The previous blog post in this series explained how many capital markets firms have ended up with a multitude of messaging technologies to handle different data movement requirements, the problems associated with that, and how Solace technology helps simplify such environments. This post drills in to how big data is leading companies in other industries down this same path.
According to Gartner, as of June 2014, 73 percent of organizations have or will be investing in big data in the next two years. While big data is intended to support both structured and unstructured data, many organizations start by analyzing their structured transactional data because it’s easier for them to understand, and can be more readily applied to optimizing operational efficiency.
During this phase, enterprises focus on how the big data technology will extract value from their data. They load all kinds of information into their big data lake using whatever tools are at hand or easiest to add to the mix. This allows them to start running analytics ASAP, with the problem of loading data in a demanding and unpredictable production environment left for later.
This can result in getting data into the Hadoop infrastructure in a variety of different ways: FTP here, Flume there, maybe some Kafka somewhere else.
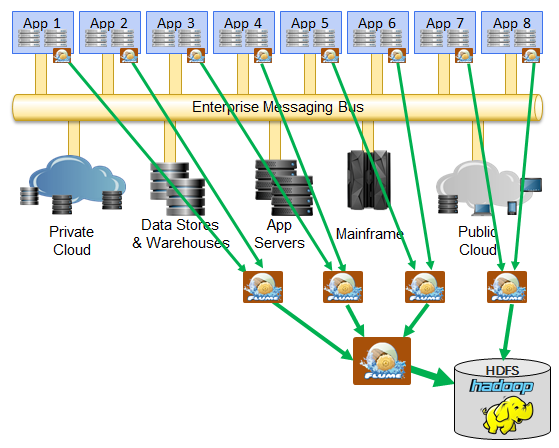 Some enterprises start with the messaging technology (or technologies) they use to link legacy applications but envision a completely separate and additional infrastructure based on Flume or Kafka that looks like this. This architecture shows a cascading Flume deployment intended to groom all data for two HDFS files into two distinct writers from many different sources.
Some enterprises start with the messaging technology (or technologies) they use to link legacy applications but envision a completely separate and additional infrastructure based on Flume or Kafka that looks like this. This architecture shows a cascading Flume deployment intended to groom all data for two HDFS files into two distinct writers from many different sources.
This means multiple data movement infrastructures go into production – all of which are point solutions that only solve the problem of getting data into Hadoop, and they can’t be used for other functions. Even for just big data you could end up with multiple technologies—you may start with cascading Flume instances or FTP because they’re simple and batch loading is sufficient, but when you then transition to streaming analytics, you need yet another technology to deal with the velocity of big data.
If you already use messaging for existing applications, why not use that same technology to stream this new data into Hadoop? The answer depends on the messaging you are using today:
- Most open source and commercial messaging technologies lack the scale and performance required by big data. In the open source community, it is this gap that was the impetus behind Kafka, which fills a role specifically for big data similar to what ActiveMQ, RabbitMQ or QPid do for integration.
- Some (older) messaging technologies are queue-based instead of pub/sub which requires a lot of manual configuration to make them work. As enterprises move to the new world of big data, they’re looking to shift to technology that is simpler and more cost-effective to manage, more cloud friendly, and that supports the required pub/sub capabilities.
- Most messaging brokers are poorly suited to big data because they don’t deal well with slow consumers. In all big data deployments, whether you’re using Hadoop itself, or Storm or Spark to feed data in, they all become slow consumers from the point of view of the messaging system. If the streaming messaging system is not designed to buffer effectively for slow consumers, you’ll find yourself with a significant scalability and manageability problem.
- In many cases, neither the team implementing big data nor enterprise architects nor the middleware teams want to take the risk of adding these data hungry, next generation applications to the existing production messaging systems because they (justifiably) worry about the instability that doing so might introduce.
What about Solace users? How do they move to a big data world? Here are a few real world customer examples:
- We have capital markets customers who transport all their post-trade information using our technology. This data is already moving through a massive real-time (sometimes global) pub/sub bus carrying the order and trade information to various post trade and middle office systems.
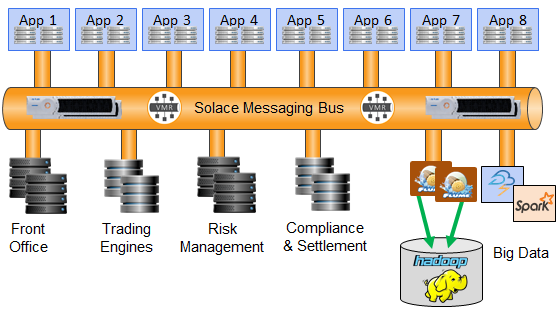 These are critical systems for their business such as regulatory reporting, settlement, risk, etc. Solace technology provides high rate, real-time pub/sub with the best slow consumer control in the industry and integrates with Flume, Spark, Storm and DataTorrent to name a few. This means a big data lake and stream processing can be added to the same bus as new consumers without any impact on other applications, without creating bridges to new transports and without needing significant initial and ongoing investment in an alternate transport system. These clients were able to focus on the big data technology and analytics – data acquisition was trivial.
These are critical systems for their business such as regulatory reporting, settlement, risk, etc. Solace technology provides high rate, real-time pub/sub with the best slow consumer control in the industry and integrates with Flume, Spark, Storm and DataTorrent to name a few. This means a big data lake and stream processing can be added to the same bus as new consumers without any impact on other applications, without creating bridges to new transports and without needing significant initial and ongoing investment in an alternate transport system. These clients were able to focus on the big data technology and analytics – data acquisition was trivial.
- Other capital markets clients are using our technology to move pre-trade prices, orders and risk information around the world. They are adding a big data lake and analytics to the existing bus, which can be used by operations staff to demonstrate when (or even if) a particular message was produced by a particular application, and by business users to monitor the prices they generate relative to various markets. In this case, some of the data being captured, specifically pricing, has a non-persistent QoS which means it is very high rate, bursty data, so bursts must be absorbed in a lossless manner by the messaging technology, and metered into the slower big data consumers.
- We have Telecom clients who have implemented Solace as part of an enterprise data grid to provide a real-time accurate, 360-degree view of the otherwise siloed information about their customers. The original use case was populating the enterprise grid in real time for use by web and mobile portals, and then other applications over time. When they added big data, the architecture remained the same, the Solace pub/sub technology remains the same, and they can add a data lake and the analytics they aspired to thanks to the maturing of new streaming analytics technology. They added new big data consumers to the existing bus and they were receiving real-time feeds of events changing in their enterprise.
In all cases, our clients did not need to deploy yet another data movement architecture to feed their big data initiative. This “single data movement” fabric has been made possible for Solace users due to the best of breed pub/sub performance, slow consumer control, robustness and manageability of Solace technology as well as its ability to integrate with both existing and new application technologies.
This is how Solace users are able to avoid the problem of ending up with many messaging products. Solace messaging is not built for a single use case, but rather it is built leveraging networking concepts and technologies to create an enterprise-wide application messaging fabric capable of supporting a wide variety of application demands. This allows our customers to focus on their applications – not the plumbing.
But what if I already have a few middleware technologies, and adopting Solace would make it the “yet another messaging product”? How can Solace help then? Stay tuned for part 3 of this series…
Explore other posts from category: Use Cases



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.