
Topic Hierarchy and Topic Architecture Best Practices
Read More
Over the last few years Apache Kafka has taken the world of analytics by storm, because it’s very good at its intended purpose of aggregating massive amounts of log data and streaming it to analytics engines and big data repositories. This popularity has led many developers to also use Kafka for operational use cases which have very different characteristics, and for which other tools are better suited.
This is the second in a series of four blog posts in which I’ll explain the ways in which an advanced event broker, specifically Solace PubSub+ Event Broker, is better for use cases that involve the systems that run your business. The first was about the need for both filtering and in-order delivery. My goal is not to dissuade you from using Kafka for the analytics uses cases it was designed for, but to help you understand the ways in which PubSub+ is a better fit for operational use cases that require the flexible, robust and secure distribution of events across cloud, on-premises and IoT environments.
Kafka is unable to perform flexible or fine-grained event filtering due to its simple event routing & event storage per partition architecture. In many use cases, this results in the need for applications themselves to filter events (which is often not practical, leads to scalability challenges, and may not be allowed by security policies) or requires separate data filtering applications to be developed – a pattern that recommends event filtering onto new topics, which isn’t agile and decreases scalability of the Kafka cluster by increasing load on the cluster and increases system complexity.
Solace brokers perform event filtering on topic metadata as a continuous stream matching against subscriptions that can contain wildcards to provide a “multi-key” matching capability across published topics. Solace brokers don’t store topic state and topics don’t need to be pre-defined, so you can have massive numbers of fine-grained topics without scalability implications. This results in fine grained event filtering and access controls so applications can receive only the events they want in a very simple, secure and efficient manner and providing significant event reuse.
Here is a video explaining the differences between Solace and Kafka topics and subscriptions.
Let’s say you have a website where you process orders against products.
What if one application wants to receive all New events; another app wants Cancelled events for a given Product Category; another wants Shipped events for a given SKU or Location; another wants all events for a particular PurchaseId. You can do that naturally with Solace as you can describe the events you wish to receive within the subscription, but this is not practical with Kafka as subscriptions are insufficiently descriptive.
Below I’ll explain why and dive into detail on this example use case.
Solace topics and subscriptions provide a set of filters on a per-publisher event stream. Each event enters the event stream in published order, then is routed to consumers based on a set of matching subscriptions. The Consumer can define which events it wants to receive and receives them in the order they were originally published. I explained the importance of this in the previous blog post in this series.
By default, Solace producers connect to a single broker and publish events with descriptive metadata topics, then consumers connect to the same or a different broker and add hierarchical subscriptions, optionally with wildcards, to attract the events to them. This concept of filtering based on event description allows Solace routing and filtering, including access control lists, to be based on event content as described in the metadata.
Like Solace, the way Kakfa filters events in a publish/subscribe model is topics and subscriptions. Kafka topics are further divided into partitions, the partitions are not used to filter events but to help scale an individual topic to more than one broker and more than one thread or process in a consumer group.
Kafka is not capable of this level of detailed filtering because the topics are heavyweight stateful labels that map to file locations on the Kafka broker and as a result, additional filtering is typically performed in the consumer or in newly created filtering processes. This relationship between a Topic/Partition and a file location is fundamental to Kafka’s design and was implemented this way for scaling storage capability and for performance reasons. But this brute force design greatly reduces the intelligence and the flexibility of dynamic and descriptive subscriptions over fine-grained topics which in turn makes re-use of events in new ways very difficult.
In many cases, having more topics with descriptive content is better to allow for more flexible filtering. However, “if you’re finding yourself with many thousands of topics, it would be advisable to merge some of the fine-grained, low-throughput topics into coarser-grained topics, and thus reduce the proliferation of partitions.” (from https://www.confluent.io/blog/put-several-event-types-kafka-topic/) This might optimize broker performance, but it comes at the expense of application performance and agility.
This architectural limitation of the Kafka broker pushes the real filtering for event re-use onto the consumer SDK and application, putting additional strain on the network, consumers and brokers. Think of Kafka as able to filter an event to a consumer based on a single label: the complete topic it is published on. In contrast, Solace is able to route a single event based on the many metadata values making up the levels of a Solace topic, and these levels can be matched by a subscription either verbatim or using wildcards. With this functionality, different applications may receive the same event for very different filtering reasons – which provides great flexibility and re-use of events.
Let’s build on the example I started using in my last post and show how flexible topics and subscriptions make this system extensible as new applications are created using the existing data within the events.
In the scenario, a large online retailer generates a raw feed of product order events that carry relevant information about each order through statuses New, Reserved, Paid, and Shipped, and that data is accessible so developers can build downstream applications and services that tap into it.
The architecture looks like this:
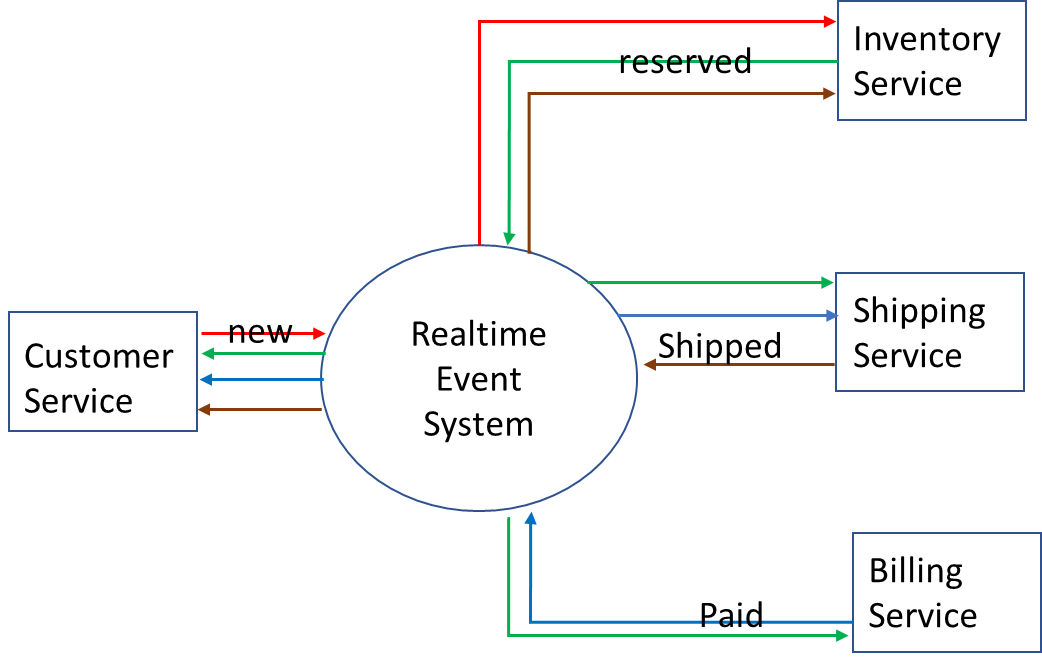
Now that this system is implemented we want to extend the data use by:
A flexible topic hierarchy will allow each of the previous applications (Inventory, Shipping, Billing) to receive exactly the events they require, but also allow new use cases to be added without change to existing producers and consumers.
Using Solace topic hierarchy best practices, a flexible topic could look like this:
ols/order/{verb}/{version}/{location}/{productId}/{customerId}/{purchaseId}
Where:
ols |
Using ols to denote online store. Including the application domain allows multiple applications to share infrastructure without fear of overlapping topics and subscriptions |
order |
each application might have different types of events, here we are talking about a purchase of an item |
{verb} |
one of [NEW|RESERVED|PAID|SHIPPED] |
{version} |
versioning to help with life cycle such as rollout of updates to events |
{location} |
region the instances of the online store covers |
{productId} |
identify the individual item being purchased |
{customerId} |
identify the individual purchaser |
{purchaseId} |
identify the specific purchase in the event |
Even with a few verbs, tens of locations, and thousands of products the total number of topics could quickly grow to the millions. Solace brokers don’t store state per-topic, so this number of topics is not a scalability concern. Solace brokers store subscriptions, which may contain wildcards, used to attract events to consumers and can handle many millions of those.
In the diagram below you can see how a detailed topic with wildcard subscriptions allows the original applications above to send and receive the events required. In location (Loc1), a customer (Cust1), purchases product (prod1) with purchase order (po1).
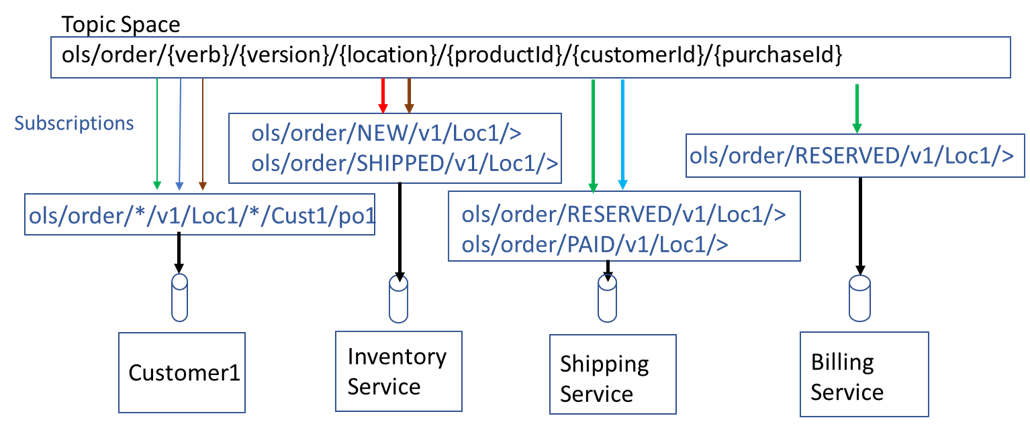
Now let’s see what happens when we add the Location service, Product service and Customer service as described above. There is no change to the producers or existing consumers. The new consumers add subscriptions that filter based on their specific needs. For example, the Location service needs all Order events specific to a location (Loc1) and receives them. The Product service needs only the events specific to a product or set of products for the specified location (Loc1) and receives them. The same is true for the Customer service, it would subscribe to receive the messages specific to an individual customer or set of customers at the specified location (Loc1).
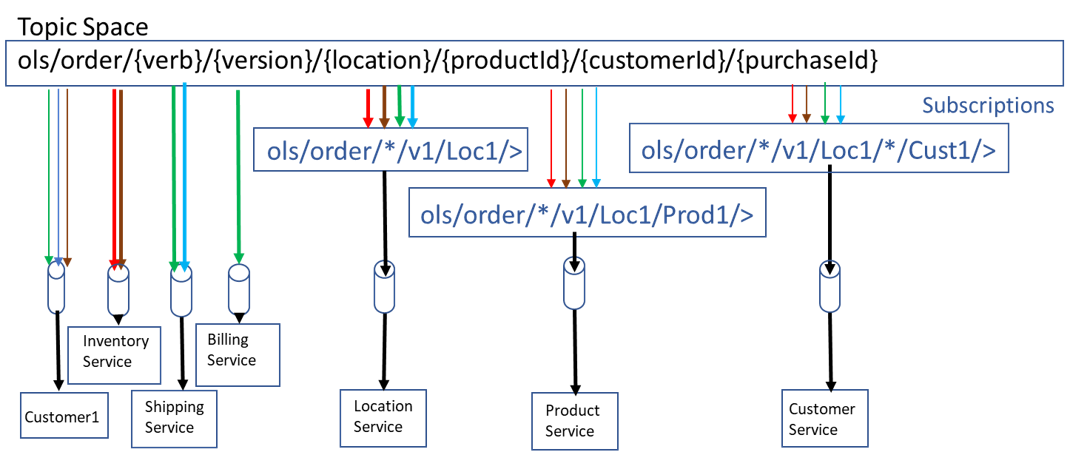
There are several important concepts shown in this picture that are worth noting.
First notice each service (Inventory, Shipping, Billing, Location, Product and Customer) has their own queueing point from which they receive events, and that multiple flexible subscriptions have been added to the individual queues. This concept of Topic Subscriptions on Queues is explained here. With subscriptions applied to a queue endpoint you get the benefits of both queueing and publish-subscribe. Each event when received by the broker is fanned out to all the queues that have matching subscriptions. This fanout provides the one to many publish-subscribe pattern. Once the message is in the queue, the full set of queueing features can be applied to the event, such as:
Apache Kafka recognizes these patterns of publish-subscribe and queuing as important, and even notes the ability to combine both as a benefit of their product. While the Kafka implementation does have publish-subscribe and message store, it lacks the true queue features listed above, which are needed to provide full queuing functionality.
Next note that the mix of detailed filtering and wildcards allow the same published event to be filtered differently by different consumers all while the entire topic space or application domain preserves published event order across all events. It is not a stretch to see why this type of flexibility is important. For example, being able to route and filter on location, range of productId, or range of consumers allow different options for scaling out the components of the system. The instances of the Inventory service could subscribe to ranges of productIds and be responsible for those products while the Billing service could be responsible for all locations using the same currency. Adding new applications to re-use existing events does not require anything other than a new subscription filtering the events as required. This simplifies the overhead of scaling out new applications. This exemplifies how re-use of events for use cases that had not been initially considered could be added without changes to any existing publisher or consumer applications and without any special filtering applications.
Finally filtering flexibility also applies when an application requests the replays of previously processed events, making this combination of features very powerful.
This exemplifies how re-use of events for use cases that had not been initially considered could be added without changes to any existing publisher or consumer applications and without any special filtering applications.
To see what this would look like in a more concrete example lets provide real values to these fields. Keep in mind the Topic Space is ols/order/[NEW|RESERVED|PAID|SHIPPED]/{version}/{location}/{productId}/{customerId}/{purchaseId}
Customer would:
ols/order/NEW/v1/NYC/091207763294/kdb123/d782fbd8-15f5-4cdc-82f2-61b4c2227c15ols/order/*/v1/NYC/*/*/kdb123/d782fbd8-15f5-4cdc-82f2-61b4c2227c15Inventory service would:
ols/order/NEW/v1/NYC/>ols/order/ SHIPPED /v1/NYC/>ols/order/RESERVED/v1/NYC/091207763294/kdb123/d782fbd8-15f5-4cdc-82f2-61b4c2227c15Finally, the flexible event filtering allows policy to be applied directly on the event mesh, for example ACLs can be written to dynamically assure a consumer can only subscribe to events related to them.
Taking the same approach as with Solace, you would be tempted to construct the same topic space used with Solace above, namely: ols/order/{verb}/{version}/{location}/{productId}/{customerId}/{purchaseId}
However, with Kafka, each topic maps to at least one partition so topics are heavy-weight constructs. Assuming some modest numbers of: 10 verbs, 1 version, 10 locations, 1,000 productIds, 1,000 customerIDs and 100,000 purchaseIds, you end up with a possible total of 1013 topics and thus at least that many partitions. Since large numbers of topics/partitions are not advisable in a Kafka cluster (see this Confluent blog post), this is far too many partitions to be considered for a Kafka cluster so this intuitive approach is not feasible.
Starting from this blog from the Confluent CTO office and reviewing the first blog post in this series, the logical topic structure might be to use NEW, RESERVED, SHIPPED, PAID as the topics with no further qualifiers and the ProductId as the key. The Inventory service would subscribe to the NEW topic as it is responsible for processing NEW events, it would emit events with RESERVED topic, Shipping subscribe to RESERVED and emit SHIPPED, etc.
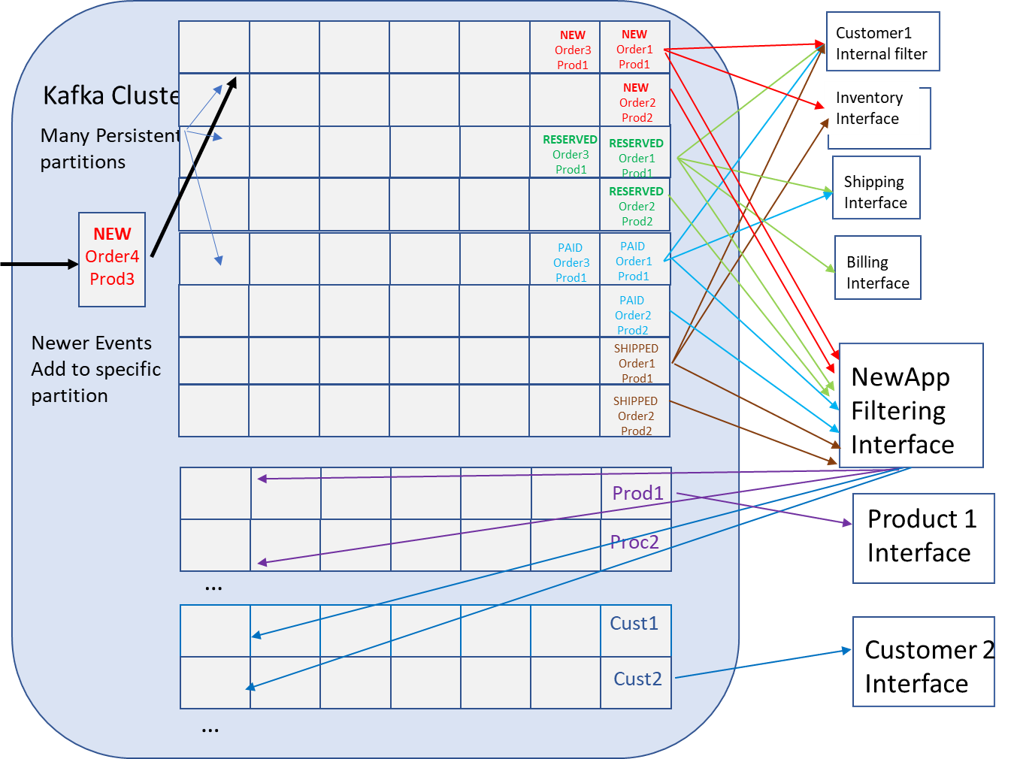
In the diagram below, each row of events is a topic partition. For this example two partitions per topic are shown. For example, there is a Topic “NEW”, the first partition holds messages for products 1,3,5 and so on, and the second holds events for products 2,4,6 and so on. This diagram only focuses on the consumer side to demonstrate lack of subscription flexibility, but all the services would also publish events, which is not shown.
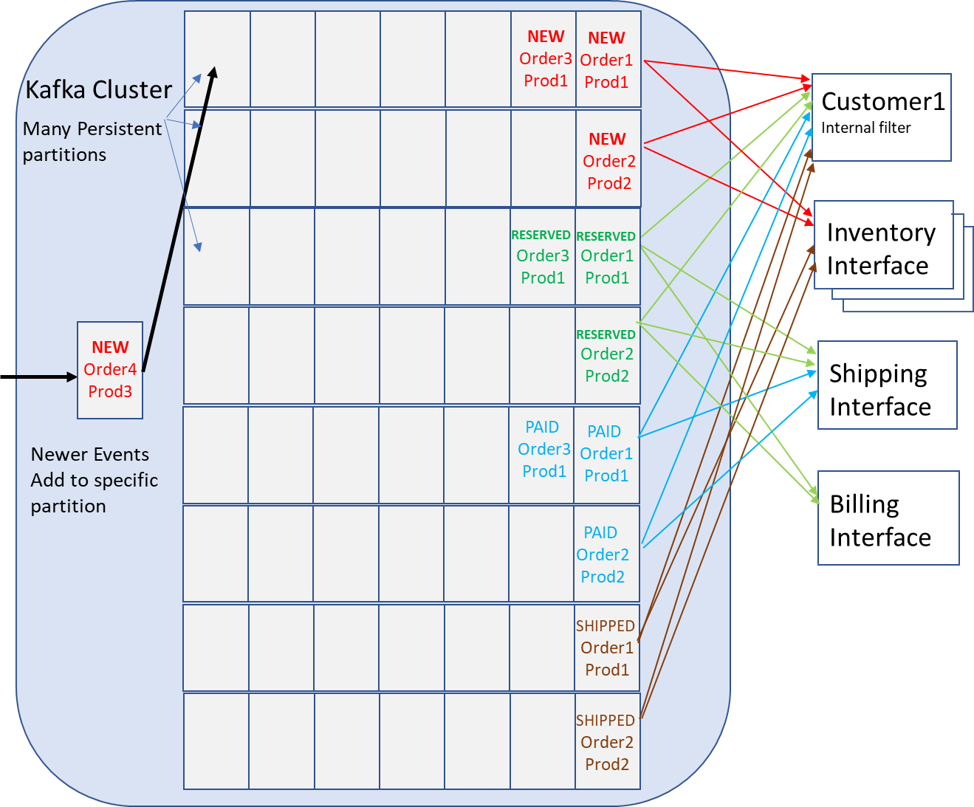
Before moving to the new use cases, there are already some areas of the concern. Notice for the customer to receive real-time event notifications on changes to just their purchase they must consume from all partitions of all topics and filter only what they need. This would mean they would have access to other customers purchases which is likely unacceptable from a privacy perspective. There is no practical way, with Kafka topics and subscriptions, to deliver the correct subset of events related to a consumer on that consumers authorized connection.
A consumer cannot tell a broker to deliver only the events that are pertaining to themselves (which is a substream of the topic) and no one else, and no practical way for the Kafka broker to enforce such a filtering rule. An agent would need to consume the events and forward the filtered events to the correct customer. I will cover this issue in greater detail in an upcoming security blog. Use of such an intermediary to pre-process and filter is a common pattern with Kafka. As discussed in a later blog this situation likely moves the requirement for authentication and authorization from the broker to the intermediary process which in turn means that process needs to be auditable secure itself. Not to mention that these types of filtering agents need to be developed, tested, deployed, etc.
Now let’s see what happens when we add the Location service, Product service and Customer service as described above.
Like the individual customer described in the previous paragraph, the new services would need to subscribe to all partitions from all topics then filter out the individual productId(s) or consumerId(s) as required. The first approach might be to simply require the new applications to subscribe to all topics and partitions containing data they require which would cause a large overhead in both network resources and application footprint as these apps deal with more data than is actually required and filter and discard in the application.
Let’s walk through the Product service from requirement to implementation. The requirement was to implement a real-time analysis for specific products. An example of the service’s use could be to understand, in real-time, the impact of flash sales of specific products. This new Product service would be required to gather all events related to certain productIds. Not only to see increased order rates, but also to evaluate failure rates and system behavior under these sales activities.
To accomplish this task the new Product service would be required to subscribe to NEW, RESERVED, PAID, and SHIPPED topics, consume messages from all partitions then discard any event that does not contain data related to the set of productIDs that it is interested in because productID is not in the topic.
The new Consumer service would follow a similar pattern.
New applications cause large connection, network, and CPU loads even with minimal actual data usage.
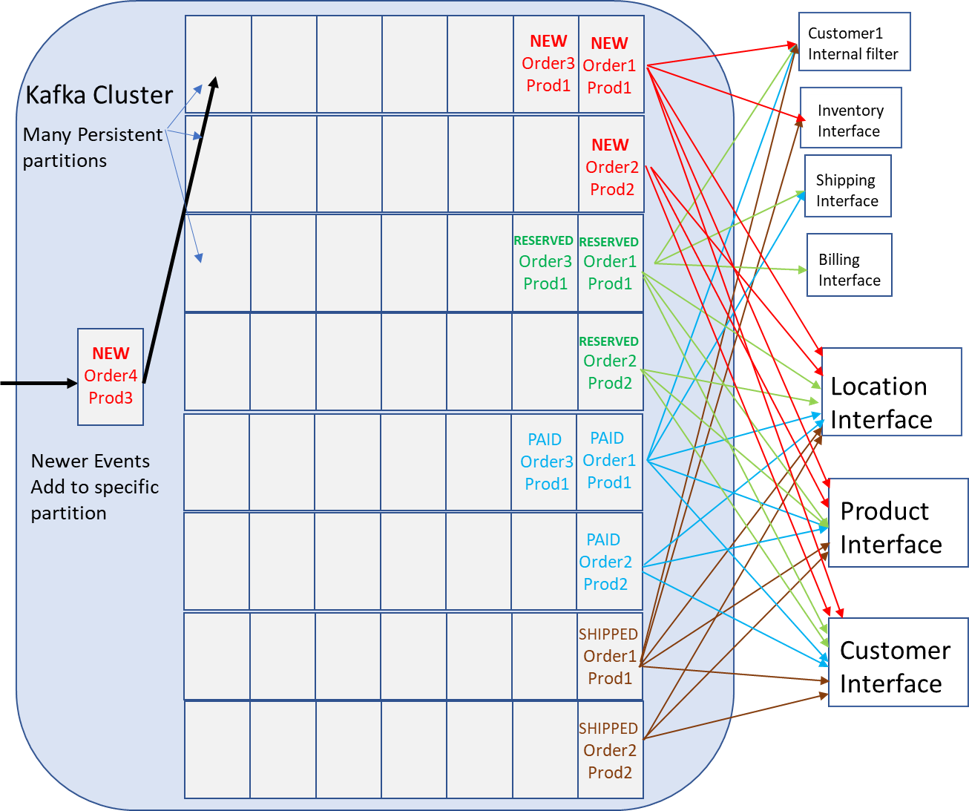
To avoid the overhead of having all applications receiving all data, the next approach would be to have an intermediary application read all data and re-publish the data needed by the downstream applications onto separate topics. This pattern is called data filtering and can be done with KSQL, for example. Here is a Confluent tutorial on how to filter and republish. This would allow existing applications to function as normal and allow new applications to be added with reduced traffic strain on the network and brokers (compared to all applications filtering) and prevents new applications from having to consume all data. But, this solution of republishing does have several issues:
Solace topics are hierarchical descriptions of the event data being distributed. This lightweight nature allows for many types of events each with there own descriptive metadata to be represented with a unique topic. In the example above there could easily be 1013 topics. This design would be consistent with Solace topic best practices as it allows the most flexible use and re-use of the events
This ability to add significant attributes into the topic allows:
Kafka topics and partitions are flat labels which describe a file location where to store the events. Because of this heavy weight file location backing the topic it cannot be as descriptive of the event and therefore not as flexible which reduces the ability to use and re-use the events. Also the Kafka subscription can only specify the simple topic label or group of labels so it lacks the ability to provide flexible filtering needed in many use cases, data filtering services are needed to do secondary filtering making the overall solution less flexible and more frail.
Why You Need to Look Beyond Kafka for Operational Use Cases, Part 3: Securing the Eventing Platform
Explore other posts from category: For Architects


Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.