This guide is for developers, architects, middleware managers, and operations managers. It is intended to help them understand what capabilities to look at when evaluating options for an event broker when their need is operational, such as executing and settling financial transactions, fulfilling orders, managing inventory, and the command and control of connected appliances and vehicles.
This guide is not intended to rank specific products, but to focus on features, capabilities and attributes, and where they apply.
Overview
Event brokers and the event-driven architecture they enable help organizations deploy time-sensitive applications and business processes at scale. As architecture, it is hidden to the end user, but by simplifying and modernizing the application framework an event broker can create seamless digital experiences for customers.
This guide is intended to provide a checklist of capabilities organizations typically look for when selecting an event broker for an operational use case. It divides event brokers into two categories: log broker and smart broker.
With market maturity there is overlap in many of the features and capabilities of the two types. However, in practice it can be difficult to fit one broker to a different use case than it was designed for. These difficulties increase development and maintenance costs, compute and storage costs, software licensing costs, SaaS subscription costs, and system latency, or can result in outright failure/message loss as you scale.
Software engineers often try to use their preferred technology to solve all of their EDA use cases. This frequently stretches the technology beyond its functional design, leading to failed implementations.”
– GartnerSource: Gartner “Select the Right Event Broker Technologies for Your Event-Driven Architecture Use Cases”, 19 June 2023, Andrew Humphreys, Keith Guttridge, Max van den Berk
While many thought-provoking articles have been written on the nuance of different broker types, we are going to keep it simple and clear. For operational use cases like payments, e-commerce, and plant operations a smart event broker is more suitable and for analytics use cases like financial accounting or performance monitoring a log broker is more suitable. Importantly – the two types work together very well in a properly federated system across an event mesh.
This guide does not recommend a specific event broker. It is intended to provide a checklist for helping the reader build their requirements list for their application or digital transformation project.
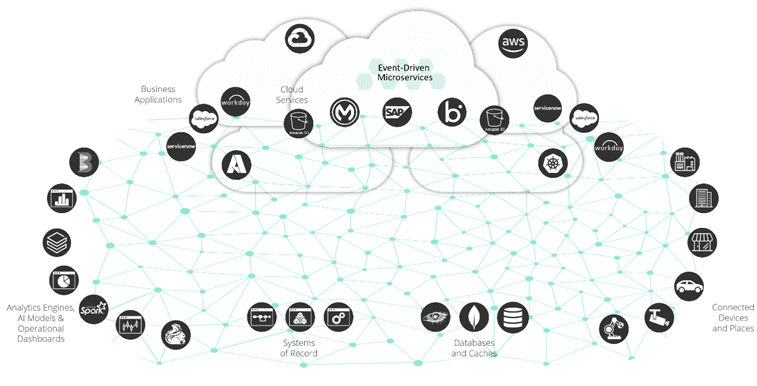
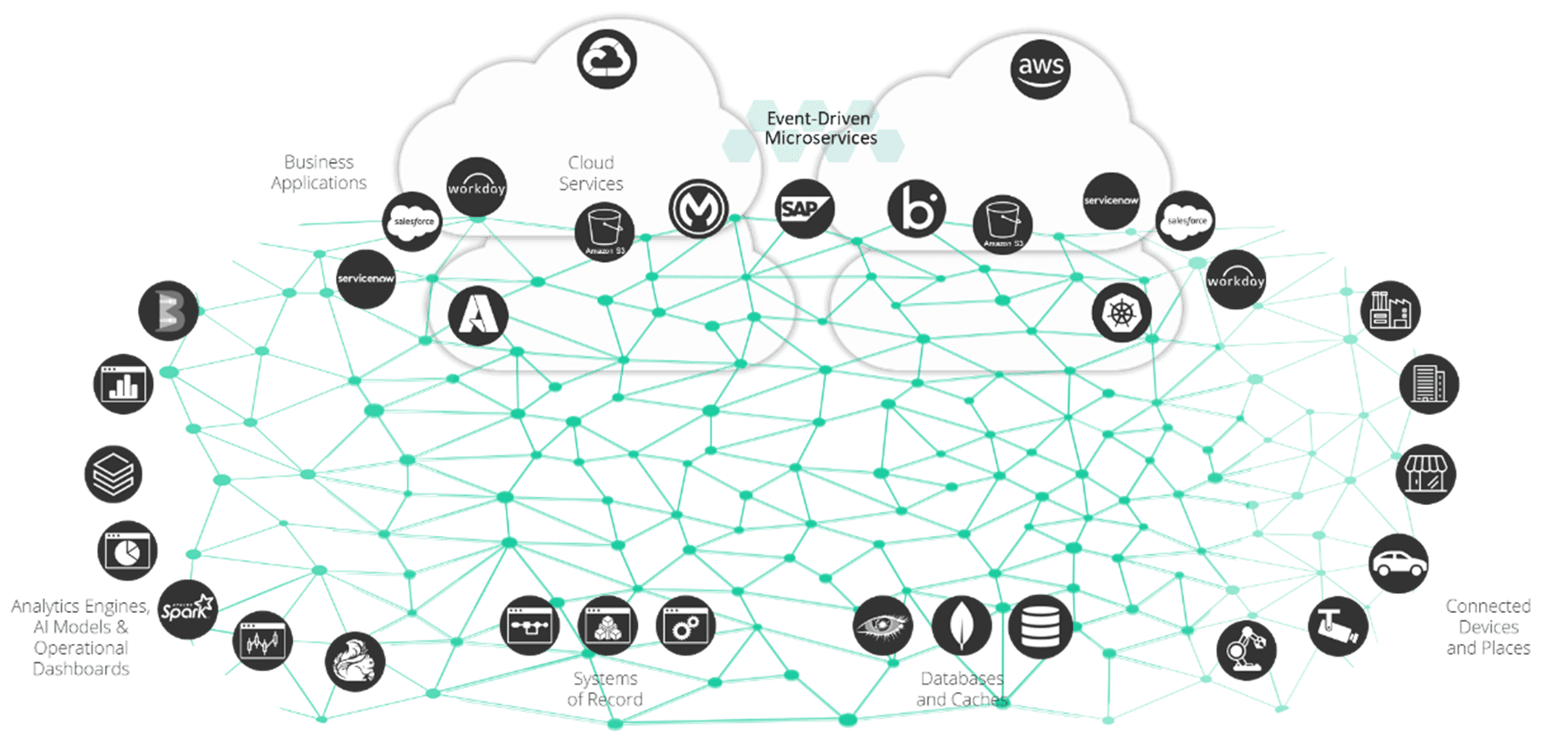
An event mesh connecting systems across an organization uses a queue-based event broker to move events
Requirements Checklist
This checklist summarizes the conclusions of each chapter of this guide into a feature list. You’ll want to customize it based on your needs and may break out the checklist item into several unique items as you see fit.
If you are an EDA expert, this may be all you need to get started on your own requirements list. If some of the terms are unfamiliar to you, then the chapters following this section will be helpful.
Fine Grained Filtering
- Topics can be defined and subscribed to hierarchically (aka Smart Topics)
- Events automatically routed by topic to all subscribing applications – and routing is stopped when there are no subscribers
- Topics manageable as part of a namespace for access control and security of the event
Rich Application Integration
- Supports the needed open messaging connectivity; like AMQP, Kafka, MQTT JS, Python, Node.js, Og, serverless, FAAS
- Supports modern frameworks like Spring™ for connectors, native iPaaS support, and native connectivity to major cloud platforms
- Supports the needed client integration like JMS, REST, .NET
- Supports IoT devices with MQTT for both readout and command-and-control
Messaging Functionality
- Message caching
- Message replay
- Support for more advanced messaging needs based on application state such as, in order delivery, delayed redelivery, TTL for messages, dead-message queues, message priority, and message durability/retention. (list requirements)
Event Observability
- Native implementation of OpenTelemetry specification for events
- Integration with application performance management (APM) vendors for managed broker services
- Managed OpenTelemetry collector for those using a managed service for the event broker
- Syslogs of broker operations fully documented and available
- Availability of native visualization and analysis tools for broker manager
Stream Partitioning
- Ability to bind broker partitions to consumers
- Ability to maintain event order as the partitions increase
- System to gracefully remove streams as the consumers are scaled down
- System to gracefully recover from consumer failures
Low Latency
- Predictable latency for systemwide design with a low variation
- Ability to define how the cache responds to live data when a new request is made for the topic
- A system to manage slow consumers and event delivery priority
- Defined operating environment (network, hardware, cloud-managed, or dedicated appliance)
Hybrid/Multi-Cloud Support
- Deployable in industry-standard containerized environments
- Available as both self-managed and vendor-managed options
- Meets operational and security requirements in all clouds (define requirements)
- Automatically connects and streams events to any newly connected brokers regardless of cloud with no configuration
Lossless Delivery
- Lossless delivery supported through a message spool
- Messages can be tagged as requiring persistent or non-persistent delivery based on the application requirements
- Supports multiple consumers with different consumption rates through queue configuration
Resilience
- Fast failover detection, recovery and resynchronization mechanism defined (including split-brain avoidance)
- Automated syncing of HA pairs states
- Selective messaging backup available (i.e. only need to backup guaranteed messages) for lower operational costs
- A method to monitor redundancy in place to ensure HA nodes are functioning
Replay
- Replay storage log distinct from message queues
- Ability to define the replay parameters by date and topic wildcards
- Configurable on how much data is stored and which message VPNs require replay
Broker Management
- In service upgrades
- Management available via GUI, CLI/API and Infrastructure as code (declarative)
- Documented SOC compliance and other security systems meet corporate standards (list requirements)
- User management and OAuth support for SSO compliance for broker management and the broker itself
Platform Completeness
- Platform broker has been tested and deployed in my use case
- Platform supports EDA design and event catalog, discovery, and audit
- Connectors for iPaaS
- Platform supports the full observability of logs, metrics, and traces including in-application dashboards.
The Two Kinds of EDA Use Cases
Enterprises employ event-driven architecture for many reasons and these reasons can be carved into many different categories – but almost every application of the technology can be grouped into one of two buckets: operational or analytical.
Analytical Use Cases
By contrast, we have analytical use cases, including audit. In these instances, latency and order aren’t generally required and may not even require 100% success in event delivery. While the concept of not needing low-latency or guaranteed delivery may sound strange to those not familiar with moving large numbers of asynchronous events, the reality is that there is a real and large cost to achieving this while also wanting log benefits that do include a very high performance at the scale needed to process large logs.
Examples:
- Fraud detection
- Financial reporting dashboards
- Security operations centers
Operational Use Cases
An operational use case, also called transactional, is defined by scenarios that require real-time publishing and consumption of events based on a trigger. Events may be consumed across multiple applications – also called subscribers. It is analogous to microservices that are intended to be decoupled and feature service reuse.
Examples:
- Processing a payment
- Fulfilling an order
- Provisioning a service
- Executing a stock or FX trade
Most operational use cases move very fast time and require a proven track record at a wide variety of volumes, with the ability to support bursty traffic (e.g. seasonal sales spikes, major capital market events, etc.). They also typically cannot lose messages and need some form of delivery guarantee. In all cases the order of the event flow matters, events go to one or more subscribers, subscribers consume at different rates, and once consumed events do not need to persist on the broker.
The Two Types of Event Brokers
Gartner and the IDC classify three general types of event brokers in their recent content: log, queue, and subscription. While these categories are technically precise, for operational use cases an event broker typically needs to support features of queues and subscriptions. These nuances are covered in their detailed reports but are hard to capture without a lot of background reading.
Forrester has defined a category called “smart broker” that we will use for this guide when making comparisons. While this is a more general term, it makes it easier for the reader to not think of an event broker as performing a single function within your infrastructure.
Smart Event Brokers
The term ‘event broker’ has its roots in message busses, message brokers, queue-oriented brokers, and the publish/subscribe message exchange pattern, aka as a subscription-oriented broker. In short, it is not the same technology as the bus, but the evolution of the bus to modern use cases. After all, you wouldn’t compare the original acoustic coupler modem you used with rotary phones with today’s optical fibre modem, but they still share some of the same name. To address the confusion, the industry has coined the latest iteration to be an event broker. This term covers two fundamentally different types.
An event broker is middleware used to transmit events between producers and consumers in a publish-subscribe pattern with support for order and integrity with exactly once, at most once, and at least once delivery. Additionally, event brokers can be connected into a higher-performance event mesh that is smart enough to know not to send an event to a location with no subscribers and therefore save egress, storage and processing costs.
An event broker supports:
- Event ledger by way of a permanent, append-only, immutable log of events. It is accessible as a data store for post-event analysis, machine learning, replay or event sourcing. In some cases, the event ledger may be used as the application’s record of truth.
- Security at various levels of authentication, authorization and topic/channel access control
- Filtering of the data content of the event object schema to apply control, distribution compliance and other policies
- Transformation of the notification data to fit the schema of the channel
- Operational analytics to improve efficiency of operations
- Optimization of scaling to support the varying traffic density of certain event types through intelligent clustering
- Tracking and billing for monetizing public access to event notifications
- Resilience by supporting high availability and disaster recovery
- Contextualization by including historic and other relevant data in directing notifications
- Custom processing by supporting programmable logic add-ons
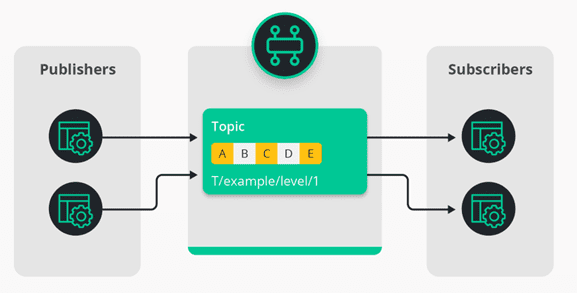
A queue-oriented event broker uses hierarchical topics to route events to subscribers and enables the decoupling needed in digital transformations and in modern applications.
Log-Based Event Brokers
The second kind of event broker is based on appending log messages. Logs (like messages) have also been around forever, and much like the prior discussion on the modern evolution of messaging, logs have also evolved.
In that context, a log-based event broker can also be performing a similar function to a database where it is persisting the same data across multiple partitions. And yes, there are a lot of interesting opinions out there about whether a log broker is a database (answer = not really).
Apache Kafka has come to dominate this category and there are many options for self-managed, or cloud-managed across dozens of companies with many related technologies to add capabilities to the core log-based functions – it has become its own ecosystem where the options are evaluated separately.
Additionally, vanilla Kafka is purely a log broker, but a lot of commercial tools and abstractions have been created to help make it function (or appear to function) like a queue broker when needed. For instance, while typically consumers pull for the latest information in a log, things like Kafka streams introduce the notion of “push-like” to help Kafka do what a queue broker is designed for. So we won’t go out on a limb and say it is a bad idea to use a log broker for operations – only that it may introduce costs to something you thought was free and open source.
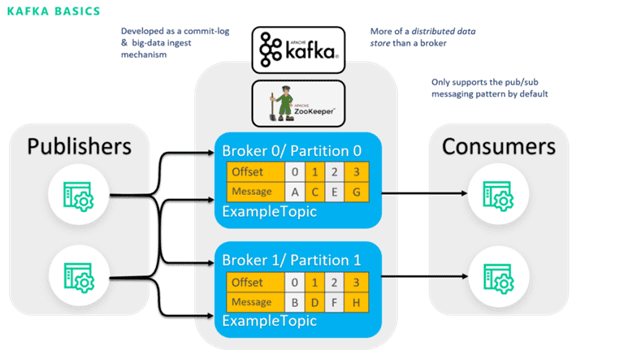
Kafka is the quintessential log-based broker where consumers are bound to partitions and there is coordination between the clusters.
Comparing Smart Event Brokers with Log-based Event Brokers
The high-level differences are summarized in this table:
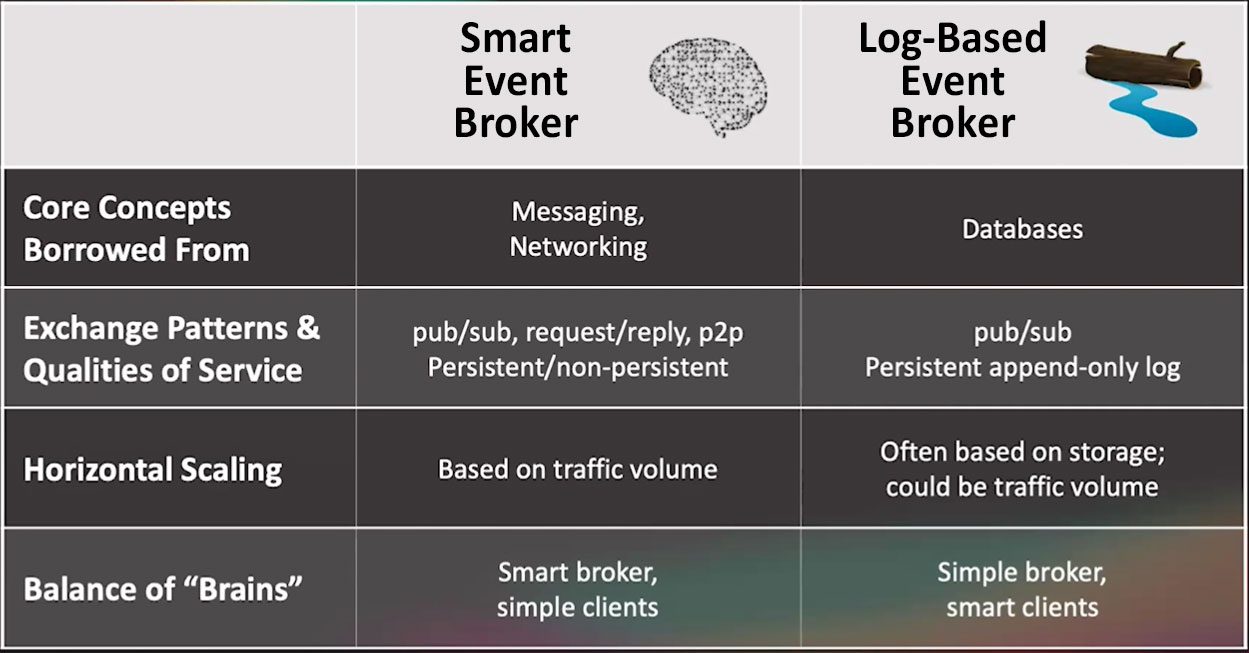
Source: EDA Summit 2023, How to pick the right event broker for analytical and operational use cases
A log broker is kind of like a big powerful freight train. You can use it to move large amounts of goods at the same time to a city, but it is hard to deliver every different product to every different store and you put the burden on the store to send a truck. A train could run on tracks running throughout the city, but that’s not practical.
An event broker is like a nimble sports car with a driver who delivers the product right to your door and gets a signature that you have received it. By the same token, a fleet of sports cars can move large amounts between cities – but that is equally impractical. An operational use case strongly benefits from the sports car – and this guide will tell you what features to look for in said vehicle.
Less colloquially, events take their roots in messaging and networking and have their fundamentals in low latency, high reliability and efficient routing. Logs have their fundamentals in storage and parallelism.
Operations, Analytics, and When to Go Hybrid
EDA is technology agnostic, and you can leverage a broker to do what it wasn’t specifically designed for. For instance, you can use log-brokers in operational use cases and smart event brokers as a messaging layer for analytics apps. In practice, this works in many cases, but also in practice we see the wrong choice failing all the time. It introduces problems as the architecture or the application demands scale or complexity. Like any choice, we consider two simple questions:
- Is this choice the most operationally efficient way to do it? Especially as organizations incur exceptional cloud costs in hybrid and multi-cloud deployments.
- Will this choice work in production and scale well? We see scenarios all the time where organizations have tried to mismatch their needs (for various reasons) and it has caused problems.
An event broker for operational use cases is used where efficiency and low, predictable latency are critical and a log-based event broker when parallelism and storage is critical. With an event mesh you can also hybridize the solution and have the event routing to a log broker for analytics or database-like needs – thinking the other way, you can have replication across logs in combination with queue-based messaging.
In short, it all seems well and good to get one to perform the tasks better suited for another… until it doesn’t.
What to Look for in an Event Broker for Operational Use Cases
| Required for Operational Use Cases? |
Required for Analytical Use Cases? |
|
| Fine-Grained Routing/Filtering (w/ Sequence) | Yes | Sometimes |
| Rich Application Integration | Yes | Sometimes |
| Messaging Functionality | Yes | No |
| Observability | Yes | Sometimes |
| Stream Partitioning (multiple queue types) | Yes | Yes |
| Low Latency | Yes | Sometimes |
| Federation across hybrid/multi-cloud | Sometimes | Sometimes |
| Hybrid/Multi-Cloud | Yes | No |
| Lossless Delivery | Yes | Sometimes |
| Resilience | Yes | Sometimes |
| Replay | Sometimes | Yes |
| Broker management | Yes | Yes |
| Platform completeness | Yes | Sometimes |
Fine-Grained Routing/Filtering
With EDA, applications can collaborate by asynchronously reacting to event stimuli, instead of synchronously polling for events or relying on an orchestration layer. To get the correct event stimuli to the applications, there needs to be a way to asynchronously deliver events. The publish-subscribe exchange pattern is effective for this need.
A microservice or application usually needs a subset of the stream. For instance, a microservice for warehouse pick management that only cares about new orders that are in its delivery zone. Moreover, if an order is cancelled then it needs to receive that cancellation in order and often to the specific microservice that processed the original request.
Routing with a topic structure can also have security benefits, as some sensitive PII or corporate secret data can be specifically available – and steered only once – to the application or network that will consume it.
Filtering in a log-based event broker is operationally more complex and costly.
A log-based event broker has a challenge with filtering and in-order delivery at the same time because events from different topics get put into two different log files within the broker. This means that architects need to design coarse-grained topics that contain all the events, which then need to be filtered on the consumer side. The cost of this approach can be measured in latency, complexity, performance and network costs.
Scenario 1: Pre-filtering
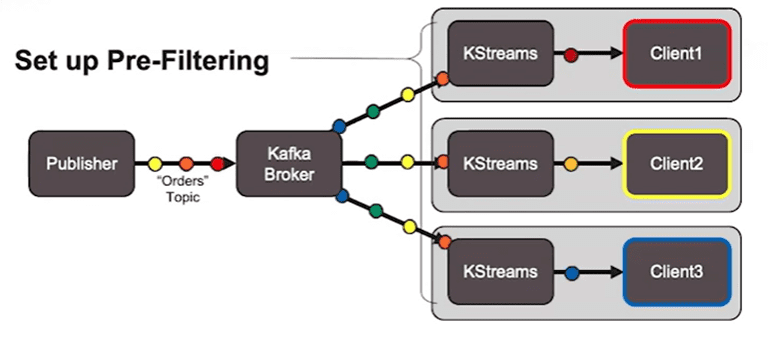
A log-based broker like Kafka will send all the events in a stream and a tool like KStreams can be used to filter it on the client side.
Scenario 2: Client creates new topic
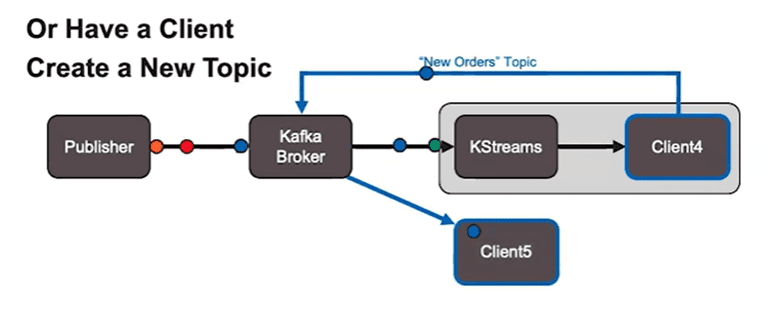
Alternative design pattern when multiple clients need to receive the same topic but all clients don’t want to have their own filtering. In this instance one client creates a new topic for consumption by others.
Alternative Pattern Used by Smart Event Broker
The story of the event is told via the topic taxonomy making it easy to publish and consume. It also enables routing and filtering without orchestration.
A simple way to explain this is to think of a topic as a sentence structure with a noun-verb-adjective. In practice, this could be: the who is the company/division plus a business object, the verb contains the event and may contain a version then the adjectives cover the rest of the key event information.
The client can subscribe to any part of the topic and receive exactly what they want. The term that we use for this is Smart Topics – which also confer other advantages for event routing (discussed later).

A hierarchal topic structure using noun, verb, adjective as the model, where the levels define different attributes and can be used for subscribing, routing, and access control.
This type of filtering is important in operational use cases since applications, especially microservices or serverless apps, want to act discretely on the events they need to perform to their function – which is typically a subset of the entire stream. Schematically, event routing is easy to picture with each event only going where there is a subscribing client.
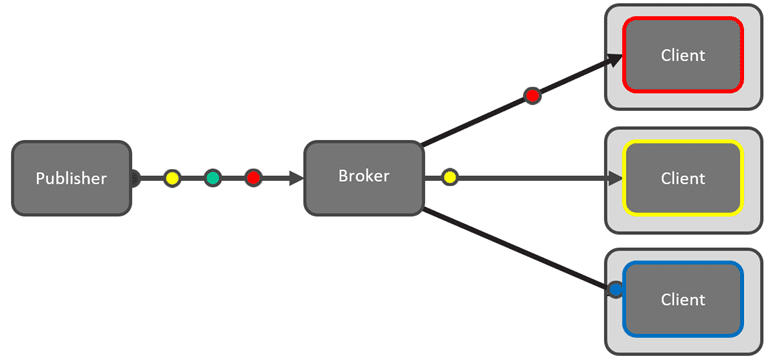
By using topics to route events to subscribers, you have a very efficient system with no unnecessary egress and network costs and no extra processing required for the clients.
Topic Taxonomy in Action
Consider an operational use case for an airline flight with the following topic taxonomy:
flight/[status]/[flight-number]/[origin]/[destination]
In this example you have multiple different flights all described by the topic, for example, “United 1070 departing from Newark and arriving to O’Hare” and the subscribers can pick any level they need for their application. A baggage claim application in Chicago may only care about flights arriving to O’Hare (airport code ORD) and could subscribe like this:
flight/*/*/*/ORD
The limits of this approach are the imagination and planning of the architects and developers designing the system. And importantly, different development teams can do different things once the event is published to the organization.
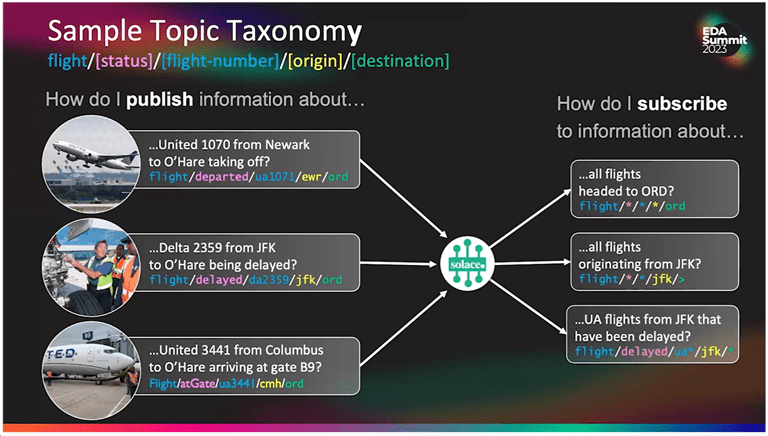
Using topic taxonomy you can subscribe to specific information of interest using topic taxonomy and wildcards. This gives application developers more freedom in building efficient applications from events.
Key Requirements
- Ability to define topics hierarchically.
- Ability to subscribe to events using topic wildcards at any level.
- Ability to route topics automatically to all subscribing applications (with no code) at the broker level.
- Ability to stop routing events when subscribers are taken off without manual intervention.
Rich Application Integration
Events need to pass from and to systems using a variety of protocols to support the range of systems across an enterprise. This can include everything from discrete consumer transactions to fanout to IoT devices, and needs to help you make unknown future integrations easy – kind of like a Swiss army knife of capabilities.
Application integration across organizations is a lot more than a queue. Support for easy connectivity saves time and risk for development teams.
An operational use case needs to support programming libraries/languages for custom applications, a wide variety of protocols and connectors to reduce reliance on unsupported custom code for integrations. This allows developers to connect legacy applications in technologies like JMS or JCA and modern applications in JS, Python, Node.JS, Go and more.
This certainly does not mean to suggest that analytical use cases do not need to bridge technologies – but the requirement is different. Analytics use cases typically write applications in Python or KSQL and typically in frameworks like Beam. The broker needs to connect to those environments for processing.
Key Considerations
- Open messaging like AMQP, Kafka, MQTT,
- JS, Python, Node.js, Og, serverless, FAAS
- Support for modern frameworks like Spring
- Support for the needed client integration like JMS, REST .NET
- Support for IoT devices with MQTT for both readout and C&C
Messaging Functionality
We have defined rich messaging functionality as “it depends” in operational use cases, because what specific function is needed depends on the situation. A single simple application may simply need a highly performant, and resilient queue.
Many operational use cases need traditional messaging functionality that is not typically required in analytics use cases since the event is less dependent on time, order, or even delivery guarantee. For operations, choreographed decoupling is critical to success in decoupled architectures and can power future applications not considered when the event layer was deployed or the event was first published to it.
Different use cases require different messaging and it ranges from simple point-to-point to asynchronous request-reply. The former is simple send-and-receive while the latter is used when the applications need to send the broker an acknowledgement that the event was received and processed and the applications operate at different speeds. Here is a quick look at a few critical patterns to understand when they are used:
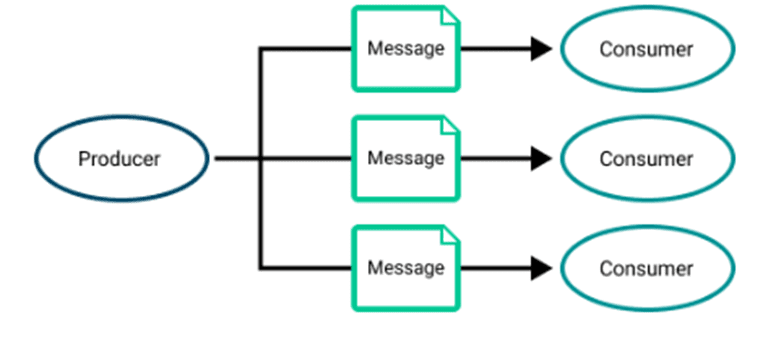
Publish/subscribe pattern where a message can be processed multiple times by different consumers
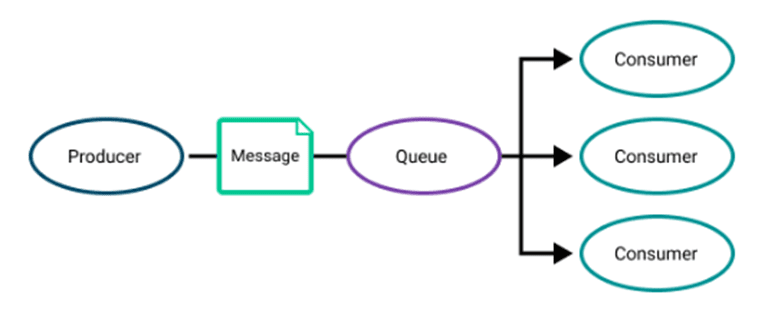
Non-exclusive consumption where multiple consumers share a queue but the message can only be consumed once
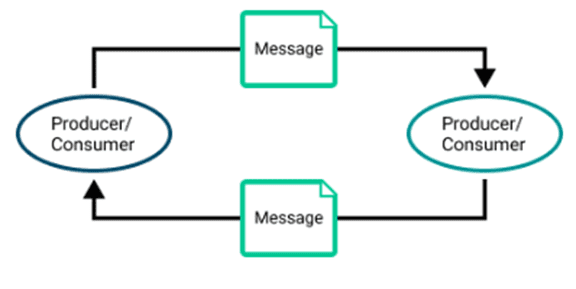
Request/reply used for guaranteed messaging.
How the message is handled must also be considered. For instance:
When the receiving application can’t process the event, the broker must support delayed delivery (and redelivery) with the ability to set the number of attempts.
- When the application can’t receive the event, it needs to send messages to a dead-message queue that has redelivery parameters specified.
- When the receiving application is overloaded and message priority can be useful in making sure that the most critical messages are processed first
- When the processing requirement changes based on time, the broker needs event time-to-live (TTL) to know if that message needs to still be processed.
- When legacy applications need transactions and session-based transactions where the asynchronous reply comes only after the event has been processed and not just on receipt.
By contrast, analytics use cases don’t typically have a complex set of microservices and applications interacting with each other in an orchestrated matter. A complete stream of all the events delivered from a log-based system is often a more appropriate and efficient use of resources.
Key considerations
- Exclusive queue, non-exclusive queue, and guaranteed delivery support.
- Message caching and replay supporting request/reply, delayed redelivery.
- Support for more advanced messaging needs based on application state such as, delayed redelivery, TTL for messages, dead-message queues, session and XA transactions, message priority, and message durability/retention.
Observability
Observability is the ability to collect and analyze logs, metrics, and traces. By supporting the full set of data in operational use cases the data is available for troubleshooting, debugging, deep monitoring (including AI powered), and audit.
“OTEL adoption has become significant with 32% of respondents indicating it is required and 50% indicating it is very important in vendor products. Slightly more than one-third (36%) of respondents use OpenTelemetry within their organization already.” (source)
The newest pillar that is really driving adoption is traces using the OpenTelemetry standard. This provides telemetry that spans (time) and context carried from end-to-end. With a trace that maintains its context from end-to-end it is significantly easier to solve problems resulting in a reduced mean time to detect (MTTD) and mean time to recover (MTTR). This was the original use for tracing in application development, but the promise of observability goes beyond the development teams.
Organizations are using end-to-end tracing to optimize systems. Because you have spans and the event/data across huge datasets it is possible to identify bottlenecks or underutilize systems and optimize for user experience and costs.
For the broker, the ability to deliver logs, metrics and traces natively means that there is no black-box when events enter and exit the broker or mesh. This can be very helpful in debugging and useful in audit compliance.
Learn more about distributed tracing and observability.
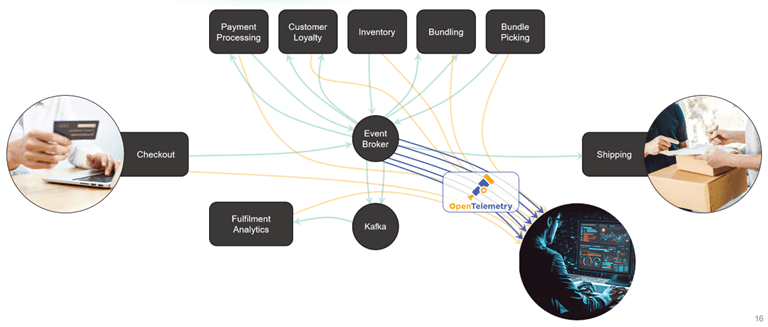
Key Considerations
- Native implementation of OpenTelemetry specification for events (versus API-level)
- Proven integration with APM vendors
- Managed services (if needed) include a managed OpenTelemetry collector
- Syslogs of broker operations fully documented and published
- Availability of native visualization and analysis tools
Stream Partitioning
Stream partitioning allows you to ensure that a microservice model can distribute rapidly and efficiently between small nodes (or clusters or pods). For operational use cases, many events must flow in order or the systems won’t work. This can be managed and scaled a couple of ways.
To understand the need for partitioning, we need to understand context. Context is defined loosely as the need for each event to understand where it is in the proper order to related events. If there is no context needed then, a non-exclusive queue can simply bind as many new consumers as needed and they will auto-balance the distribution of the events based on the speed of the various consumers. If context, but no scaling, is needed then you can simply partition different services to specific event streams with exclusive queues. But when you need both autoscaling of consumers and context you need stream partitioning.
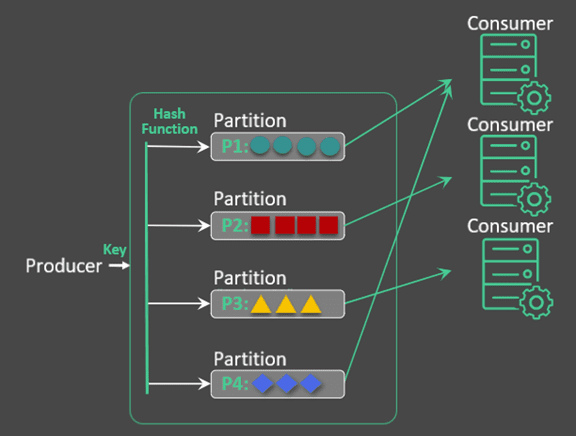
With multiple consumers, like events (colors) must keep context and be consumed by the same consumers. With auto-scaling this can’t be maintained without partitions on the queues.
For example, with credit card online order processing, if a variable changes then it impacts all related events. In this type of scenario, it is important to maintain that context with a key (or hash) so that as new consumers are added or removed events don’t go to the wrong consumers. In this example, if a credit card is updated and that update goes to a new consumer and is processed before the account holder information is even created then the system will break. The updated number needs to go to the same consumer that the original information was sent to.
Key considerations
- Ability to bind broker partitions to consumers
- Ability to maintain event order as the partitions increase
- Ability to gracefully remove streams as the consumers are scaled down (or recover from a consumer failure)
Low Latency
In operating environments, the event broker must at minimum be able to deliver events as fast as the fastest consumer. Oftentimes even faster with the events being held in queue/cache. This must also be done predictably otherwise complex systems become hard to design if any single component falls outside of a narrow range.
While a lot of other systems play into the delivery of events, from physical location to the network, to the hardware – the key is that the event broker is not the bottleneck. And this applies to how live data is handled (cache first or cache last) as well as cached data. A corollary to this is that the brokers you deploy can respond to manage both slow and fast consumers.
This is implemented operationally by routing all the messages to any brokers that have applications subscribing to the topic. Because the event broker are optimally located close to consumers the response is fast and the system is architected reliably to not require internet transit at the time of consumption.
Many technologies can route tiny messages quickly and reliably but a larger message can degrade performance quickly. In brokers, this is also seen in large fan-out scenarios where, on paper, they suggest great capability, but the results don’t deliver in the real world.
This is a commonly specified need with analytics needs, but against the cost of achieving it with stored datasets, in that instance a short delay doesn’t break the system – and many may meet the need in batch processing – where latency isn’t even a consideration.
Key considerations
- Lowest latency for my typical and worst-case event scenarios
- Predictable latency for systemwide design
- Ability to define how the cache responds to live data
- A system to manage slow consumers
- Defined operating environment (network, hardware, cloud-managed, or dedicated appliance)
Federate and Scale across Hybrid/Multi Cloud
Many organizations with complex technology stacks need to deploy using self-managed and vendor-managed technology – so evaluating how the platform is deployed and managed requires a few considerations. The industry standard for a containerized deployment model is for Kubernetes (K8) with certification across the major platforms.
If brokers are deployed and connected into an event mesh then your end-to-end system performs optimally because the event brokers are physically located near the producing and consuming applications.
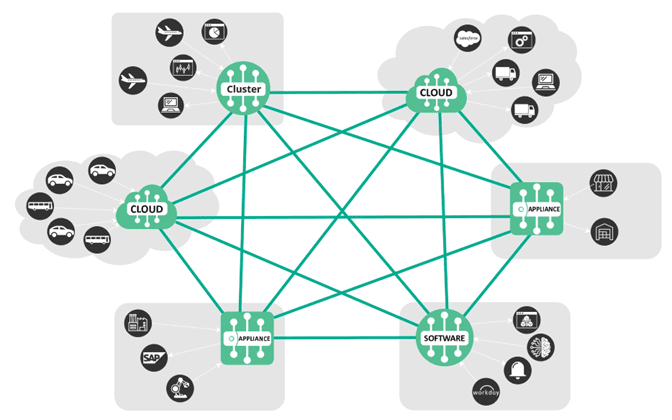
Different clouds, on-premise legacy, hardware, software and SaaS need to be able to receive and use the same events.
In an event mesh, event routing is automatic and easy to manage. This is the concept of federation, where all the brokers appear as a single broker regardless of what is actually routing in the back-end. In a federated scenario, an event mesh comprised of event brokers dynamically streams all events to any other broker on the mesh – with the caveat that it streams it precisely and accurately from one source of truth and only sends it when there are subscribers (to save cost).
Finally, there are two other scenarios where multi-cloud is required. First, is when there is a regulatory requirement to maintain some apps and data in a country. The second is when you want to be able to switch off a single cloud provider if they aren’t cost or quality-competitive to give better leverage in negotiations (aka avoid a walled garden).
Key consideration:
- Deployable in industry standard containerized environments
- Available as self-managed and vendor managed options
- Vendor managed options are available globally and in my preferred cloud vendors
- Automatically connects and streams events to any newly connected brokers
- Federates events by making them appear as a single event broker to the consumers
Lossless Delivery (aka Guaranteed Messages)
For operational use cases, lossless delivery is almost always a requirement because the next operational step cannot happen if there is a message loss. Lossless delivery is also critical for applications, like banking, where the cost of a lost event isn’t just measured in the event itself but in the revenue impact on the organization – which in stock trading or retail scenarios can be very high.
In very high throughput and very complex environments, this is very difficult to achieve. This is where guaranteed messages come in. Event brokers need to enable guaranteed/lossless delivery between applications and microservices at scale without significant performance loss. Scale that also supports bursty traffic.
The event broker provides the shock absorption and guaranteed delivery and supports persistent messaging and replay that enable lossless delivery in the form of Guaranteed messaging (aka subscriber acknowledgement).
Guaranteed messaging can be used to ensure the in-order delivery of a message between two applications even in cases where the receiving application is offline, or there is a failure of a piece of network equipment.
Two key points about guaranteed messaging:
- It keeps messages that are tagged as persistent or non-persistent (rather than Direct) across event broker restarts by spooling them to persistent storage. Although a persistent delivery mode is typically used for guaranteed messages, a non-persistent delivery mode is provided to offer compatibility with Java Message Service (JMS).
- It keeps a copy of the message until successful delivery to all clients and downstream event brokers has been verified.
Key considerations
- Lossless delivery supported through a message spool.
- Messages can be tagged as requiring persistent or non-persistent delivery.
- Supports multiple consumers with different consumption rates.
Resilience
The cost of enabling resilience is a sliding scale that is shaped like a hockey stick (i.e. rising fast at the extreme) but event brokers live in the extreme because multiple systems rely on them. They have been built for reliability like network (or physical) layer technology versus application-layer technology.
Event brokers must support simple high-available (HA) deployments and be able to seamlessly support disaster recovery (DR) without message loss. To make management simple, the tools that manage the events work together to deliver on these requirements without extra configuration.
For those self-managing event brokers, deploying HA nodes should be simple. This means one broker operates in standby mode and the other in active mode and connected over the IP network. The standby broker picks up in the event of failure and once the primary is active again, the standby needs to gracefully hand back responsibility. Similarly, if the active broker loses connectivity to both the standby and monitoring nodes then it needs to stop activity to avoid a split-brain scenario where the messages aren’t in the same state.
For disaster recovery, storage and other event brokers work together to help recovery. Once the broker is back online its queue can get re-filled without lost messages.
For those using managed cloud services, the vendor should deploy HA nodes as the standard with one additional detail, which is that the service should run the brokers on different availability zones when available. The event brokers should deliver the maximum uptime SLA that the cloud (i.e. AWS, Google Cloud, Azure) offers.
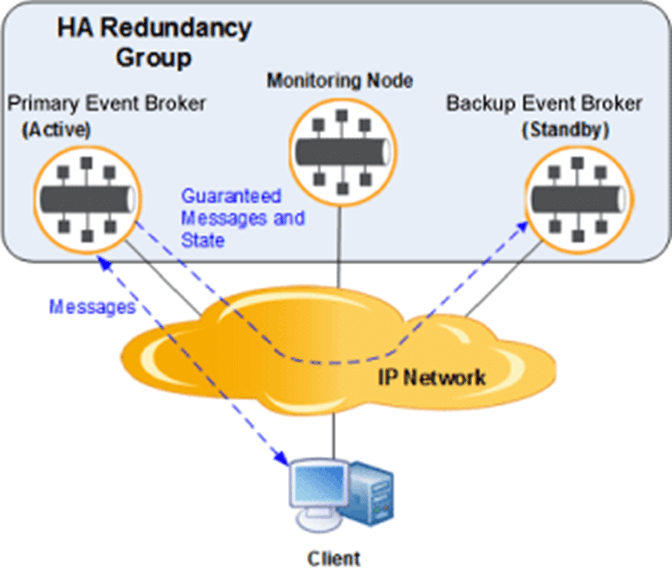
An HA pair in action with a monitoring node to ensure seamless handoff in the event of failure.
Key considerations
- Fast failover detection
- Fast recovery and resynchronization mechanism with replication between pairs
- Technique to avoid split-brain scenarios
- Selective messaging backup (i.e. only need to backup guaranteed messages)
Replay
Replay is needed to help protect the system from a faulty consumer. And with scaling microservices, it could be a single consumer instance.
Message replay allows an event broker to store and resend messages to new or existing clients that request them, hours or even days after those messages were first received by the event broker. Replay functionality helps protect applications by giving them the ability to correct database issues they might have arising from events such as misconfiguration, application crashes, or corruption, by redelivering data to the applications. It also allows for late-join applications to get ‘caught up’. Replay logs are maintained distinct from the message queues when there are multiple subscribers for efficiency so that they aren’t stored multiple times.
Once replay is initiated, the event broker delivers messages from the replay log that match any subscription on that queue or topic endpoint and once complete it joins the live event stream.
For analytics use cases being able to recover the data if applications are corrupted is very useful. It can also be useful for binding new analytics apps to the events. For operational use cases, the usefulness of the state is generally time-bound since there have been follow-on processing or new data that supersedes the older values. Replay is still a benefit, but it has a resource cost that must be balanced at scale.
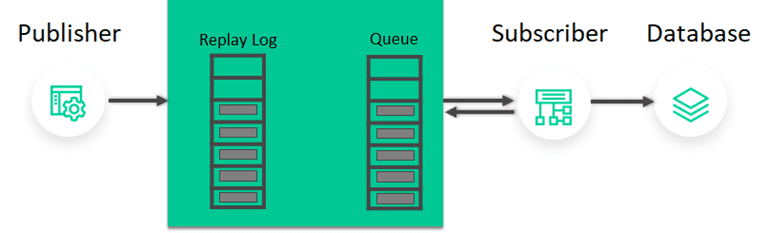
Key considerations
- Replay storage log distinct from message queues
- Ability to define the replay parameters by date and topic wildcards
- Configurable on how much data is stored and which message VPNs require replay
Broker Management and Observability
We have already discussed distributed tracing for observing the events flowing over the event broker. Here we focus on brokers themselves with a more traditional APM view.
There are two basic parts of broker management, the first being the initial installation and upgrades and the second being managing operational brokers. In either case, it provides for configuring, viewing and troubleshooting the event brokers deployed in your organization.
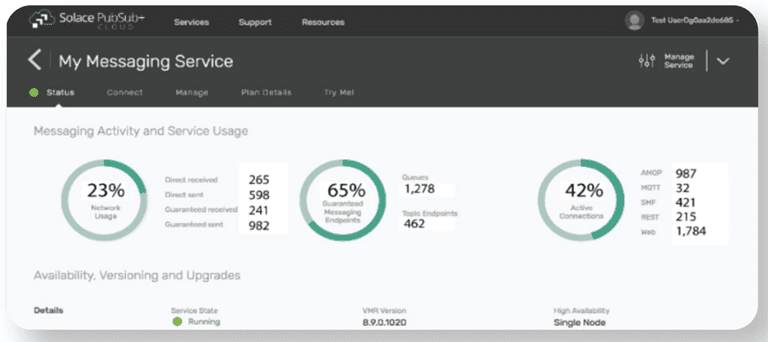
A broker manager, such as Solace’s seen here, provides for a snapshot of the configuration and operation
A manager also helps with installation/upgrades for self-managed or cloud-managed services. And it provides for event mesh management. Broker management tools make this task much easier for the teams managing the services.
Users and organizations like to do things in different ways, and broker management will allow for this GUI, CLI, API and Infrastructure as Code (IaC). In all cases, management should cover all the commands needed for a seamless install and upgrade procedures – including how it interacts with outside tooling such as CI/CD pipelines to manage the lifecycle or autoscalers (like KEDA) to support microservice scaling.
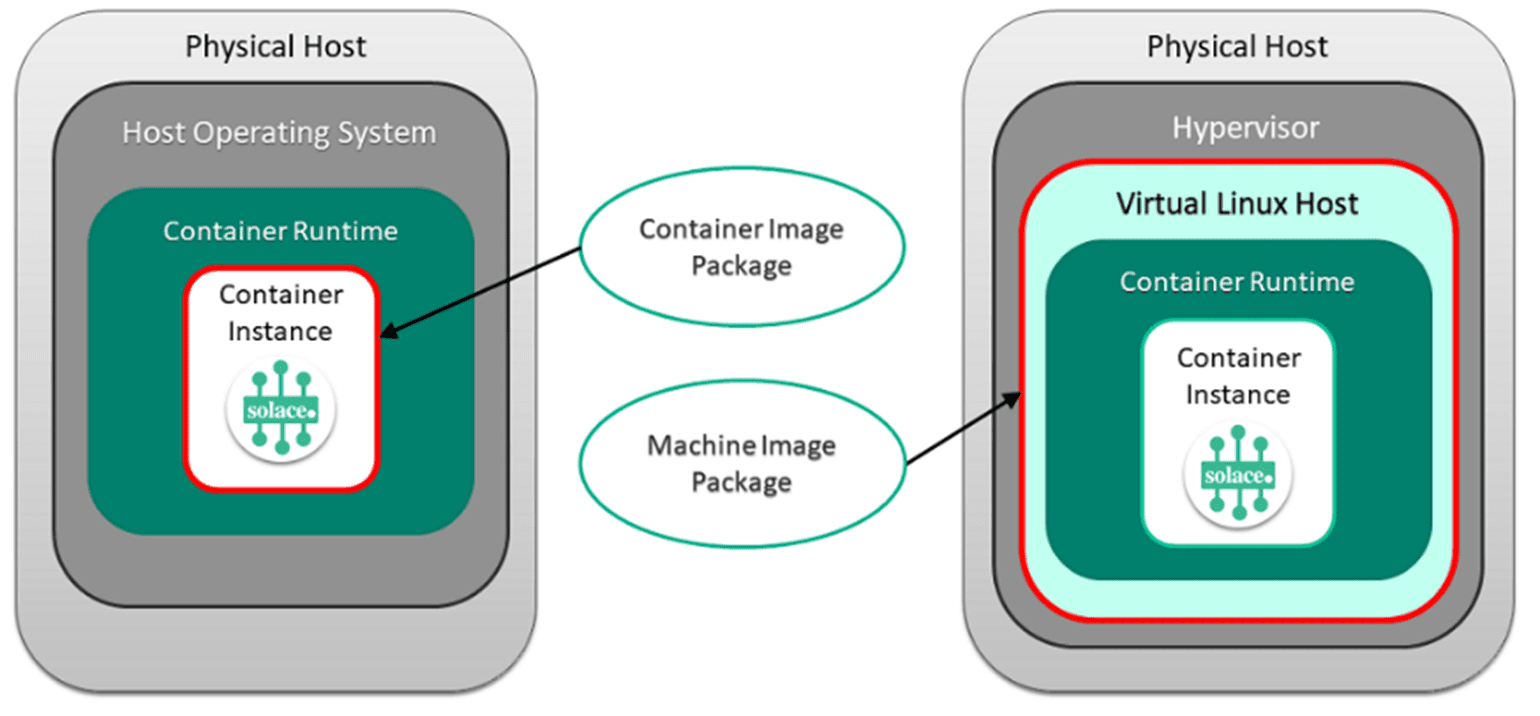
Figure 18: Broker should have multiple installation options to suit your use case.
In an event mesh scenario, multiple event brokers are moving the events around the organization to wherever there are subscribers to the topics. Therefore, upgrades need to be quick and simple to perform sequentially across the mesh.
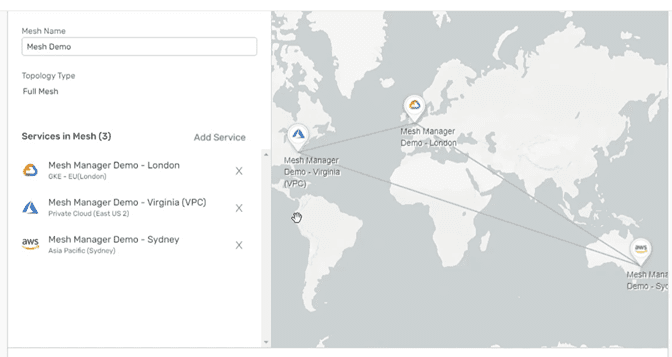
A multi-cloud event mesh with brokers in different clouds, as seen in Solace’s cloud management console.
On the operational side, broker management provides a visual representation of the broker configuration and has available tools to monitor the health of the event mesh and to enable rapid detection and response of problems. As it relates to full Observability, this area is covered above and has it’s own whitepaper – but for these purposes of cataloging a broker-management requirement, we can encapsulate it as providing native observability.
Key considerations
- In service upgrades
- Management of all functions available via GUI, CLI, API and IaC
- Documented SOC compliance
- User management and OAuth support for SSO compliance
- Native broker performance management (i.e. APM for a broker)
- Full set of observability capabilities – metrics, logs and traces both natively and to third party apps (as applicable)
Platform Completeness
A full EDA platform allows for messaging and streaming at scale, broker operation and observability of the broker and the events themselves, ready-built integrations and connectors, and tools to access (design) and govern the event-driven system.
This guide focused on the event broker for operational use cases and only touched tangentially on the many platform capabilities organizations typically leverage for their EDA. For enterprises looking to connect and integrate anything, anywhere, reliably and in real-time, through the power of event-driven architecture the whole capability is important.
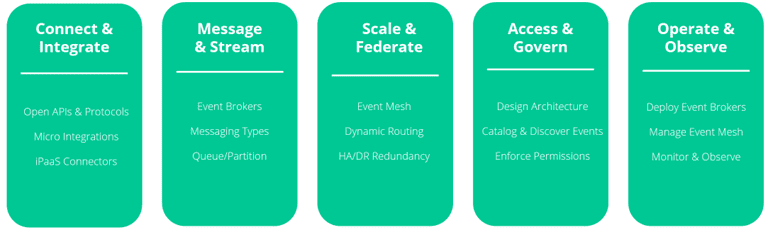
An event broker is the key to several pillars in a modern EDA platform
PubSub+ Platform
With PubSub+ Platform, Solace provides a comprehensive way for organizations to stream, integrate and govern events from where they are produced to where they need to be consumed. Established enterprises worldwide trust Solace to modernize their application and integration landscape; enable time-sensitive applications and processes at scale; and create seamless digital experiences for their customers, partners and employees.
Conclusion
In addition to the key features needed for operational use cases, there are several capabilities we believe different options deliver when evaluating event streaming technologies. Solace has published a paper called Comparing EDA-Enabling Platforms and Technologies, and industry analyst IDC recently published the first event broker competitive evaluation by a major analyst firm: IDC MarketScape: Worldwide Event Brokering Software 2024 Vendor Assessment