Note: For an update comparison of Solace and Kafka, click here.
This blog post is part of a series of blog posts comparing Apache Kafka with Solace PubSub+ Event Broker and covers how filtering, both message and topic, differs in these two brokers. Check out the other posts in the series:
- Solace PubSub+ vs Kafka: The Basics
- Solace PubSub+ vs Kafka: Implementation of the Publish-Subscribe Messaging Pattern
- Solace PubSub+ vs Kafka: High Availability
- Solace PubSub+ vs Kafka: Multi-Site Architecture
To get an understanding on the differences between Solace topics and Kafka topics, check out Solace Topics vs. Kafka Topics: What’s the Difference? or watch this video.
Topic Filtering
No two applications are the same, so having the flexibility to allow subscribers the ability to filter published events differently is important.
Typically, a subscriber registers a topic subscription of interest with the broker. When a publisher sends a message on that topic, the broker will forward that message to any subscriber that has a matching topic subscription. So how does a subscribing application potentially match an infinite number of topics? Easy. Via subscription wildcards. Wildcards enable advanced routing and filtering of messages.
Both Solace and Kafka support topic subscription wildcards but in slightly different ways.
Solace
Solace maintains a list of all subscriptions. When a message is received, the broker performs matching on the topic in a dynamic, real-time way and delivers the message to client applications and/or persistent endpoints. There are two different wildcard types: single-level (*) and multi-level (>).
Let’s take a look at an example. We have a publisher publishing data for all US stocks from different exchanges to topics such as EQ/US/NYSE/AAPL, EQ/US/NYSE/AAL and EQ/US/NASDAQ/GOOG. The consumers leverage the different wildcard types to subscribe to multiple topics via one topic string.
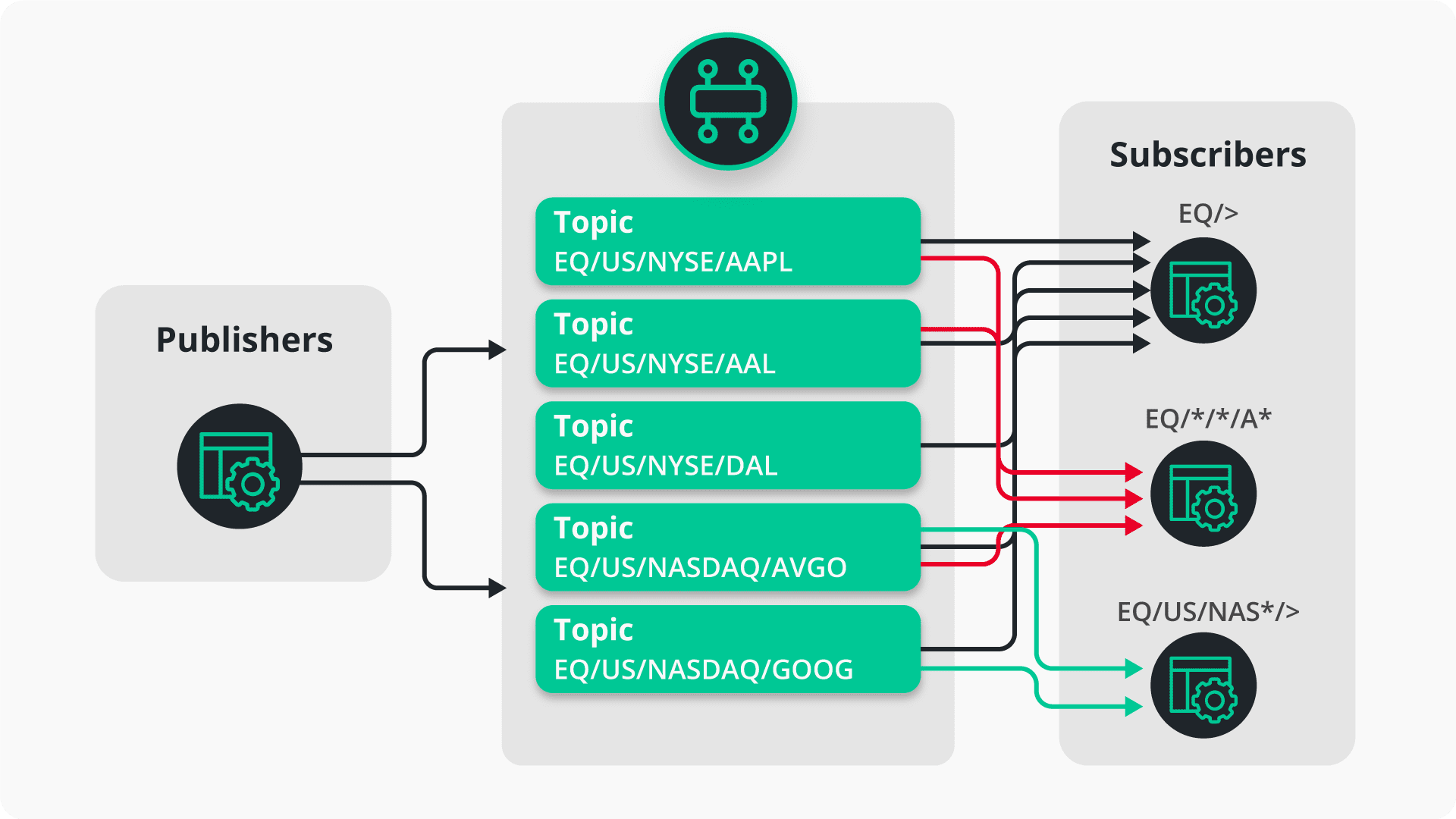
What happens if a new topic is referenced by a new message? Because topic matching is dynamic and evaluated on a message-by-message basis, any messages published to a new topic are automatically and immediately consumed without consumer intervention.
Kafka
Because Kafka topics are implemented as files, topics do not work in the same way in comparison to Solace. In the Kafka API, you can specify a pattern-based topic string that are compatible with Java’s regular expression Pattern class. Upon an initial subscription call, the Kafka Broker will interpret the pattern, perform a match to existing topics and bind the consumer to that topic. As messages are put onto the topic, the consumer will pull the messages from its bounded topic(s).
Using the same example as above, our example publisher publishes into various topics. The consumer connects to Kafka providing either a simple regular expression like * or a more complex pattern as demonstrated below.
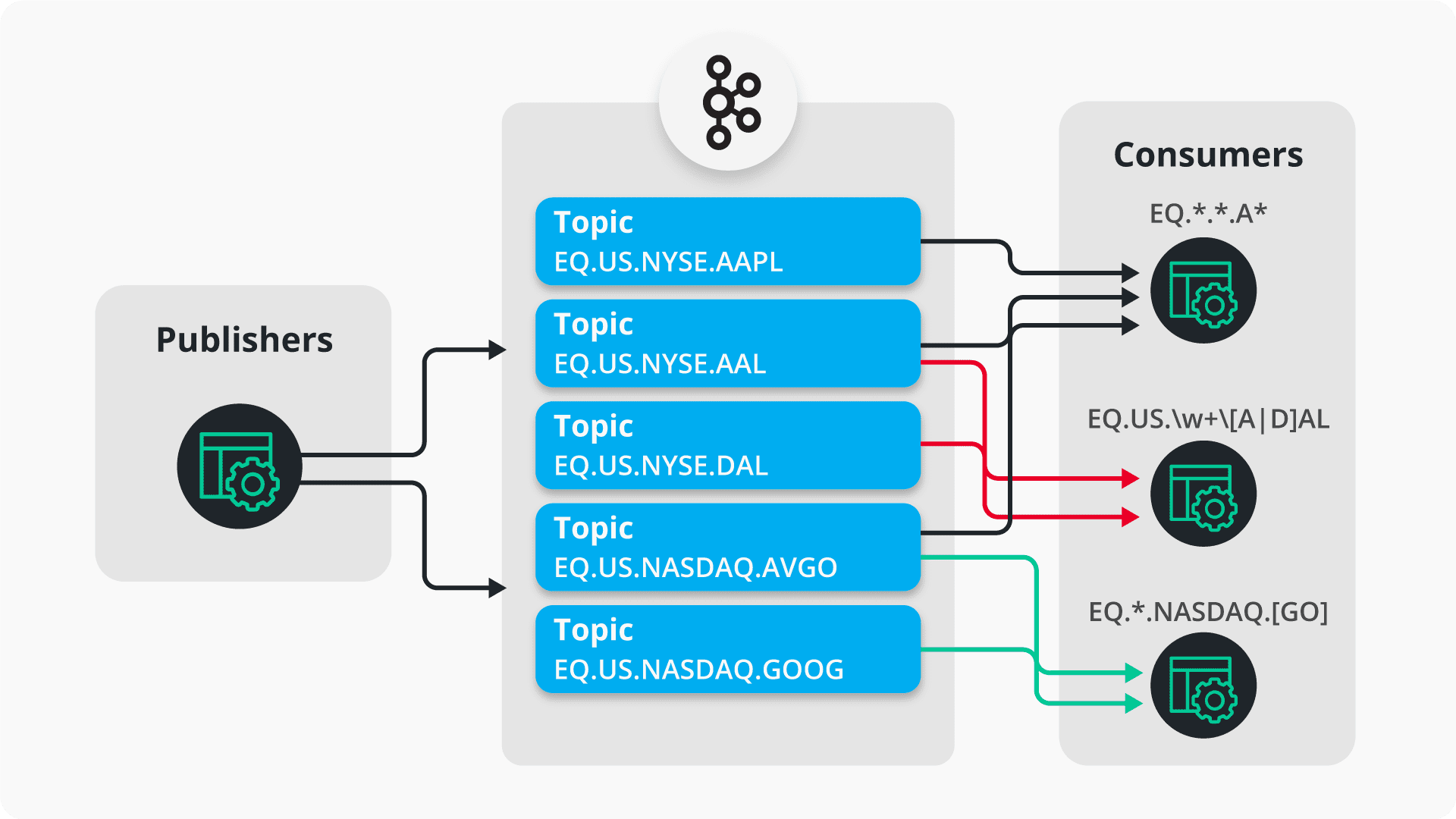
But will a consumer receive messages from a newly created topic after the consumer already created a wildcard subscription? Yes and no. Because Kafka is statically binding the consumer to matching known topics, it will miss any new topics created after the consumer connects. However, Kafka consumers perform a periodic metadata update. Any new topics are represented in the updated metadata and the consumer then connects to the newly created topic. Fortunately, that period of time is configurable via the metadata.max.age.ms parameter. The default value is 5 minutes, so it is possible for a consumer to receive delayed messages and/or miss the message entirely.
While the above example is valid, it is also unlikely since Kafka uses a flat, file-based topic system which makes scaling topics limited to physical resources like disk size.
Data on a topic can be distinguished and filtered based on a key (e.g., Topic=EQ.US.NYSE Key=AAL). But the filtering will occur on the consumer side. The client will receive all messages from a topic and then able to filter upon receipt for desired messages. This can be inefficient in regards to networking resources. In today’s environments, compute resources can be scaled based on needs but typically the network is not a scalable resource. A lot of unused bandwidth can be consumed by undesired messages. If you are incurring WAN charges, this could potentially be costly for data you are simply throwing away.
But it’s not just an inefficient use of bandwidth but CPU as well. If two consumers apply the same filter, they both need to process the entire message stream. Both consumers are using CPU cycles to filter for the same messages. In comparison to Solace PubSub+ Event Broker, the filters are applied in parallel and the message stream is only processed once.
Conclusion
In summary, Solace and Kafka have the ability to filter topics but in different ways. Solace uses wildcards in the form of single-level (*) and multi-level (>) wildcards in topic subscriptions whereas Kafka uses patterns as regular expressions. In the next post, we will talk about high availability in both brokers.
Explore other posts from categories: For Architects | For Developers



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.