Introduction
Apache Kafka and Solace Platform are both leaders in the world of event-driven data distribution, but they represent different origins and approaches. Kafka is a distributed log built for high-throughput, durable event storage, and replay, while Solace Platform is built around an event broker that specializes in real-time data distribution across environments using a wide range of APIs and protocols.
This paper compares their architectures, messaging models, filtering strategies, and operational capabilities to help architects and developers understand where each shines. It also explains how they complement each other, because an increasing number of organizations are taking a hybrid approach: using Kafka clusters to serve applications that benefit from immutable log retention (such as stream processing and analytics) and Solace Platform to take care of the real-time distribution of those and other operational events across the enterprise and around the world.
From pub/sub mechanics to filtering logic, from HA to multi-site distribution, the differences between Kafka and Solace Platform are significant—if you’re building an integration layer, operational control plane, or AI-driven ecosystem, this piece will help you understand them.
Architecture
This section compares the foundational architecture of Apache Kafka and Solace Platform, specifically Solace Event Broker, showing how their design choices shape their strengths, tradeoffs, and suitability for different kinds of use cases. It also describes how they complement each other when the use-case benefits from both log and queue-based eventing/messaging. In considering architecture, we aren’t going to (yet) dive into the platform benefits that accrue to development, architecture and middleware teams in terms of ease of managing event driven architecture.
Kafka Architecture
Apache Kafka is a distributed log platform built to handle large volumes of event data with durability and horizontal scalability. At its core, Kafka stores messages in partitioned, append-only logs that are persisted to disk and replicated across brokers. Producers publish messages to specific topics, and consumers read those messages by polling from topic partitions and tracking their own offsets.
Kafka’s log-based architecture enables persistence, stream processing, and scaling by partitioning, but it also pushes a lot of messaging concerns — such as filtering, delivery guarantees, and ordering — to the application layer. Developers must think carefully about partitioning strategies, replication factors, and offset management to ensure data correctness. One of the key benefits of a log-based approach is the ability to batch process the logs and, in the matching use-cases, get high throughput to multiple consumers.
Older Kafka deployments, still in use, depend on external coordination via ZooKeeper while as of Kafka 4.0 KRaft is used. KRaft is a built in consensus protocol integrated in the broker to perform the same function. Additionally, organizations rely on additional services like Kafka Connect, Schema Registry, and ksqlDB to meet operational and integration needs.
Kafka architecture at a glance:
- Scales horizontally via partitioned, disk-based logs
- Pull-based consumption with client-managed offsets
- Strong support for event replay and stream processing
- Requires external components for coordination and filtering
Solace Architecture
Solace Platform includes a purpose-built event broker called Solace Event Broker that enables real-time, event-driven communication across distributed systems. Instead of relying on persistent logs and partitions, Solace uses a routing engine that dynamically pushes events from publishers to subscribers over hierarchical, metadata-rich topics. These topics support wildcard filtering, allowing consumers to express interest in a flexible range of events – while the topic subscriptions are also used to dynamically and intelligently route messages in a highly efficient manner.
Unlike Kafka’s client-managed model, Solace Event Broker handle message routing, delivery, filtering, flow control, and failover, freeing developers from implementing that logic. Solace supports a wide range of messaging patterns, including pub/sub, point-to-point, request/reply, and FIFO queues, and can deliver messages over multiple open protocols, such as MQTT, AMQP, JMS, REST, and WebSockets.
Solace also allows for processing in the event layer of your architecture. With Solace, message transformations are not done in the event brokers, but are pushed to the edge in micro-integrations. This has the benefit of enabling the routing layer to do what it does best – which is moving events at very high speed and very low latency. It also means that the application receiving the data doesn’t require the additional complexity and overhead to filter the data.. Critically, when it, event transformations can occur in a batch-type process while allowing the offsets to be tracked and maintained so that the queue is maintained.
Solace is also built with enterprise-grade high availability, offering active/standby failover and persistent message guarantees.
Solace architecture at a glance:
- Push-based event routing with fine-grained topic filtering
- Built-in high availability and flow control
- Native support for multiple open protocols (MQTT, AMQP, REST, JMS, etc.)
- No need for external coordination systems
Summary
In short, Kafka is a distributed commit log designed for scalable, durable ingestion and replay of large volumes of data — ideal for analytics pipelines and data lake ingestion. Solace is a high-performance event broker designed for routing and governing real-time messages between distributed systems — perfect for operational use cases, service mesh communication, and IoT.
While Kafka gives you low-level building blocks and replayable logs, Solace provides a more application-centric platform with built-in routing, filtering, protocol bridging, and high availability. Each excels in different contexts — and together, they often form complementary parts of modern data architectures. Logs where they are needed and queues where they are needed.
Publish/Subscribe Messaging
Both Apache Kafka and Solace Platform support the publish/subscribe messaging pattern — but they implement it very differently. This section breaks down how each system handles pub/sub behavior, including delivery guarantees, message flow, and ordering.
Kafka Pub/Sub Messaging
Kafka implements publish/subscribe via partitioned topics, where producers write messages and consumers subscribe to read from them. Messages in a single partition are ordered, but when topics are spread across multiple partitions, global ordering is lost. Developers can preserve ordering per key (e.g., per customer ID) by using a consistent partitioning strategy, but that limits parallelism and throughput and can get complex.
Kafka is pull-based — consumers must poll for new messages, manage their own offsets, and handle retry logic. This gives consumers flexibility, including the ability to replay historical data. But it also introduces latency and requires careful handling of backpressure, batching, and load balancing.
Kafka supports consumer groups, where messages are load-balanced across multiple consumers, but there’s no broker-side filtering — each consumer must receive all messages on a topic and filter them post-delivery.
Kafka pub/sub at a glance:
- Partitioned topics support scalable pub/sub
- Ordering only guaranteed within partitions
- Consumers poll for data and manage offsets
- No broker-side filtering — consumers filter post-delivery
Solace Pub/Sub Messaging
Solace Platform implements publish/subscribe through a topic-based routing engine that delivers events in real time using a push-based model. Producers publish messages to hierarchical topics, and subscribers express interest using exact topic strings or wildcards to match patterns. This gives applications flexible, declarative control over what messages they receive — with routing and filtering handled at the broker level. Importantly – routing is also only performed when there is a consumer at the other end using a technology called Dynamic Message Routing. This is very efficient and mitigates costs associated with replication across clusters.
Solace guarantees message order per publisher even when filtering across topics, and can deliver messages with varying qualities of service — including non-persistent best effort or persistent guaranteed delivery. Consumers don’t have to manage offsets or poll for data — they simply connect, subscribe, and receive messages as they arrive.
Solace supports a variety of pub/sub variations, including multi-protocol delivery, filtered fanout, and queue-based persistence for replay or backpressure handling, all without needing to build external stream processing apps.
Solace pub/sub at a glance:
- Push-based delivery with dynamic topic routing
- Broker-side filtering with wildcard support
- Ordering preserved across filtered messages
- Supports multiple qualities of service (best-effort or guaranteed)
Summary
Kafka’s pub/sub implementation is durable and scalable, but it comes with tradeoffs: consumers must poll for data, manage offsets, and handle out-of-order delivery across partitions. You get flexibility and replayability, but at the cost of developer complexity and added latency.
Solace offers a broker-managed pub/sub experience: messages are pushed to subscribers, routing is dynamic and filterable, and delivery guarantees are built-in. It simplifies application logic and enables real-time responsiveness with less overhead.
Kafka gives you raw throughput and historical access. Solace gives you precision targeting and real-time flow — both valuable, but in different kinds of systems. Importantly one does not replace the other as simple micro-integration can treat the Kafka cluster as a source that the queue-based system pulls from. It can also be a consumer where a local Kafka cluster serves a local application that benefits from its immutability ((i.e. analytics).
Message Queues
Solace Message Queues
Solace’s message queue capabilities provide a granular, message-centric approach that is highly advantageous for integrations across different use cases. Key aspects include:
- Guaranteed Delivery and Persistence: When a publisher sends a message to a queue, Solace ensures that the message is durably stored and delivered to a consumer, even if the consumer is offline or experiences a temporary outage. This is critical for reliable execution of applications, including those where intermediate results or commands cannot be lost.
- Load Balancing and Concurrency: Multiple instances of a consumer can subscribe to the same queue, and Solace will distribute messages across them in a load-balanced fashion. This allows for horizontal scaling of computationally intensive agents, ensuring that tasks are processed efficiently and quickly
- Point-to-Point and Publish/Subscribe Flexibility: Solace supports both point-to-point (queue-based) and publish/subscribe (topic-based) messaging. While publish/subscribe is excellent for broadcasting information to multiple interested agents, point-to-point queues are essential for direct communication between specific consumers or for ensuring that a task is picked up by only one available consumer.
- Fine-grained Filtering and Routing: Solace’s hierarchical topics and wildcard subscriptions enable highly precise filtering of messages. Consumers can subscribe to very specific event patterns, receiving only the messages relevant to their immediate tasks. This reduces network overhead and processing burden on the application layer.
- Request/Reply Patterns: Many interactions follow a request/reply pattern to guaranteed messaging. Solace natively supports this pattern, simplifying the development of these type of workflows.
An event mesh built with Solace Platform is an event distribution layer that supports many different operational needs across an organization without requiring application developers to custom develop the integration layer in order to get a queue type that meets their applications needs.
Contrast with Kafka’s Log-Centric Model
Apache Kafka, while an excellent platform for event streaming, takes a fundamentally different approach based on a distributed commit log. This distinction has significant implications for its suitability in real-time, dynamic integrations compared to Solace’s message queue model.
| Feature | Solace (Message Queues & Event Mesh) | Apache Kafka (Distributed Log) |
| Core Abstraction | Message queues and dynamic, hierarchical topics. Focus on per-message semantics and direct delivery. | Append-only distributed commit logs (partitions). Focus on ordered stream of records. |
| Message Delivery | Guaranteed, push-based delivery to consumers. Messages are removed from queue upon successful consumption. | Pull-based consumption from logs. Consumers manage their own offsets. |
| Scalability | Horizontal scaling of queues and consumers for load balancing. Dynamic topic creation is lightweight. | Scaling achieved by partitioning topics. Adding or rebalancing partitions can be complex. |
| Filtering/Routing | Native, fine-grained, hierarchical topic-based filtering with wildcards at the broker level. | Limited filtering at the broker level. Complex filtering often requires client-side processing or stream processing (e.g., KSQL). |
| Messaging Patterns | Supports publish/subscribe, point-to-point queues, request/reply, and non-persistent messaging. | Primarily publish/subscribe. Point-to-point and request/reply often require workarounds. |
| Operationality | Simpler to operate with centralized management and unified event mesh for distributed environments. | More complex operational model with dependency on manual partition management. |
| Use Cases | Real-time operational workflows, microservices, hybrid/multi-cloud integration, dynamic AI agentic systems, etc. | Log aggregation, event sourcing, stream processing for analytics, real-time ETL. |
Filtering and Topic Model
One of the biggest differences between Solace and Kafka lies in how topics are structured — and how filtering works. This section explains each platform’s approach to topic naming, subscription matching, and how they impact scalability and system design.
Kafka Filtering & Topic Model
Kafka uses flat topic names, with no hierarchical structure or metadata encoding. If a consumer wants to receive a subset of messages, they must subscribe to specific topic names or use regex-based subscriptions to match patterns across topics — but these patterns are evaluated only at the client side, not by the broker.
Kafka brokers do not perform filtering. Once a consumer subscribes to a topic (or pattern), it receives all messages published to the matching topics. Filtering, transformation, and business logic must happen downstream — either inside the consumer or with intermediary processors like Kafka Streams or ksqlDB.
Because Kafka topics are tied to partitions, they can’t be created in large numbers without performance impact. Systems that try to encode metadata (e.g., order.<region>.<status>) into topic names often run into scalability limits due to Kafka’s tight coupling between topics and partitions.
Kafka topic model at a glance:
- Flat topic namespace (no hierarchy)
- Regex-based filtering at the client side only
- Filtering logic must be handled by consumers or stream processors
- Topic explosion can create scalability and resource problems
Solace Filtering & Topic Model
Solace was designed with flexible filtering and topic navigation at its core. Messages are published to hierarchical topics that encode metadata — like order/created/us-west/customer123. Consumers can subscribe to exact topics or use wildcards (e.g., order/created/> or order/*/us-west/*) to receive subsets of events.
Crucially, Solace performs this filtering at the broker level. Consumers only receive the messages that match their subscriptions — reducing network traffic, CPU load, and client-side logic. This model is especially powerful in environments with large numbers of topics or highly granular data.
Solace topics are decoupled from storage and performance constraints. You can publish to millions of distinct topic strings without worrying about resource contention or provisioning — which allows designers to model business events semantically rather than structurally.
Solace topic model at a glance:
- Hierarchical, metadata-rich topics
- Wildcard filtering built into the broker
- Efficient delivery with no need for client-side filtering
- Scales to millions of topics without performance impact
Summary
Kafka offers topic-level subscription control, but not filtering in the traditional sense. You can subscribe to topics by name or regex, but you’ll receive everything published there — then filter on your own. This is fine for analytics pipelines, but less ideal for operational systems with specific data needs.
Solace allows intelligent routing and filtering directly in the broker, based on rich topic hierarchies and wildcards. This model scales better, reduces infrastructure load, and simplifies consumer code — especially when topics reflect business metadata like location, type, or status.
Kafka treats topics as storage boundaries. Solace treats them as semantic routing paths. That difference defines how each system scales and interacts with the real world.
High Availability
Both Solace and Kafka offer high availability (HA), but the mechanisms, configuration complexity, and operational guarantees are quite different. This section explains how each platform maintains service continuity in the face of failures — and what developers and operators have to do to make it work.
Kafka High Availability
Kafka achieves high availability through partition replication. Each topic partition has one leader and zero or more followers across different brokers. Producers and consumers only interact with the leader, and the followers replicate data from it to ensure redundancy. If a broker fails, a new leader can be elected from the ISR (in-sync replica) set.
However, this architecture comes with tradeoffs. To ensure zero data loss, the producer must wait for acknowledgments from all replicas (acks=all), and unclean leader election must be disabled. If these aren’t configured correctly, Kafka may lose messages during failover or recovery. This means that HA is possible — but not automatic.
Kafka depends on KRaft for metadata coordination and leader election and setting up operational HA requires several considerations and ongoing monitoring.
Kafka HA at a glance:
- Partition-level replication provides redundancy
- Correct configuration required to prevent data loss
- Failover time depends on leader election delays
Solace High Availability
Solace Platform provides built-in high availability using an active/standby pair model. Two brokers are configured together — one actively handles traffic, while the other sits in hot standby, constantly synchronized via synchronous replication. If the active broker fails, the standby takes over automatically, without message loss or service disruption. HA nodes are automatically deployed in all cloud managed instances with each broker deployed in a different availability zone – while deploying them for a self-managed scenario is a simple configuration.
All message types — persistent or non-persistent — are supported in HA mode, and failover happens at the broker level, not at the topic or queue level. This simplifies system design and reduces the need for per-topic failover logic. Clients are automatically reconnected using reconnection logic and session persistence, with no need for manual offset tracking or retry strategies.
There is no external metadata system (like the now deprecated ZooKeeper) required because Solace has used a very similar approach to the KRaft consensus algorithm for years for assigning the primary and backup event brokers. HA is handled entirely within the broker HA node, making the architecture simpler, more predictable, and easier to manage in production.
Solace HA at a glance:
- Built-in active/standby broker HA
- Automatic failover with no data loss
- No reliance on external coordination services
- Works for all message types and protocols
Summary
Kafka supports high availability — but only with careful tuning. You need to configure replication, acknowledgments, and leader election settings correctly to avoid message loss. It’s powerful and scalable, but puts the burden on the operator.
Solace offers automatic, built-in HA that just works out of the box. There’s no need to architect around failover or teach developers how to recover from partition leadership changes — the platform handles it. This makes Solace a strong choice when resilience and operational simplicity matter.
Multi-Site Architecture
Enterprise systems often span multiple data centers or cloud regions, making multi-site messaging a critical requirement. Both Kafka and Solace support these deployments, but they approach the problem with different assumptions, tradeoffs, and tooling.
Kafka Multi-Site Architecture
Kafka supports multi-site replication through MirrorMaker 2, a separate tool that copies data between clusters. It works by consuming from one Kafka cluster and producing to another, creating a “mirrored” version of topics. While flexible, MirrorMaker is asynchronous, meaning data loss or duplication is possible during network failures or failover. However, this is not a really true apples-to-apples comparison of how Solace manages this need; to bring this type of functionality to the organization generally third party tools need to be licensed generally alongside costly full stack Kafka-based solutions.
Kafka does not natively propagate subscriptions across clusters, and it doesn’t support bi-directional replication safely out-of-the-box. If messages are mirrored back and forth between clusters, loops can form unless you explicitly rename topics or use complex routing logic. Kafka also lacks built-in awareness of cluster topology — it treats every broker and topic the same, whether it’s across the hall or across the ocean.
To build a resilient multi-site Kafka deployment, you typically need to manage:
- Independent clusters in each region
- MirrorMaker pipelines
- Topic renaming conventions
- Failover orchestration
- Potential re-ingestion logic
Kafka multi-site at a glance:
- Uses MirrorMaker 2 for cross-cluster replication
- Asynchronous — not guaranteed real-time or lossless
- No native support for bi-directional sync or loop prevention
- Requires careful planning of topic naming and failover flows
Solace Multi-Site Architecture
Solace was designed from the ground up for distributed, multi-region deployments. Its Dynamic Message Routing (DMR) capability allows multiple brokers to form a linked event mesh, where messages and subscriptions can flow intelligently between regions.
With DMR, brokers automatically propagate subscriptions across the mesh — meaning an event only flows to another region if a consumer there is interested. This enables demand-driven routing, rather than just bulk replication. Solace also includes built-in loop prevention, so bi-directional topologies “just work” without risking message duplication or infinite hops.
Solace supports fine-grained control over what gets shared between sites (e.g., which topics, which clients, which QoS levels), and offers robust network and latency optimization tools. Failover between regions is handled seamlessly, and consumers can reconnect to alternate brokers without re-architecting.
Solace multi-site at a glance:
- DMR links brokers into an event mesh
- Subscriptions propagate automatically across sites
- Loop prevention built-in for bi-directional routing
- Supports real-time, on-demand cross-region flow
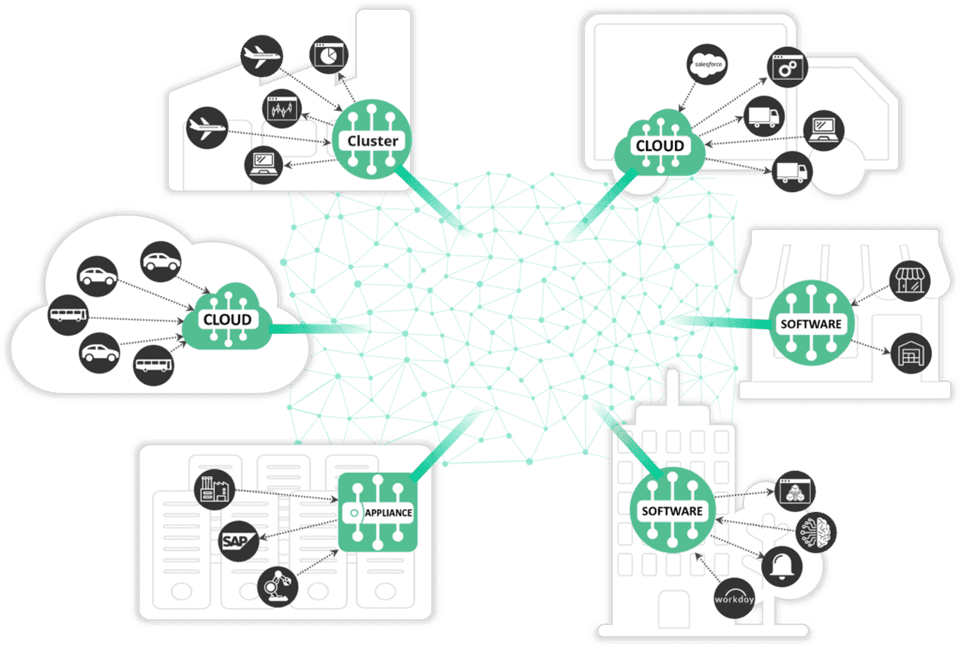
An event mesh built with Solace Platform is an event distribution layer that supports many different operational needs across your organization. DMR enables the efficient movement of events without requiring application developers to custom develop the integration to meet their applications needs.
Summary
Kafka gives you multi-site messaging — but you have to build and babysit it. MirrorMaker gets the job done for one-way replication, but lacks the awareness, governance, and responsiveness needed for dynamic event routing. Most organizations need custom naming conventions and failover orchestration to make it work.
Solace offers a native event mesh that handles subscription-aware routing, loop avoidance, and cross-region delivery out of the box. It’s built for real-time, distributed systems, with governance knobs and runtime intelligence baked in.
Kafka replicates blindly – which is not a bad thing when it is needed. Solace routes with purpose.
Operational Use Cases: Filtering + Ordering
Many business processes rely on more than just high throughput — they need precise control over message flow, such as filtering specific event types and preserving the exact order of events tied to a customer, transaction, or asset. These operational use cases are where the differences between Kafka and Solace really start to show.
Kafka in Filtering + Ordering Use Cases
Kafka supports ordered delivery within a partition, but as soon as a topic is partitioned for scale, ordering across messages is lost. Developers can preserve order for a given key (e.g., customerId) by always sending those messages to the same partition, but this limits parallelism — one key, one partition. It’s a fundamental tradeoff: the more you parallelize, the more you sacrifice ordering.
Filtering in Kafka is not broker-aware. You can’t say “only send me order updates from the western region” and have the broker handle it. Consumers must subscribe to entire topics (or sets via regex) and do their own filtering post-consumption. If the filtered events were scattered across many partitions, you may need to buffer, re-order, or coordinate between threads to get the right event sequence.
This makes building real-time systems like order lifecycles, payment flows, or customer state machines more complex. Developers often resort to using Kafka Streams or ksqlDB to bolt on additional filtering and sequencing logic — which adds operational and architectural overhead.
Kafka ordering + filtering at a glance:
- Order guaranteed per partition, not across topics
- No broker-side filtering — consumers must handle it
- Partitioning strategy directly impacts ordering and scalability
- Often requires external processing layers to manage logic
Solace in Filtering + Ordering Use Cases
Solace allows fine-grained filtering and strict ordering to coexist. Because messages are published to hierarchical topics, developers can embed metadata like region, status, or channel directly into the topic string. Consumers then subscribe to only what they need — using wildcards — and the broker delivers only matching messages in the correct order.
Solace ensures order is preserved across all matching messages from a single publisher, even when filtered by topic. There’s no need to sacrifice parallelism — Solace handles high-throughput delivery while maintaining per-stream order at the transport level.
This makes Solace ideal for transactional workflows, operational dashboards, real-time control loops, and any system where event sequencing matters. Developers don’t have to think about how messages are partitioned or how to reassemble streams — the broker handles all of it.
Solace ordering + filtering at a glance:
- Ordering preserved across filtered topics
- Broker-level filtering with wildcard support
- No need for custom buffering or sequencing logic
- Ideal for transactional, stateful, or control-driven apps
Summary
Kafka gives you filtering after delivery, and ordering within partitions — but not both together at scale without added tools. Building stateful, sequence-sensitive workflows takes extra effort, careful partitioning, and often external stream processors.
Solace gives you precise filtering and strict ordering simultaneously, without sacrificing scale. The broker does the work, not your app. That means fewer bugs, simpler code, and cleaner architectures — especially in systems where the order of operations is business-critical.
Kafka makes you choose between scale and precision. Solace lets you have both.
Flexible Event Routing
Flexible event routing is about more than just getting messages from A to B — it’s about ensuring the right events reach the right systems, at the right time, in a way that’s scalable, maintainable, and adaptable as business needs evolve. This section explores how Kafka and Solace handle that challenge.
Kafka Event Routing
Kafka topics are flat namespaces, usually with names like orders, payments, or inventory-changes. Because routing is based entirely on topic name and partition, there’s no native support for routing based on event metadata — like region, channel, product type, or customer.
To route events intelligently, teams either:
- Create many narrowly scoped topics (e.g., order.created.us, order.canceled.eu) — leading to topic explosion, or
- Use generic topics and rely on consumers or stream processors to inspect message payloads and decide what to do
Both approaches come with tradeoffs. Too many topics bog down the cluster (each topic = multiple partitions = more resources). Too few means all consumers get all messages, even if they only need 5% of them. Kafka doesn’t support dynamic or hierarchical routing, and all routing intelligence must be built outside the broker.
Kafka routing at a glance:
- Flat topic structure with no metadata awareness
- Routing based on manual topic naming or stream processing
- Risk of topic explosion or over-consumption
- No built-in support for event re-use or routing evolution
Solace Event Routing
Solace is built for intentional, metadata-driven routing. Its hierarchical topic structure lets publishers embed rich attributes in the topic itself — e.g., order/created/us-west/high-value. Subscribers use wildcard patterns to subscribe to exactly the slice they care about: order/created/> or order/*/us-west/*.
Because this filtering happens in the broker, not the client, consumers never waste cycles inspecting irrelevant messages. Solace can support millions of topic permutations without performance impact — making it easy to model business semantics without worrying about scale.
This routing flexibility also enables event reuse. The same message can be consumed by fraud detection systems, analytics pipelines, inventory updates, or mobile push services — all subscribing to their own slice of the topic space.
And because topics are descriptive and decoupled from infrastructure, developers can evolve them without breaking consumers — a huge win for long-lived systems.
Solace routing at a glance:
- Hierarchical, semantic topics with rich metadata
- Supports precise, broker-side routing
- Enables event reuse and evolution without disruption
- Handles millions of topic variations efficiently
Summary
Kafka routes messages based on topic names and partitions — and expects developers to figure the rest out. You can scale it, but you can’t bend it easily. There’s no room for dynamic routing, semantic targeting, or evolving structures without adding complexity.
Solace gives you a routing fabric that adapts with your needs. You can filter by metadata, reuse events across domains, and introduce new subscribers without changing publishers. It’s more flexible, more intuitive, and better suited to systems that need to evolve over time.
Kafka routes by structure. Solace routes by intention.
Support for Agentic AI
Getting source data to the LLM in real-time is really a traditional application of an event queue and delivers all the same benefits discussed throughout this comparison paper. Agentic AI workflows are a significant advancement from so-called traditional linear application use cases, where there is a single cause and effect integrated via RESTful programming.
Instead of following pre-defined, rigid instructions, AI agents autonomously perceive their environment, reason about tasks, make decisions, and execute actions, in collaboration with other agents (both LLM and traditional) to achieve complex goals. Along the way information is transformed and routed dynamically in ways that aren’t necessarily planned by a developer that added their event to the event mesh or that coded a microservice for it. As more and more intelligence is built into complex global integration patterns, it makes the importance of EDA that much more important for flexibility and for vertical and horizontal scaling as well as adding new agents to the system.
Kafka for Agentic AI
A log-based system is beneficial for many blackboard-style patterns where the storage-focus of the logs would preclude the need for other storage patterns and where performance and message order isn’t critical. With a typical AI system you aren’t generally processing large number of logs at a time due to the latency inherent in LLMs so the benefits of batching isn’t always as obvious.
However, in a pure data-streaming-type application where the applications are self-contained to deliver on a single use case, the blackboard topic pattern fulfilled by logs may be a preferred method of scaling events to the worker agents. If this pattern is beneficial, then upstream the event mesh may still delivering events to a Kafka cluster subscriber (same as it may to a vector database in a RAG workflow) that is connected to the event mesh. This is the notion of Solace AND Kafka discussed previously – one does not necessarily negate the other.
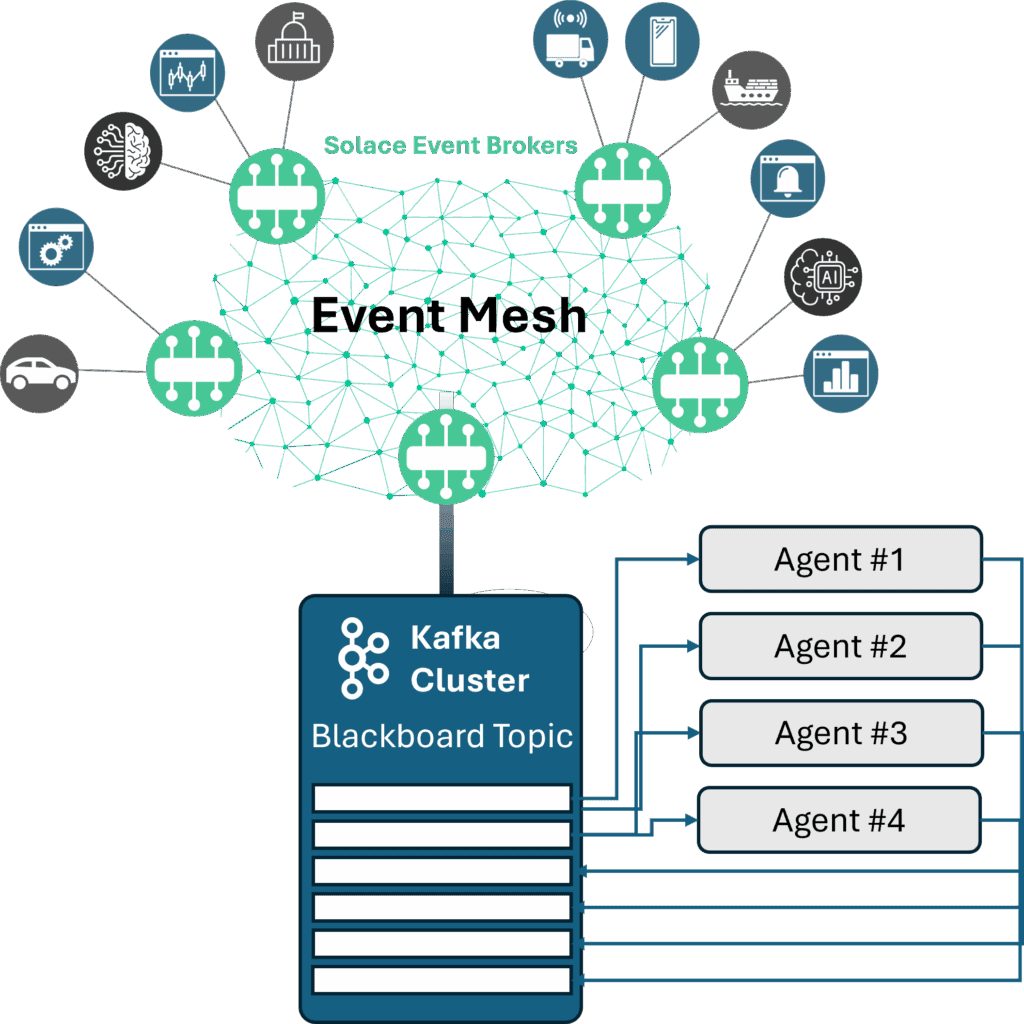
In simple blackboard applications, Solace simply treats the Kafka cluster like any other application in the organization, where Solace moves the operational data and Kafka stores the logs used by multiple agents similar to how a data store is used.
With the log structure of Kafka, you are potentially introducing a lot of operational complexity for an agentic system. Instead of a simple event mesh where your new subscribers automatically start attracting events that they are interested in, you have a situation where you are scaling out topics and partitions that can quickly get very complex as AI becomes more and more multi-nodal solution in an organization.
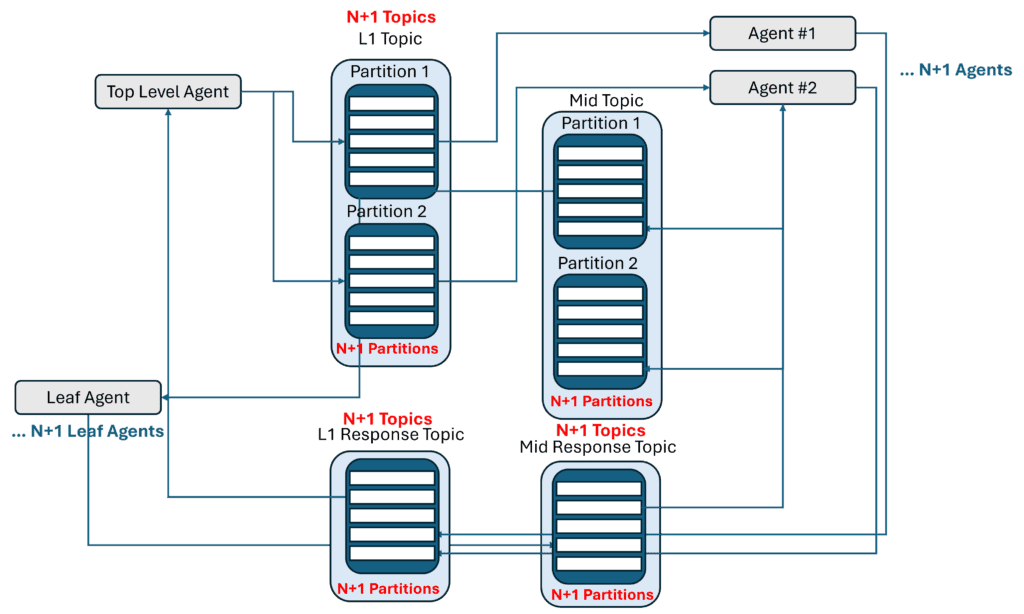
With multi-agent hierarchical orchestration, Kafka complexity can grow very quickly in terms of topics, clusters and partitions as agents are added to systems that may be better served by a queue-based event broker.
Additionally, you will still need to create and manage your own agentic framework if you require both orchestration and gateways to manage the movement of events and the governance over what humans and LLMs can access what events. Without the benefit of a platform, this can be complex to manage. Solace offers both the platform and the framework.
Solace for Agentic AI
Deploying EDA with Solace Platform provides an incredibly useful foundation for bridging AI with enterprise systems, such as RAG pipelines, and for creating automated multi-agent systems. Both use cases benefit from high performance, low latency queues and the topic flexibility and event routing that comes from the Solace Platform.
Common use cases in AI include those applications that leverage a “blackboard” design with events distributed to multiple LLMs for different uses, and an “orchestrated” design where the movement and transformation of the event(s) goes across LLM, databases, and microservices/applications. The former case is a traditional pub/sub workflow that a queue-based solution has excelled at for years. The latter one demands, by definition, an event-based focus in order to even work at any kind of scale.
Solace Agent Mesh: An Event-Driven AI Fabric
Solace Agent Mesh is an agentic AI framework that orchestrate and facilitate these multi-agent AI systems. At its core, it leverages the power of Solace Platform combined with the orchestrators and gateways needed for integration. Because this is a comparison paper versus a log broker, we will discuss the importance of Solace Platform for these workflows.
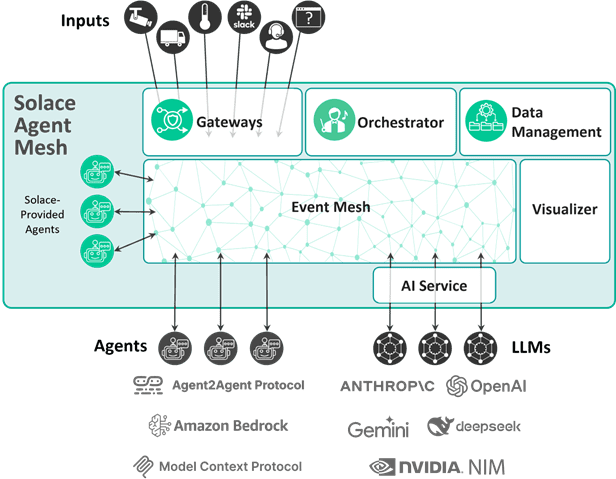
For dynamic AI agentic workflows where agents need to interact with varying patterns, receive precisely filtered information, and guarantee delivery of critical commands, Solace’s message queue approach offers a natural and efficient fit. The ability to create dynamic, hierarchical topics on the fly, coupled with native support for diverse messaging patterns, allows AI agents to communicate with the agility and precision required for autonomous operations. While Kafka excels at high-throughput log aggregation and stream processing for analytical use cases, Solace provides the real-time, event-driven backbone essential for the intelligent, interconnected world of AI agents.
Security
Security is more than just encrypting the pipes that move data in event driven architecture — it includes controlling who can publish and subscribe, it gives operators the tools to govern and audit access, it provides the advanced observability that DevSecOps needs…AND it protects the data in transit. Kafka and Solace both support enterprise-grade security, but they approach it very differently where the latter is an enterprise solution while the former has tools that you need to deploy and manage on your own. Let’s look deeper.
Kafka Security
Kafka supports a wide range of security features — but they’re modular, decentralized, and complex to configure. Authentication can be handled via SASL (with options like Kerberos, SCRAM, or OAuth2) or mutual TLS. Encryption in transit is achieved via TLS, but must be configured separately on every component. We also should mention that third-party support for Kafka may come along with its own security protocols as part of their license models.
Authorization is enforced via Access Control Lists (ACLs) on topics, consumer groups, and other resources. These ACLs are stored and managed per broker, and tools for managing them at scale are often third-party or custom-built.
Kafka security isn’t just about the broker — it also requires you to secure:
- ZooKeeper (older deployments)/KRaft metadata layers
- Kafka Connect
- Kafka REST Proxy
- Schema Registry
- Any other adjacent systems in the stack
This modularity gives power and flexibility, but it also introduces a larger attack surface area and more operational complexity that do create more risk to me mitigated.
Kafka security at a glance:
- Supports TLS, SASL, OAuth2, ACLs
- Configuration spread across many components
- Requires external tools for certificate and identity management
- Fine-grained control available, but difficult to centralize
Solace Security
Solace provides centralized, broker-native security controls across all supported protocols. Authentication can be handled via LDAP, OAuth2, SAML, or certificates, and is managed consistently across MQTT, REST, JMS, AMQP, and WebSocket clients. Encryption is supported out of the box via TLS, with unified certificate management built into the broker UI and CLI.
Authorization is handled via Role-Based Access Control (RBAC) and Access Control Lists (ACLs) applied to topics, queues, and operations (e.g., connect, publish, subscribe). Solace also supports multi-tenant governance, allowing administrators to segment access by business unit, region, or application group — all without needing separate brokers or clusters.
Solace’s security posture is designed for operational simplicity — all configuration is centralized, and changes can be audited, exported, and automated. It also supports per-user and per-client policies, session-level encryption, and integration with enterprise identity providers.
Finally, as an enterprise-focused organization, you get the benefit of Solace having the critical ISO and SOC requirements fully in place with the document library you need for your own compliance documentation.
Solace security at a glance:
- Centralized TLS, auth, and RBAC across protocols
- Unified certificate and identity management
- Multi-tenant controls without infrastructure sprawl
- Designed for regulated and zero-trust environments
Summary
Kafka gives you powerful security tools — but they’re distributed, low-level, and often DIY. You get the flexibility to choose your auth mechanisms and roll your own governance model, but it’s up to you to stitch it together and maintain it across components.
Solace bakes security into the platform. From TLS to topic-level access control to identity federation, it’s all natively supported and centrally managed. That makes it easier to meet compliance requirements, onboard teams, and evolve policies over time.
Kafka gives you the security building blocks. Solace has already used the blocks to build you the vault.
Conclusion
Apache Kafka and Solace Platform each bring powerful, but distinct, capabilities to the world of event-driven architecture. Kafka’s log-based approach can be beneficial for use-cases that need durable storage and batch processing, such as analytics. Solace Platform, by comparison, offers dynamic routing, protocol bridging, and fine-grained control for real-time operational use cases and for hydrating databases for applications like retrieval augmented AI.
Rather than making a choice between them, many organizations are embracing both—using Kafka where log-based processing is essential, and Solace Platform to orchestrate and distribute real-time events across hybrid, multi-cloud, and edge environments.
The architectural decisions you make today will shape the agility, scalability, and complexity of your systems tomorrow. By understanding where Kafka and Solace differ—and where they fit together—you can design event-driven systems that are not only performant, but purpose-built for the challenges ahead.