In previous blog posts, I covered the foundational aspects of event-driven integration. I also explained how an event mesh can complement an iPaaS, and thus create more optimal and performant architectures while reducing development time and refocusing developer responsibilities. Whereas the patterns I explored before were more feature/function-oriented and sought to reduce the infrastructure logic that a developer would do in the integration layer (i.e. the iPaaS), by delegating that to the native capabilities of the event mesh, the patterns I will look at in this article, are more architectural in nature and will explore how an event mesh can be brought to bear in solving broader scoped problems.
The architectural patterns that can be realized using the event mesh can be applied to any industry vertical and in a wide variety of use cases. In the following sections, I will explore a few of these “macro-patterns” and look at the impact their applications have on solving some challenging problems.
Architectural Patterns for Event-Driven Integration
An event mesh can be extremely valuable when designing and building solutions that require:
- Event distribution at global scale
- Global reliability and availability
- Management of variable speeds and volumes i.e. handling bursty traffic
- Synchronization of data across diverse geographical environments (both cloud and on-prem)
Not addressing the challenges early in the design stage, can lead to severe problems and have significant impact to a system’s uptime and can drastically affect the bottom line. It is thus imperative that one consider technologies and approaches that can lead to a scalable and evolvable architecture from the very beginning. In the following sections, I will look at how the event mesh can help de-risk while at the same time optimizing certain use cases.
Just as a review, the event mesh is a collection of interconnected Event Brokers (potentially spanning multiple geographies) that share event routing information. Akin to an IP Network where the routers share routing tables with each other to most optimally route data packets, the Even Mesh nodes share with each subscription table so that events can be routed seamlessly to all the interested parties across a global landscape. Besides the Dynamic Event Routing capability, the event mesh is also able to “buffer” traffic to not overwhelm certain slower consumers, thereby maintaining a “steady state” flux of data.
Hybrid Environment Synchronization
In this day and age, most enterprises have a diversified technology landscape, with sometimes thousands of applications and systems living across the cloud-scape and their enterprise data centers. Most business solutions will require these applications to be connected with one another, and they require data to flow freely across the multiple environments, and across the diverse application landscape. For instance, activities occurring in a cloud application will likely need to drive an update on a mainframe database residing in the enterprise on-prem data center. There are many ways of accomplishing this with some being more efficient and scalable than others.
Let’s look at a couple of examples that illustrate how the event mesh as a pattern can help improve cross-environment data movement:
- Cross-geography event distribution
- Cloud to on-prem data synchronization
For scenario 1, let’s imagine that you have 3 different cloud regions located in separate geographies, and you want to make an event published in one environment available to the other two in real time, akin to the diagram below:
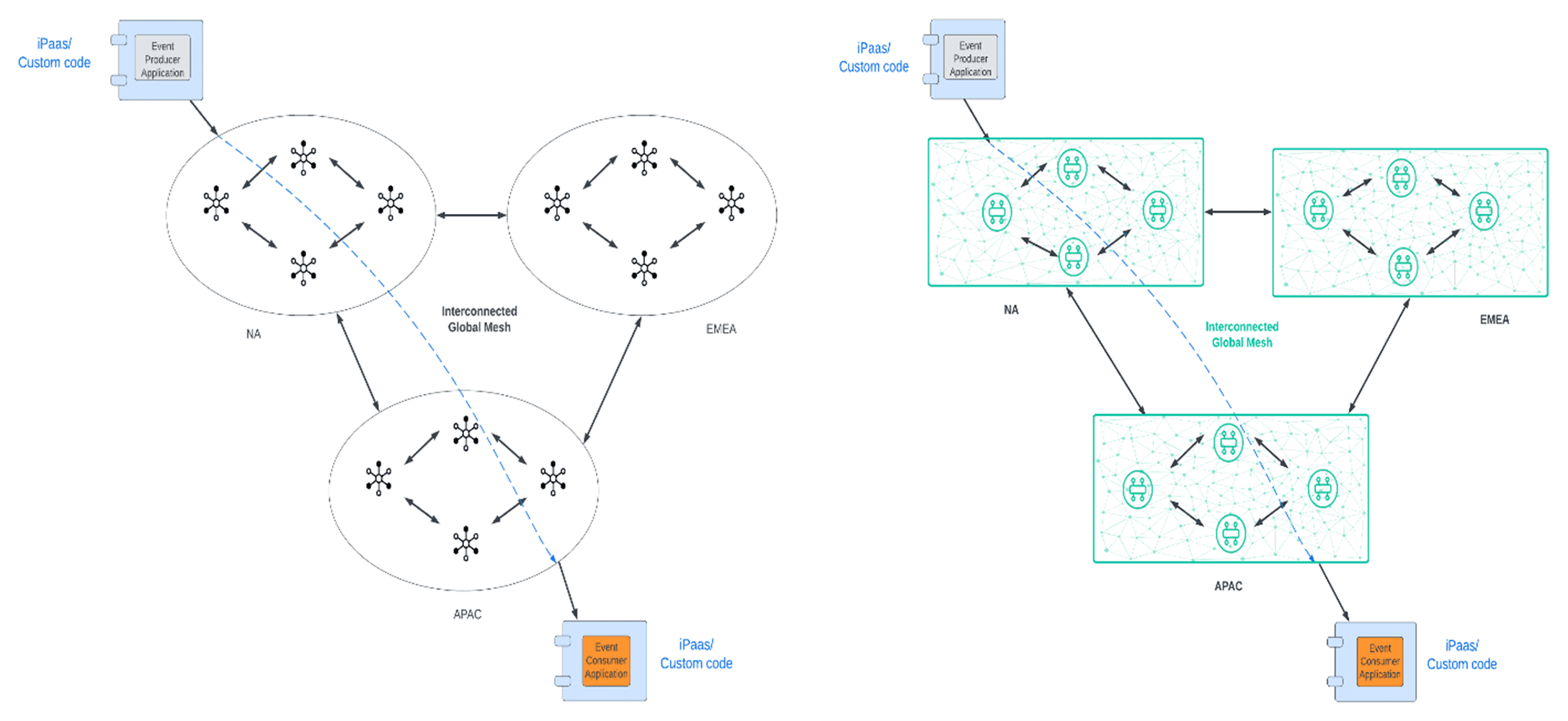
The core challenge here is that you will need to have “forwarding agents” in each environment that act as a bridge between the environments. Moreover, each environment could be using its own eventing protocol so the forwarding agent will not only have to know of the destination (topic/queue) that it will need to forward the event to, but it will also have to “speak” two protocols to be able to forward the event. So, to be able to implement this scenario in a non-event mesh way you need to implement at least 3 agents that have to incorporate:
- Protocol connectivity/bridging logic
- Routing logic
In addition, error handling and monitoring can become very difficult as each environment would have its own protocol-specific error handling and monitoring capability but there is no global monitoring capability to oversee all 3 environments unless a custom solution is built.
If you used an event mesh that is natively interconnected, then this scenario would be drastically simplified, as the subscribers would express their interest in the event published, and the event mesh would route that event implicitly to all respective destinations. There is no extra coding or capacity required, and because the event mesh is virtually one fabric, monitoring and handling covers the entire scope of the event mesh.
For scenario 2, let’s imagine you need to synchronize data that changed in an OS390 system (mainframe) with SalesForce and a database (i.e. MySQL) in AWS. The typical way of doing this would be to set up an integration process that would connect to the mainframe via IBM MQ. When the record change would occur the change would be published to MQ, to which the integration process would be subscribing to. It would then invoke a REST API to update data in SalesForce and it would connect via AWS SQS to an integration component in AWS that would then insert the new change in the AWS database.
With this implementation you have two integration components (one on-prem and one in AWS), you have to bridge MQ to SQS, and you have to call out a REST API.
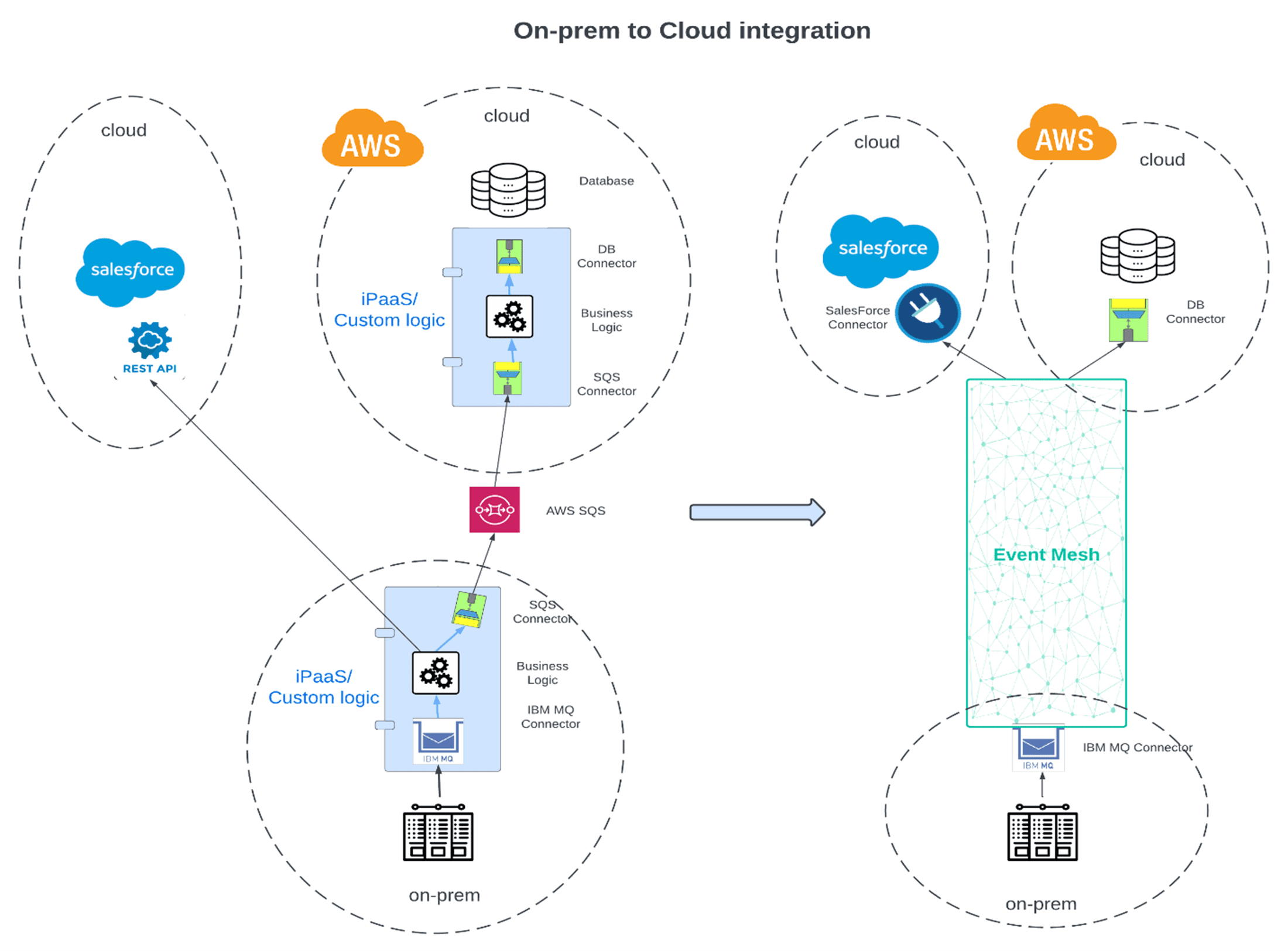
In short, more moving parts, which can make the solution more brittle, error-prone and less stable.
If you use an event mesh, you could use the IBM MQ connector bridged directly to the event mesh (no integration required) on the publishing end, and on the subscribing end you could use the SalesForce and database connectors bridged to the event mesh to up-sert the record directly into the AWS database and SalesForce respectively.
So, although cross-environment synchronization solutions can certainly be built without an event mesh, they will typically be more inflexible and will require additional development time and capacity. The event mesh greatly simplifies both scenarios.
Fast Data for Slow Consumers
Another common scenario that is typically very difficult to realize without an event mesh is connecting an environment that thrives on fast data with one that can absorb lower volumes at lower speeds. What makes this scenario possible is the event mesh’s shock absorption capabilities, which is designed to ensure a consistent traffic flow, by slowing it down when needed to a level that a consumer can ingest events at.
Two examples of where this can come into play are:
- IoT to the Enterprise (i.e. OT to IT)
- Banking and Capital markets.
In the IoT example, the high volumes of IoT Events are often too much to absorb by the core enterprise systems, however that data still needs to get there somehow. It is often the case that edge processes “summarize” the IoT event streams to reduce the volume and make them ingestible by core enterprise systems. This adds extra logic and it may result in inaccurate data making its way into the enterprise systems. Having an IoT event mesh connected to an enterprise event mesh will ensure that all events are delivered in order without the addition of any new software, and the “slowed down” event stream can be ingested by any enterprise system at their respective consumption rates. The diagram below illustrates this:
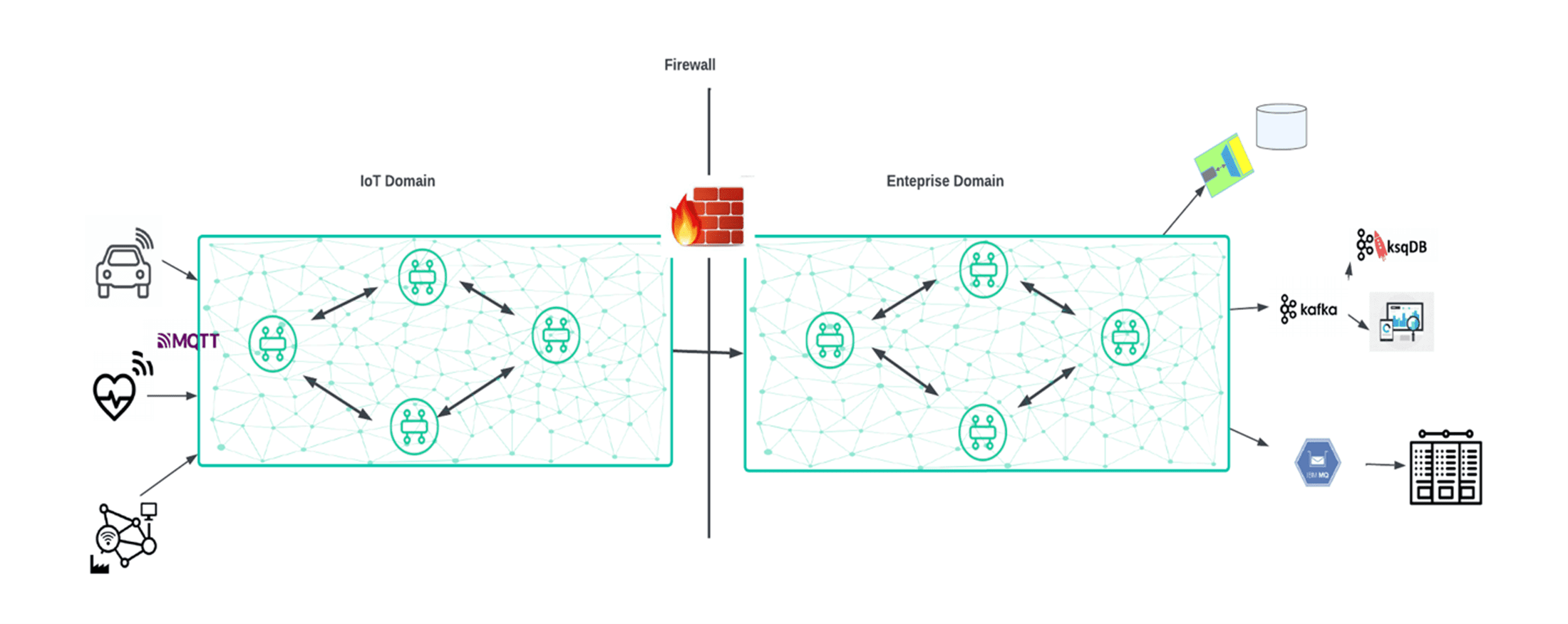
In the banking scenario, capital markets are typically a separate environment from the core banking systems, due to the simple fact that capital market data is super-fast, whereas core banking systems are limited in the amount of data they can ingest in real-time. Much like in the IoT use case, if you have a capital markets event mesh, connected to a core banking system via an event mesh, then you can essentially enable core banking systems to have access to real-time data and make more appropriate decisions. For instance, a wealth and asset management (WAM) division would greatly benefit from obtaining live insight on a client’s equity investments, as gleaning the state of affairs more readily, could result in better advice being given to the client, especially if the WAM is able to emit real-time notifications to their client with appropriate decision making content and context.
In summary, the event mesh’s shock absorption capabilities can now lead to the easy implementation of use cases that were previously very difficult to implement.
Data Distribution
A very common use case is the real-time distribution of data changes (often referred to Change Data Capture – CDC), to a large “audience” of applications and systems that are potentially globally distributed. Enterprise-wide data change dissemination is quite easily achievable via traditional integration platforms that have connectors supporting CDC, and (depending on the number of downstream systems) mechanisms to distribute the data either via scatter gatherer mechanism or by leveraging an event platform. This however is not so easy when the downstream consumers of that data are in potentially different geographies, different clouds, different environments, and there are a very large number of them (i.e. thousands or tens of thousands)!
Let’s consider a use case. A large CPG enterprise needs to change the price of one of its products, and that change needs to be propagated to its over 2500 global stores, which are in multiple countries, on multiple continents and time zones. Each of the 2500 stores needs to update the regional pricing model, apply the necessary discounts, and account for potential currency conversions. Using a traditional integration model there would be three options:
- The CDC Integration component detecting the price change would have to call out to a subset of APIs (at the geography level) which in turn could call out to the many sub-geography APIs that would represent the various stores.
- Alternatively, if each region has its own pricing catalog, the CDC integration component could update those repositories, and respective regional CDC integration components would pick up the change and invoke the local geography store APIs.
- An additional option would be much like in the previous section, where you are using a set of local eventing platforms with forwarding agents routing the change data/event between platforms.
The challenges with these options are as follows:
- Scatter Gatherers, although parallelizing calls, still await the completion of all the parallel threads before exiting the process. In a situation where the number of downstream systems is very large, the initiating process can time out.
- The approach of updating regional product catalogs is a better option than the first one as it reduces the number of downstream calls from the calling API. It does however increase complexity as you now have to have multiple CDC integration processes (one for each regional product catalog) in addition to the original CDC process.
- Using an Eventing platform to disseminate data changes is the best option in terms of scalability, however when dealing with multiple eventing platforms across different environments and geographies, you can run into challenges with the forwarding agents, and potentially different protocols for different environments; so, protocol bridging can add another level of complexity.
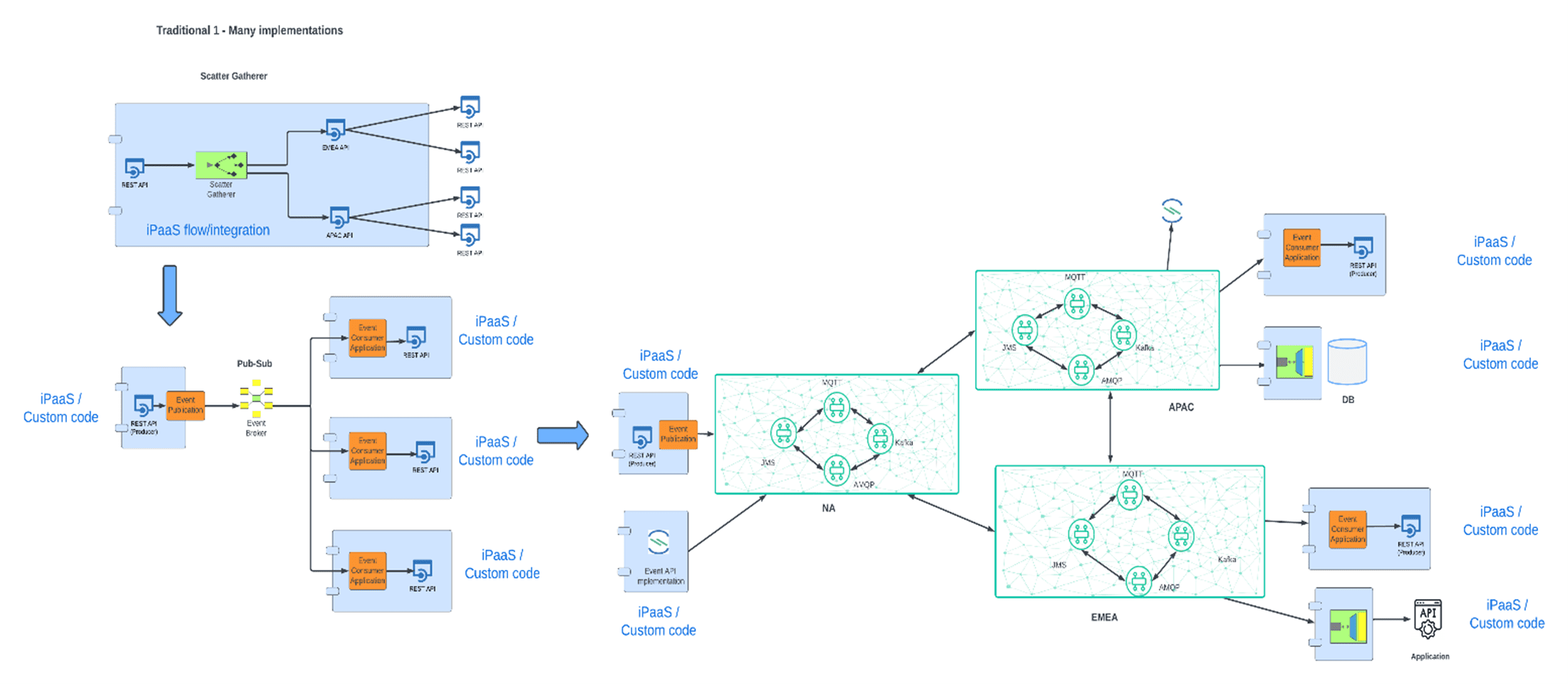
Taking an event mesh-based approach however simplifies matters. The event mesh creates a global fabric where events are dynamically routed to where the interested subscribers are irrespective of geography. The event mesh’s smart topics, guaranteed delivery and shock absorption capabilities can ensure that the events get to their respective destinations unhindered. In addition, the consumers of the changed data events, can use any type of integration platform or custom code to handle the incoming events and apply the necessary logic to handle that price change according to local rules and laws.
The event mesh-based approach allows great flexibility and agility and can accommodate any scenario that requires the update of any number of systems in real-time.
Data Aggregation
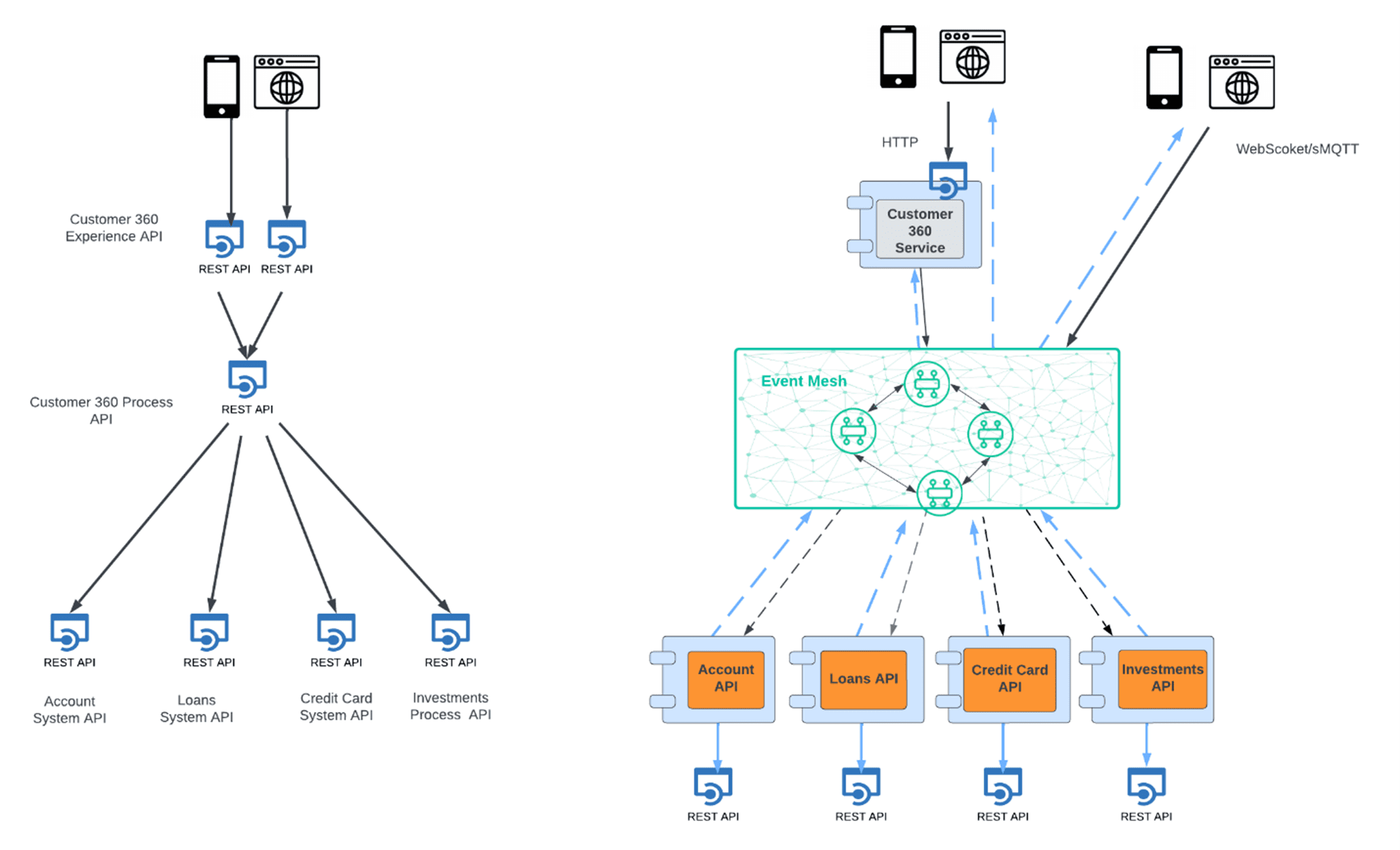
Customer 360 is one of the most common use cases out there, and it is applicable to pretty much any industry. In a pure REST-full implementation, the typical way to do this is via an orchestration of multiple API calls and aggregate the responses.
The problem with this approach is twofold:
- The more points you need to orchestrate over, the higher the risk of failure and timeout
- The further apart these APIs are (i.e. disparate geographies) the higher the risk of increasing latency, and again, the higher the risk of a time out.
Additionally, to mitigate the risk of increased latency, often enterprises duplicate API instances in different geographies, which although may reduce local latency will increase the global capacity requirements and increase management costs.
For situations where APIs are geographically distributed, using an event mesh in the middle could alleviate many problems. If you stick with the notion that a request for all-encompassing customer data is done via REST-full API, then the implementation of that API could result in the publication of a “data request event” to the event mesh, rather than doing the traditional orchestration. All customer data subscriptions would receive the event, query their related data stores, and respond with the respective subset of data. The initiating customer 360 API receives all the responses, aggregates them and returns the complete payload to the requesting client. In some ways, this approach is akin to performing map-reduce in a Big Data context. There are a couple of big benefits to this approach:
- You are essentially parallelizing the request, which makes for a faster response time
- Scaling becomes much easier as you can add additional data components without changing the structure of the overall request.
Modern UIs based on some type of JavaScript framework (REACT, Angular etc.), have built capabilities for eventing. As such, one can in fact submit a customer data request event from the UI directly via MQTT or WebSockets to the event mesh, thereby obviating the need for the REST interface. Although this approach could simplify the architecture and further improve performance, it may not be the best choice as it relegates the Experience layer APIs to the UI, thus impacting the separation of concerns principles. An optimal solution however would be one where the initial request would leverage a REST API for the initial load/request, after which all subsequent changes to the customer data set would be forward to the UI directly in an asynchronous manner. This approach would make for a much better customer experience as it combines the speed of the “map-reduce” approach, with the constant real-time update to the data in the UI driven by respective data changes.
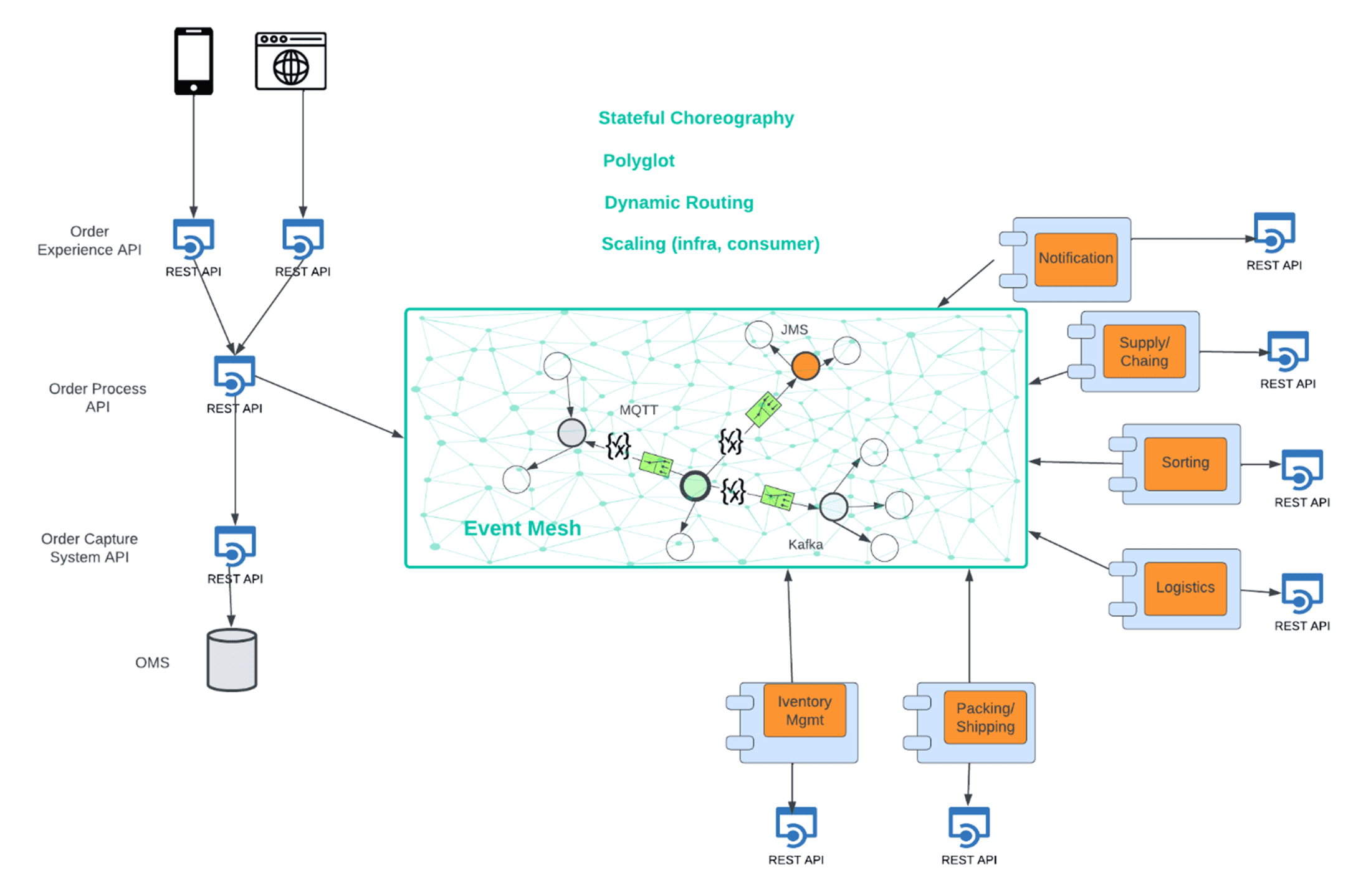
Stateful Choreography
Order fulfillment is a very common use case, and much like the previous use cases identified in this article, it is applicable across industries.
Order processing begins with the order being submitted. More often than not this is done via a REST-full API, and it usually involves two key activities:
- Enter the order in the Order Management System (OMS)
- Initiate the fulfilment process
The fulfilment process needs to be choreographed as it can take an inordinate amount of time, and it can span multiple services and systems. There is an important aspect of this process which often causes challenges: state management. Unlike orchestrations where the state of a given process is centrally controlled and thus visible, in choreographies, that is not the case. State management in choreographies is delegated to each of the services in the ensemble. This adds additional logic to every service to update the state they are at, it needs an application where the state can be stored, and APIs to extract the state on demand. As it can be seen although choreography is the best architectural pattern to materialize the order fulfilment process, it requires additional capacity, and it increases the degree of complexity of the implementation.
Some of the native capabilities of the event mesh can help alleviate the state management challenge encountered in choreographies. Smart topics have three key differentiating aspects:
- They are hierarchical in nature, thus creating topic structure that look like URLs (e.g.
/order/processed/US) - They support variables that can be inserted in any of the segments of the URL (e.g.
/order/processed/US/{city}/{store_id} - They support wildcards, that subscribers can use to identify the data set they want to receive (e.g.
/order/processed/US/Chicago/*)
You can apply these capabilities to enable state management within the event mesh itself. For instance, you can use variables to incorporate state in the very structure of the topic: /order/processed/{product_id}/{state}. Thus, if you have just received the order, you can trigger the choreography by publishing the order event to /order/processed/{product_id}/{create}. Once the service consuming the event from the “create” state finishes its work, it will publish an event to the next step in the choreography /order/processed/{product_id}/{inventory}. Thus, publication of an event changes the state of the choreography, while consuming the event virtually handles the state change/transition.
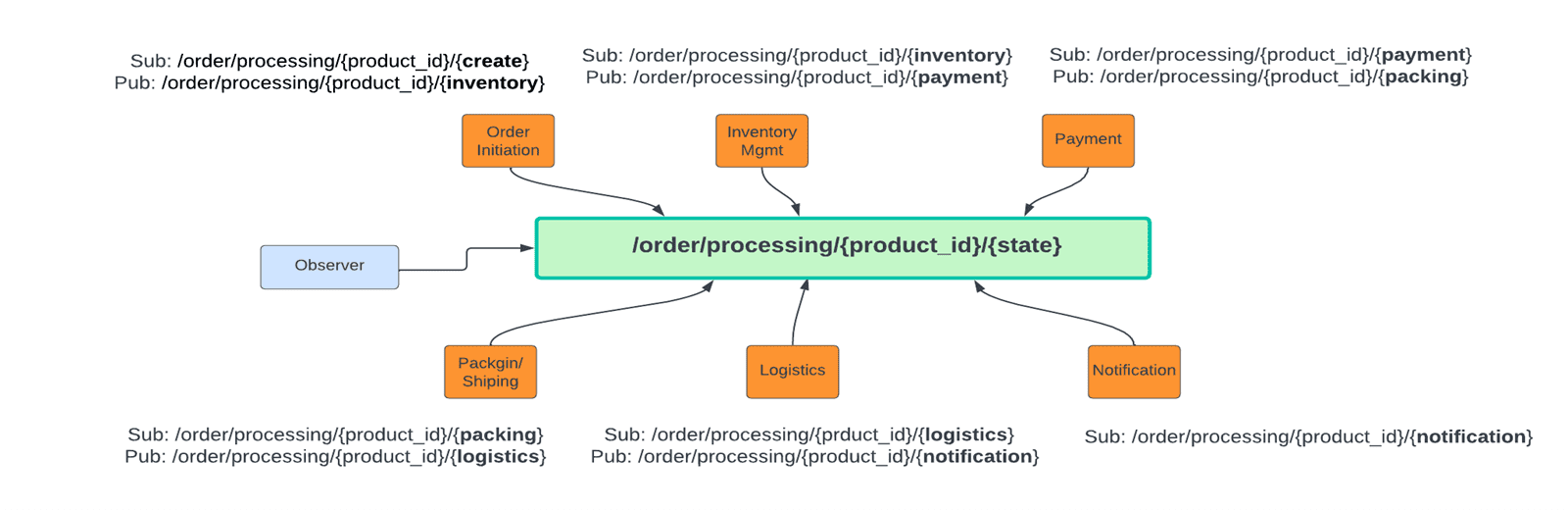
In addition, an Observer service can monitor all state transitions, and report on them, notifying interested parties of where the business transaction is in its execution.
This approach to implementing an order fulfillment process is extremely beneficial:
- It eliminates the need to write and manage state management logic
- It reduces capacity requirements (to host databases/applications to hold the state)
- It provides “observability” to the flow of a business transaction
This type of implementation can be called stateful choreography. The diagram below illustrates an event mesh-based architecture:
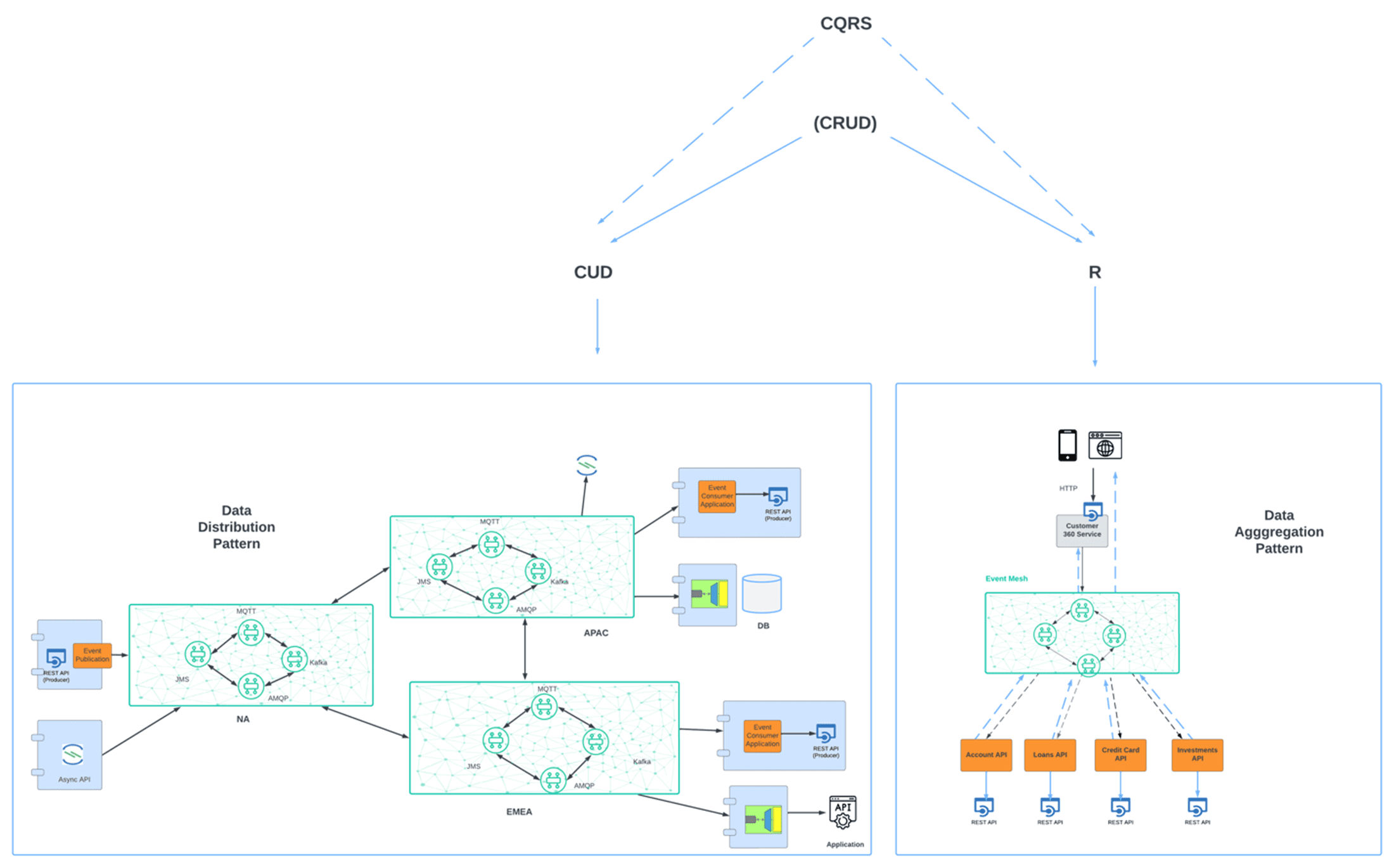
Composite Patterns (CQRS)
Command query response segregation (CQRS) is a relatively common pattern that looks at optimizing data access by separating the responsibilities of handling commands (create/update/delete) from the responsibility of querying data (read).
As querying occurs more often than modifying data, deployment architectures can allocate more capacity to the querying service than to the data modifying service; this type of separation of concerns, optimizes scalability, performance and security
Looking at CQRS through an event mesh lens, allows us to consider solutions that can leverage disparately distributed services and simplify the integration. The Data Distribution scenario previously described does in fact illustrate how the event mesh can be used to implement data modification capabilities at global scale. Similarly, the Data Aggregation solution illustrates how the event mesh can be used to perform querying at global scale.
Thus, the event mesh can be used to greatly increase the scope of a CQRS pattern due to its innate capabilities.
Topology
The last pattern that I will cover in this article does not focus on integration per se, but rather on design patterns for event mesh topologies. As the foundation for an optimal Event Driven Integration architecture, it is imperative that the event mesh be designed in a way that can address the business needs and guarantees no data loss, and consistent performance irrespective of the growth patterns of the enterprise.
There really are two core topology patterns that are most relevant, extended by a subset of variations:
- Geography based
- Domain based
The geography-based pattern is pretty intuitive in its nature, and it simply defines event mesh clusters deployed in different data centers around the world so as to accommodate seamless global traffic. The event mesh clusters are fully interconnected so as to achieve a global mesh.
The domain-based pattern, borrows from principles of Domain Driven Design, and it recommends a layered approach to the topology. Every business domain has its own respective event mesh that offers global coverage, thus all traffic related to that business domain happens over an explicitly defined “event boundary”. For inter-domain communication, there is an “event mesh Backbone” that behaves like a switchboard or a global router of event traffic, that marshals traffic along either in a peer-to-peer fashion (domain to domain) or a pub-sub fashion (one domain broadcasting to multiple domains).
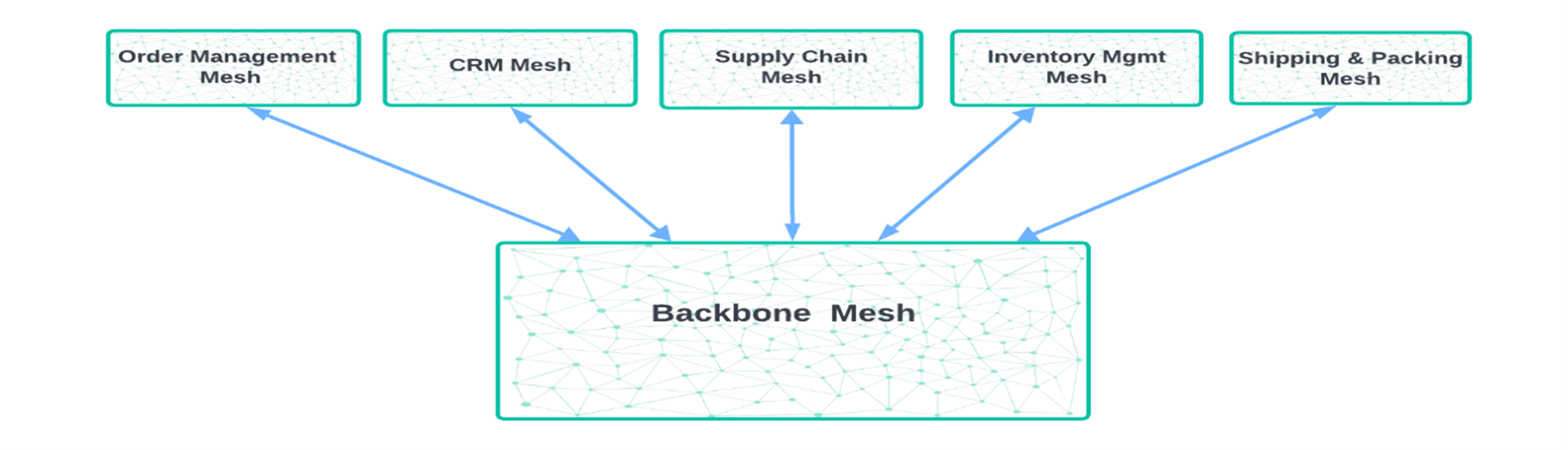
Which topology is best suited for a given enterprise is a matter of scope and purpose. Often, however, enterprises opt for a hybrid model, where the core topology is a domain-based one, but each domain has geographically distributed topology.
Summary
In this article, I explored many different approaches that can optimize the design of event-driven integrations. The key challenge addressed by these patterns is global scaling, and implicitly, optimization of distributed architectures. From synchronizing data across geographically dispersed environments, distributing or aggregating data, or optimizing long-running processes, these patterns focus on optimizing data movement at global scale. The key feature of these patterns is the maximization of the synergy between an event mesh and integration platforms.
These patterns can be implemented with any commercial integration platform (i.e. iPaaS) or custom-coded solutions. The event mesh is the key ingredient that enables these optimizations, and besides delivering global scale it also delivers on security, performance and data loss prevention. It is important to consider how a distributed architecture will scale from the very beginning of the design process, for in doing so one arrives at a more robust and evolvable architecture.
Explore other posts from categories: Event-Driven Integration | For Architects



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.