During EDA Summit 2022, Solace chief technology solutions officer Sumeet Puri did a short session on the topic of Kafka Mesh. It was so popular, he and fellow colleague Thomas (TK) Kunnumapurath ran a follow-up session on Sept 29th to explain the concept in a bit more detail and demonstrate how it works.
You can watch the full video here, or read on for an in depth recap of the session.
Before the session got started, the audience was polled to determine which version of Kafka they were currently using in their environment. Unsurprisingly, the results showed Apache Kafka was the most prevalent at 69%, followed by Confluent as 28%, Amazon MSK at 10%, and the remainder were using either Cloudera or Azure Event Hubs.
What is a Kafka Mesh and Why Should You Consider Building One?
Sumeet made some fair points about how enterprises today are more distributed than ever, with edge and cloud gaining traction alongside existing core systems and assets.
With the acknowledgement that network is now faster than disk in most cases, and thousands (or millions) of devices are needing connectivity, streaming is becoming the de facto paradigm for data exchange throughout organizations. And for many, Kafka is their streaming platform of choice.
But these new patterns introduce new challenges:
- The need to exchange data between clouds of same or different providers, as well as exchanging data between cloud and on-premises systems.
- Streams don’t exist in isolation and often require integration with API management systems, as events should be treated and governed like APIs.
- The sheer volume of data now requires applications to become more efficient in data ingestion. Why ingest everything, when you could only ingest the data you really need?
- With scale comes partitioning; and with this, filtering and preserving order of events presents a challenge, particularly for transaction-based systems that must maintain order of events (i.e., you don’t want to process an order_cancel event before the original order is processed).
- Replication becomes a challenge when you have different flavors of Kafka clusters in your environment. Why do you even want to replicate streamed data (like a database would require) – why don’t you only stream the necessary data to applications?
- Lastly, what about non-Kafka event streams? With multiple flavors of Kafka, and non-Kafka systems how to you manage and govern all these environments?
A Kafka Mesh Liberates Kafka Data Streams
Kafka Mesh is a network of event brokers that natively connect to Kafka clusters and solve these challenges noted above. Not only does a Kafka Mesh connect different versions and islands of Kafka clusters but also connects to non-Kafka applications such as microservices, IoT devices, serverless functions, API platforms, and iPaaS platforms. It ultimately liberates your Kafka data streams throughout the enterprise in a cloud agnostic manner.
Sumeet then spoke about some sample use cases where a Kafka Mesh proves useful:
- Payment processing: These systems typically run on mainframes and rely on enterprise service bus (ESB) or legacy IBM MQ messaging systems. How could you liberate that data and make it available to Kafka-based applications for fraud detection or customer analytics?
- IoT/Connected Vehicles: Consider information continuously streaming from vehicles that you want to mine for driver behaviour (for insurance purposes). This data originates from non-Kafka environments and needs to be sent to Kafka applications for stream processing.
- Order & Inventory Management: We have seen a lot of ecommerce and/or order management systems with Kafka bolted-on, but typically a large retailer will also be running SAP and other non-Kafka applications for fulfilment, warehousing, and/or logistics management. These systems might also need access to the Kafka-based eCommerce system – how do you bring these worlds together? With a Kafka Mesh.
Another attendee poll was presented, asking the audience what challenges they face with their Kafka implementations. The results showed the following:
- 51% – Replicating data/events between different kinds of Kafka clusters
- 49% – Linking on-premises and cloud based Kafka clusters
- 45% – Filtering Kafka data streaming while preserving order
- 26% – Streaming from millions of devices/vehicles to Kafka clusters
- 20% – Connecting Kafka with edge apps and IoT devices
Sumeet wrapped up with the main benefits a Kafka Mesh can bring to your organization.
- The ability to easily replicate Kafka to Kafka event streams, without actually replicating data.
- The ability to subscribe to specific subsets of Kafka data streams via advanced filters and wildcards.
- Securely transmit Kafka data streams across WAN links.
- Provide real-time connectivity between Kafka clusters and everything else in your organizations.
- Discover, catalog, and visualize the Kafka data streams you already have in your network.
But how is all this possible?
Transforming Kafka Records into Routable Events
Thomas (TK) then took over the presentation and proceeded to explain the critical first step of transforming Kafka records into routable events the Kafka Mesh can intelligently route throughout the network. This is done by extracting the Kafka topic metadata and mapping it into a routable topic structure.
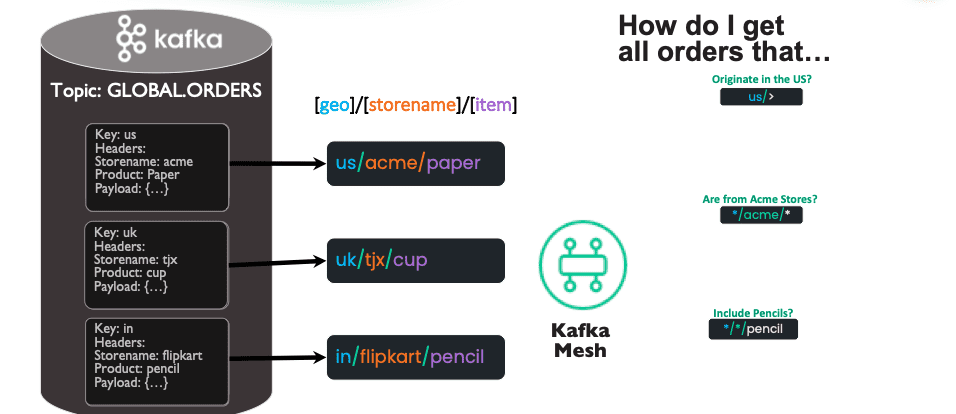
As this diagram illustrates, subscribing applications ask intelligent questions such as “how do I get orders that only originate in the US”, or “how can I look at all orders for pencils from anywhere?”
TK proceeded to demonstrate how easy it is to setup a in the Kafka Mesh and subscribe to a particular Kafka stream. In the example above, he uses GLOBAL.ORDERS.
He used the PubSub+ “Try Me” function to mimic a client application that might subscribe to a subset, or a filtered view of the GLOBAL.ORDERS stream. In this example he subscribed to US/ACME/*, and UK/TJX/* respectively and in each case only received the records from the GLOBAL.ORDERS stream that matched those filtered topics.
In these examples, the client (or consuming) application is only sent the records that match the topic subscription without the need for any further filtering application, as would normally be necessary in a Kafka only environment.
The Benefits of a Routable Topic Structure in a Kafka Mesh
TK closed his section by echoing Sumeet and showing some key benefits of Kafka Mesh users get when working in the manner described in the previous section:
- Dynamic and On-Demand Routing of Kafka streams – Using the wildcard filtering options shown above, you can route portions of your streams to other Kafka clusters with a simple topic subscription, and no need to setup any replication.
- Streaming events to/from the Edge with API Management support – With PubSub+’s built-in multi-protocol support you can receive events directly from IoT devices over MQTT and stream them to other applications over different protocols such as AMQP or event stream to API management solutions using a standard REST protocol.
- Store & Forward – If Kafka clusters are connected via a Kafka Mesh and the network connection fails, all flowing events can be buffered in the PubSub+ broker and resume streaming once connectivity is restored ensuring no events are lost.
- Native integration with Cloud Services – In the example, the GLOBAL ORDERS Kafka cluster could exist on-premises and connect to various other Kafka installations in different clouds. Each cluster receives a customized stream and delivering to one or more destinations in the cloud, such as another Kafka cluster and a cloud serverless function. It is important to appreciate that records only traverse the WAN once and are fanned-out to all subscribing applications/functions per the image below.

- Distributed Tracing for Observability – With PubSub+ support for distributed tracing via Open Telemetry, full end-to-end visibility of records as they traverse the Kafka Mesh can be recorded.
- Managing Kafka Event Streams with Event Portal – With PubSub+ Event Portal for Kafka you can visualize your entire Kafka estate and have a complete catalog of your event streams for ongoing re-use, governance and audit requirements.

Sumeet closed out the session with a great analogy on how to think of event-based subscriptions. Consider how you effectively subscribe to various #hashtags in Twitter in order to see a filtered view of everything in your twitter stream (ie. #vegan, #crypto etc…). That is pretty much the same concept as subscribing to granular topics in a pub-sub based event-driven system (order/shipped/*/sku123/> , order/cancel/> etc..).
Explore other posts from categories: For Architects | For Developers



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.