High Availability is a critical part of your middleware platforms, and Solace continually puts enormous effort into building and testing rock-solid HA and DR solutions that have been providing “five 9’s” reliability to customers for years.
Even if the message bus stays up flawlessly for a decade, none of that matters if the applications using it fall over. So what does Solace offer to application architects that we can leverage to make our applications more fault tolerant and highly available? I’ll walk through a few of the different tools that are available.
Reconnect Logic
At a bare minimum, if your application uses messaging you need to be able to maintain connectivity to that platform in the event of failures. Solace messaging client libraries provide highly available connectivity support through several mechanisms built into the client libraries, the appliances and their communication protocols. They take care of connection stability, reconnect logic and message sequence handling so that our application code can concentrate on what we as application developers do for a living. These features are user-configurable so you can control them without having to implement them.
Sumeet Koshal explained Solace’s options for configuring our built-in HA and DR capabilities to simplify your applications. Here are some examples that he explains in-depth:
JCSMPChannelProperties ccp = new JCSMPChannelProperties(); ccp.setConnectRetries(8); ccp.setConnectRetriesPerHost(5); ccp.setReconnectRetries(40); ccp.setReconnectRetryWaitInMillis(3000); ccp.setKeepAliveLimit(3); ccp.setKeepAliveIntervalInMillis(1000); properties.setProperty(JCSMPProperties.CLIENT_CHANNEL_PROPERTIES, ccp);
Round Robin Delivery via Non-Exclusive Queues
Load Balancing is the easiest form of high availability: provision a whole bunch of processors and then round-robin deliver messages across them all. If any processor fails, just deliver to the next in the list. Solace, like most persistent messaging systems supports load balancing via the non-exclusive queue for both resiliency and for simple horizontal scaling.
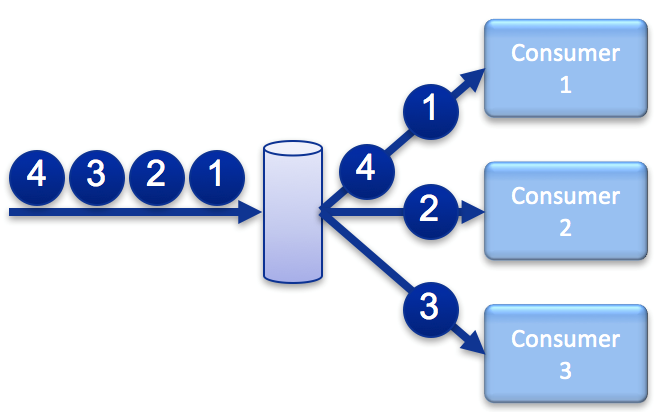
This works for only the simplest kinds of processing semantics where message order does not matter and the processing applications are stateless. For any kind of stickiness per flow, some systems support delivery via JMSXGroupID. In Solace we prefer to use topic-filtering to filter out individual flows, then topic-to-queue mapping to deliver the flow via exclusive queues (more about that later).
Leader Election via Exclusive Queues
Exclusive queues allow many applications to bind to the queue, but only delivers messages to one at a time. An event is raised to that application when it becomes active in case your code needs to perform anything prior to consuming messages. In the event that the connection to the current live consumer drops, the appliance starts send all un-acknowledged messages (including any that were potentially sent to the previous application).
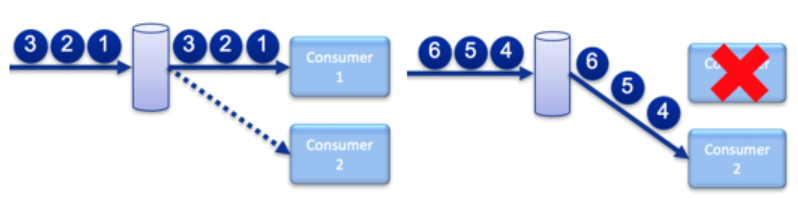
This allows stateful processing of a flow where message order within the flow is important. For example, when a queue persists customer orders, it’s really important that an order cancellation is received after the related order submission or modifications. By putting the relevant partitioning information on the message topic and using topic-to-queue mapping to apply the partitioning to queues, fault tolerant clusters of application instances can bind to the same queue and if the active processor fails then Solace selects one of the backups to take over.
State Management via Last Value Queues
Last value queues (LVQ’s) store just the latest value of a stream. This doesn’t directly help application availability but provides an additional tool for hot/hot members of an application cluster. LVQ’s can be configured to subscribe to the output stream of the cluster to help state synchronization between members. For instance, in the event of the primary cluster member failing and subsequent leader election, the new primary member can read the message on the LVQ to synchronize its internal state to the last known output of the cluster.
Putting It All Together
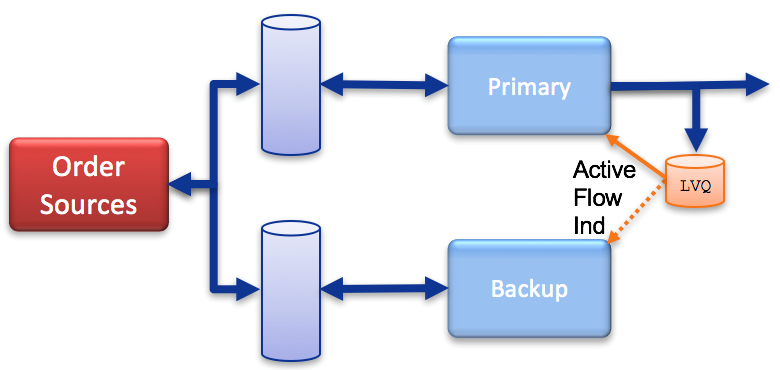 These tools provide the base functionality from which more sophisticated HA architectures can be designed. In the next post, we will walk through the code for a sample using them to implement a “hot/hot” redundancy model where redundant application instances process the same data from parallel queues to keep in sync and failover to each other quickly and reliably.
These tools provide the base functionality from which more sophisticated HA architectures can be designed. In the next post, we will walk through the code for a sample using them to implement a “hot/hot” redundancy model where redundant application instances process the same data from parallel queues to keep in sync and failover to each other quickly and reliably.
Explore other posts from category: Products & Technology



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.