Kafka Summit 2018 kicked off today under clear blue skies in San Francisco. Held at Pier 27 along the Embarcadero, the premier event for those interested in streaming data with Apache Kafka also had a premier venue to host an event of around 1,000 attendees.
This was our view for lunch:

The event kicked off with a fantastic keynote from Chris D’Agostino, VP of Streaming Data at Capital One. In the presentation, What’s in your topic? Building an enterprise streaming platform at Capital One, D’Agostino broke down the four critical goals his team developed before implementing a streaming data platform:
- Shared Infrastructure & Self-Service: they needed dynamic provisioning across all environments (DEV, QA, PROD) for four LOBs, digital and shared technology,
- Producer Autonomy: producers needed to own their data, control access to it, and determine performance and blast radius characteristics,
- Data Governance: This was about producer accountability and the establishment of consistency and quality for events using data management tools; and,
- Data Democracy: the ability to easily produce, consume and act on data through a single user experience.
Here is D’Agostino’s full keynote:
After the keynote I ran back to our booth only to find fellow Solacians Heinz Schaffner (principal architect and 10-year Solace veteran) and Emily Hong (our senior sales engineer) already deep in conversations about the Kafka-compliant source and sink connectors we announced a few hours before the event.

Heinz Schaffner, second from the left; Emily Hong, second from the right.
Joseph deBuzna, VP of field engineering at HVR Software, delivered an interesting presentation as well. deBuzna discussed why HOP! airlines pivoted from legacy monoliths to a more agile and streamlined HVR + Kafka pairing, and how it improved operational efficiency and customer service as a result:
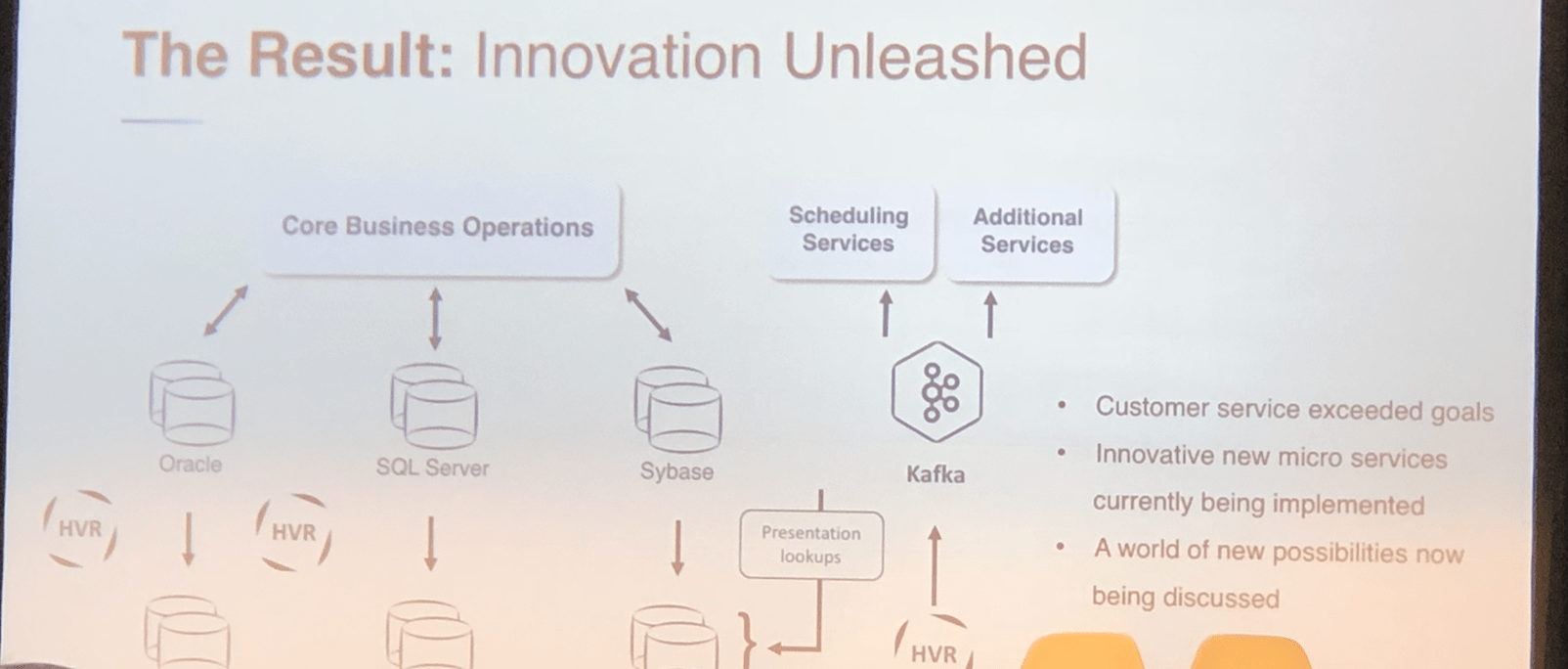
HVR’s role here is in its log-based change data capture, which can replicate changes to multiple locations and then both enrich and convert those changes into a time series that allows Kafka to better integrate with legacy architecture.
From there, principal enterprise architect Gary Samuelson gave a talk titled Event-Based Business Architecture: Orchestrating Enterprise Communications. Samuelson broke down the definitions and fundamentals of event-based architectures, including where Kafka fits into the mix:

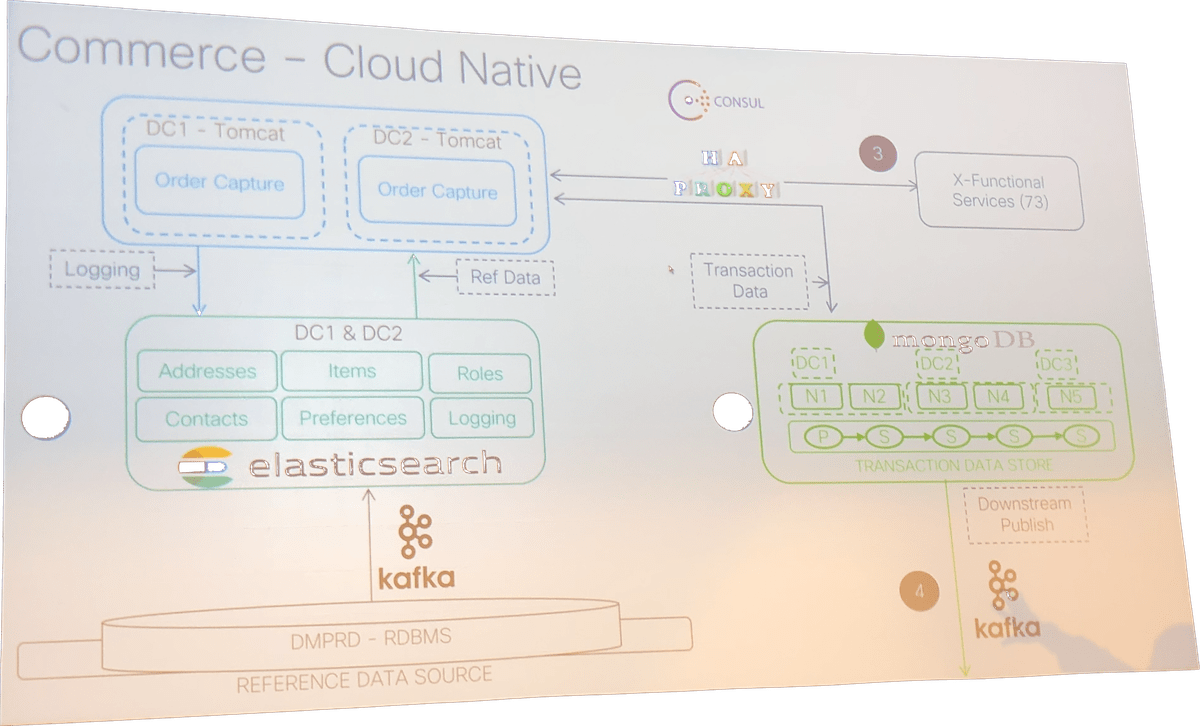
Lastly, two fascinating talks rounded out the day. The first, by Dharmesh Panchmatia and Gaurav Goyal of Cisco, explored in detail how Cisco’s e-commerce platform (it’s custom-built and generates $40 billion of Cisco annual revenue) uses Kafka to remove point-to-point integrations and push data for machine learning and analytics uses.

Dharmesh Panchmatia, left; Gaurav Goyal, right
Here’s a glimpse into some other massive numbers from the platform:

And here’s a look at their cloud-native architecture:
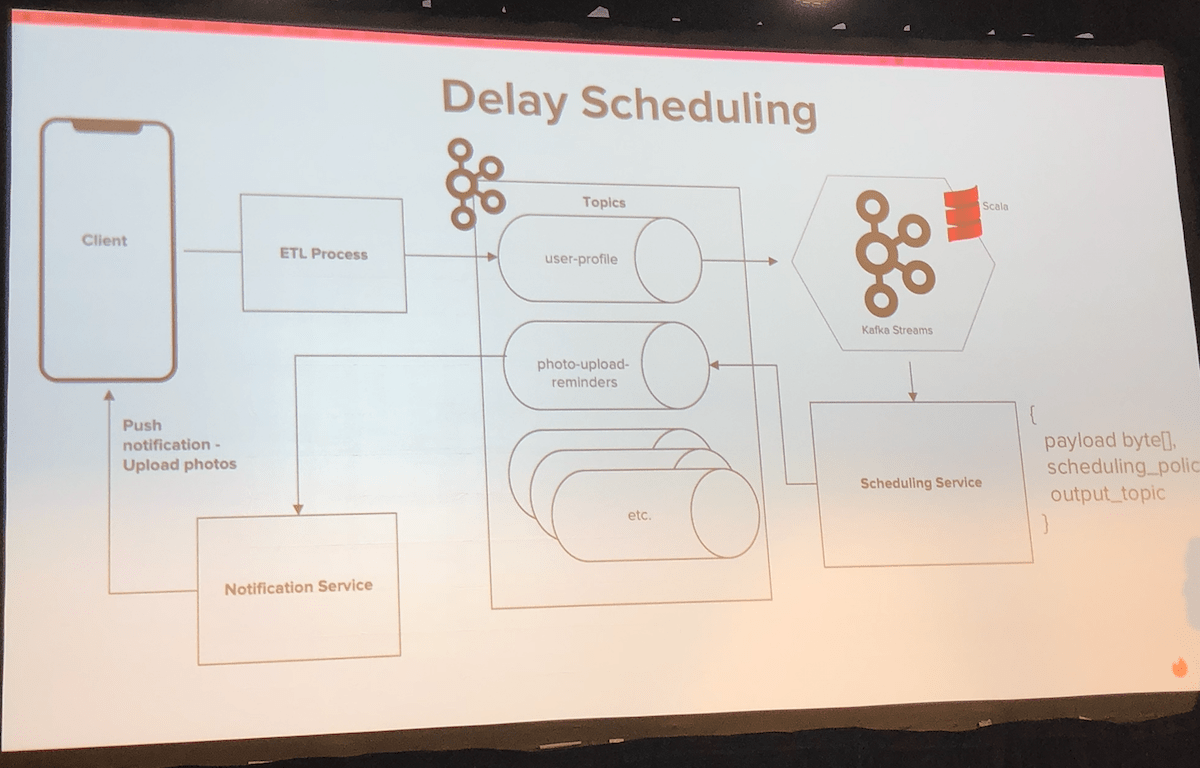
The second talk was from Krunal Vora, software engineer at Tinder:

Vora’s talk was engaging and succinct. He elegantly told it through the story of two people meeting, bouncing back and forth between their interests and where they lived (and when they swiped right) to what took place under the hood to create those user experiences.
Tinder and Kafka at scale:

A look at Tinder’s architectural flow for a particular app notification sequence:
That’s a wrap from Day 1 here at Kafka Summit 2018 in San Francisco. Stay tuned for tomorrow’s recap, and shoot me a message on Twitter or on LinkedIn if you’ll be swinging by our both.
Explore other posts from categories: Company | For Architects | For Developers



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.