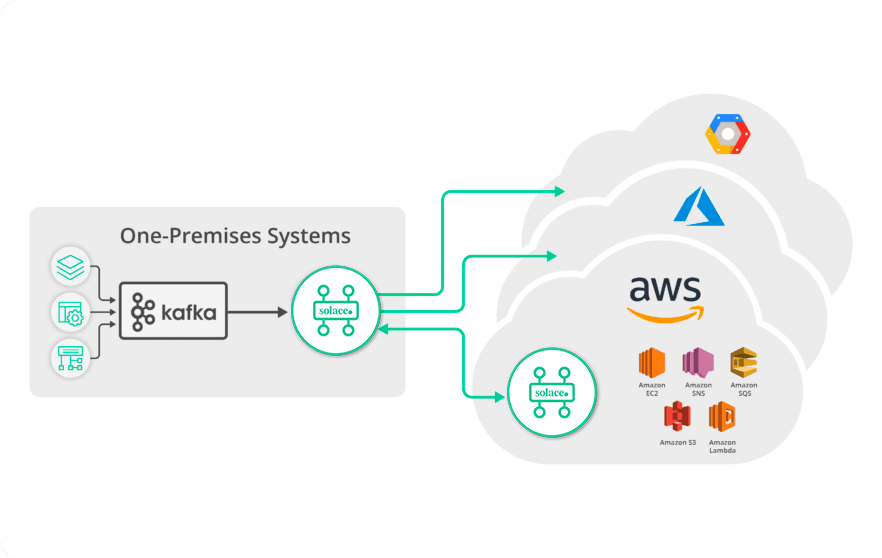
Real-Time Data Across Hybrid and Multi-Cloud Environments
Connect a Kafka event stream to a Solace event broker natively or using external connectors to route a filtered set of information to a cloud analytics engine. Solace keeps bandwidth and consumption low by using fine-grained filtering to deliver exactly and only the events required.
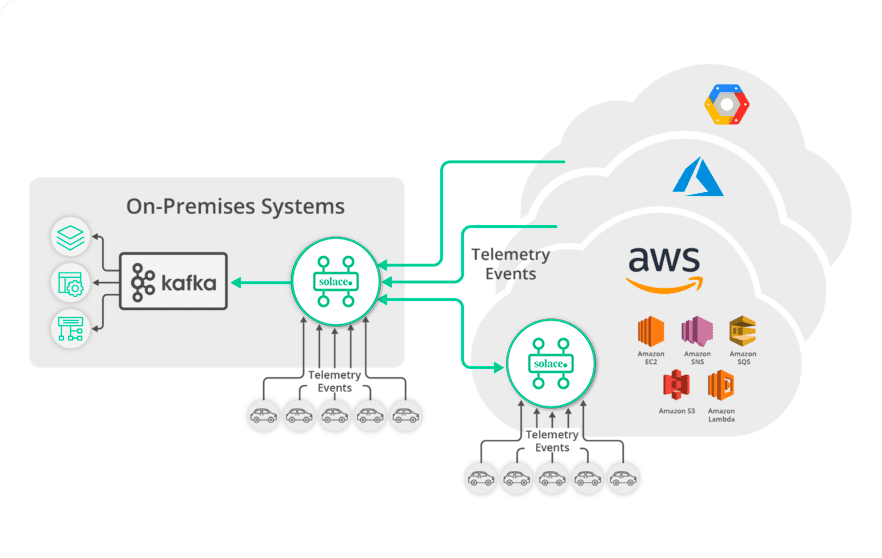
Ingest High-Volume Data From All Kinds of Apps and Devices into Kafka
Solace supports MQTT connectivity at massive scale, enabling reliable, secure and real-time communications with tens of millions of devices or vehicles so you can stream data to Kafka for aggregation or analytics. And Solace supports a variety of popular and open standard protocols and APIs, so you can stream events to Kafka from all your applications, running in all kinds of cloud and on-premises environments.
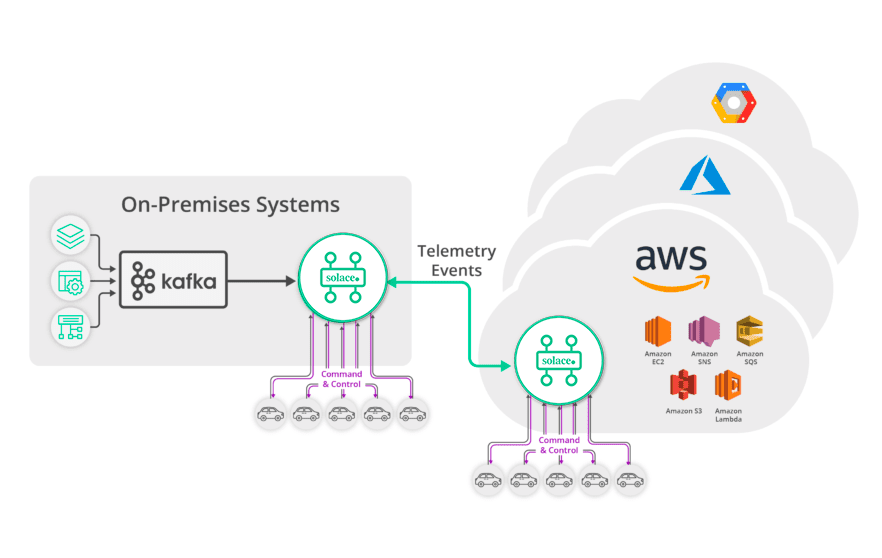
Streaming Kafka Events to Connected Devices/Vehicles
In addition to supporting the inbound aggregation of events from millions of connected devices, Solace supports bi-directional messaging and the unique addressing of millions of devices through fine-grained filtering. For example, with Solace and Kafka working together you could send a tornado warning alert to a specific vehicle, or all vehicles in or approaching the affected area.