Executive Summary
Agentic AI systems are rapidly evolving from isolated task-specific components into collaborative networks distributed across environments, departments, and organizational boundaries. The architectural decisions you make today will determine whether these systems scale successfully or collapse under unaccounted-for limitations.
This whitepaper provides enterprise architects with a comprehensive framework for designing production-ready multi-agent systems. Drawing on organizational design principles and proven integration patterns, we demonstrate why brokered event-driven communication, rather than point-to-point wiring, provides the foundation for scalable, governable, and resilient agentic systems.
The Core Thesis
Designing effective agentic systems is not fundamentally different from designing effective organizations. Both are composed of autonomous actors constrained by roles, communication paths, and shared objectives. When this organizational lens is applied to multi-agent architecture, each agent becomes a team member with an explicit job description, decision rights, and interfaces plugged into a structure that deliberately balances hierarchy with autonomy.
Why Event-Driven Architecture
While point-to-point asynchronous communication may appear sufficient at small scale, complexity grows rapidly as new agents are added and new business requirements start to surface. Each agent introduces additional dependencies, tighter coupling, and increasing context propagation requirements. Event-driven architecture addresses these scaling concerns by shifting focus from agent-to-agent communication to state and event propagation. Agents react to events rather than calling each other directly, naturally supporting collective intelligence while preserving autonomy.
Industry analysts concur. Gartner’s research on Multi-Agent Generative Systems (MAGS) explicitly recommends event-driven architecture as the foundation for enterprise-scale deployments, advising organizations to adopt standardized messages and events with clearly defined agent roles and interfaces.
What You Will Learn
- How to select use cases that balance ambition with pragmatic constraints
- Organizational design patterns translated to multi-agent architectures
- Context engineering strategies that prevent the degradation that plagues production systems
- Specification and governance approaches that enable evolution without breaking existing functionality
- Security architecture patterns for agent identity, authorization, and audit
- Horizontal and vertical scaling strategies powered by event-driven infrastructure
The practical reality observed across enterprise AI initiatives is clear: roughly 20% of the challenge is addressed by AI technology and model selection, while the remaining 80% is a data integration problem. This whitepaper addresses that 80%.
Introduction
Who This Whitepaper Is For
This whitepaper is written for enterprise architects, integration specialists, and AI platform teams responsible for designing and deploying multi-agent AI systems at scale. You may be facing a mandate to adopt agentic AI, evaluating how to move from proof-of-concept to production, or seeking to establish standards early that will prevent pain later.
We assume basic familiarity with large language models, messaging systems, and enterprise integration patterns. You do not need to be an AI researcher or prompt engineering expert as this document focuses on architectural decisions rather than model internals.
The Current Landscape
The agentic AI landscape is evolving rapidly. What began as narrowly scoped agents performing single functions is transforming into collaborative systems distributed across environments, departments, and organizational boundaries. There is now an expectation of collective reasoning, near real-time context sharing, and memory continuity across long-running workflows.
This shift is reflected in industry research. Gartner’s analysis of enterprise-scale multi-agent systems highlights that managing these architectures requires more than capable models. Scale, governance, compliance, observability, and security are critical concerns that must be addressed as agentic systems approach the new normal of business performance.
Key Terminology
Before proceeding, let us establish common vocabulary:
- Agent: An autonomous software component powered by a large language model that can perceive its environment, make decisions, and take actions to achieve goals. Agents operate within defined boundaries and can use tools to interact with external systems.
- Tool: A capability that an agent can invoke to perform specific operations—retrieving data, executing transactions, calling APIs, or interacting with other systems. Tools extend what an agent can do beyond pure language processing.
- Orchestrator: A special kind of agent that coordinates multiple agents and plans generation, managing workflow sequences, routing decisions, and quality gates. Orchestrators may themselves be agents or may be deterministic workflow engines.
- Gateways: serve as the primary interface between the agent mesh and external systems, exposing agents to the outside world through various protocols by translating external requests into Agent-to-Agent (A2A) protocol. Gateways also manages the flow of responses back to external systems, along with handling authentication and authorization, user enrichment, and message processing across multiple interface types including REST APIs, HTTP Server-Sent Events (SSE), webhooks, and event mesh connectivity.
- Event Broker: Infrastructure that enables asynchronous communication through publish-subscribe patterns. Agents publish events to topics; other agents subscribe to relevant topics and react to events as they occur.
- Context: The information available to an agent when making decisions—including system prompts, conversation history, retrieved documents, tool outputs, and any other data in the agent’s attention window.
- Agent Mesh: A distributed architecture where multiple agents collaborate through event-driven communication, enabling dynamic topologies and loose coupling between components.
How to Use This Document
This whitepaper can be read sequentially or used as a reference. Chapters build on each other conceptually, but each addresses a distinct concern:
- Chapters 1-2 establish context and help you select appropriate use cases
- Chapters 3-5 address agent design philosophy, tool architecture, and context management
- Chapters 6-7 cover production concerns: prompt engineering and specification strategy
- Chapter 8 provides comprehensive security architecture guidance
- Chapters 9-10 discuss the event-driven advantage and the path from design to deployment
Throughout, we provide practical frameworks, decision criteria, and concrete examples. Our goal is to help you make informed architectural decisions—not to prescribe a single approach for every situation.
The Architecture Decision Tree
Agents are not task-specific components operating in silos. The coordinated decision-making across many autonomous agents operating with shared situational awareness is what agentic AI is fundamentally about. This brings us to the architecture decision tree: how should agents communicate, and how should you design collaborative autonomous systems?
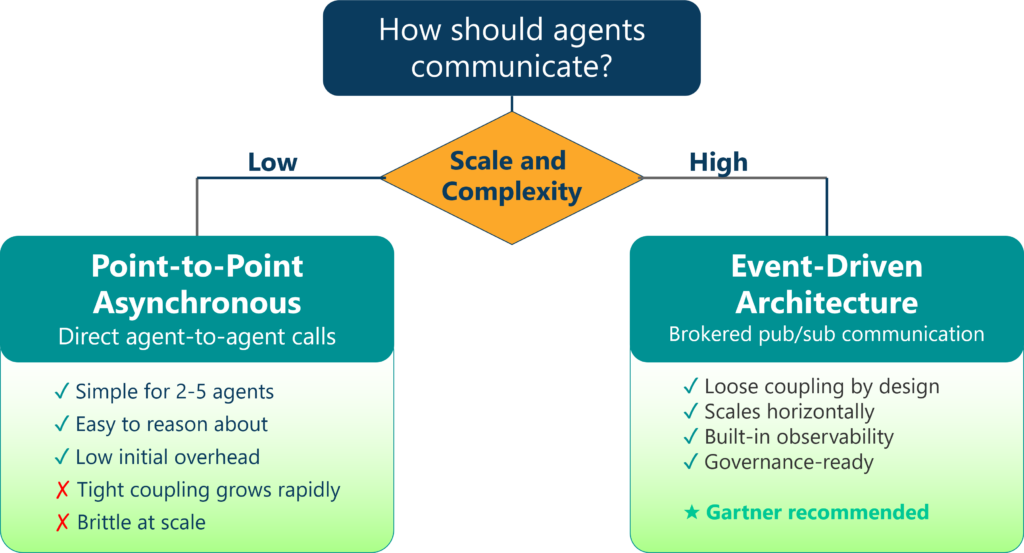
Two Interaction Patterns
At a high level, agentic systems typically gravitate toward one of two interaction patterns: asynchronous point-to-point communication or event-driven architecture. While both patterns include elements of asynchrony, they differ significantly in how context, scale, governance, observability, and autonomy are handled.
Point-to-Point Communication
The asynchronous nature of agent communication forms the foundation of non-blocking independent operation. It allows agents to progress without waiting on one another, tolerate partial failures, and operate across distributed environments.
At small scale, asynchronous point-to-point communication can appear sufficient. An agent sends a request, another responds, and the interaction is easy to reason about. However, when implemented purely through point-to-point wiring, complexity grows rapidly. Each new agent introduces additional dependencies, tighter coupling, and increasing context propagation requirements. Over time, this results in brittle systems where understanding behavior requires tracing a web of direct interactions.
Event-Driven Architecture
A brokered event-driven approach addresses scaling concerns by shifting focus from agent-to-agent communication to state and event propagation, delegating the format of communication to the protocol layer. Agents react to events rather than calling each other directly. Context is emitted, consumed, and transformed as part of the system’s data flow rather than embedded in tightly coupled execution paths.
This pattern naturally supports collective, coordinated intelligence while preserving agent autonomy. Gartner clearly comes down on the side of including a message broker (also called an event broker) into the reference agentic architecture. They advise organizations to ensure scalability and reusability by adopting an event-driven architecture that uses standardized messages, events, or commands with clearly defined agent roles, responsibilities, and interfaces.
“Ensure scalability and reusability by adopting an event-driven architecture that uses standardized messages, events or commands, and clearly defines agent roles, responsibilities and interfaces.”
Why Complexity Resides in Communication
Agents are expected to make decisions with or without human intervention based on evolving system state and business context. The complexity of an agentic system does not arise from the internal logic of individual agents, but from the interactions between them.
An event-driven approach to agent communication is explicitly designed to manage this interaction complexity by decoupling producers from consumers and enabling many agents to coordinate through sophisticated management of shared context and memory. This places real-time data access at the core of the system instead of an afterthought, allowing agents to respond to changes as they occur rather than relying on stale snapshots.
This aligns with a practical reality observed across enterprise AI initiatives: roughly 20% of the challenge is addressed by AI technology and model selection, while the remaining 80% is a data integration problem.
Starting Your Design
If a broker-fortified event-driven architecture is the right foundation for agentic systems, how do you get started designing? The chapters that follows address what an enterprise architect facing a mandate to adopt agentic AI should consider when creating a first pilot project, but also with an eye toward standards to establish early that will prevent pain later.
Starting Right—Use Case Selection
Top-Down: What Problems Are We Solving?
The top-down approach begins with a deceptively simple question: What business problems are we trying to solve, and is AI the right way to solve them? This methodology starts from the strategic level, identifying pain points, inefficiencies, or opportunities across the organization, then evaluating whether agentic AI represents the optimal solution.
The Strategic Imperative
Top-down use case selection aligns AI initiatives with organizational priorities from the outset. Rather than deploying technology in search of a problem, this approach ensures that every AI agent serves a clear business purpose with measurable outcomes. The key is identifying problems that are significant enough to warrant investment but appropriate for the current state of AI capabilities.
Critical Factors for Evaluation
When evaluating potential use cases, consider these factors that distinguish viable candidates from poor investments:
Stakeholder Buy-In Across Three Dimensions
Successful agentic AI projects require alignment across
- integration teams (who must understand how agents connect to existing systems),
- business stakeholders (who need clarity on outcomes and ROI), and
- AI specialists (who must validate technical feasibility).
Without alignment across all three groups, projects encounter resistance at every stage. The most successful implementations begin with champions in all three domains collaborating on use case definition.
The Goldilocks Zone of Criticality
The ideal candidate sits in what we call the Goldilocks Zone: problems that are important enough to justify investment and generate meaningful ROI, not so critical that failure would pose existential risk, yet valuable enough to maintain stakeholder attention. Problems that are too trivial fail to generate organizational momentum. Those that are too crucial create excessive risk aversion, leading to endless validation cycles. The sweet spot involves processes where AI can deliver substantial improvement while maintaining appropriate fallback mechanisms.

Uniquely Suited to AI Capabilities
Not every automation problem requires AI. The strongest use cases leverage capabilities uniquely served by large language models: synthesizing information from multiple disparate sources, adding valuable context by understanding relationships between data points, interpreting nuanced requirements expressed in natural language, and adapting to variations in input format or business conditions. If a problem can be solved equally well with traditional rule-based automation, AI adds unnecessary complexity.
Realistic Performance Requirements
LLMs and AI agents operate with different performance characteristics than traditional software. Response times typically range from seconds to tens of seconds, not milliseconds. Data volumes are constrained by context windows. Consistency improves with prompt engineering but never reaches 100% deterministic behavior. Use cases must accommodate these probabilistic realities.
Security and Access Control Alignment
Use cases with complex, dynamic security requirements introduce significant implementation challenges. Starting with scenarios that align with existing access patterns—where a user’s existing permissions naturally translate to agent capabilities—reduces complexity and accelerates deployment.
Real-Time Data Dependencies
Many use cases require access to current, rapidly changing information: live inventory levels, current market data, real-time sensor readings, or dynamic customer state. Event-driven architectures that stream updates to agents as changes occur prove far more effective than polling or batch refresh patterns.
Distributed Data and Edge Intelligence
Modern enterprises operate across multiple physical locations, cloud regions, and edge deployments. Agent mesh architectures that support distributed deployment enable agents to run where data resides rather than forcing all processing through central chokepoints.
Bottom-Up: What Capabilities Do We Have?
While the top-down approach begins with problems, the bottom-up methodology starts with an inventory of existing capabilities and asks: What can we enable that was not previously possible?
Leverage Existing Agent Investments
Organizations already possess AI assets, often distributed across silos: commercial off-the-shelf agents like SAP Joule or Salesforce Agentforce, departmental projects developed by individual teams, and hyperscaler platform agents from AWS Bedrock, Azure AI, or Google Vertex. The most efficient use cases build upon these existing investments rather than creating entirely new capabilities. An agent mesh architecture enables previously isolated agents to collaborate, multiplying their value without proportionally increasing development costs.
Reusability and Composability
The most valuable use cases create capabilities that extend beyond a single application. Agents developed for one workflow can be composed into solutions for related problems. Skills and tools built for one use case become building blocks for future initiatives. Data integrations established for one agent benefit the entire ecosystem. When evaluating use cases, prioritize those that build foundational capabilities with broader applicability.
A Balanced Approach
Successful agentic AI initiatives balance ambition with pragmatism. The top-down approach ensures business alignment and meaningful outcomes. Bottom-up discovery reveals unexpected opportunities from combining existing capabilities. Effective teams maintain both perspectives, apply rigorous validation, start small but think big, learn continuously, and decline inappropriate use cases strategically to preserve credibility and resources.
“Your first use case matters enormously. Get it right, and you build momentum, capability, and organizational confidence. Get it wrong, and you may not get a second chance. Choose wisely.”
Agentic Design Philosophy
The agent design philosophy starts with a concrete, high-value business use case that acts as the north star for everything that follows. Framing agents this way keeps the focus on value creation rather than AI for its own sake, and forces explicit choices about job descriptions, roles, scope, access, and success metrics for each agent in the system.
Before defining agents, tools, or orchestration logic, you must answer: What outcome creates meaningful business value? What decision, process, or workflow improves if autonomy is introduced? What does success look like in measurable terms?
“Designing effective agentic systems is not fundamentally different from designing effective organizations and highly effective teams.”
Treat Multi-Agent Systems as Organizational Charts
Organizations and agentic systems are both composed of socio-technical elements with autonomous actors constrained by roles, communication paths, incentives, and shared objectives. Instead of starting from tools and models, a path that tends to be the default with agent design, the correct starting point is purpose. Without this grounding, agentic systems risk becoming impressive demonstrations that fail operationally.
Effective organizations invest heavily in role clarity, reporting lines, spans of control, and collaboration patterns. Research on successful organizations consistently highlights clarity in roles, ownership, and interfaces as a dominant factor for building high-performing teams. Agentic systems face the exact same constraints.
Every agent should have a defined role and bounded scope through system instructions, explicit access rights through tools, memory, and data sources, a manager through orchestrators and parent agents, and defined collaboration rules through access control. When this philosophy is applied, each agent becomes a team member with an explicit job description, decision rights, and interfaces.
Organizational Structures as Design Patterns
Not every organization is designed the same way, and neither should every multi-agent architecture be. Different structures optimize for different trade-offs in speed, control, specialization, and collaboration.
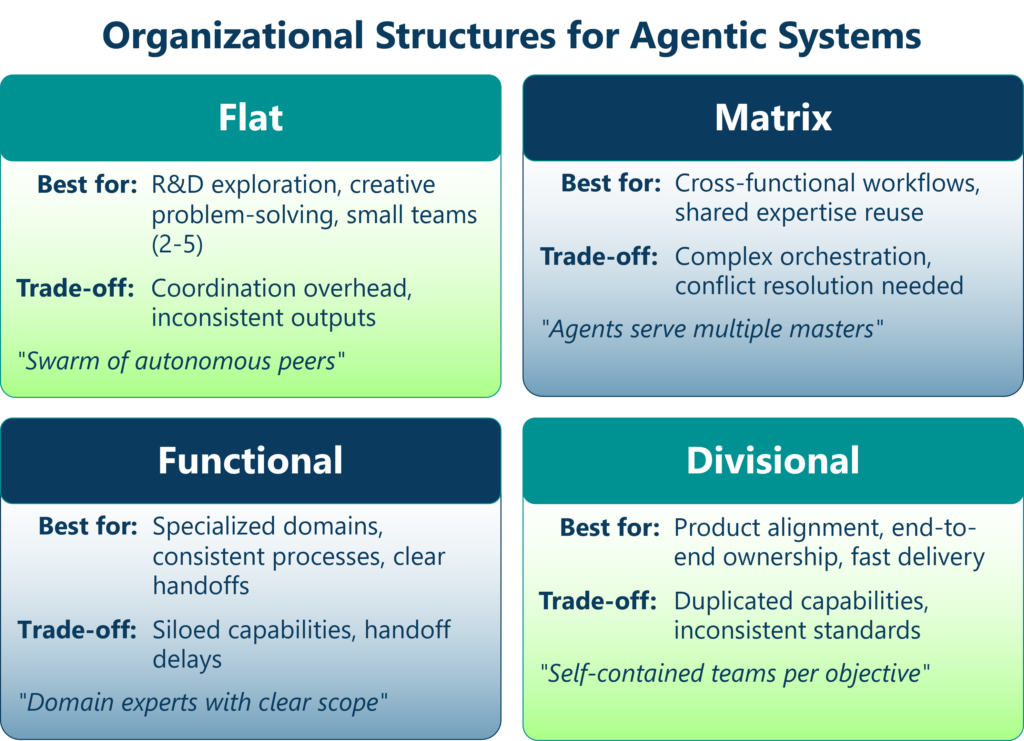
Flat Structure
A flat organizational structure minimizes management layers, resulting in broad spans of control and high individual autonomy. Decision-making authority is distributed, and communication paths are short. This excels where speed, experimentation, and adaptability matter more than strict governance—best for exploratory tasks, R&D, and creative problem-solving. In multi-agent terms, this translates to a swarm of largely autonomous agents with minimal hierarchy, communicating peer-to-peer. It works well for exploratory problem solving but results in coordination overhead at scale.
Functional Structure
As organizations scale, specialization becomes necessary. A functional structure groups teams by domain expertise, each led by a functional manager responsible for standards and performance within that function. This optimizes for depth of expertise, operational efficiency, and consistency. Agentic systems inspired by functional structures group agents by capability rather than outcome. Each agent class becomes highly specialized, excelling where repeatable steps, clear handoffs, and reusable agent capabilities matter.
Divisional Structure
A divisional structure groups teams by business objectives—products, customer segments, or regions—where each division has end-to-end responsibility. This maximizes accountability, speed, and customer focus by reducing dependencies between divisions. In multi-agent architecture, each agent team aligns to a specific business objective. While this benefits from end-to-end ownership, the tradeoffs include duplication of agent capabilities across divisions.
Matrix Structure
The matrix structure combines functional and divisional designs. Individuals report to both a functional manager and a product or project leader. It enables cross-functional collaboration and shared expertise but introduces complexity in decision-making and conflict resolution. A matrix agentic architecture allows agents to participate in multiple contexts simultaneously—for example, a reasoning agent serving multiple product-focused teams while a compliance agent enforces global standards across domains.
Organizational Concepts to Agentic Equivalencies
| Organizational Concept | Agentic System Equivalent |
|---|---|
| Job Description | Agent Card (role and capabilities) |
| Scope | Task boundaries and authority |
| Resources | Tool, data, and API permissions |
| Access Level | User-delegated authorization |
| Manager | Supervisory or orchestrator agent |
| Reporting Structure | Communication and escalation paths |
| Reviews and Approvals | Human in the loop |
| Asynchronous Communication | Event-Driven Architecture |
| Feedback | Response evaluation and scoring |
| Cross-functional Collaboration | Multi-agent coordination |
This framing allows architects to reason about agents not as scripts, but as actors within a system of governance. Agents without clear scope behave like employees without job descriptions—duplicating work, overstepping boundaries, or stalling decisions.
Autonomy and Collaboration: The Twin Pillars
An agentic system is not defined by the sophistication of any single agent, but by how autonomous actors interact, coordinate, and collectively solve problems. Autonomy does not imply unrestricted freedom. In organizational terms, it is closer to empowered accountability: agents act independently, but within constraints defined by role, access, and policy.
For overall effectiveness, autonomy alone is insufficient. High-performing organizations rely on the balance between autonomy and collaboration—individuals can own decisions while sharing information, delegating work, and negotiating over priorities. Similarly, agentic systems rely on both capabilities: collaboration manifests as the ability to exchange state and insights, pass and accept delegated tasks, and negotiate over constraints and resources in real-time as new business events flow into the system.
Collaboration in multi-agent systems rests on three foundational capabilities: formally specified communication protocols, robust coordination and synchronization mechanisms, and explicit human-in-the-loop pathways for oversight and exception handling. A well-designed collaboration layer treats inter-agent communication as a first-class concern, with typed messages, schemas, and contracts that are versioned, validated, and observable across the system.
Gateways: The Point of Entry and Exit to the Outside World
In traditional organizations, not every team member interacts directly with external stakeholders. Instead, organizations establish controlled interfaces (e.g. reception desks, customer service departments, sales teams, partner relations offices) that serve as designated points of contact between the internal organization and the outside world. These boundary-spanning units perform critical functions: they authenticate visitors, route requests to appropriate departments, translate external inquiries into internal work items, enforce security policies, and format internal outputs for external consumption. They act as both filters and translators, ensuring that the organization’s internal operations remain coherent while still responding effectively to external demands. The design and quality of these interfaces fundamentally shape how the organization is perceived, how efficiently it operates, and how well it scales under varying loads of external interaction.
Agentic systems face an identical challenge. Without properly designed gateways, the entire multi-agent architecture becomes inaccessible, ungovernable, and brittle. Gateways are the primary interface components that expose the agentic system to external systems, users, and services through various protocols and communication patterns. They serve as the bridge between the outside world and the internal agent mesh, translating external requests into messages that agents understand and routing them to the appropriate autonomous actors within the system.
Equally important, they manage the reverse flow: taking agent responses and formatting them appropriately for the receiving system or end user. Gateways are not mere pass-through layers; they are active, intelligent components that handle authentication, authorization, request enrichment, context injection, protocol translation, and response formatting. The architectural significance of gateways cannot be overstated—while internal agents handle domain logic, reasoning, and task execution, gateways define how the system presents itself to the world and how the world interacts with it.
A well-designed gateway layer establishes security boundaries by authenticating external requests and enforcing access policies before any interaction reaches internal agents, provides protocol abstraction allowing the same agentic system to serve REST APIs, webhook endpoints, real-time streaming interfaces, event-driven integrations, and chat platforms without requiring agents to handle protocol-specific concerns, and enables context injection through the configuration of a specific system purpose that frames how all incoming requests should be interpreted.
From an organizational design perspective, gateways function like customer-facing departments with explicit mandates and operating procedures. Just as a sales team operates differently from a technical support desk despite both serving external stakeholders, different gateway types optimize for different interaction patterns and use cases. A REST-based gateway might prioritize request-response cycles with immediate task acknowledgment and polling-based status retrieval, analogous to submitting a support ticket and checking its status. A real-time streaming gateway with server-sent events and messages sent over a message broker mimics a live conversation with instant feedback, similar to speaking with a customer service representative. A webhook gateway operates like an automated notification system, receiving external events and triggering internal processes without requiring synchronous responses. The importance of deliberate gateway design becomes evident when considering operational requirements and failure modes.
In organizations, poorly designed customer touchpoints create bottlenecks, frustration, security vulnerabilities, and reputational damage. The same holds for agentic systems. Gateways that lack proper authentication expose the entire agent mesh to unauthorized access, those without rate limiting or request validation invite abuse and instability, and those that fail to provide clear error messages leave external systems in ambiguous states. Conversely, well-designed gateways provide observability into external interactions, enforce consistent policies, enable gradual rollout of new capabilities, and allow the internal agent architecture to evolve independently of external interfaces.
A mature agentic system architecture recognizes that different use cases may require different gateway configurations even when using the same underlying agent infrastructure, a principle directly analogous to how a single organization might operate distinct customer service processes for enterprise clients versus individual consumers. The gateway layer provides a critical decoupling mechanism—by separating external protocol concerns from internal agent logic, the architecture gains flexibility. Agents can be refactored, replaced, or reorganized without breaking external integrations, as long as the gateway contract remains stable. New external interfaces can be added without modifying agents, and authentication mechanisms can be upgraded system-wide by updating gateway configurations rather than touching every agent.
This separation of concerns mirrors the organizational principle of having specialized boundary-spanning roles that shield internal teams from the volatility and heterogeneity of external interactions. Ultimately, the effectiveness of an agentic system is not determined solely by the sophistication of its agents, but by how accessible, secure, and reliable those agents are to the systems and users that need them. Gateways define this accessibility. They determine whether external systems can integrate easily or struggle with complexity, whether security policies are enforced consistently or bypassed through ad-hoc channels, and whether users experience responsive, well-formatted interactions or opaque, frustrating delays. Designing an agentic system without thoughtful gateway architecture is akin to building an organization with world-class internal teams but no coherent way for customers to engage with them—the capability exists, but it remains locked away, inaccessible, and ultimately unrealized in terms of delivered value.
Given the strategic importance of gateways, organizations must evaluate agentic frameworks not only on their pre-built gateway offerings but on their extensibility at the gateway layer. Production deployments inevitably encounter integration requirements beyond standard patterns—proprietary systems, legacy APIs, domain-specific protocols, custom authentication flows. The ability to develop custom gateways without architectural compromises becomes essential.
Frameworks like Solace Agent Mesh address this through a Gateway Development Kit (GDK) that abstracts agent-to-agent protocol translation complexity, providing a structured foundation for building custom gateways that inherit core capabilities while allowing developers to focus on protocol-specific logic. This ensures new integration requirements can be addressed through extension rather than exception, allowing the system to grow with organizational needs rather than constraining operational reach.
Tool Architecture
Tools transform agents from sophisticated conversationalists into actors capable of affecting the world. Without tools, an agent can only generate text. With tools, it can retrieve data, execute transactions, trigger workflows, and integrate with the systems that run your enterprise.
What Is a Tool, Really?
A tool is a capability that an agent can invoke to perform a specific operation. Tools bridge the gap between natural language reasoning and deterministic system interaction. When an agent decides to use a tool, it generates a structured request (typically JSON) that specifies the tool name and parameters. The tool executes and returns results that become part of the agent’s context for continued reasoning.
This definition encompasses tremendous variety: simple API calls, complex multi-step operations, database queries, file manipulations, external service integrations, and even invocations of other agents. The common thread is that tools extend what an agent can do beyond pure language processing.
Tool Granularity: Fine-Grained vs. Coarse-Grained
One of the most consequential design decisions in tool architecture is granularity. Consider two approaches to giving an agent access to customer data:
Fine-grained approach:
get_customer_name(customer_id)get_customer_email(customer_id)get_customer_orders(customer_id)get_customer_address(customer_id)
Coarse-grained approach:
get_customer_profile(customer_id)— returns all customer data
Fine-grained tools give the agent precise control and minimize data transfer, but require more tool calls and more decision-making about which tools to invoke. Coarse-grained tools reduce decision complexity but may fetch unnecessary data and consume context tokens on information the agent does not need.
The right granularity depends on your use case. For agents that typically need comprehensive customer information, coarse-grained tools reduce latency and simplify agent logic. For agents that perform targeted lookups, fine-grained tools prevent context pollution.
The LLM as a Tool
A powerful pattern emerging in production systems is treating LLM invocations themselves as tools. When an agent encounters a task requiring specialized reasoning, it can invoke an LLM with a specific prompt rather than handling everything in its primary context.
This pattern enables several architectural benefits. First, it allows model selection per task—using a small, fast model for classification while reserving expensive, capable models for complex reasoning. Second, it provides context isolation, preventing specialized reasoning from polluting the main agent’s context. Third, it enables prompt specialization, where each LLM tool can have optimized prompts for its specific function.
MCP, REST, and the Data Freshness Dilemma
Tools interact with external systems through various protocols. REST APIs remain the dominant pattern for enterprise integration, but the Model Context Protocol (MCP) is emerging as a standardized way for LLM-based systems to interact with data sources and tools.
The data freshness dilemma arises because most enterprise data lives in systems of record that are not optimized for real-time agent access. An agent checking inventory levels might query an ERP system that updates on batch cycles. An agent answering customer questions might access a CRM that reflects yesterday’s state.
Event-driven architecture addresses this dilemma by streaming state changes as they occur. Rather than polling systems of record, agents subscribe to event streams that notify them of relevant changes. This inverts the traditional integration pattern: instead of agents pulling stale data, fresh data pushes to agents.
Where Logic Lives
A critical architectural question is where business logic should reside. Consider a tool that processes refunds:
- In the tool: The tool enforces refund limits, validates eligibility, and applies business rules. The agent simply requests a refund; the tool handles complexity.
- In the agent: The agent reasons about refund eligibility, calculates appropriate amounts, and calls a simple execute_refund tool that performs the transaction.
- In the gateway: A policy layer intercepts all refund requests, enforces limits regardless of which agent or tool initiated the action.
- In the orchestrator: The workflow engine manages refund approval chains, escalating large refunds to human review.
The answer often involves all four layers, each handling appropriate concerns. Tools should handle system-specific integration logic. Agents should handle reasoning and decision-making within their domain. Gateways should enforce organization-wide policies and authorizations. Orchestrators should manage workflow coordination and plan actions that spans multiple agents.
Tool Discovery and Registration
As agent ecosystems grow, managing tool availability becomes a governance challenge. Which agents can access which tools? How do new tools become available? How are tool changes communicated to dependent agents?
Production systems typically implement tool registries that catalog available tools with their schemas, permissions, and version information. Agents query the registry to discover tools appropriate for their role. When tools change, the registry provides a single point of update rather than requiring changes to every agent.
The Context Challenge
In every generation of computing, progress is constrained by a dominant bottleneck. Early systems were bound by compute and cost. Then storage capacity and disk I/O emerged as the limiting factor. The rise of distributed systems shifted the bottleneck to network latency. Today, in agentic systems powered by large language models, the most limiting constraint is context.
Context is not just a resource in agentic systems—it is the hard ceiling that governs what any set of agents can reliably understand, coordinate, and execute at scale. In simple terms, context is the attention span of an LLM. It is the amount of information a model can effectively attend to at any given moment. And like poorly designed organizations, most agentic systems fail not because of lack of intelligence, but because of information overload, misrouting, unclear accountability, and lack of real-time critical business information.
Attention Dilution
Every consumed token in an LLM interaction competes for a finite pool of attention. As context length increases, attention is spread thinner, forcing the model to allocate focus across a growing surface area. This results in slower responses, increased cost, degraded reasoning, and potentially increased hallucinations.
Context composed of repeated summaries, full conversation history, verbose logs, or uncurated memory hinders the model’s ability to distinguish what is important from what is merely present. A routing agent that should make a simple decision must parse thousands of tokens of historical context before acting. A synthesis agent may fixate on recent tool output while ignoring a critical constraint introduced earlier. Research from Stanford University examined the Lost in the Middle effect: models exhibit a U-shaped performance curve driven by primacy and recency bias, attending better to information at the beginning or end of the context window.
“Context is both king and bottleneck in agentic systems. What is included—and for that matter excluded—shapes decisions and the content of responses. Every additional token carries a hidden tax.”
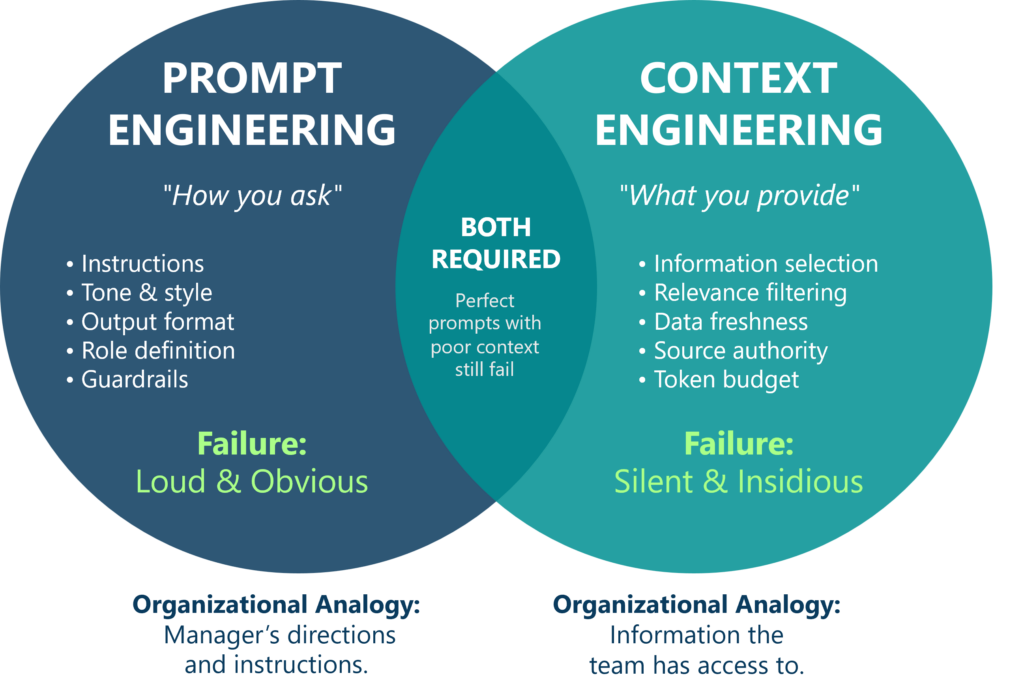
Prompt vs. Context Engineering
The internet is saturated with guides highlighting the promise of better instructions yielding better performance. While prompt engineering is crucial for system effectiveness, it captures only part of the problem.
Prompts shape behavior, tone, and output alignment, but they operate within the boundaries of whatever information the model has been given. Prompt engineering optimizes how you ask a model to perform a task. Context engineering optimizes what information you choose to provide in the first place.
In agentic systems, context engineering is the harder problem and ultimately the more consequential one. Poor prompts are visible and correctable—they fail loudly. Poor context fails quietly. It subtly degrades reasoning, biases decisions, and increases hallucinations without obvious signs of error. A perfectly designed instruction set coupled with bloated, noisy context will still degrade as context length grows, while cleanly curated context can rescue performance even with relatively simple prompts.
| Dimension | Prompt Engineering | Context Engineering |
| Focus | Instructions | Information selection |
| Scope | Syntax, tone, format | Relevance, freshness, authority |
| Failure Mode | Clear: ambiguous output | Silent: hallucination, drift, latency |
| Organizational Analogy | How a manager gives directions | What information reaches the team |
Hierarchies to the Rescue
Decades of organizational research point to a consistent conclusion: high-performing teams in scaling organizations are not flat, and they are not information-symmetric. Information symmetry—where every individual has access to the same information—becomes counterproductive at scale.
Functional organizational structures address this by grouping teams around domain expertise, each led by a functional manager. This intentional asymmetry ensures that specialists focus deeply on what matters within their scope, while higher-level leaders operate on synthesized, cross-functional insights rather than raw data.
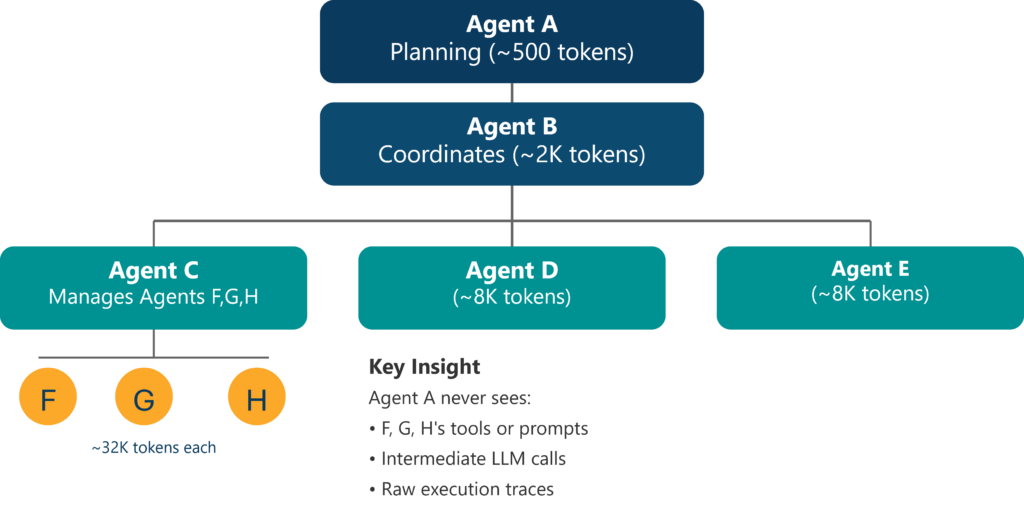
Agentic systems face the same scaling pressures, yet many are designed as flat meshes of agents connected through point-to-point wiring and shared global context. When all agents see all tools, all histories, and all intermediate reasoning steps, these systems inherit the worst properties of poorly designed organizations. Context grows uncontrollably, costs explode, and reasoning quality degrades through context rot.
By structuring agents into explicit layers of responsibility, ownership of context selection and summarization gets delegated to dedicated functions. This introduces information compression layers: lower-level agents operate on rich but narrowly scoped context, mid-level agents filter and abstract outputs from sub-agents, and higher-level agents reason exclusively over distilled signal rather than raw execution traces.
The Four Principles of Agent Design
- Domain-Aligned Scope: Design agents around natural organizational and functional boundaries, using human roles as a primary guide. By grouping related tools and functionality within specific scopes, you ensure that agents have a coherent purpose rather than becoming mediocre generalists. The person responsible for writing an agent’s instructions will deeply understand the domain requirements and can update that specific agent without affecting others.
- Context Optimization: Every piece of information in an agent’s context must serve a specific purpose for the current task. Be deliberate about what is included in system prompts, how tools are described, and which parts of conversation history are maintained. Include only essential information and avoid lengthy examples unless strictly necessary. Additional context can always be provided later via artifacts or tool results when needed.
- Task Encapsulation: Delegate complex, multi-step workflows to sub-agents when the primary agent only requires the final result. The guiding question: does the main agent need to see every intermediate step? If only the outcome matters, encapsulate the task in a sub-agent. This creates clean interfaces between components, allowing the main agent to orchestrate while specialists handle complex reasoning behind the scenes.
- History Management: Preserve what matters while discarding what does not through an intelligent data management layer. Think carefully about which information needs to persist and which details can be summarized, archived, or handled entirely by sub-agents. Use artifacts where necessary, execute calculations outside the LLM context, and delegate to sub-agents when appropriate.
Prompt Engineering for Production
Designing Prompts That Scale
The gap between a demo that impresses executives and a production system that serves real users is often measured in prompt engineering maturity. In demos, you can hand-craft the perfect prompt for anticipated scenarios. In production, you face the full entropy of human expression, unexpected edge cases, and relentless pressure to modify behavior without breaking what already works.
The Persistence of Schemas
There is a seductive fantasy that sufficiently intelligent models will eliminate the need for formal data contracts. If an LLM can understand natural language, why constrain it with rigid schemas? This fantasy collides with reality the moment you try to build reliable systems.
You can never escape schema management. The same disciplines that made API design successful—clear contracts, versioning, validation—apply with even greater force to agentic systems.
- LLMs are probabilistic, not deterministic: Given the same prompt, an LLM might structure its output differently across invocations—using customer_id one time and customerId the next. Without schema enforcement, downstream systems must handle infinite variation.
- Integration requires precision: When an agent’s output feeds into a database, triggers a workflow, or updates a system of record, the receiving system needs predictable structure. A payment system does not care how eloquently an agent reasons; it needs the transaction amount in a specific field with a specific type.
- Error detection requires expectations: Without schemas, how do you know if an agent’s output is wrong? Did it fail to extract a required field, or does that field simply not exist? Schema validation provides immediate feedback when outputs do not match expectations.
- Evolution requires contracts: As your system evolves, you will need to change what agents produce. Schemas make change visible and manageable. You can assess the impact of adding a field, changing a type, or deprecating a capability.
System Prompts vs. Dynamic Context
System Prompts: The Foundation
System prompts establish the baseline identity, capabilities, and constraints of an agent. They are relatively static—changing infrequently and applying uniformly across interactions. System prompts define identity and role (who is this agent and what expertise does it bring), capabilities and boundaries (what can it do and refuse to do), and output conventions (how should it format responses). System prompts should be version-controlled, tested, and deployed with the same rigor as application code.
Dynamic Context: The Runtime Input
Dynamic context includes everything that varies per interaction: user input, retrieved documents, current state, tool outputs, and conversation history. The key insight is that system prompts define how to process dynamic context. They establish the interpretation framework; dynamic context provides the material to be interpreted.
Modular and Additive Prompt Architecture
Production prompt systems rarely consist of a single monolithic prompt. Instead, they layer multiple components that combine at runtime, following a specificity gradient: components closer to infrastructure are more generic, while components closer to the user are more specific.
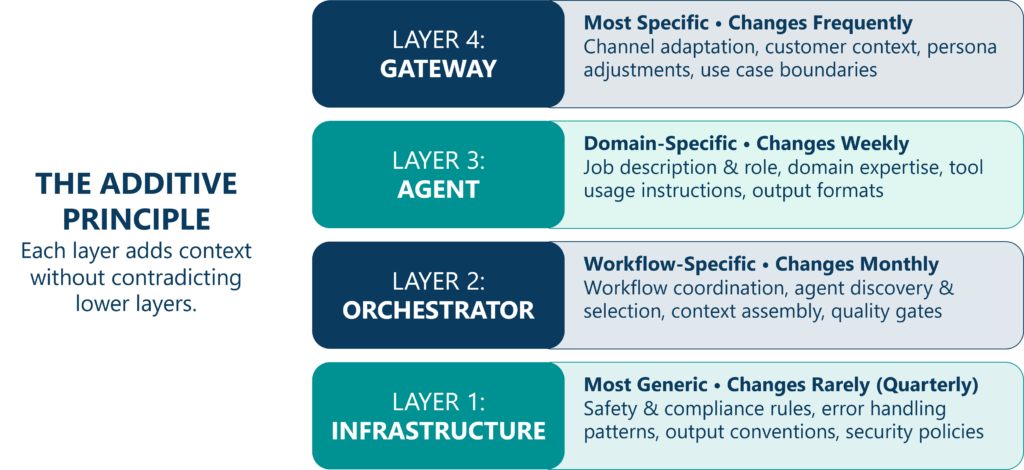
- Layer 1: Infrastructure Prompts (Most Generic): Universal behaviors applying across your entire agent ecosystem: safety rules, compliance requirements, output structure conventions, error handling patterns.
- Layer 2: Orchestrator Prompts: Workflow-specific instructions: how to coordinate with other agents, what context to assemble, quality gates and compliance checkpoints.
- Layer 3: Agent Prompts: Individual agent job descriptions: domain expertise, tool usage instructions, specialized knowledge, output format requirements.
- Layer 4: Gateway Prompts (Most Specific): Use-case-specific adaptations: channel requirements, customer context, persona adjustments for specific brands or situations.
Each layer should add to the layers below it, not contradict them. When conflicts arise, they indicate architectural problems—either the lower layer is over-specified, or the upper layer is trying to do something it should not.
Testing and Validating Prompt Changes
“Prompts are code. When you change a prompt, you change system behavior.”
Evaluations (evals) are to LLM-based systems what tests are to traditional software. They provide confidence that changes do not break existing functionality, that new capabilities work as intended, and that the system meets quality standards.
- Functional evals: Does the agent produce correct outputs for known inputs? Create test cases with expected outputs and verify the agent produces them.
- Regression evals: Do prompt changes break existing functionality? Maintain a golden set of input-output pairs that must continue working.
- Quality evals: Does the agent meet quality standards? Use automated metrics and human evaluation to assess output quality.
- Adversarial evals: Does the agent handle edge cases and attacks gracefully? Test with malformed inputs, injection attempts, and boundary conditions.
The challenges of testing agentic systems closely parallel the challenges the industry faced with microservices. The teams that invest early—building eval datasets, implementing automated scoring, integrating testing into CI/CD—will have significant advantages as the space matures.
Specification Strategy
Building for Reuse and Scale
The difference between a prototype that impresses stakeholders and a production system that survives contact with real users often comes down to specification strategy. In agentic AI systems, this challenge is amplified: you are not just designing APIs between services, you are defining contracts between entities that make autonomous decisions, handle ambiguous inputs, and must gracefully degrade when the unexpected occurs.
When to Reuse, When Not To
The instinct to maximize reuse is deeply ingrained, but in agentic systems, premature generalization creates more problems than it solves. Different types of specifications have different reuse profiles.
High-Reuse Candidates
- Event schemas and data contracts represent the highest-value reuse target. When an agent publishes a CustomerOrderCreated event, every downstream consumer benefits from a consistent schema. These contracts multiply value across the entire system.
- Tool implementations that interact with enterprise systems should be designed for maximum reuse. A well-designed tool with clear input/output contracts can serve dozens of agents without modification.
- Security and identity patterns must be consistent across your entire agent ecosystem. Authentication, authorization, audit logging, and data classification rules should be implemented once at the gateway level and enforced uniformly.
Low-Reuse Components
- Agent system prompts are frequently over-generalized. The temptation to create a universal customer service agent leads to bloated prompts, confused behavior, and poor performance. Agents should be specialists with focused job descriptions.
- Orchestration logic is highly use-case-specific. The workflow for fraud investigation differs fundamentally from loan application processing. Attempting to create a universal orchestrator typically results in complex conditional logic harder to maintain than purpose-built orchestration.
- Context assembly patterns vary significantly between use cases. The context needed for a quick FAQ response differs from what is needed for complex analysis. Standardizing context assembly often means over-fetching or under-fetching.
Allocating Specifications Across the Stack
The Security Gateway Layer
Security gateways form the outermost boundary of your agent system—the point where external requests enter and responses exit. This layer should specify user authentication and session management, broad access control policies, rate limiting and abuse prevention, system-wide persona and boundaries, and use case scoping. Security gateways should NOT specify business logic, domain rules, or workflow sequences.
The Orchestrator Layer
Orchestrators coordinate multi-agent workflows, managing which agents are invoked, in what sequence, and with what context. This layer should specify workflow coordination and sequencing, agent discovery and selection, quality gates and compliance checkpoints, and context assembly logic. Orchestrators should NOT specify domain expertise, detailed analysis, or tool implementation details.
The Agent Layer
Individual agents represent domain expertise, specified primarily through a job description and a minimal set of focused prompts. This layer should specify the agent’s role and purpose, tool usage and output formats, and domain-specific knowledge. Agents should NOT specify workflow sequencing, access control, or cross-agent coordination.
Event Schema Governance
Event schema governance is arguably more crucial than traditional API governance because the loose coupling that makes event-driven architecture powerful also makes problems harder to diagnose at runtime. When an agent publishes a malformed event, the failure might not manifest until much later, in a completely different part of the system.
This temporal and spatial separation demands proactive governance: maintain a central schema registry with version history, automatically verify compatibility before deploying schema changes, use hierarchical topic structures that encode event metadata, implement dead letter handling for events that cannot be processed, and include event schema validation in your CI/CD pipeline.
Scaling
Event-driven architecture provides unique advantages for scaling agentic systems—not just in enabling scale, but in detecting when scaling is needed.
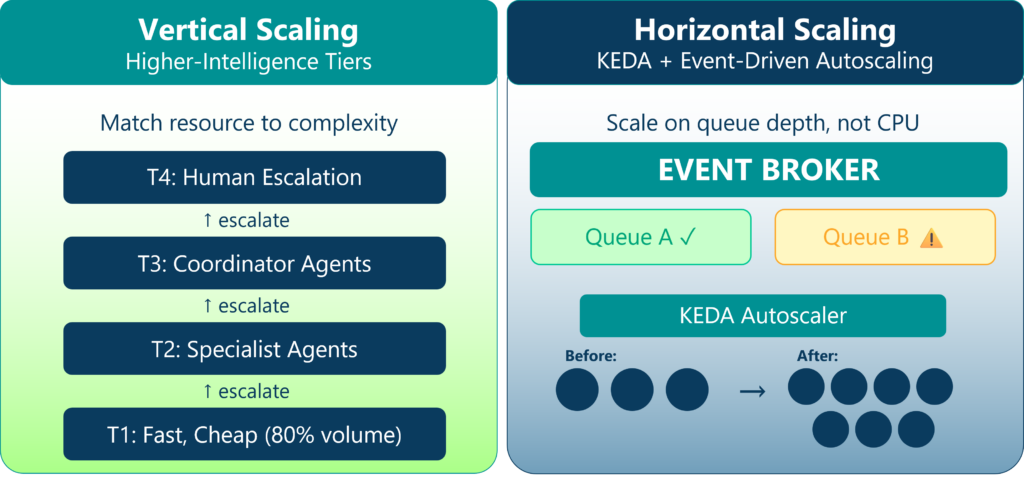
Horizontal Scaling: Adding More Instances
The loose coupling between event producers and consumers means you can add or remove agent instances without coordination with the rest of the system. Queue depth, processing rate, and message age provide direct, real-time scaling signals. KEDA (Kubernetes Event-Driven Autoscaling) bridges event-driven architecture and container orchestration, enabling automatic scaling based on event metrics rather than just CPU and memory utilization.
Vertical Scaling: Hierarchical Communication
Vertical scaling in agentic systems means adding layers of intelligence to handle more complex problems. Simple tasks go to fast, cheap agents. Complex tasks escalate to sophisticated agents or orchestrators. Some problems require human judgment. The hierarchy includes clear escalation paths that hand off to humans with full context about what automated agents have already tried.
Security Architecture
Agent Identity and Authorization
Security architecture for agentic AI systems extends far beyond traditional application security. The autonomous nature of AI agents, their ability to access sensitive data and execute consequential actions, and their potential to communicate with other agents all introduce security considerations that require thoughtful architectural responses.
Three Levels of Authentication and Authorization
Consider an HR system as a concrete example. This system requires different levels of access control that illustrate principles applicable across enterprise agentic deployments.
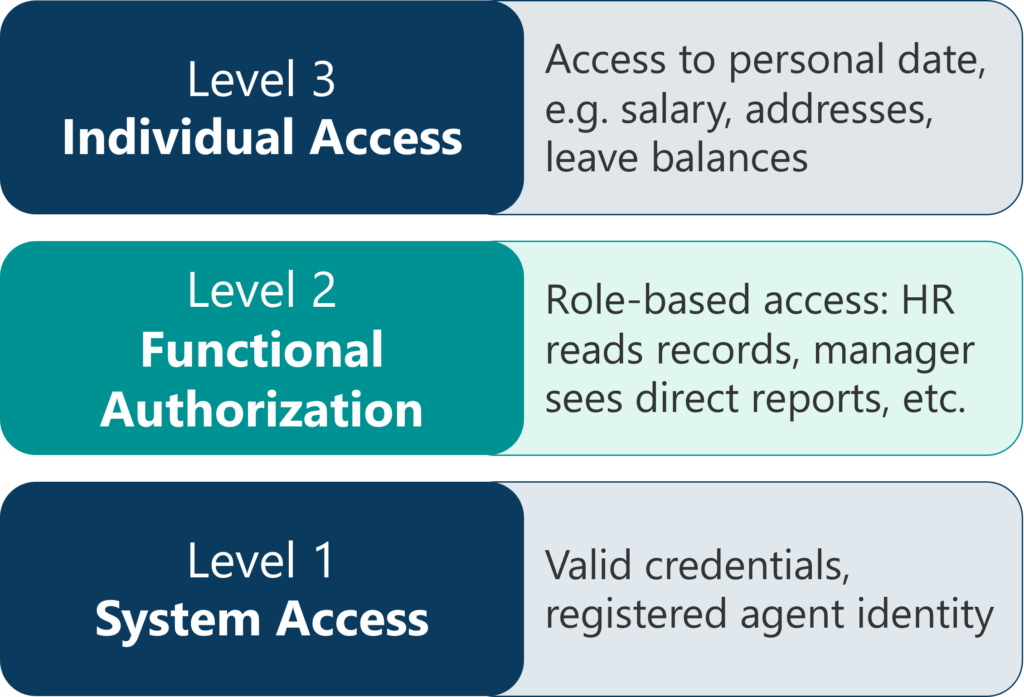
System-Level Access (Authentication)
The first level establishes whether an entity—human or AI agent—is permitted to interact with the system at all. This is traditional authentication: verifying identity before granting any access. AI agents must be properly registered and authenticated as legitimate internal resources before they can interact with any functionality.
Role-Based Access (Functional Authorization)
The second level applies role-based access control to determine what actions authenticated users and agents can perform. HR representatives might have read access to employee records. Managers might have access to their direct reports but not to employees outside their reporting structure. AI agents must similarly be assigned appropriate roles that constrain their capabilities.
Individual-Level Access (Personal Data Protection)
The third level ensures that sensitive personal information remains accessible only to the individuals it concerns. Employees should be able to view their own salary data, holiday schedules, and personal addresses—information that even HR representatives might not be authorized to access. When an AI agent assists an employee, the agent must operate within this individual-level constraint.
“Authorization in agentic systems must be both hierarchical and contextual. An AI agent’s effective permissions at any moment depend not only on its registered role but also on the specific user it represents and the particular resource being accessed.”
The Imperative of Data Proximity
When data originates in a system like an HR database, it carries with it not just information but the context of its access restrictions. However, as that data is extracted, transformed, and loaded into secondary systems—analytics platforms, data warehouses, AI training datasets—these authorization contexts become progressively diluted.
An AI agent granted access to a data lake for analytics purposes might inadvertently gain access to sensitive information it would never have been able to retrieve from the source system. The agent is not circumventing security controls; rather, the security controls ceased to exist when the data left its original context.
The architectural implication is clear: wherever possible, agentic AI systems should query data at its source rather than from consolidated repositories. When an AI agent needs to answer a question about employee benefits, it should retrieve that information directly from the HR system—where proper authorization controls can be enforced.
Impersonation vs. Delegation
Two primary patterns have emerged for how AI agents authenticate when accessing resources on behalf of users.
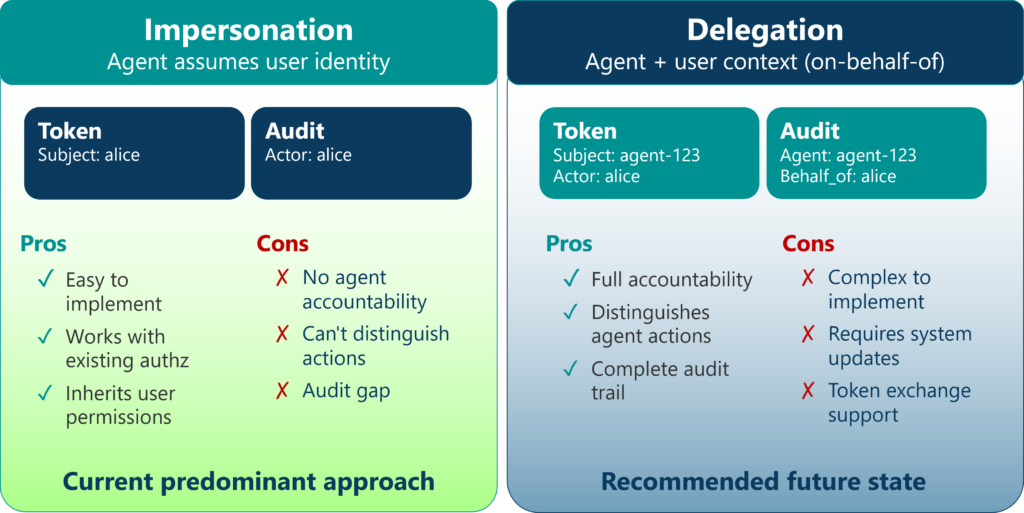
Impersonation
The agent assumes the identity of the user it serves. When the agent accesses a resource, audit logs show the user’s identity, not the agent’s. This model has simplicity: existing authorization frameworks work without modification. However, impersonation creates an accountability gap. When an AI agent executes a financial transaction, organizations need to know not just which user authorized the action but whether it was taken by the human directly or by their AI agent.
Delegation
Formalized through OAuth 2.0 on-behalf-of flows, the AI agent authenticates with its own identity while presenting credentials that demonstrate authorization to act on behalf of a specific user. The resulting access token carries both identities. Systems can log both, apply authorization rules based on the combination, and make informed decisions about agent-initiated versus human-initiated actions.
While delegation represents the more mature security model, adoption remains limited due to implementation complexity. Organizations should plan for eventual migration to delegation patterns, even if initial implementations use impersonation for pragmatic reasons.
Agent-to-Agent Authentication
As agentic AI systems scale to collaborative multi-agent architectures, the security perimeter expands to encompass agent-to-agent communications. The potential for unauthorized agents to infiltrate these networks necessitates robust mutual authentication mechanisms.
Security gateways at multiple points in the agent communication flow provide defense in depth: token validation gateways verify that access tokens are valid and appropriate, content inspection gateways examine payloads for policy violations, and rate limiting gateways prevent runaway agents from overwhelming systems.
Access Control in Event-Driven Systems
Event-driven architectures introduce unique access control considerations. When agents communicate through event brokers, traditional endpoint-based authorization models must adapt to event-based paradigms.
Topic-based access control provides several advantages: natural security boundaries aligned with data domains, separation of concerns at the infrastructure level, and clear audit trails. Events containing HR information flow through HR topics accessible only to authorized agents. Financial events flow through separate channels with their own rules.
Secure by Default Architecture
Effective security architecture begins with a fundamental principle: locked down by default. Every agent, every communication channel, every data access path should be denied by default, with access granted only through explicit authorization decisions that are documented and auditable.
This principle stands in contrast to the temptation to start with permissive access and tighten controls later. The pressure to demonstrate functionality quickly leads many organizations to deploy agents with overly broad access rights. These temporary permissions have a tendency to become permanent, creating security debt that compounds over time.
The Event-Driven Advantage
Why HTTP Is Not Enough
Throughout this whitepaper, we have referenced event-driven architecture as foundational to scalable agentic systems. This chapter consolidates the advantages that make event-driven patterns essential for enterprise deployments.
Shock Absorption: Handling Traffic Spikes
Traditional request-response architectures couple producers tightly to consumers. When a spike in requests occurs, every component in the chain must handle the load simultaneously or fail. In event-driven systems, the event broker absorbs traffic spikes. Producers can publish events at whatever rate the business generates them. Consumers process at their own pace, catching up during quieter periods. This decoupling prevents cascading failures and enables graceful degradation.
Geographic Distribution Without the Pain
Enterprise deployments span multiple regions, clouds, and data centers. Event-driven architecture supports geographic distribution naturally through event mesh topologies that replicate events across locations. Agents can run where data resides, subscribing to local event streams while participating in a global coordination fabric. This reduces latency, supports data residency requirements, and provides resilience against regional failures.
Enterprise Readiness: Non-Functional Requirements
Production systems must satisfy requirements that demos can ignore: guaranteed delivery (events are not lost even if consumers are temporarily unavailable), ordering guarantees (events are processed in the correct sequence when order matters), exactly-once processing (critical operations are not duplicated even during retries), and replay capability (historical events can be reprocessed for recovery or analysis).
Enterprise event brokers provide these guarantees at the infrastructure level, freeing agent developers to focus on business logic rather than distributed systems complexity.
Session Management and Connection Resilience
Agentic workflows often span extended time periods—hours, days, or longer. HTTP connections are ill-suited to such durations. Event-driven patterns support long-running workflows naturally: agents can disconnect and reconnect without losing state, events persist until processed, and workflow progress is captured in the event stream itself.
Where EDA Fits in the Agent Mesh Story
The agent mesh concept—a distributed architecture where multiple agents collaborate—requires a communication fabric that supports dynamic topologies, loose coupling, and scalable coordination. Event-driven architecture provides this fabric.
Agents join and leave the mesh by subscribing to and unsubscribing from topics. New agent types can be added without modifying existing agents. The event broker handles routing, ensuring that events reach interested consumers without producers needing to know who those consumers are.
This architectural pattern enables the organizational structures discussed earlier. Flat structures emerge from peer-to-peer event patterns. Functional structures emerge from topic hierarchies aligned with domains. Matrix structures emerge from agents subscribing to multiple topic patterns based on their cross-cutting responsibilities.
From Design to Deployment
Making It Real
The principles in this whitepaper translate into concrete implementation steps. This chapter provides guidance for moving from design to production.
Architecture Review Checklist
Before deploying an agentic system, validate that your architecture addresses these concerns:
- Use case validation: Does this problem genuinely benefit from agentic AI, or would simpler approaches suffice?
- Agent boundaries: Is each agent’s scope clearly defined with explicit job descriptions?
- Context strategy: How is context managed to prevent attention dilution and context rot?
- Tool design: Are tools appropriately granular with clear input/output contracts?
- Schema governance: Are event schemas versioned, validated, and governed?
- Security model: Have authentication, authorization, and audit requirements been addressed at each layer?
- Scaling strategy: How will the system handle increased load? What triggers scaling?
- Failure modes: What happens when agents fail, time out, or produce unexpected results?
- Human escalation: When and how do issues escalate to human operators?
- Observability: Can you trace requests through the system and understand agent decisions?
Common Anti-Patterns and How to Avoid Them
- The Monolithic Agent: One agent tries to do everything, resulting in bloated context, confused behavior, and poor performance. Instead, design specialists with focused responsibilities. Use orchestrators to coordinate.
- Global Context Sharing: All agents see all information, leading to context pollution and reasoning degradation. Instead, implement information hierarchies where agents receive only context relevant to their role.
- Point-to-Point Sprawl: Agents call each other directly, creating a web of dependencies that becomes impossible to understand or modify. Instead, communicate through events with well-defined topics and schemas.
- Schema Anarchy: Every agent defines its own output format, making integration a constant battle. Instead, establish schema governance early. Define contracts before building agents.
- Security Afterthought: Security is bolted on after the system is built, creating gaps and inconsistencies. Instead, design security in from the beginning. Lock down by default; grant access explicitly.
Monitoring and Observability
Agentic systems require observability that goes beyond traditional metrics:
- Decision tracing: Why did an agent make a particular choice? What context influenced the decision?
- Quality metrics: Are agent outputs meeting quality standards over time?
- Cost tracking: How much are you spending on LLM invocations? Which agents are most expensive?
- Latency analysis: Where is time being spent? Are bottlenecks in agents, tools, or external systems?
- Error categorization: Are failures due to agent reasoning, tool failures, or integration issues?
OpenTelemetry provides a foundation for distributed tracing. Event broker metrics reveal queue depths and processing rates. Custom instrumentation captures agent-specific concerns like token usage and decision confidence.
The Path to Production
Successful production deployments typically follow a progression:
- Start with a single, well-chosen use case that demonstrates value without excessive risk.
- Build the foundational infrastructure: event broker, schema registry, security gateway.
- Develop agents incrementally, validating each with comprehensive evaluations.
- Deploy to a limited audience, monitoring closely and gathering feedback.
- Iterate based on real-world performance, expanding scope gradually.
- Establish governance processes before the second use case, capturing lessons learned.
- Scale horizontally as demand grows, using event metrics to drive autoscaling.
- Add use cases that leverage existing infrastructure and agents, maximizing reuse.
Each step builds capability and confidence. Resist the temptation to skip ahead—the organizations that succeed are those that build solid foundations before scaling.
Conclusion: Building for the Agentic Future
Throughout this whitepaper, we have explored agentic AI systems through an organizational lens—recognizing that designing effective multi-agent systems is fundamentally similar to designing effective organizations. Both involve autonomous actors constrained by roles, communication paths, and shared objectives. Both succeed or fail based on how well they manage complexity, coordinate action, and adapt to changing circumstances.
The core thesis bears repeating: event-driven architecture provides the foundation for enterprise-scale multi-agent systems. While point-to-point communication may suffice for simple demonstrations, production systems require the loose coupling, scalability, and governance capabilities that event-driven patterns provide.
Key Takeaways
- Design agents like you would staff a team—with clear job descriptions, defined scope, and explicit reporting structures.
- Context is the dominant constraint. Engineer it deliberately, or watch your system degrade under information overload.
- Schemas are not optional. The same disciplines that made API design successful apply with even greater force to agentic systems.
- Security must be designed in from the beginning. Locked down by default; access granted explicitly.
- Event-driven architecture is not just about scale—it is about managing the interaction complexity that defines agentic systems.
- Your first use case matters enormously. Choose wisely, execute well, and build momentum for what follows.
Tips for Getting Started
- Start with one use case: Apply the Goldilocks Zone framework to identify your first pilot project—important enough to matter, not so critical that failure is catastrophic. Validate that the problem genuinely benefits from agentic AI before committing resources.
- Assess your current architecture: Evaluate your existing agent investments. What COTS agents, departmental projects, and platform agents already exist? How might an event mesh unlock their collaborative potential?
- Invest in infrastructure early: The organizations that master agentic AI will be those that invest in event-driven infrastructure, schema governance, and evaluation pipelines now—not after technical debt accumulates.
- Build capability iteratively: Each project should build toward larger transformation. Treat early implementations as opportunities to develop expertise, establish patterns, and prove value to stakeholders.
The agentic AI landscape is evolving rapidly. The architectural decisions you make today will determine whether your systems scale successfully or collapse under unaccounted-for limitations. The frameworks in this whitepaper—rooted in organizational design principles and proven integration patterns—provide a foundation for building systems that deliver sustained value.
“The organizations that master use case selection—identifying where agents create genuine value while recognizing where they do not—will build sustainable competitive advantages from agentic AI. Those that deploy agents indiscriminately will waste resources chasing hype rather than delivering results.”
Your first use case awaits. Choose wisely, build thoughtfully, and scale confidently.

