For much of the last decade, enterprises fought against data silos, isolated persistence stores holding untold but inaccessible knowledge. Their primary weapon was the data lake: a huge centralized datastore that held terabytes of domain-specific data in a single logical location. These lakes were first on-premises and then migrated to the cloud to save costs. With all an enterprise’s data in one place, the theory was that brilliant data scientists would spot trends using diverse data sets and give the business a strategic advantage.
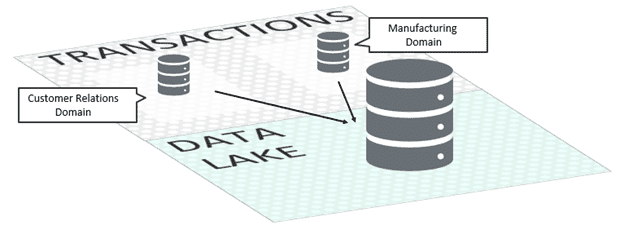
Traditional data lake architecture
It turns out data lakes bring challenges of their own. At least that’s the general takeaway from numerous experts, noting frustrations borne of:
- Data specialists with no domain knowledge trying to mine data gold out of disparate data sets.
- Data producers with little incentive to contribute quality data to the data lake
- Data consumers with no expertise left waiting for data specialists to prioritize their project
Among the proposed solutions: replacing or supplementing data lakes with a “data mesh” (advocated by Zhamak Dehgani in a 2019 blog post, a 2020 blog post, and a conference keynote presentation) or a “data fabric” (advocated by Gartner). Both fabric and mesh move data ownership back to domains. However, while these concepts are similar in naming and domain-centeredness, there are key differences. While the data mesh requires more upfront investment, it is more likely to improve your business’ decision-making, particularly when it utilizes an event-driven architecture.
Data Mesh vs. Data Fabric
Both data mesh and data fabric emphasize domains regaining control of their data, rather than pushing it into a data lake. Which makes sense: domains understand both their own data and how they want to utilize data from other domains. Both concepts envision separate planes: one for business transactions and an additional layer used for data.
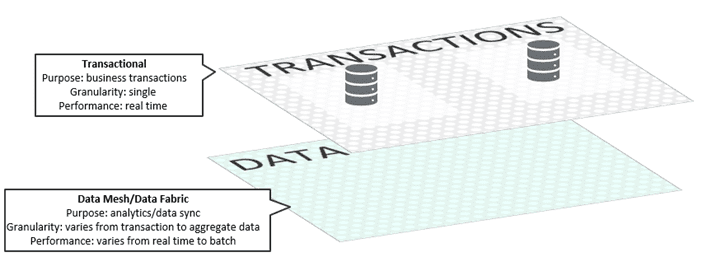
Moving towards a multi-layer architecture
These layers serve separate purposes and as a result have different characteristics. The transactional layer facilitates business use cases: a customer buys a pair of chinos or account information flows from Salesforce into SAP. In modern enterprises that means that each request goes to applications independently, and as close to real-time as possible. In contrast, the data layer supports analytics use cases: determining monthly sales numbers or updating the number of taxicabs currently on the streets of New York, for example. This information may travel in real-time or may be time-delayed in order to ensure quality. And transactions on the data layer can be combined into aggregate statistics, as opposed to being sent individually.
But pushing data back into domains reincarnates the original problem of data silos. The solution for both mesh and fabric relies on establishing connectivity between the domains, ensuring that data can be discovered and the quality can be governed.
What is a Data Fabric
Gartner’s conception of a data fabric relies heavily on the “backbone” of a knowledge graph. The knowledge graph describes the relationship between data sources throughout the entire fabric. Using this graph, machine learning and artificial intelligence determine the relationships between various sources of data and infer metadata automatically. The result is a catalog of data resources that can be used by consumers across the enterprise.
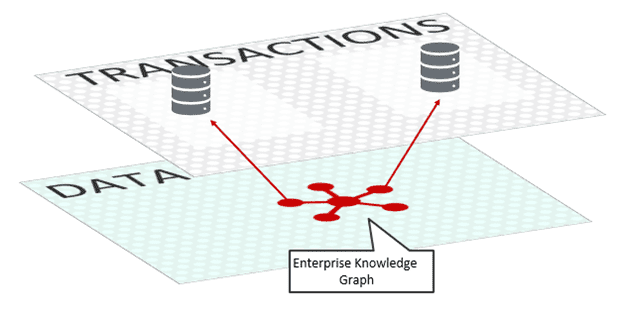
Data Fabric logical architecture
On the data access side, while there is support for events, data fabric puts a heavy emphasis on a request/reply interaction style. The knowledge graph allows natural language queries to be run against the knowledge of the entire enterprise. At high enough maturity levels, and given enough metadata, Gartner’s conception of the data fabric can automatically create integrations to allow for even higher order conclusions.
While there are undoubtedly benefits from an all-seeing, all-knowing, all-adapting knowledge graph, a major driver for the data fabric is cost savings and agility. Rather than creating additional data stores and creating additional services to access them, enterprises leverage existing datastores and services. Rather than defining standard metadata or mapping between differing conceptions of fields, machine learning does the work. After all, machines work quickly and don’t experience Zoom fatigue after attempting to figure out what “status” means to 14 different databases.
What is a Data Mesh
In contrast to data fabric’s emphasis on the knowledge graph, the focal point in data mesh is the “data product” that exposes the domain’s data to outsiders. These data products consist of separate data persistence stores (e.g. databases or cloud object stores), along with services for accessing the data. Because data products are distinct from existing transactional datastores, the data mesh puts the onus on domain teams to design data products. That means thinking critically about:
- What data outside domains would find valuable?
- What the best format for the data payload?
- What is the best metadata to include?
- What’s the best delivery mechanism for that data?
The process of creating data products also cements the ownership of both the transactional product and the data product by the domain team. There are huge benefits to domain-experts considering the needs of data consumers and creating metadata standards. And frankly, putting faith in ML/AI to work out challenges has not been working out so well lately judging by the headlines for one particularly famous Jeopardy! contestant.
The answers to these questions inform the design of data products, which most likely use a data format, metadata and delivery mechanism very different from those used for day-to-day business transactions. As Dehgani writes, “The source aligned domain datasets must be separated from the internal source systems’ datasets. The nature of the domain datasets is very different from the internal data that the operational systems use to do their job.”

Data mesh logical architecture
Once implemented, the domain team advertises the finished data product to outside domains for their consumption in a centralized governance system. The quality of the data product is the responsibility of the domain team, just like their services on the transactional layer. In practical terms that means bringing over concepts from the transactional layer: “Each domain dataset must establish a Service Level Objectives for the quality of the data it provides: timeliness, error rates, etc.,” writes Dehgani.
Flavors of Data Products
Intentionally designing data products allows domain teams the flexibility to customize both the specifications and the number of data products available.
Per Dehgani, the best way of distributing information on the data plane is through events that contain raw business data. For less sophisticated consumers and to allow more quality control, aggregating data into higher level information is also suggested. Here’s a brief comparison between different models of data product:
| Domain Data Events | Aggregated Domain Data Snapshots | |
|---|---|---|
| Format | Events | Serialized files on an object store |
| Time domain | Real-time | “Time interval that closely reflects the interval of change for their domain” |
| Granularity | Atomic | Aggregated |
| Data Quality | Lower level of accuracy, including missing or duplicate events | Higher expectations of clean data |
How to get started with an event-driven data mesh
Well-designed events let data consumers receive low-level raw data, sent in real-time information, with metadata that provides valuable context for the information. The price for those benefits is potentially redundant work as multiple consumers perform the same operations, along with lower data quality in the form of duplicate messages and less enrichment. In contrast, aggregated snapshots are updated less frequently, but in a more easily digestible form. Without access to raw data, there is less customization possible.
Assuming that your organization gives priority to developing domain data events over aggregate data snapshots, picking the underlying real-time event infrastructure becomes crucial. Without real-time infrastructure, the carefully crafted data products are just another data silo.
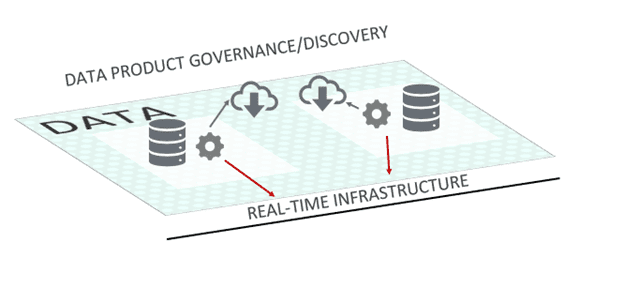
Supporting infrastructure for domain data events
What should you look for when choosing infrastructure for an event-driven data mesh? Candidates should be:
- Able to route and filter data events in a fine-grained, flexible manner. Since events are published every time a data source changes, certain data products could emit a flood of data events. The infrastructure must offer multiple ways of narrowing in on only data that a particular consumer is interested in.
- Flexible: Flexible topology integrates on-premises and cloud-based data sources to provide information regardless of where it lives. Flexible communication and diverse data sources (both emerging and legacy) should be able to connect to the infrastructure through multiple standard protocols.
- Rock solid in terms of reliability: Given the importance of analytics to decision making, the infrastructure needs to ensure high availability, guaranteed message delivery, fault tolerance, and disaster recovery.
- Secured: Fine-grained access based on a standardized hierarchy of information.
- Governed: When existing data products change, the complex impact on the data mesh needs to be clear. And to justify the added effort of new data products, they need to be visible to the rest of the enterprise.
- Standards-based: Utilizes metadata using both enterprise and open standard event formats such as CloudEvents
Conclusion
Event-driven architecture at the transactional layer accelerates customer interaction, giving businesses a leg up on their competition. One layer down, an event-driven data mesh can do the same for analytics, decreasing the time it takes to get answers to crucial questions using data from across domains. The first steps down the path are to choose an approach (data fabric vs. data mesh) and pick an event-driven infrastructure that can support the initiative.
Explore other posts from category: For Architects



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.