Update: In 2023 Solace added support for partitioned queues as a means of consumer autoscaling. This blog post covers a lot of the problems and mechanics of managing queues when you need service scaling and is a great reference, but when you’re done here check out How Partitioned Queues Enable Consumer Autoscaling in Microservices Environments.
“Consumer Groups with Hashed Delivery”, “Load Balancing with Subscriber Affinity” or “Sticky Load Balancing” are all interchangeable terms for the same message or event routing pattern. The pattern allows the user to load balance a message or event stream over a variable number of receiving consumers in order to cope with processing the load. A specialisation of this pattern, over general load balancing, ensures that the event order is maintained for sub-streams within the aggregate event stream.
The typical use case here is within a microservices-style pipeline where you need to scale a portion of the pipeline that does some heavy lifting while maintaining the order. In this case, the consumer count for the stage of the pipeline being scaled is controlled by something like CPU utilisation for each service. When the load increases, more consumers are started so that the load can be shared and the headroom for the peaks can be maintained.
Examples of this type of requirement are many, but for clarity we will examine only one. The example here is an online storefront that must cope with high peak loads, for example, during the Black Friday period, but much lower transaction volumes, loads, and processing demands in general. In this case it is not viable to provide the peak processing capability all year round because it eats into profitability. It is much better to design a flexible architecture that allows the processing capacity to be added and removed based on a demand forecast or some measurable indicator metrics.
This is illustrated in the following diagram.
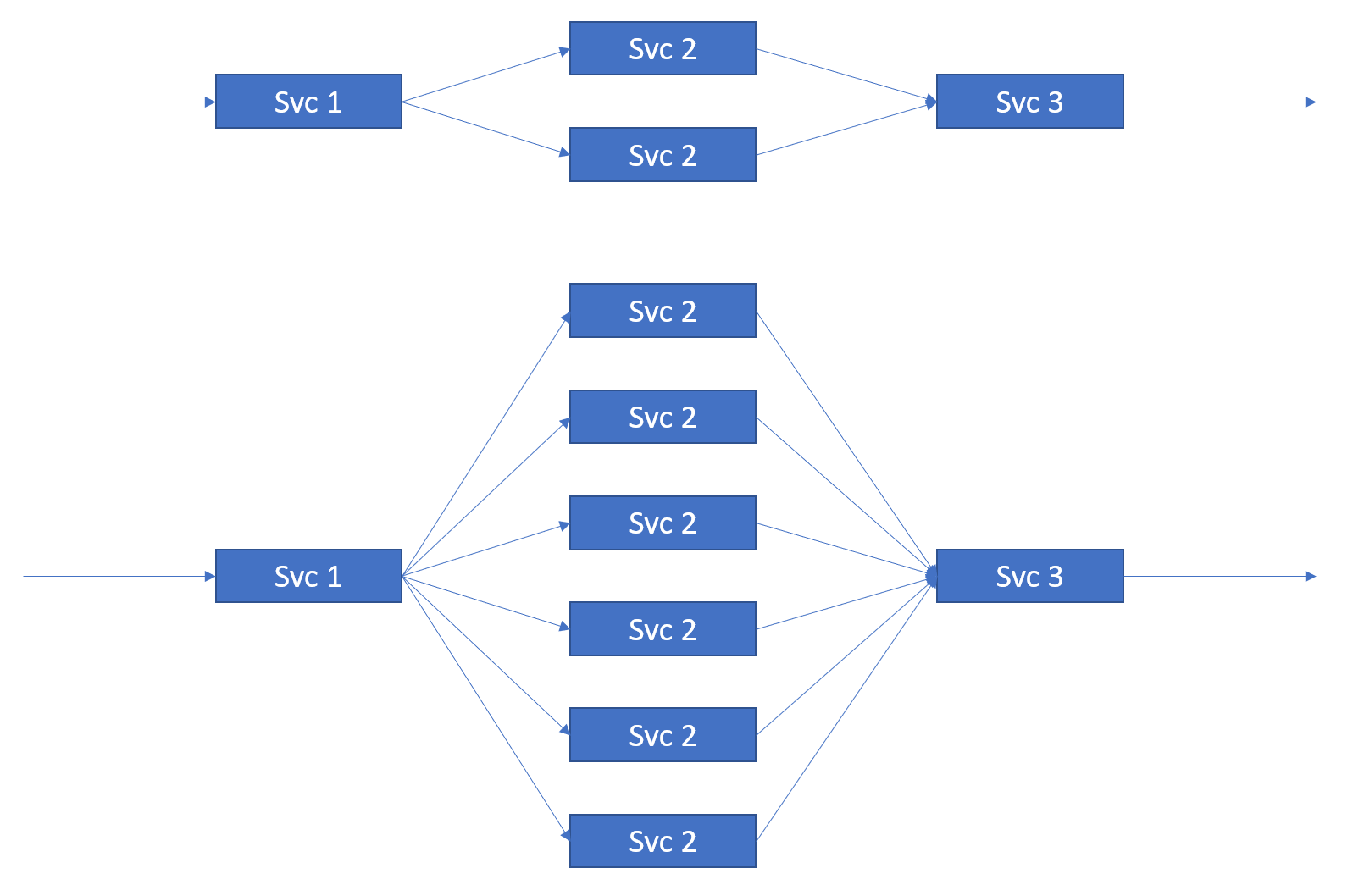
Microservice scaling (Top = Normal, Bottom = Peak)
As stated above, key attributes of the service shown in the figure are:
- The system should be able to change the number of instances of Svc 2 dynamically at run-time.
- The order of events is important for sub-streams within the aggregate stream.
The second attribute means that the sub-streams need to be keyed in some way so that all events belonging to a given sub-stream are serviced by the same instance of Svc 2. If this is not done, then serial events on a given sub-stream may be executed in parallel, by different instances of Svc 2, leading to a possible change in the event order. This could be problematic if, for example, the account debit was applied before a previous account credit and funds were declined or a quantity was changed from 1 to 10 but the events were reversed and only 1 item was ordered.
The next figure compares the standard round-robin load balancing with the hashed or keyed round-robin load balancing. In the figure, you can see an aggregate stream composed of two component sub-streams (in green and yellow).
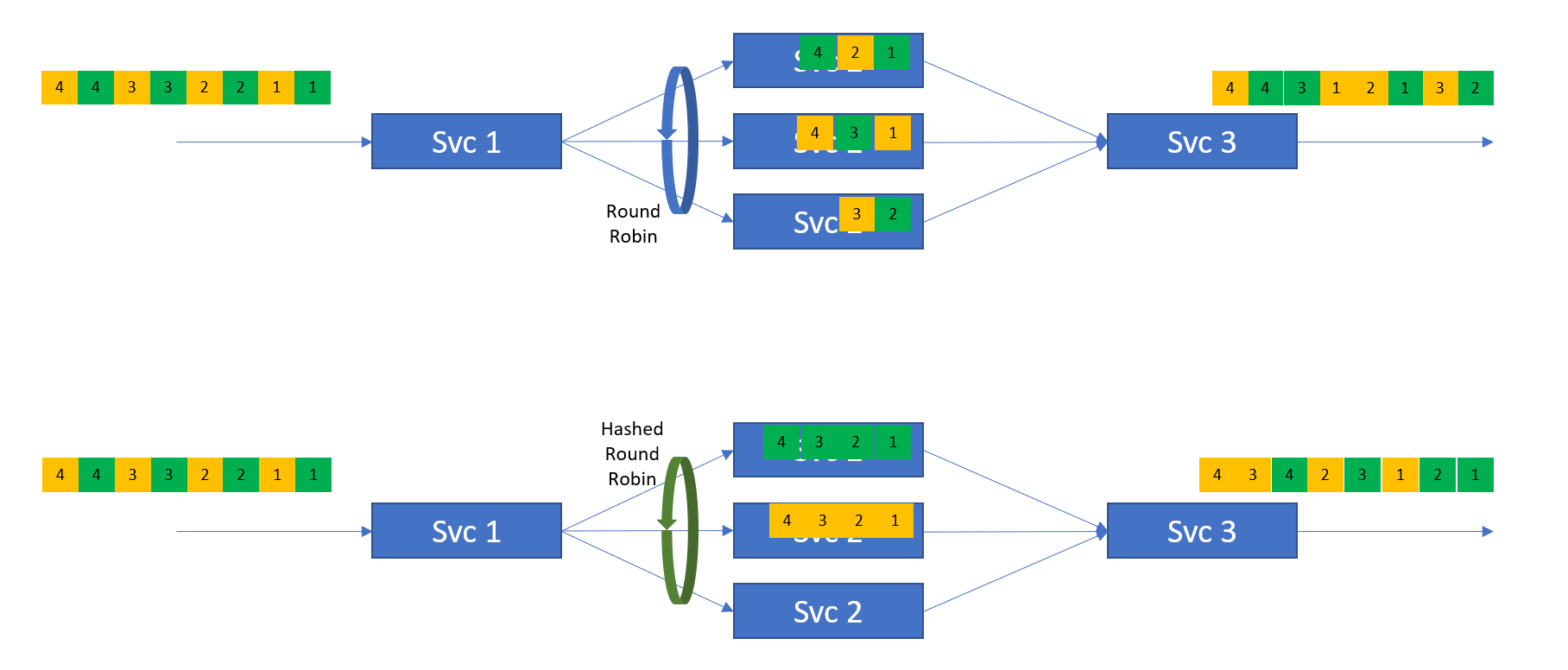
Comparing standard round-robin load balancing with hashed or keyed round-robin load balancing
The upper part of the figure shows the use of standard round-robin load balancing. Using the standard round-robin distribution techniques in Svc 1 to spread the load across the multiple Svc 2 instances leads to a reordering of events. As there is no awareness in the system of the sub-streams within the aggregate event stream, it can lead to events within a stream becoming mis-ordered. In the example, you can view Event 1 as a relatively “heavy” event in terms of processing. As we spread the events across the available Svc 2 instances, the Events Green 1 and 2 end up on different Svc 2 instances. As Event 1 is a heavier weight event than Event 2, it takes longer to complete, meaning Svc 3 sees Event Green 2 before it sees Event Green 1. This is problematic for many use cases.
The lower part of the figure uses sub-streams or some other key information, e.g., stream.colour(), to map a sub-stream to a given instance of Svc 2. In the figure, all Green events are serviced by the top instance of Svc 2 and the Yellow stream has all events serviced by the middle Svc 2 instance. In this manufactured example, the 3rd Svc 2 instance is unused BUT the order of events within each of the sub-streams is maintained, that is, while the arrival of individual events at Svc 3 may not be exactly the same as the arrival of events at Svc 1, for each sub-stream Svc 3 will see the event in the original published order—Events 1, 2, 3, 4, etc.
The lower part of this figure is the behaviour we need to satisfy this eventing or messaging pattern as it maintains the order for the keyed/hashed streams.
The Mechanics of Load Balancing
Most people with a basic knowledge of event-driven architecture, middleware, and JMS should be familiar with the concept of Non-Exclusive Queues. Non-Exclusive Queues provide the above-described standard-based load balancing and are commonly used when people attempt to scale microservices. The following figure shows this.

Use of Non-Exclusive Queues to connect (micro-)services
This is a fairly standard pattern. However, this implementation suffers from the ordering problems illustrated in the previous section.
To provide hashed or key load balancing, Solace can make use of its Queue Subscription capability to bind a hashed or keyed subscription to an Exclusive Queue that will service one instance of the next service in the service pipeline.
Note that the queue service type chosen is ”Exclusive”. This is because the messages from this queue should go to a single consumer and not be load balanced. The Exclusive queue type will also help with resilience and microservice failures, which is covered later in this blog post.
The following figure shows this arrangement.
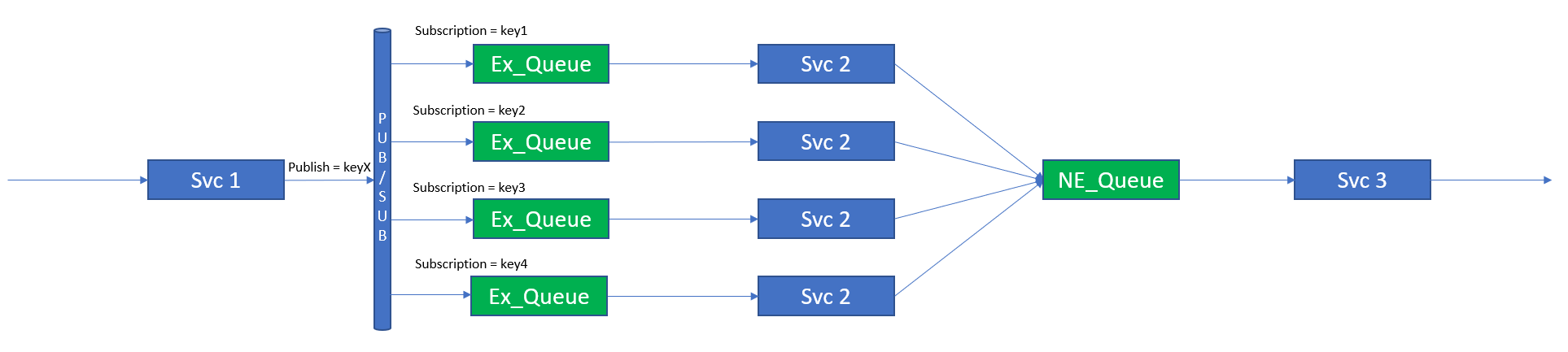
Hashed/keyed load balancing using queues and queue subscriptions
In the figure, you can see that each instance of Svc 2 subscribes to its own queue and that each queue subscribes to a hash or keyed topic. The Svc 1 instance is then changed to publish onto the topic KeyX where X depends on the sub-stream that the event belongs to. In this way we can be sure that all events that map to key1 will be processed by the first instance of Svc 2 and the order of all the events that map to key1 will be maintained.
There is no guarantee of order between events on key1, key2, key3, etc. This “Key” is the “unit of order” and therefore sub-streams, for which order is important, should be mapped to a single key (though it should be noted that multiple sub-streams can be mapped to the same key).
The mechanics of deriving this key will be application specific. The derived key will be a level in the topic hierarchy that the queues, as part of the load balance group, subscribe to. The publisher will be responsible for attaching the correct key, in the form of a topic prefix.
As each queue can support multiple subscriptions, it is perfectly reasonable to have a larger “key space” than there are queues. For example, a key space of 100 values could easily be spread across 10 or 15 queues.
Publishing Keyed or Hashed Events
The mechanism for generating the Key will be different for each application and will inevitably depend on how sub-streams are identified. Examples might be:
- All events for a given order ID.
- All events for a given Account ID.
- All events from a given source.
For example, if we want to have an event order for any given account ID and we have millions of accounts, then we need a way of converting the large set of accounts into a smaller, manageable set of “keys”. This process is referred to as ”hashing”.
In order to hash our accounts, we might decide to take the account event, each with a numeric account number, choose to extract the account ID from the event, and then produce a modulo 100 of the account ID to derive the key. This will give us a “hashed” key value within the range of 0 – 99 depending on the account ID provided. While a relative operation, it ensures that all events for “account x” are hashed to the same key value every time and will therefore be processed by the same consuming service.
A conceptual representation of such a hash function is illustrated below. The figure shows an event being passed to a hash function that extracts the accountID property from the message and then applies a “modulo 100” operation. The function then uses the output to amend the topic that the message will be published to by applying a prefix—in this example “56”, as this is the modulo of the account ID.
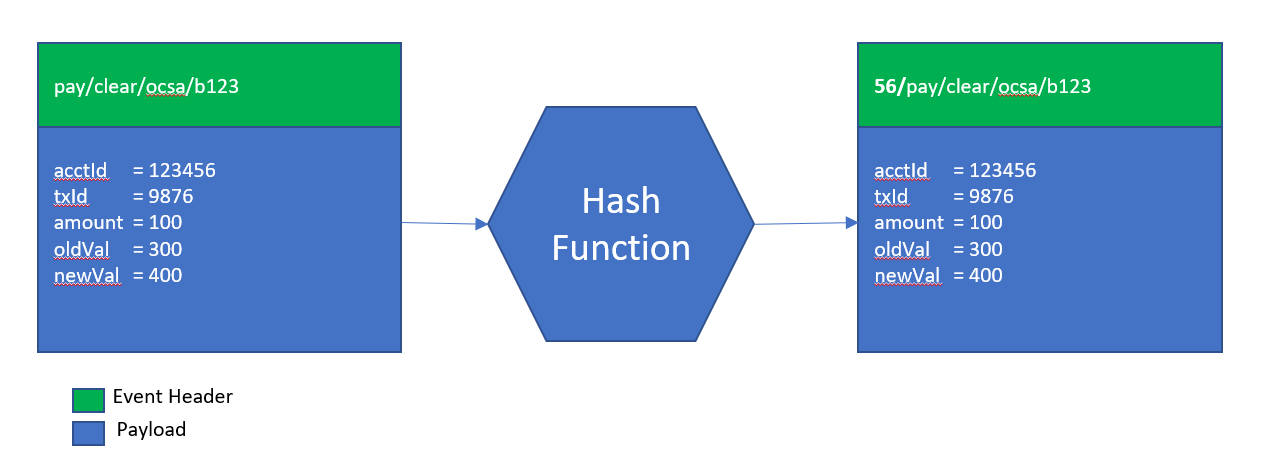
Conceptual hash function and topic prefix
As each queue can support multiple subscriptions, it is perfectly reasonable to have a larger “key space” than there are queues. For example, the key space of 100 values could easily be spread across 10 or 20 queues. In this case, the number of queues should be mapped to the maximum number of consumers required to process the load rather than any other metric. This is illustrated below.
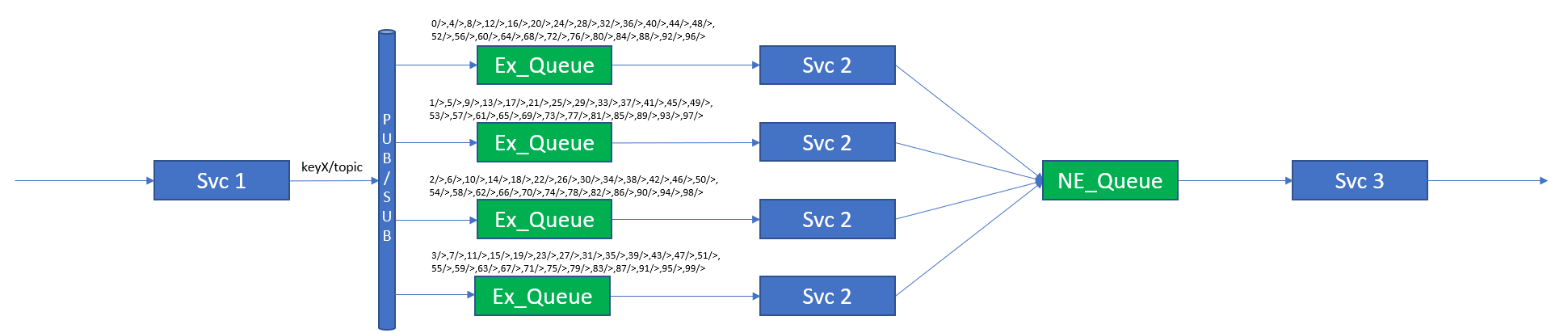
Multiple subscriptions per queue — improved decoupling
At first casual glance, it would appear that this is a wasteful strategy as it seems to waste “topic subscriptions”. However, a key benefit of being able to do this is that it truly decouples the publisher and subscriber. It is possible to stop the publisher service(s), add more queues and consumers, re-stripe the topic subscriptions, and then restart the publisher service(s). No change of configuration is required at the publisher.
The discussion so far has illustrated an application pattern for a publisher that can provide keyed or hashed sub-streams to downstream services. The publisher provides messages or events which are distributed in a load balanced manner with the order preserved within each sub-stream.
So now that we have event sub-streams ordered, how do we deal with variable consumer numbers?
Scaling the Consumers Dynamically at Run-Time
One of the attributes of the service that we have to cover is the ability to scale consumers up or down dynamically while the service is running. We have already determined in the previous section that adding consumers, queues, and rebalancing topics requires that the publishers be stopped in order to affect the change.
The requirement to stop the service arises because trying to rebalance topics means that a topic must be added to another queue and removed from the original queue. This risk duplicates messages. If we decide to delete the topic first before adding it to the new queue, then we risk message loss.
Neither message duplication nor message loss is acceptable, so adding queues and rebalancing topics is NOT the solution.
Though the number of queues and the distribution of topics is fixed, the number of consumers is variable within set bounds. The bounds of the service should be that the number of consumers is less than or equal to the number of queues that are part of the load balanced group. As all queues must be serviced, the consumers may have to bind and consume from more than 1 queue. This is illustrated below.
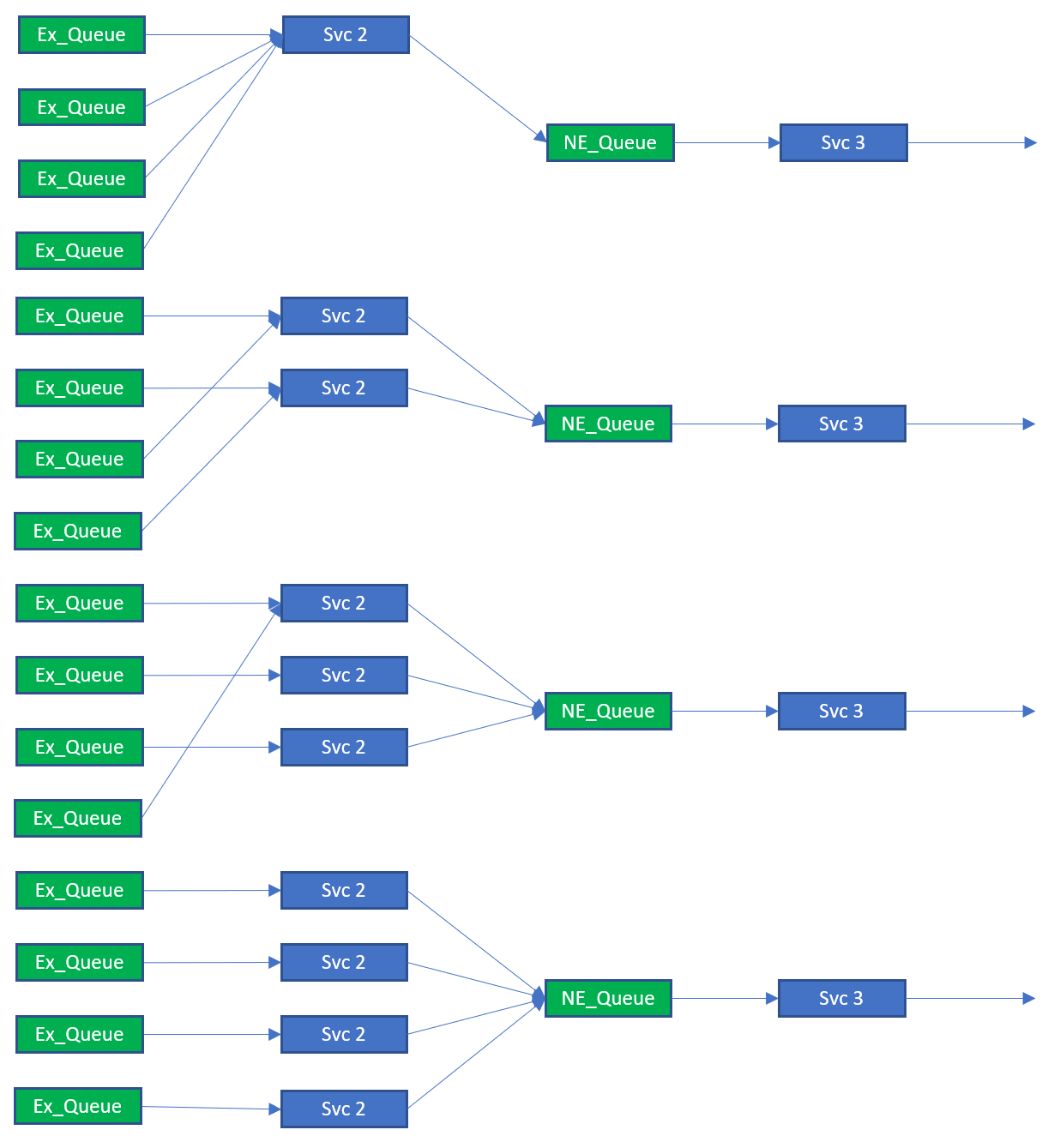
ncreasing Service 2 count from one to four
Ideally the ability to scale consumers, as illustrated above, would not require a restart and reconfiguration of the consumer group. Changes like this should, as already stated, be dynamic and occur while the system is running. The system also needs to cater for scaling down the service from 4 to 1, in the example shown in the figure, without the loss of system availability and any messages.
Removing a consumer as a consequence of scaling down the service is likely to be indistinguishable from the loss of a consumer due to the microservice failure. In this regard, the service will also provide redundancy for a single service instance failure assuming there are always two or more instances running.
Property of Exclusive Queues
It turns out that we can use one of the main properties of exclusive queues to allow multiple consumers to bind to a queue but only have the queue service the primary active consumer. This allows us to have each client bind to every available queue and to designate certain queues as primary queues for which it is responsible. For each of the remaining queues in the set, the consumer will act as a backup consumer in case the primary consumer is not available.
To illustrate the process, we will assume we have four queues served by up to four instances of Service 2. Initially, as we are not at peak load, there are only two instances of Service 2 running. We will illustrate the service instance failure and recovery, and that coping with the increasing event/traffic rate will increase the number of Service 2 instances to three. This is shown in the following figures where:
- Heavy lines are carrying event traffic.
- Light lines are not currently carrying event traffic.
- Solid lines indicate lines which the consumer believes it is responsible for, i.e., it should be the primary consumer.
- Dotted lines indicate the backup or secondary connections from the consumers’ viewpoint.
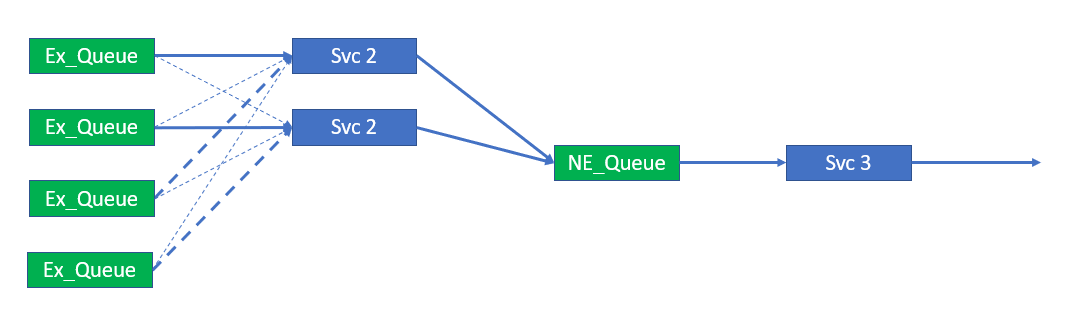
Two instances servicing four queues
In the figure, Instances 1 and 2 of Service 2 both bind to their respective queues as ”primary”, that is, Instance 1 binds to Queue 1 and Instance 2 binds to Queue 2. The two services also bind to every other queue as a “secondary” connection.
The “primary” and “secondary” designation refers to how the service instance client handles each connection:
- Primary connections are held for the entire time when the service instance is active.
- Secondary connections, in contrast, are periodically released and re-made. In this example, secondary connections are cycled every 60 seconds or so.
Secondary connections are cycled periodically so that primary connections can reclaim their status as the active connection for the queue.
In the example, the periodic release of the secondary connections means that irrespective of the startup order, within 60 seconds, the Service instances will service their primary queues. The remainder of the queues will be serviced by Service Instances 1 and 2 as each service “bounces” its secondary connection to the queue. Since at any one time any queue is only serviced by 1 consumer, the order is preserved for all event flows.
The next stage is to look at the failure of a running instance as shown in the figure below.

Two instances service four queues – Service failure
In this case, Instance 2 has failed and disconnected from the message or event broker. The normal behaviour for exclusive queues is to resume the service by sending messages to the next available client—Service Instance 1 in this example. No messages are lost, and the service restoration is very quick.
It is expected that in normal operations the failed service will be detected and restarted by the (micro-)services management environment. The figure below shows the restart of Service Instance 2.
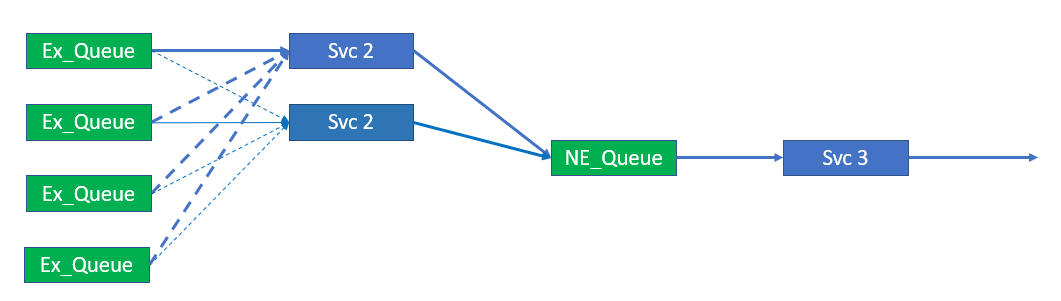
Two instances service four queues – Service recovery
The figure shows Service Instance 2 restarting and reconnecting. Note that at this point Service Instance 2 will not receive the traffic to process, even on its primary connections, until Service Instance 1 gives up its secondary connections as illustrated below.

Two instances service four queues – Traffic rebalancing
Once Service Instance 1 cycles its connections, we end up with Service Instance 2 processing the traffic once more.
During the day traffic rates increase. We need some way of determining this increase has occurred, for example we could base it on CPU utilization of the processes running. Whatever metric we decide to use we trigger an event that starts Service Instance 3. This is shown in the following figure.
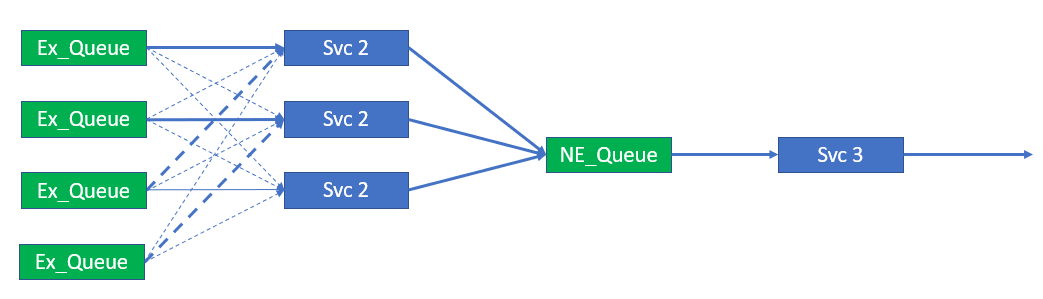
Three instances service four queues – Adding the 3rd service instance
As seen in the figure, adding Service Instance 3 is very similar to the restart of Service Instance 2. It will connect and bind to its primary and secondary queues but will receive no traffic until the other service instances cycle their secondary connections.
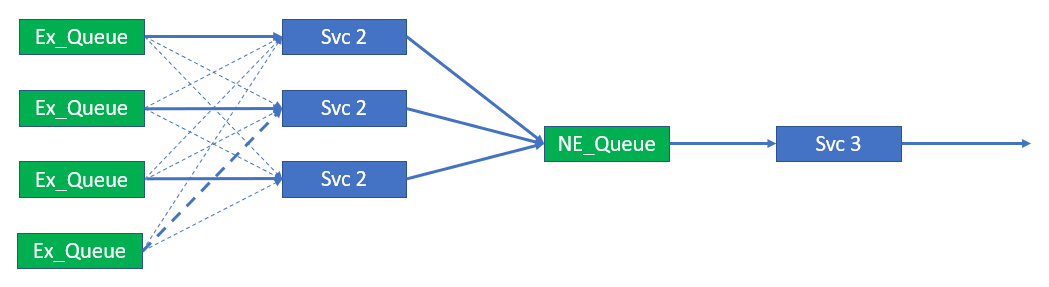
Three instances service four queues – Traffic rebalancing
After the secondary connections are cycled by Instances 1 and 2, traffic flows to Service Instance 3 over its primary connection.
Once again, Queue 4, which is served by secondary connections, will bounce between service instances and cycle their secondary connections. At any moment Queue 4 will only be serviced by one service instance ensuring the event and message order is maintained.
Deploying the “Sticky Load Balancing” Pattern
Having defined what we are trying to do and why we are trying to do it, we need to work through some implementation requirements. This will help simplify deployment and reduce deployment mistakes.
The code samples for this pattern have 4 components:
- CG_admin
- LBGHashedPublisher
- LBGClient
- LBGValidationClient
Only the first three items implement the pattern. The Validation client simply tests the output republished by the LBG client to report topic and instance allocation changes and flag any order errors.
Coordinating Configuration Attributes
In order to deploy this pattern, there should be a number of parameters that need to be coordinated for publishers and consumers to act on in order to provide a working ‘Load-Balanced Group’.
The attributes required for the provision of a “Load Balanced Group” are:
- Hash Prefix—the prefix that will be used at the first level of the topic hierarchy to keep this hash group separate from any other hash group
- Hash Count—the number of “shards” that the topic space will be broken into. We disconnect the hash count from the queue count for additional flexibility. The hash count will form the second level of the topic hierarchy in this example deployment.
- Queue Count—the number of queues to be provisioned for clients to bind to
- Queue Size–the spool to be allocated to each queue when provisioned
- Client-Username—owner of the queue, used by consumer group clients
- Client-Password–the password of the client. It is included here for completeness but noted as insecure—probably remove from here and use certs instead.
The list of the items will be used by the following functions:
- Publisher: will use Items 1 and 2 to determine how to publish to the load balanced group, that is, Item 1 will provide the topic prefix for this load balanced group. Item 2 will provide the hash modulo for the hashed topic space.
- Administration Agent: will use Items 1 through 6 for the provisioning of the service.
- Consumer Group Consumer: will use Item 3 (also 5 and 6).
Note that Consumer Group Consumer will also need to know the maximum clients being started for the peak load and its client starting number within the potential client population. This is not shared or static information but could change in each run as the system evolves and traffic volumes grow.
Storing Configuration Attributes Centrally
As a number of separate actors need access to configuration, it is suggested that the configuration attributes for a load balanced group be stored in a central location. From the central location it can be read by the producers and consumers instead of each actor holding its own configuration file.
For this example, the use of JNDI queues will be overloaded to store the “Load Balanced Group” information.
The JNDI Queue object maps a JNDI Queue name to a Physical queue name. The physical queue name can be up to 250 characters long and can in principle store a JSON representation of the LBG configuration. An example configuration is shown below:
{“HP”:“hash1”,“HC”:100,“QC”:12,“QS”:100,“CU”:“lg_cu1”,“CP”:“pw12345”}
In this case, the JSON fields are as follows :
- HP = Hash Prefix
- HC = Hash Count
- QC = Queue Count
- QS = Queue Size
- CU = Client-Username
- CP = Client-Password
Writing Configuration and Provisioning Solace Objects
To write the configuration into JNDI and configure the Solace objects, a small admin application was created. It took the configuration parameters from the command line, created the Solace objects, and then created the JSON to store in the JNDI.
The program needs VPN Read/Write privileges. It uses SEMPv2 for the provisioning of the Solace objects within the VPN. It is assumed that users will be locked to their VPN via their login ID and will only be able to manage LBG within their VPN.
The application allows the user to create, list, or delete the Load Balanced Group configuration.
final String usage = "\nUsage: CGadmin [create | delete | list] <semp_base_path> <management_user> <management_password> <vpnname>" + "\nEx: CGadmin create <mgt_interface_dns> <mgt_user> <mgt_password> <vpn_name> <group_name> <hash_prefix> <hash_count> <queue_count> <queue_size> <client_username> <client_password>" + "\n Create all load balanced group configuration including queues, subscriptions, client username and profiles for the subscribers" + "\n CGadmin list <mgt_interface_dns> <mgt_user> <mgt_password> <vpn_name>" + "\n List all load-balanced groups that are configured" + "\n CGadmin delete <mgt_interface_dns> <mgt_user> <mgt_password> <vpn_name> <group_name>" + "\n Delete a named LBG, including queues, usernames and profiles";
During the configuration, the application checks to ensure none of the prefixes for the LBG, client-username, client-profile, and the queues is unavailable.
The use of SEMPv2 is pretty simple. The following is an example of creating queues and adding subscriptions:
public void createQueues(String messageVpnName, String queuePrefix, LBG settings ) throws ApiException {
System.out.format("Creating %d persistent Queues:...\n", settings.QC);
int qcount = 0;
int scount = 0;
//Create the queue
for (qcount = 0; qcount < settings.QC; qcount++ ) {
// Create a queue
MsgVpnQueue queue = new MsgVpnQueue();
String queueName = queuePrefix + "/" + qcount;
queue.setQueueName(queueName);
queue.setPermission(PermissionEnum.NO_ACCESS);
queue.setIngressEnabled(true);
queue.setEgressEnabled(true);
queue.setAccessType(AccessTypeEnum.EXCLUSIVE);
queue.setMaxMsgSpoolUsage((long)(settings.QS));
queue.setOwner(settings.CU);
MsgVpnQueueResponse resp = sempApiInstance.createMsgVpnQueue(messageVpnName, queue, null);
//Add subscriptions to the queue
for (scount = qcount; scount < settings.HC; scount += settings.QC) { MsgVpnQueueSubscription sub = new MsgVpnQueueSubscription(); String subscriptionTopic = settings.HP + "/" + scount + "/>";
sub.setSubscriptionTopic(subscriptionTopic);
MsgVpnQueueSubscriptionResponse subresp = sempApiInstance.createMsgVpnQueueSubscription(messageVpnName, queueName, sub, null);
}
}
}
Consumer Group Clients
Consumer Group clients are the “consumers” that will join the consumer group service and consume the application messages from the queues within the consumer group. Consumer group clients are therefore just a “special” application client.
The Consumer Group Clients will:
- Be started knowing the LBG to which it must attach, the number of clients being started, and its client index within the group started.
- Read the LBG configuration when started.
- Work out from the LBG configuration the queues to which it must connect.
- Connect to ALL of the available queues in the LBG with the following rule:
If (queuenumber % clientnumber) - clientindex == 0) primaryqueue = true else primary_queue = false - Periodically cycle through all of the consumers connected to queues while running. If the queue is not set as a primary queue, then destroy it and recreate the consumer queue binding.
The following code snippets show this. First create the consumer queue bindings and determine whether the binding is primary or not.
ConsumerContainer consumers[] = new ConsumerContainer[queueCount];
//loop through a create primary and secondary queues
int loop = 0;
for (loop = 0; loop < queueCount; loop++) {
consumers[loop] = new ConsumerContainer();
consumers[loop].queueName = queuePrefix + loop;
if (((loop % clientCount) - clientNumber) == 0) {
consumers[loop].primary = true;
} else {
consumers[loop].primary = false;
}
//System.out.println( consumers[loop].queueName + " " + consumers[loop].primary);
Queue queue = JCSMPFactory.onlyInstance().createQueue(consumers[loop].queueName);
// Create a receiver.
ConsumerFlowProperties flowProp = new ConsumerFlowProperties();
flowProp.setEndpoint(queue);
flowProp.setAckMode(JCSMPProperties.SUPPORTED_MESSAGE_ACK_CLIENT);
consumers[loop].consumer = session.createFlow(this, flowProp, null);
consumers[loop].consumer.start();
}
While running, periodically cycle through the consumers and close, re-create, and start the consumer. This action allows the primary consumers for the queue to ”bubble to the top” and become the consumer that reads from the queue.
The exact period for rerunning this rebalancing is not fixed and is suggested as 30 seconds or 60 seconds. This example uses 30 seconds.
while ( run == 1 ) {
Thread.sleep(30000);
System.out.println("cycle...");
for (loop = 0; loop < queueCount; loop++) {
//System.out.println(loop);
if (!(consumers[loop].primary)) {
//Unbind and re-bind non-primary consumers to allow primary to become active
consumers[loop].consumer.close();
Thread.sleep(100);
Queue queue = JCSMPFactory.onlyInstance().createQueue(consumers[loop].queueName);
// Create a receiver.
ConsumerFlowProperties flowProp = new ConsumerFlowProperties();
flowProp.setEndpoint(queue);
flowProp.setAckMode(JCSMPProperties.SUPPORTED_MESSAGE_ACK_CLIENT);
consumers[loop].consumer = session.createFlow(this, flowProp, null);
consumers[loop].consumer.start();
}
}
}
For each consumer, we keep the following container class for the Consumer attributes:
class ConsumerContainer {
FlowReceiver consumer = null; // The consumer handle
String queueName = null; // The queue name - this is needed as for non-primary queues we periodically destroy and recreate the bind
boolean primary = false; // Is this queue a primary queue for this client?
Testing the LBG Proposal for Sequenced Order, Message Loss, and Duplicates
In order to test the setup, we need to ensure that:
- A publisher was configured to send data to the LBG which would involve hashing a key field to provide a hash number within the hash range.
- The publisher would also supply information within the messages such as a sequence number (per topic) and a topic or hash number so that data can be sorted easily at the eventual receiver.
- At the LBG Client we added code to republish the messages received by the LBG client to a single test receiver so that we can detect errors in sequence and changes in the LBG client processing the message.
- A final receiving client that would receive the aggregate data republished by the LBG clients and per topic report on the Errors in sequence number delivery, and…
- Changes in the LBG client that is processing the message shard.
The following figure shows the test set.
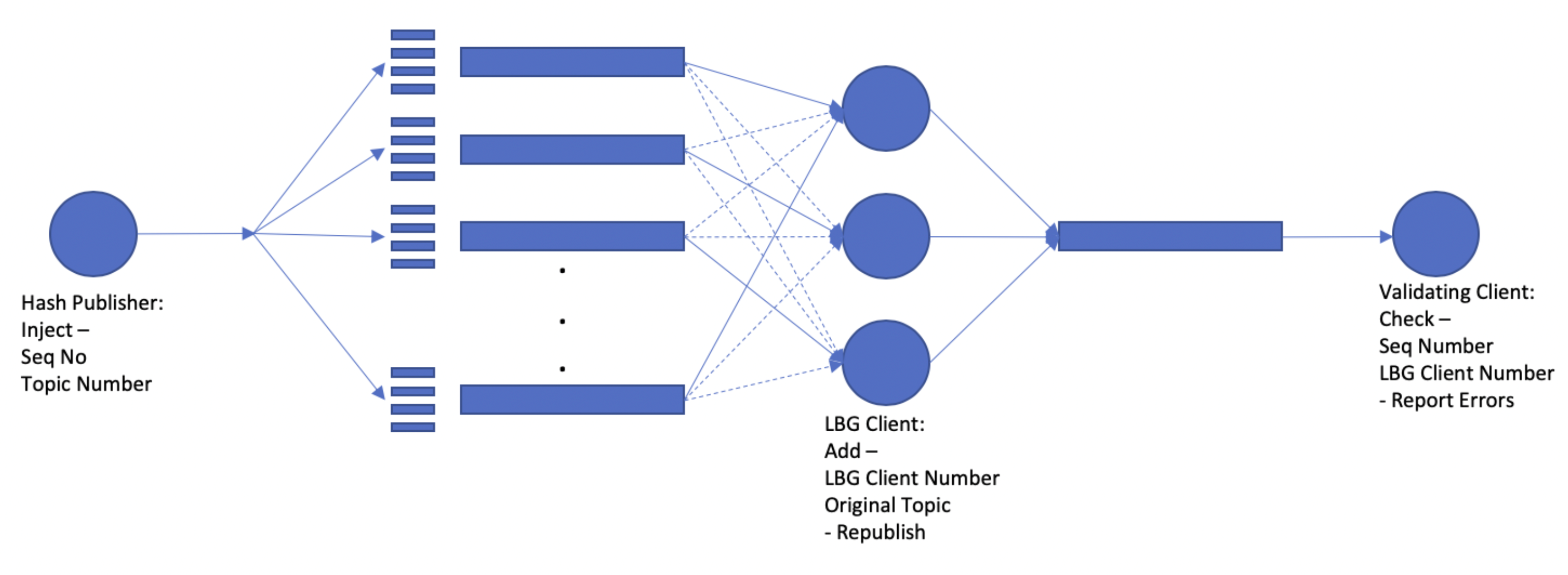
Hashed Publisher
Hash Publisher – Generate the topics to be used:
for (int loop = 0; loop < topicCount; loop++) {
availableTopics[loop] = new String(UUID.randomUUID().toString() + "/" + UUID.randomUUID().toString());
System.out.print(".");
}
Hashed Publisher code snippet:
int run = 1;
int perTopicSeqNo = 0;
while ( run == 1 ) {
int cycle = 0;
for (cycle = 0; cycle < topicCount; cycle++) {
MapMessage sendmsg = JCSMPFactory.onlyInstance().createMessage(MapMessage.class);
SDTMap sendmap = JCSMPFactory.onlyInstance().createMap();
sendmap.putInteger("seqno", perTopicSeqNo);
sendmap.putInteger("topicnumber", cycle);
sendmsg.setMap(sendmap);
sendmsg.setDeliveryMode(DeliveryMode.PERSISTENT);
Topic topic = JCSMPFactory.onlyInstance().createTopic(hashedTopic(hashPrefix, hashCount, availableTopics[cycle]));
prod.send(sendmsg, topic);
System.out.print(".");
}
perTopicSeqNo++;
}
Hashed Publisher Hash Code:
private String hashedTopic (String hashPrefix, int hashCount, String topic) {
String hashedTopicString = hashPrefix + "/" + Math.abs(topic.hashCode()%hashCount) + "/" + topic;
return hashedTopicString;
}
LBG Client
OnReceive() -
public void onReceive(BytesXMLMessage message) {
``
int seqNo = 0;
int topicNumber = 0;
String originaltopic = "";
``
if (message instanceof MapMessage) {
MapMessage receive = (MapMessage) message;
originaltopic = receive.getDestination().getName();
SDTMap map = receive.getMap();
try {
seqNo = map.getInteger("seqno");
topicNumber = map.getInteger("topicnumber");
} catch (JCSMPException e) {
System.err.println("JCSMPException: " + e);
e.printStackTrace();
}
}
``
try {
MapMessage sendmsg = JCSMPFactory.onlyInstance().createMessage(MapMessage.class);
SDTMap sendmap = JCSMPFactory.onlyInstance().createMap();
sendmap.putInteger("seqno", seqNo);
sendmap.putInteger("topicnumber", topicNumber);
sendmap.putInteger("lbgclient", clientNumber );
sendmap.putString("originaltopic", originaltopic);
sendmsg.setMap(sendmap);
``
sendmsg.setDeliveryMode(DeliveryMode.PERSISTENT);
Topic topic = JCSMPFactory.onlyInstance().createTopic(republishTopic);
prod.send(sendmsg, topic);
``
message.ackMessage();
Validation Client
OnReceive()
public void onReceive(BytesXMLMessage message) {
int seqNo = 0;
int topicNumber = 0;
int lbgclient = 0;;
String originalTopic = "";
if (message instanceof MapMessage) {
MapMessage receive = (MapMessage) message;
SDTMap map = receive.getMap();
try {
seqNo = map.getInteger("seqno");
lbgclient= map.getInteger("lbgclient");
topicNumber = map.getInteger("topicnumber");
originalTopic = map.getString("originaltopic");
} catch (JCSMPException e) {
System.err.println("JCSMPException: " + e);
e.printStackTrace();
}
}
//get the validation object based on the topic
if ((validation[topicNumber].seqNo + 1) != seqNo) {
System.out.println("Sequence number error. " +
" topic number " + topicNumber +
" Expected " + (validation[topicNumber].seqNo + 1) +
" but received " + seqNo +
" :: lbg client - " + lbgclient +
" :: original topic - " + originalTopic );
}
validation[topicNumber].seqNo = seqNo;
if (validation[topicNumber].lbgclient != lbgclient) {
System.out.println("Shard assigned new lbgclient. " +
" topic number " + topicNumber +
" was " + validation[topicNumber].lbgclient +
" now " + lbgclient +
" :: original topic - " + originalTopic );
}
validation[topicNumber].lbgclient = lbgclient;
message.ackMessage();
Test Run
The test run shows that, in principle and in practice, the solution does provide the ability to load balance the hashed stream across many consumers that share the load while maintaining the order within a given hash stream.
The system allows LBG clients to be added to increase throughput or reduce it when throughput drops in an elastic manner.
The system test also shows that in case of a failure of the LBG client, for example a “microservice”, other clients will pick up the load quickly.
Validation Client Output
The Validation client output from a run shows a few interesting properties of the solution.
When the active client count is not equal to the maximum client count, hashed topics will move between LBG clients at the frequency that LBG clients “release non-primary queues”. This move only occurs for queues with no ‘primary client’ and the move is lossless and does not cause any re-ordering or sequence number issues. The following snippet shows LBG Client 1 releasing its non-primary binds and LBG Client 2 taking over.
Shard assigned new lbgclient. topic number 71 was 1 now 2 :: original topic - __hash1__/96/b8c1ccb2-c67f-446f-8111-9eec8b264782/25c151d2-76c3-41aa-98c4-508542cd80b9 Shard assigned new lbgclient. topic number 85 was 1 now 2 :: original topic - __hash1__/84/8024b039-92dd-42de-9d16-8656d70f733f/f911ffac-c737-4fed-aed2-7e68a4ae7d15 Shard assigned new lbgclient. topic number 93 was 1 now 2 :: original topic - __hash1__/72/7b8be135-ac05-44bf-b5ed-d544400a211d/f0ead9f2-bf5b-4432-a79e-13d6e8ccc617 Shard assigned new lbgclient. topic number 98 was 1 now 2 :: original topic - __hash1__/84/4d92a5e9-7788-4ed3-bd09-bc47850b25a0/545ea629-b35e-4a94-8a80-8ef982ef02c1 Shard assigned new lbgclient. topic number 2 was 1 now 2 :: original topic - __hash1__/24/92af4374-a230-43d5-a6ae-440ffee9891d/3f7cc992-30c4-4c22-9df9-2df9de726573 Shard assigned new lbgclient. topic number 17 was 1 now 2 :: original topic - __hash1__/24/e8011270-42d6-4724-b3c8-23350f42cbf7/7ead4b11-b87e-4296-b951-d0ec604475d4
The release cycle ensures that with one cycle the primary LBG client for that queue will be active if available and connected.
A failure of a node results in no message loss and minimal message duplicates. It might be possible to eliminate duplicates by using session transactions, but this was not tested in this use case.
Sequence number error. topic number 28 Expected 483 but received 480 :: lbg client - 0 :: original topic - __hash1__/83/aad03408-3404-4fcc-ae83-1eb2c6739596/7a3ca558-8176-420a-ac8d-322f249caa33 Shard assigned new lbgclient. topic number 28 was 2 now 0 :: original topic - __hash1__/83/aad03408-3404-4fcc-ae83-1eb2c6739596/7a3ca558-8176-420a-ac8d-322f249caa33 Sequence number error. topic number 78 Expected 482 but received 481 :: lbg client - 0 :: original topic - __hash1__/86/1bb13765-cfa4-40da-9fc3-548bb5d6f4b0/9a1ec910-ec85-4e80-936c-893b0b78501a Shard assigned new lbgclient. topic number 78 was 2 now 0 :: original topic - __hash1__/86/1bb13765-cfa4-40da-9fc3-548bb5d6f4b0/9a1ec910-ec85-4e80-936c-893b0b78501a Sequence number error. topic number 51 Expected 482 but received 480 :: lbg client - 0 :: original topic - __hash1__/77/e06158ad-1009-4c76-9a17-f51f4b090ee0/6950910b-e930-4e2b-94f8-0b248b77eedd Shard assigned new lbgclient. topic number 51 was 2 now 0 :: original topic - __hash1__/77/e06158ad-1009-4c76-9a17-f51f4b090ee0/6950910b-e930-4e2b-94f8-0b248b77eedd Sequence number error. topic number 49 Expected 482 but received 480 :: lbg client - 0 :: original topic - __hash1__/11/a7927956-6806-409e-8b63-3c815618a448/151ba948-7bd9-4347-9165-ea3b8dd9755d Shard assigned new lbgclient. topic number 49 was 2 now 0 :: original topic - __hash1__/11/a7927956-6806-409e-8b63-3c815618a448/151ba948-7bd9-4347-9165-ea3b8dd9755d Sequence number error. topic number 30 Expected 483 but received 481 :: lbg client - 0 :: original topic - __hash1__/44/453c1d21-a8a2-484c-9e3f-0f6f2909dd64/e46b477e-a60e-4b36-a8fb-a57a333d3e18 Shard assigned new lbgclient. topic number 30 was 2 now 0 :: original topic - __hash1__/44/453c1d21-a8a2-484c-9e3f-0f6f2909dd64/e46b477e-a60e-4b36-a8fb-a57a333d3e18 Sequence number error. topic number 0 Expected 483 but received 482 :: lbg client - 0 :: original topic - __hash1__/38/925a1901-bf13-4580-beba-d64a607d0095/e654ddc4-ea01-41d2-8c54-cbbcc7b348f8 Shard assigned new lbgclient. topic number 0 was 2 now 0 :: original topic - __hash1__/38/925a1901-b
Summary
We have shown that
- Implementing Load-Balanced Consumer Groups using the basic Solace PubSub+ Event Broker features is simple.
- Flexible scaling of consuming services while maintaining order is possible.
- The implementation has some major benefits in terms of decoupling the producers and consumers involved in the group.
- As long as we plan for growth in determining the number of hash groups, the number of queues and the number of clients, and we ensure that HC≥QC≥CC (where HC = Hash Count, QC = Queue Count and CC = Consumer Count), we can scale the number of queues and consumers without having to reconfigure publishers.
- The service is also resilient as clients connect to exclusive queues, in our proposal. If a consuming client fails, then the delay in resuming message processing is minimal as we already have standby clients bound to the queue.
For more information, visit PubSub+ for Developers. If you have any questions, post them to the Solace Developer Community.
Explore other posts from category: For Developers



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.