In this post, I have compiled a list of frequently asked questions regarding data mesh, its implementation, and how it relates to data lakes, data fabric, domain-oriented data, and event-driven data mesh. I hope you find these answers useful in your quest to unlock analytical data at scale.
What is a Data Mesh?
A data mesh is a paradigm based on distributed architecture that enables users to access, query, and discover analytical data from any data source rather than relying on getting output from a data lake or data warehouse. A data mesh supports the concept of “data as a product” where domain teams have ownership over their own data pipelines – a self-serve data platform, if you will.
Data mesh proponent, Barr Moses, calls it the “data platform version of microservices,” comparing it to the way teams have transitioned from monolithic applications to microservices architecture.
In a system built with microservices, small teams “own” well-defined slices of functionality. For example, a fulfillment team might own the “product shipped” microservice. The fulfillment team then also owns the database needed to run it and the data structures required to interact with it. Other teams access the microservice’s functionality using an API (in a traditional REST architecture), or the microservice emits events (in event-driven architecture).

A data mesh gives those same small teams ownership of a data product. In contrast to the microservice, which uses transactional data, the data product uses analytical data, defined as “the temporal, historic and often aggregated view of the facts of the business over time” that is “modeled to provide retrospective or future-perspective insights.”
Since the domain team knows the data the best, they are best equipped to define and oversee the data product. So instead of relying on a “data scientist” to figure out what fulfillment data would be helpful for analytics, the fulfillment team takes care of it themselves.
Why Do You Need a Data Mesh?
The term was coined by Zhamak Dehghani, who is a director of technology at ThoughtWorks, focusing on distributed systems architecture in the enterprise. She literally wrote the book on data mesh, so I’ll use her own words to introduce why enterprises need this new mesh:
“Data platforms must close the distance—time and space—between when an event happens, and when it gets consumed and processed for analysis. The analytics solutions must guide real time decision making. Rapid response to change is no longer a premature optimization of the business; it’s a baseline functionality.”
What’s behind all that? Dehghani is talking about the fact that today’s data lakes, data marts and ETL processes tend to slow down the rapid response required to succeed in today’s real-time world. Centralizing data, knowledge, and tooling for analytical data in a single place (like a data lake) stalls out innovative new features and slows data from reaching where it’s needed. Similar to how microservices and event mesh aim to address the issues with monolithic applications, the “data mesh” aims to address the issues with data lakes.
How Do You Implement a Data Mesh?
There are many ways to implement a data mesh, and an organization may allow multiple ways of accessing the same data product. Here are three possible approaches:
- Event-driven Data Mesh: When something changes within a data product, interested consumers are automatically notified.
- Query-Driven Data Mesh: Interested consumers can periodically query the data product’s database using SQL or another query language. Or using a query that federates multiple databases, get insights by combining multiple sources.
- File-Based Data Mesh: the data product is aggregated and put either a file or into a cloud-based file bucket
Again, it’s not an either/or decision, organizations should consider using some or all the approaches.
Advantages of an Event-Driven Data Mesh
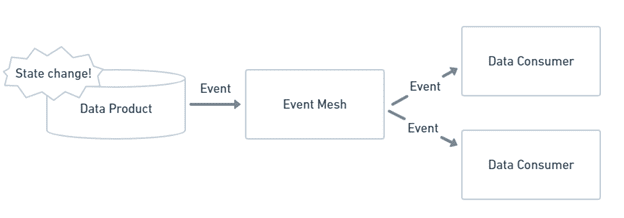
Event-driven architecture uses a “push” model of information delivery. When there is a change in a data product, a message that describes the change is sent out to an event mesh that links all the endpoints that send and receive data. The event mesh distributes that message to consumers that are interested. Find out more about event-driven architecture
Building a data mesh with event-driven architecture checks a lot of boxes for what you’d want in a data mesh:
- Emphasis on asynchronous interactions: Again, from Dehghani: “Over the last decades, the technologies that have exceeded in their operational scale have one thing in common, they have minimized the need for coordination and synchronization”
- Simple data distribution amongst multiple environments: The event mesh handles the underlying “plumbing” needed as data flows around the enterprise. Applications do need to know how to connect to applications running in distributed cloud and on-prem environments, just how to reach their favorite event broker.
- Analytical data in real time: the push model eliminates the need for data consumers to constantly poll for updates. Instead, new data is delivered as quickly as it is generated.
- Creates a single point for access control
Advantages of a Query-Driven Data Mesh
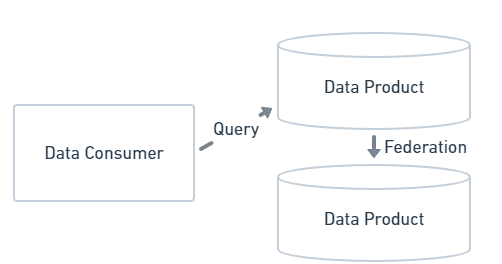
In a query-driven data mesh implementation, data product owners expose their databases to outside access. Individual databases also can be federated together to allow for queries over multiple databases.
There are multiple benefits to this approach:
- Keeps data close to data product owner. This reduces errors from copying data from place to place. And particularly in cloud environments, it reduces the cost associated with data movement.
- If users are familiar with SQL (or similar tooling) they can continue to use it, even after the shift to a data mesh.
- Having the ability to create adhoc queries gives users the freedom to create define their own time domains.
Advantages of a File-Based Data Mesh
Another approach is for a data product owner to create pre-aggregated data products, typically in file format, either on hard drives or in file buckets in the cloud.
There are a couple key benefits to this approach:
- If multiple consumers want the same data aggregated over the same time period, it prevents duplicated effort.
- If some teams don’t have the expertise to run their own analytics, having a pre-aggregated form of data provides easier access to insights.
Data Mesh vs. Data Fabric vs. Data Lake vs. Domain-Oriented Data – How Do They Relate/Differ?
In the words of James Serra, Data Platform Architecture Lead at EY, “a data mesh is more about people and process than architecture, while a data fabric is an architectural approach that tackles the complexity of data and metadata in a smart way that works well together.” In contrast to data fabric’s emphasis on the relationship between data sources (explained more below), the focal point in data mesh is the “data product” that exposes the domain’s data to outsiders (consumers). These data products consist of separate data persistence stores (e.g. databases or cloud object stores), along with services for accessing the data. Because data products are distinct from existing transactional datastores, the data mesh puts the onus on domain teams to design data products.
Data fabric is a design concept focused on technologies, working to standardize data management across environments (on-prem, multi-cloud, edge). Data fabric relies heavily on the “backbone” of a knowledge graph that describes the relationship between data sources throughout the entire fabric. Using this graph, machine learning and artificial intelligence determine the relationships between various sources of data and infer metadata automatically.
A data lake is a large body of data stored in a physical location where data domains are disconnected from the owners and operate in isolation from the data producers. The data lake concept typically focusses on a specialized team of data scientists using specialized tools to reformat data with wildly different formats, time domains and meta-data. The result? A lack of agility, and business insights. For a great write up of this, see https://www.linkedin.com/pulse/data-mesh-lake-jeffrey-t-pollock
Domain-oriented data is business information associated with a bounded realm of business functionality. For example, domain-oriented data for sales and distribution within an enterprise would be assigned to different domains. In data mesh, teams from business domains design, own and are responsible for their domain-oriented data products.
Other Quick Questions About Event-Driven Data Mesh
Now that you understand what a data mesh is, why you might want one, and the three ways you can implement it, I’ll try to proactively answer the questions that come up when I explain event-driven data mesh. If I’ve missed any, ask away in the comments or over in the Solace Community!
For an event-driven data mesh can I just install CDC on my transactional database?
Nope, that’s an “anti-pattern”! Transactional microservices and analytical data products care about very different things in their data. Remember, data products may be aggregated over different time periods and are used for analytics by many different consumers, so the transactional data and data products may have completely different data structures and access methods.
What kind of governance does an event-driven data mesh need?
Even though data products are the responsibility of each domain team, there are still common concerns that need standardized solutions. Things like security and privacy enforcement, meta-data management and more will need to be determined at the organization level. The key is that representatives from the domain teams should play an integral role in the decisions, not defer them to “experts” in a separate group.
Where does a self-serve data platform fit into an event-driven data mesh?
While the human element to governance is crucial, proper tooling and infrastructure is important as well. A self-service data platform catalogs, documents and provisions data products that are available to an enterprise. That helps to ensure that data products are actually used to further the business.
Conclusion
Data mesh brings domain-ownership to analytical data. Why? Giving control of analytical data back to the teams that create the data improves agility and re-use of crucial data. No matter how you choose to implement it, a data mesh can result in better decisions and a better customer experience.
Explore other posts from categories: For Architects | For Developers



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.