Developing a Disaster Monitoring Service with Solace PubSub+
MakeUofT is Canada’s largest makeathon. Similar to a hackathon, it’s a place where projects come
Harjeet “Harry” Singh is a Solace Developer Community member. Recently, he developed a Spark-Solace connector to send events to Solace PubSub+ Event Broker. Below he shares his experience developing the project that accomplished what his employer needed and how he benefited from the Community.
I work for Bharti Airtel, a leading global telecommunications company headquartered in New Delhi, India. Here at Airtel we’ve been using Solace PubSub+ Event Broker for a while and we recently started a project that required us to send events from our Hadoop Distributed File System (HDFS) to the event mesh in a distributed fashion. As a Senior Data Engineer on the X-Labs team, I was tasked with developing a way to publish and consume data to and from the broker in a way that met multiple business requirements.
I started with the concept of publishing to the PubSub+ Event Broker via REST Services which is straightforward if you follow Solace’s documentation. When you have millions of rows which are distributed as blocks in an HDFS cluster (or any other underlying structure since this architecture is generic and can be applied to other file systems such as Amazon S3), and if you want to send data in a distributed way to Solace, you’ll need to leverage the Solace JMS API to publish data to Solace’s queue or topic.
The diagram below illustrates the system architecture of our project.
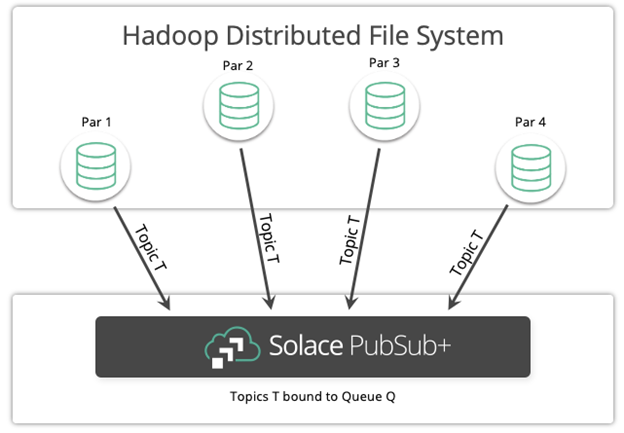
As you can see, the architecture was to open a connection object to Solace PubSub+ Event Broker per partition of Spark Executor and send rows of each Spark partition either as individual events or as a JSON Array by clubbing all rows of Spark partitions to Solace PubSub+ queue or topic as one event.
The benefit of such a design is that in a normal scenario where data resides in one JVM for example, all I need is a single connection to send that piece of data (pr events) to Solace PubSub+ Event Broker and we are done. When data is spread across nodes as millions of pieces (let’s say data size is 100GB), multiple connections have to be opened in a logical unit (which is Spark’s partition here) and they all work in parallel depending on how the Spark driver schedules them. With our design, the multiple connections can independently work on a chunk of data sending it to Solace’s Event Broker, thus saving lot of time by avoiding sending the 100GB of events from a single JVM.
So in Spark a dataset is a distributed collection of data; assume a table of rows like:
// +----+-------+ // | age| name| // +----+-------+ // |null|Michael| // | 30| Andy| // | 19| Justin| // +——+-------+
But the rows are not stored as single continuous bytes in memory, the data stored in any of the forms (Parquet, Avro, Csv, ORC) is distributed as 64/128 MB chunks all across nodes which are managed by a central node which has all their metadata. So applying business/computation logic to distributed data and sending them as Solace events required some connector which can send those events to the Solace broker.
Spark’s dataset API gives a way to write custom code at the partition level:
//Dataset.forEachPartition( row-> {//custom code});
This allows me to repartition our Spark dataset on custom logic or integral values to create even-sized partitions or partitions having a specific kind of data for use case.
I then made a connection to the Solace JMS API. You can make this connection either using JNDI information if you have it available, or you can make a dynamic connection. I had a configurable JSON where an end user can mention whether he has JNDI info and, if he has, he can supply it. While making a connection, my code checks whether the JNDI flag is true. If it is, it picks up the information supplied. Otherwise, it makes a dynamic connection. The Solace JMS API needs VPN-NAME, HOST, USERNAME, and PASSWORD to create a connection to the Solace broker. Depending on our requirement, I created a topic bound to a queue for persistence messaging and used the standard JMS APIs to publish the records from record iterator (either individually or bulk) to the message producer.
The code that we used looks something like this:
Dataset.foreachPartition( rowIterator->{
SolConnectionFactory factory= SolJmsUtitlity.createConnectionFactory();
factory.setHost(“localhost:55555”);
factory.setVpn(“default”);
factory.setusername(“default”);
factory.setPassword(“default”);
Connection connection= factory.createConnection();
Session session= connection.createSession();
Topic topicName = session.createTopic(“myTopic”);
MessageProducer msgP=session.createProducer(T);
TextMessage msg=session.createTextMessage(rowIterator.next()) //you can also custom handle how you want to create text message from your dataframe’s row object
msgP.send(topicName,msg,DeliveryMode ….);
//conn.close //explained later why it’s commented
})
The outcome of the project was to automate the notifications to a team as a Solace event which was then picked by a process and then, according to some business logic, a communication needed to be sent downstream. The challenge was to get the data out of HDFS, do some processing, and send the result (based on said processing) as an event in Solace. This challenge was solved by using the connector.
One of the important things that I’ve learned from this project is that I can use Spark DataFrame API to write my own connector to Solace PubSub+ Event Broker. All I needed to do was make a class named “Default Source”, implement DataSourceRegister, CreatableRelationProvider, and createRelation for the above code. I’ve found the Data Source API documentation very useful. So if my Java package name is com.connector.harjeet.solace, Spark will look for the class DefaultSource in this package, and I can use it to call my custom connector which will send data to Solace in a distributed way.
The code snippet looks like this:
//some spark code. creating spark session , data frame etc. dataset.write().format(“com.connector.harjeet.solace”).save();
I can make the host, VPN-name, etc. configurable and pass the information into options in the API call to save.
One of the resources that helped me with my project is the Solace Developer Community. For example, one of the challenges that I had was how to improve the performance. Each partition is creating a connection object to Solace PubSub+ Event Broker. So, if our Spark’s DataFrame has thousands of barriers, it would create that many connection objects. One thing I could do is to make connection singleton. This limits the number of connection objects to an upper limit of the number of executors I give to my Spark job which can be 10–20. However, it creates another problem–I’ll have to let the connection remain open so that one partition does not close the link for other barriers in that executor.
I posted a couple of questions and asked the Community to help me understand some core concepts and how to improve efficiency. I got many quick and helpful replies from both Solace employees and Community members, which suggested that I should keep the connection open and let Solace PubSub+ Event Broker itself close the connection at its end because creating too many relationships is a costly operation at the broker’s end. Help like this from the Community has not only guided me through our project, but also boosted the performance of our connector.
I really encourage every developer who is using PubSub+ to use the Solace Developer Community. I am sure it will benefit you one way or another.
 Harjeet “Harry” Singh is currently a Data Engineer at MongoDB and holds a bachelor’s degree in Computer Science and Engineering from NIT Jalandhar, India. He is very passionate about understanding and working with distributed systems.
Harjeet “Harry” Singh is currently a Data Engineer at MongoDB and holds a bachelor’s degree in Computer Science and Engineering from NIT Jalandhar, India. He is very passionate about understanding and working with distributed systems.
Explore other posts from category: For Developers


Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.


