Deploying microservices in a distributed environment can present a number of challenges, chief among them being the challenge of getting chatty microservices to communicate effectively. The more you scale your system (load and connections) within and across different environments, the harder this challenge can get, especially if you’ve started with a REST-based communication pattern. Using messaging to enable communication between microservices, however, can help you overcome these challenges and provide several key benefits.
The 5 key benefits of messaging when deploying microservices:
- Simple, scalable connectivity
- Simple, high availability
- Simple producer/consumer scalability
- The enablement of publish/subscribe, message filtering, routing and fanout
- Message rate and consumer availability decoupling
You may be wondering how REST/HTTP-based communication stacks up against messaging in enabling these benefits. In short, REST is an alternative to messaging and can deliver benefits 1-3 (above), but it doesn’t enable benefits 4 and 5.
Let’s take up each benefit in turn, and we’ll cover the REST vs. Messaging for Microservices debate as we go.
1. Messaging enables simple, scalable microservice connectivity
Without a message broker and queues or topics, producer services talk directly to consumer applications through TCP or HTTP/REST. This is not a problem when it’s just one producer talking to one consumer, but it becomes a huge problem when:
- New producers and consumers are added to the mix
- More and more instances of the producer and consumer services are added to the system
Without messaging, each time a new producer or consumer is added to the system, the system gets more complex. Software changes have to be made to all the applications in the system so the right information gets to the right applications, in the right format, at the right time. Each new application adds N number of new connections that need to be incorporated within the system logic (code).
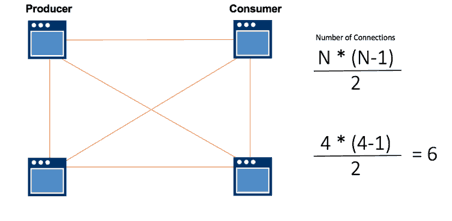
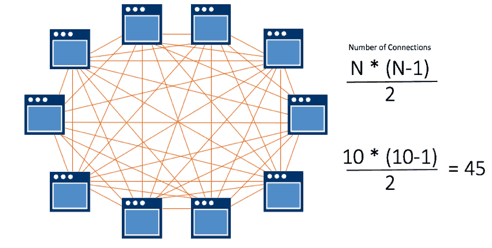
This process repeats with every new application added until it grinds your development team to a halt because they’re spending all their time making application changes to accommodate new connections.
Moreover, to cover application or server failure, you’ll have to build in a way for the system to know to find a new instance if an application in your system or your server fails (more on this in the next section).
In summary, TCP and HTTP/REST doesn’t scale in terms of application connectivity, and the management of the communication between the connections doesn’t scale either.
By contrast, in event-driven microservice architectures supported by messaging, producers emit business events to a messaging system, and consumer applications subscribe to the events they want to know about.
For example, a producer application might emit an event to the message broker describing a new sale. A consumer application that has subscribed to the topic “new sales” would receive this message about the new sale via the message broker. The producer application doesn’t have to know anything about the consumer application, and the consumer application doesn’t need to know the producer application. What they both need to know are the standards and protocols to send and receive specific messages from the message broker.
In this system, producers and consumers are not directly connected; there’s a message broker between them so the communications system (code) doesn’t get more complicated as new producer and consumer applications connect to the broker.
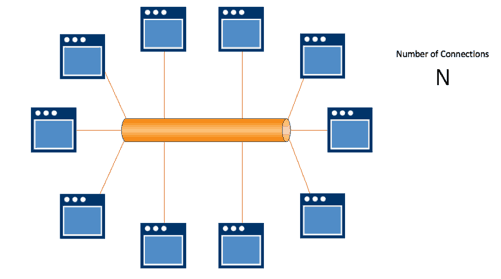
2. Messaging enables simple, high availability
Without messaging, applications are directly connected. If a consumer application fails, then ideally a new instance of that application will spin up, the producer application will have code built in to detect the failure, and after so many tries it will be programmed to go on to the next instance. This “ideal” scenario is complex to engineer in and of itself.

Now think how much more complex this code gets as new applications are added to the system.
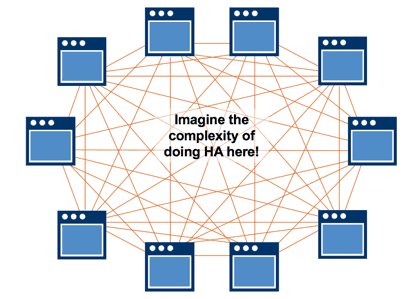
Instructions about what to do in every failure scenario need to be included in the code, and this gets increasingly difficult to manage. Further, if you fail to plan for a specific failure, the entire system can grind to halt.
By contrast, in an event-driven message broker environment, publisher applications connect to the broker, not one another. Publishers emit events, and new consumer applications connect to the system and subscribe to events.
When a new event message is emitted to the broker, the messaging system knows which subscribing applications are active and which are not. Messages are sent to subscribing consumer applications that are active, and to a central queue to await the availability of inactive subscriber applications.
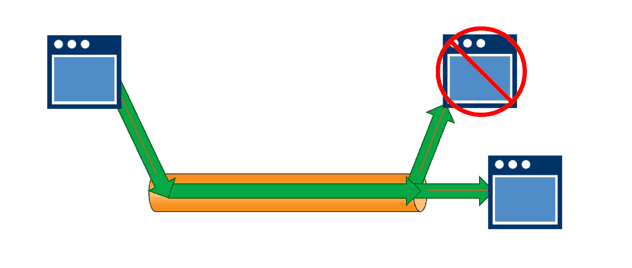
Moreover, if an active application fails, the messaging system knows where the standby system is, and it sends the message there.
Importantly, in this event-driven messaging architecture the publishing application doesn’t need to know or plan for the failure of consumer applications – it just emits events to the broker and moves on.
3. Messaging enables producer/consumer scalability
In a non-messaging environment (like REST/HTTP), because applications are directly connected, they can impede the efficiency of one another.
For example, if a producer application is creating information at a rate that is too high for a consumer application to process, a situation will arise where the producer accumulates messages while it waits for the slow consumer to be ready.
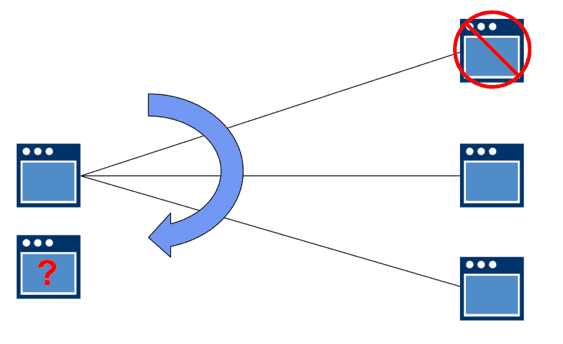
If you add new instances of your consumer application to distribute the load without something in the middle (message broker), you have to tell your producer application to spread the load to multiple consumers when it’s not really the producer application’s problem (it’s the slow consumer).
The same issue occurs if you scale the publisher. The consumer needs to know about the new publisher, which means simply adding or moving resources can create a total mess.
Alternatively, in an event-driven messaging environment, publishers generate messages and emit them to the broker, consumers connect to the broker, and as more and more consumer applications connect and subscribe to events the broker just directs the messages to more and more of them. This is known as horizontal scaling of the application.
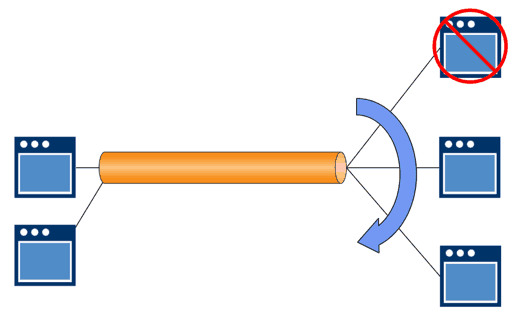
Because there is a central queuing point inside the message broker, you can see if the queue is getting too deep and whether the number of consuming applications you have is enough (because they’re not keeping up and you need to add more). When the consumer applications are spun up and connected in the message broker, the applications automatically share the workload. This is incredibly beneficial in cloud applications where you can spin up applications in busy times and spin them down when it gets quiet. The message broker manages this process without the publishers or consumers having to know about one another.

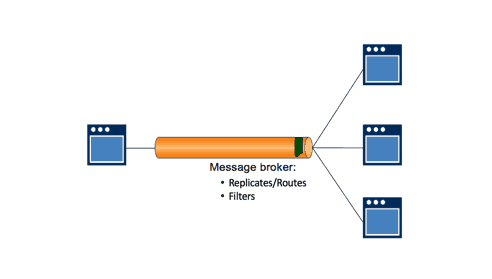
4. Messaging enables publish/subscribe, message filtering, routing and fanout
In situations where you have an application producing a number of events, and particular events need to go to multiple consumers, then doing this using HTTP/Rest or TCP is a real pain. As described above, you would need to build a lot of complexity into the code, and the code would get more complex as new producers and consumers are added.
Further, if the publishing application evolves over time to create new events, the publisher would have to write code about who needs to receive what information, or the subscribers would get everything the publisher produces (forcing them to filter the information on their end to get the information they really want). Both scenarios are a pain.
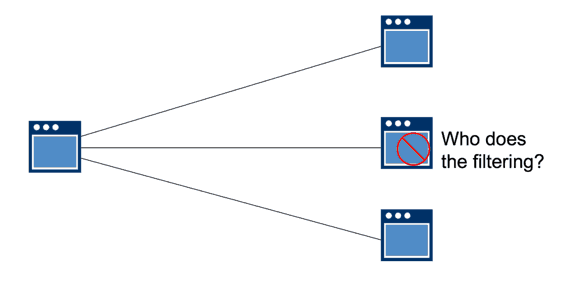
There is also no mechanism for governance built in, so subscribers might receive information they’re not entitled to.
By contrast, event-driven messaging environments enable publish/subscribe (pub/sub) messaging, as described above. As producing applications introduce new event messages to the system, they are only delivered to applications that have subscribed to them, so the filtering and routing of the information is built into the system (no additional code is needed to enable the efficient delivery of information).
Just as publishers aren’t required to know anything about the consumer applications that have connected to the broker, consumer applications don’t need to know anything about the publishing applications. All they need to know about is the event—how to ask for it, and the syntax and semantics of the payload.
The message broker can also contain rules about which applications can subscribe to what type of messages, as well as what applications are allowed to send specific types of events (so messages can’t be spoofed). The broker authenticates publishers and subscribers, and grants publishing and consumption permissions based on that authentication. This makes the system fully auditable based on the rules in the message broker.
5. Messaging enables decoupling of message rate from consumer availability
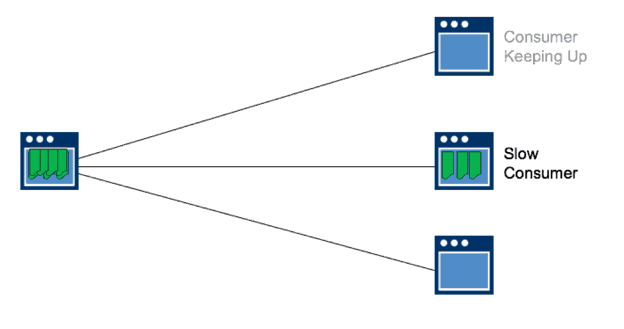
Without messaging, information from a producer application to consumer applications is delivered in an ordered way (synchronously), so if a consumer is slow or not available that will affect the message rate and service to the rest of the consumer applications in the system.
Trying to build efficiency into the system (with code that tells the system to go on to consumer 3 when consumer 4 is found to be inactive, for example) gets more complex as more consumers are added and the producer application has to remember what consumers have consumed what, what rate they can accept data and in what format, etc.
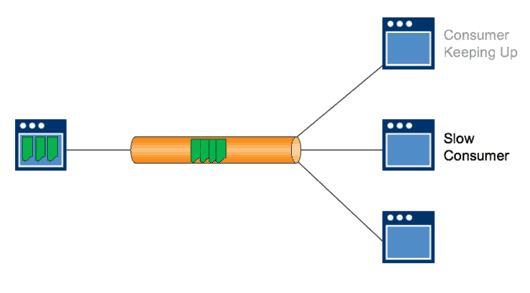
By contrast, if you put a message broker in the middle, messages are published as they come in. They get routed out to the consumers that can keep up, and the message broker keeps the messages for the slower applications until they’re ready to process them.
The message broker stores them to a disk and sends them out when they’re ready to accept them or they’re back online.
Conclusion: REST/HTTP vs. Messaging for Microservices?
Many of the challenges developers are experiencing in building and scaling their microservices stem from trying to use the design patterns they know (i.e., REST/HTTP) when it may not be the best tool for the job.
REST/HTTP works for synchronous request/reply patterns, for service-oriented architectures (SOA), and for public-facing APIs.
But it isn’t suited for event-driven microservices.
With HTTP you can’t:
- simultaneously deliver an event to multiple places,
- deliver messages asynchronously,
- easily scale your system as more and more applications and instances are added.
Messaging may not be the communication pattern you know best, but as you move to adopt a modern, event-driven microservice architecture, it’s worth investing the time to get more familiar with it.
To start, download Jonathan Schabowsky’s guide on the one modern messaging integration pattern you can leverage to realize the full potential of a microservices architecture.

Explore other posts from categories: DevOps | For Architects | For Developers


Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.