ever need, as topics and subscriptions are “cheap” in Solace PubSub+.
Next, configure as many queues as the number of likely future consumers in a “consumer group”. You could configure the exact same number of queues as consumers, but as queues in Solace PubSub+ are “cheap” as well, it makes sense for easier future flexibility to configure a larger number of queues than initially needed.
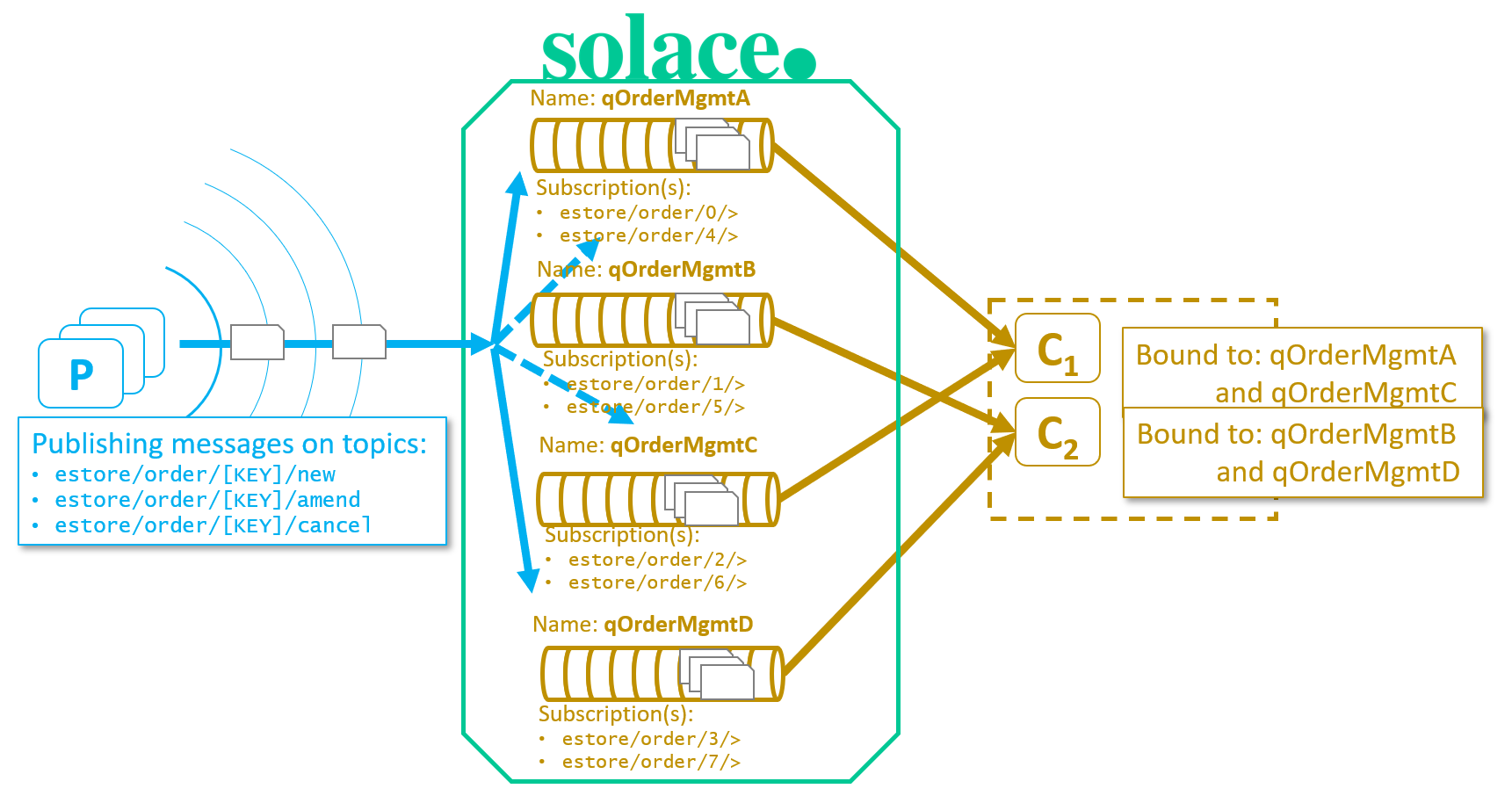
Fig 4: Persistent Sticky Load-Balancing with Topic Partitions
As shown in the example diagram:
-
- There are 4 queues configured, each subscribed to 2 of the partitions.
(Note the use of multi-level wildcard “>” at the end of the subscriptions, after the partition key level) - There are only 2 consumers, each receiving data from 2 queues; therefore, each consumer is receiving 4 partitions’ worth of data.
- There are 4 queues configured, each subscribed to 2 of the partitions.
In this eStore example, if the customer gateway/API was enhanced to allow different types of order events (e.g. new, amend, cancel), it would be desirable for events related to the same Order ID to go to the same backend processor. This would ensure a “new” order isn’t received by one processor, and the “cancel” got routed to another. Whenever an order type event is generated by a publisher, the 3rd level of the topic (in this case) is used to key the message to a particular partition by taking the modulo 8 of the Order ID.
It is possible to have a very large number of partitions using this approach with essentially no change to the architectural pattern, using topics to define the partition. This allows future flexibility by being able to add more consumers into the consumer group by rebalancing the key subscriptions across a new number of queues.
For more advanced discussion on the sticky load-balancing pattern in Solace PubSub+, check out “Sticky Load Balancing” in Solace PubSub+ Event Broker by my colleague Mat Hobbis.
Appendices
Appendix A: Partition Future Flexibility
Kafka partitions are implemented as log files, and therefore require an open file handle to maintain. This puts a practical limit on how many partitions you can create.
As Solace partitioning is done using topics and topic subscriptions, choose a hash/key function with a very large modulo, as topic subscriptions are generally not a constrained resource in the Solace broker. This lightweight partitioning allows for exceptional scalability on the consumer side.
For example, choosing a key function as modulo of 360 allows for nicely balanced consumer groups of size 2, 3, 4, 5, 6, 8, 9, 12, 15, 20, 24, … etc. But all these topic subscriptions could be mapped to a small number of queues to start.
Appendix B: Multi-Key Hashing
As Solace supports a hierarchical topic structure, it is possible to have a single topic encoded with multiple keys. For example, both “Order ID” and “Customer ID” could be different levels of the topic hierarchy. This allows different groups of consumers to determine which attribute they wish to key on to receive in-order.
In Kafka, this would require double-publishing to different Kafka topics, with a different partition key for each.
Appendix C: Partition Overdrive & Low-Priority Reject
One advanced feature of Solace PubSub+ that may be appropriate is the persistent queue feature of low priority rejection. This allows an administrator to configure a limit as to how deep a queue can be before it starts rejecting low priority messages. This allows an over-driven partition to throttle new messages.
In our previous example, “new” messages would be low priority, and “amend” and “cancel” messages would be high priority. This would ensure the latter always end up in the correct queue; but “new” messages would be rejected if the queue is too full, and the publisher would recompute the hash key and resubmit to a different partition.
For more information on configuring low-priority rejection, see Enabling Rejection of Low-Priority Messages in Solace PubSub+ documentation.
Explore other posts from categories: For Developers | Products & Technology



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.