AI is everywhere right now. Fraud detection, risk analytics, customer service automation, software development — organizations across industries are actively deploying AI across the board. But there’s one category that’s quietly delivering some of the highest ROI with the fastest payback: AI Operations, commonly called AIOps.AIOps applies AI to IT operations by using intelligent agents to monitor infrastructure, diagnose issues, automate routine tasks, and surface insights that would otherwise require hours of manual investigation. The appeal of AIOps is simple: the problems are well-defined, the data is already there, and the inefficiencies being replaced are enormous. You don’t need to convince anyone there’s a problem. Every ops engineer already knows exactly how their day looks.
Managing a Large Messaging Estate Takes Real Effort
Large organizations commonly run substantial middleware estates. Event brokers route data between systems, and keeping them healthy at scale requires dedicated expertise. Solace brokers are extremely powerful, handling mission-critical data flows with high throughput and reliability, but with that power comes operational depth. Diagnosing an issue typically means checking the broker manager for current configuration, pulling historical metrics from Prometheus, searching Splunk for relevant logs, and cross-referencing Solace documentation alongside internal runbooks. That process can easily take an hour or two per ticket, and during a critical outage, every minute matters.
If you multiply that effort and “operational latency” across a team handling dozens of tickets a week, you’ll realize that a significant chunk of engineering capacity gets consumed by work that should be automatable. BAU requests, health checks, capacity reviews, and documentation lookups are the tasks that keep experienced middleware engineers stuck in reactive mode rather than focused on strategic initiatives.
What Solace Has Built
Solace has built a multi-agent AIOps solution on top of Solace Agent Mesh to address exactly this challenge. It’s available as part of a service pack called the Solace AIOps Accelerator.
Solace Agent Mesh is Solace’s open, vendor-neutral platform for building and deploying agentic AI systems at production scale. It provides the orchestration, observability, security, and connectivity infrastructure that agents need to work reliably together — without locking you into a specific LLM or cloud provider. It’s the foundation that makes building trustworthy multi-agent applications practical rather than experimental.
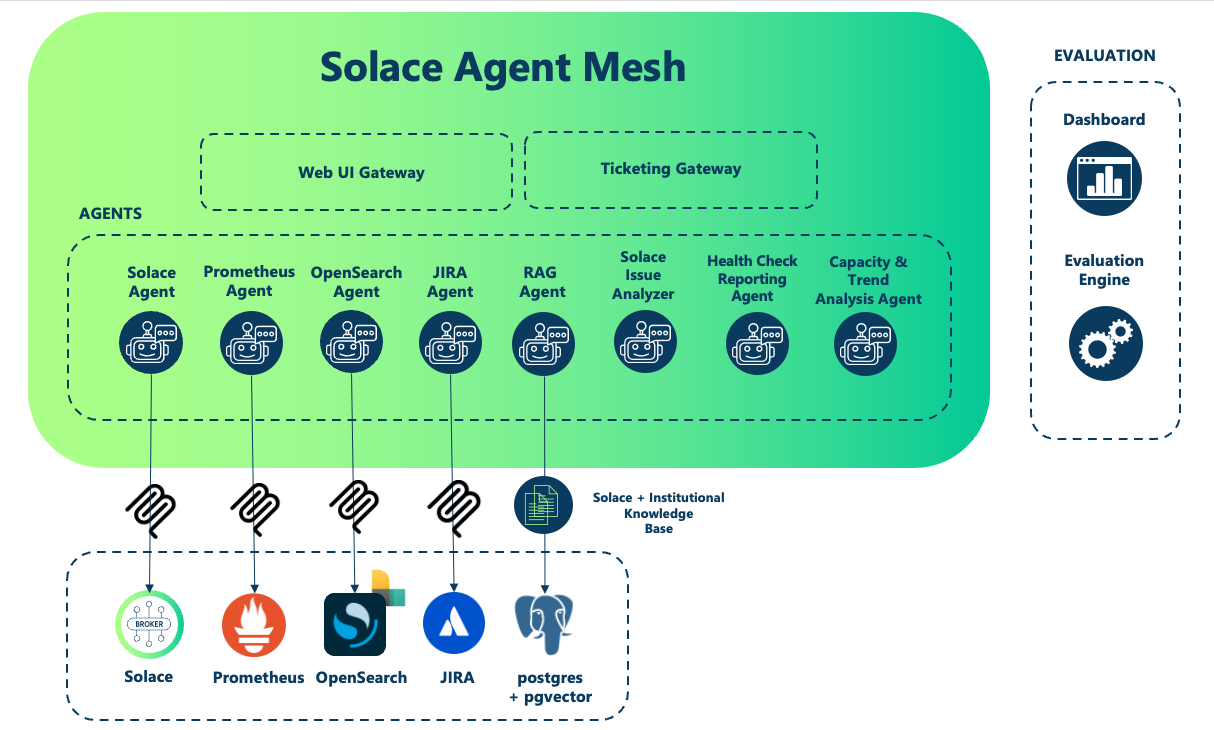
This AIOps solution is composed of several specialized agents, each focused on a specific operational domain:
- Issue Analyzer — the core diagnostic agent. It synthesizes current broker configuration, historical metrics, operational logs, institutional knowledge, and Solace documentation to produce a structured analysis with root cause assessment and recommended next steps. Every response includes detailed citations so engineers know exactly where the insights are coming from.
- Health Check Agent — generates comprehensive health check reports against your Solace brokers in minutes. This is work that Solace’s Professional Services team has traditionally done manually, requiring deep product expertise and significant time. The agent handles it automatically, surfacing configuration drift and best-practice violations without human intervention.
- Capacity and Trend Analysis Agent — monitors broker capacity and usage trends over time, generating reports that flag brokers approaching their limits before they become production incidents. The kind of analysis that prevents outages rather than simply responding to them.
- Prometheus, OpenSearch, JIRA, and RAG Agents — these work in the background to pull data from the monitoring and logging tools your team already relies on, and to surface relevant institutional knowledge at exactly the moment it’s needed.
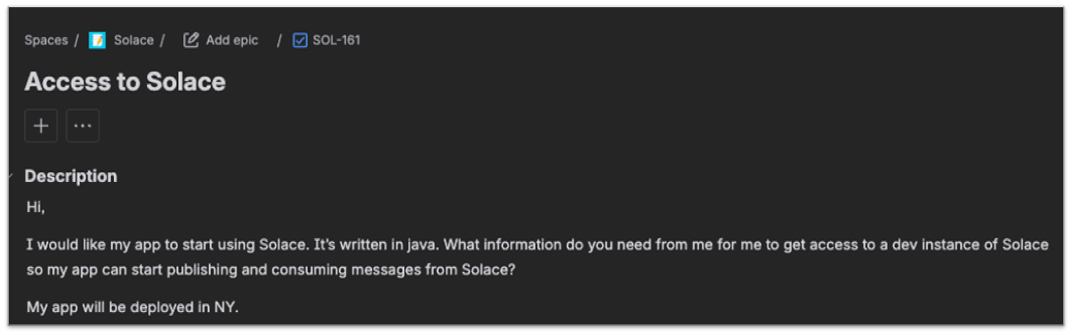
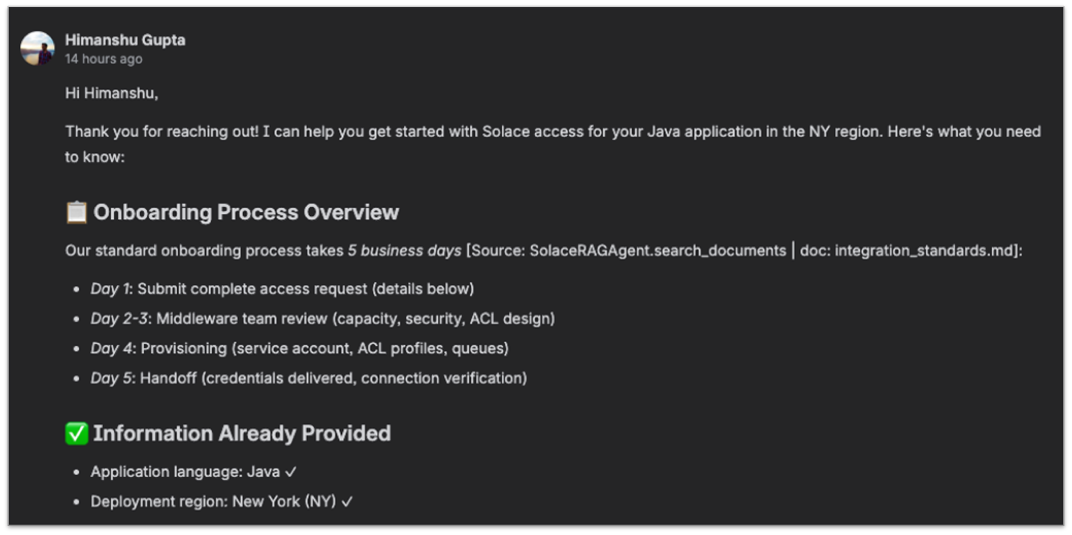
Sample Ticket Response for Onboarding Request with rich context leveraging company’s onboarding process.
One of the more compelling capabilities is the integration with ticketing platforms such as Atlassian JIRA. When a developer opens a support ticket, the solution automatically analyzes the issue and posts a comment with a root cause assessment and recommendations for the middleware team to review. This is human-in-the-loop by design. The ticket owner reviews an AI-generated response already enriched with current broker state, historical metrics, and institutional knowledge, then validates and acts. What used to take one to two hours now takes about five minutes.
The Features That Make an AI Ops Solution Production-Ready
Building a chatbot that can answer questions about Solace is the easy part. Building something an operations team can trust and rely on in production is a different challenge entirely. A few things make the difference.
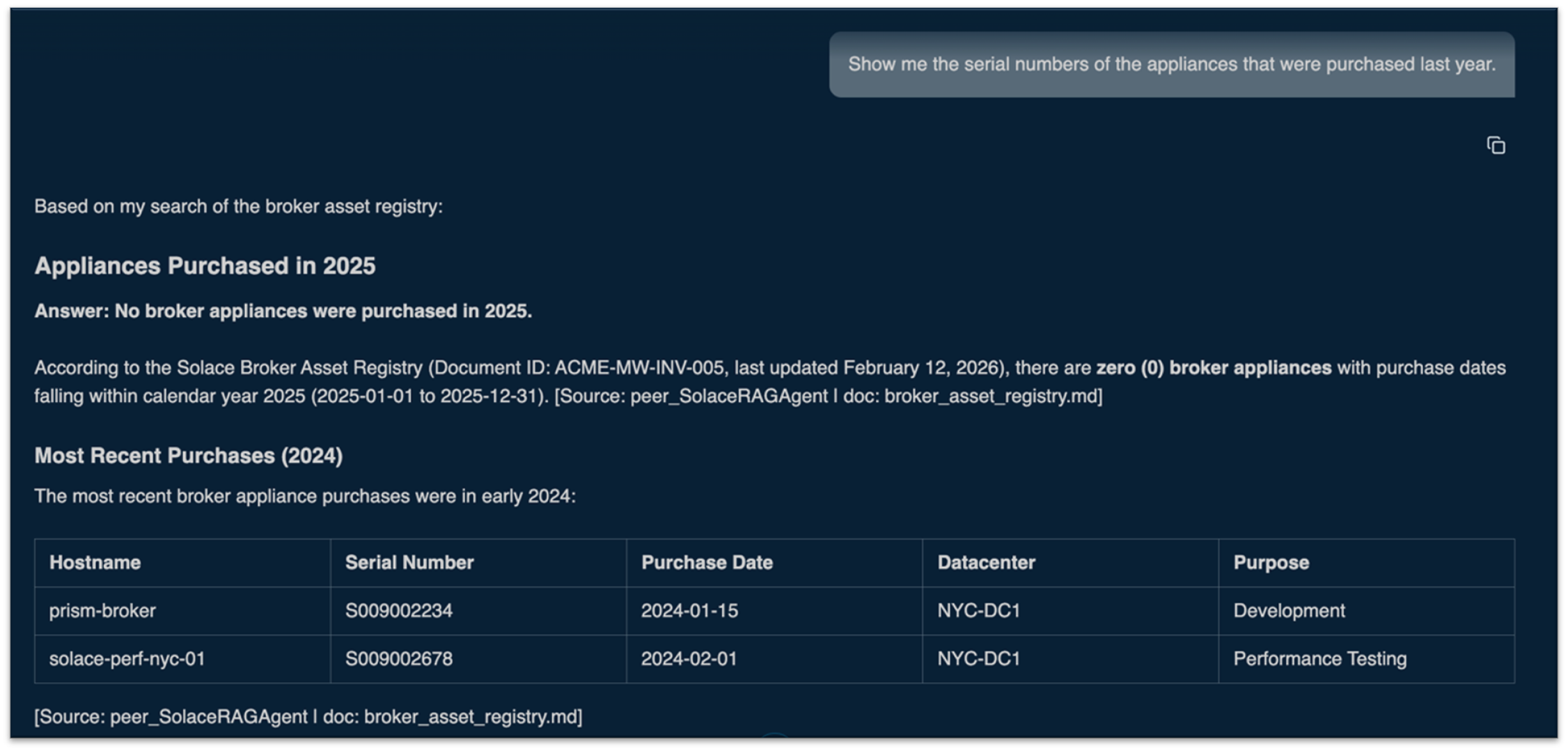
Sample response showing citations and RAG for leveraging institutional knowledge
- RAG and institutional knowledge. Every organization has knowledge locked in wiki pages and internal runbooks scattered across different systems. The solution ingests this institutional knowledge from multiple sources and makes it available to the AI agents at query time. This is what separates generic AI from something that actually understands your environment — your naming conventions, your custom configurations, your known issues, your escalation processes, and your SLAs across different environments.
- Citations. AI agents can and do hallucinate, which makes traceability non-negotiable. Every response from the Issue Analyzer includes citations pointing back to the specific documents, metrics, and configuration data that informed the analysis. Engineers don’t have to take the AI’s word for it. They can follow the reasoning, validate the sources, and build genuine trust in the outputs over time.

Dashboard with Real-time Evals and Feedback on what’s lacking in each response.
- Continuous evaluation. Every AI response is automatically scored across multiple criteria: technical accuracy, completeness, relevance, clarity, and actionability. Prompts are categorized — greeting, informational, technical, analytical — and different scoring weights apply accordingly. This gives teams real visibility into how the system is performing and provides the data needed for continuous improvement, rather than relying on gut feel.
- Observability. Because the solution is built on Solace Agent Mesh, the underlying agent communication is event-driven and fully observable. You can see what agents are doing, trace how decisions are made, and monitor the system like any other production application.
See it in Action

Built to Fit Your Environment
No two Solace deployments look the same. The monitoring tools, the ticketing systems, the internal runbooks, the team structure — these vary significantly across organizations. This solution is designed to be customizable. Solace’s forward-deployed engineers work directly with customers to tailor the solution to their specific environment and requirements, integrating with the tools already in use, ingesting the institutional knowledge that matters most, and configuring agents to match how the team actually operates. The goal is demonstrable ROI early — not a six-month implementation before anyone sees value.
It’s All About The ROI
Most AI initiatives struggle with adoption because they solve problems that aren’t painful enough, or they require too much behavior change before delivering any value. AI Ops is different. The problems it targets — slow MTTR, repetitive BAU tasks, manual health checks — are real, well-understood, and easy to measure. That means ROI is trackable from day one. And beyond the efficiency gains, there’s an opportunity cost benefit that compounds over time: every hour an experienced middleware engineer isn’t writing up a ticket response or compiling a capacity report is an hour they can spend on work that actually requires their expertise.
We’ve had strong early interest from customers, and the feedback has been consistent: the depth of the analysis, the quality of the institutional knowledge integration, and the ticketing automation in particular have resonated with ops teams who have been waiting for something like this.
If you’re managing a large Solace deployment and want to see this in action, I’d be happy to walk you through a demo. Reach out — we’re actively working with customers to deploy this and would love to show you what’s possible.
Explore other posts from categories: Artificial Intelligence | DevOps



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.