Microservice architecture is a transformative pattern for implementing complex processing that has received a lot of attention over the last couple of years. The advantage of event-driven microservices is that they can be used in combination with synchronous, RESTful API microservices to provide a flexible, scalable, and performant software architecture. A combined approach can help enterprises realize the true promise of microservices; however, to meet the demands of applications and to maximize the benefits of compute capacity, event-driven microservices must be elastically and individually scalable.
Event-driven microservices introduces an event broker and asynchronous processing into your architecture, and with it comes its own benefits and challenges with managing scalability. But the scalability challenges are not insurmountable and the benefits of event-driven microservices differ from that of synchronous microservices. In this blog post I’ll talk about scaling as it applies to event-driven microservices: the basics, the benefits, what can go wrong, and how to get it right.
What is Scaling in Microservices?
Scaling is the ability to manage compute capacity to match demand. When demand goes up, we want to increase our compute resources to match the requirements. When demand goes down, we want to decrease our compute resource to save on cost. Scaling for cost is particularly effective if the infrastructure is in the cloud because we save on resources that are de-allocated.
Auto Scaling Microservices
Scaling microservices is particularly interesting because of the of the opportunity to manage capacity at a granular, or per service level. If we have a platform hosting 100 microservices, perhaps 10 are running full throttle (high demand), 40 at zero or nominal demand, and the rest somewhere in between. We want to allocate resources where they are needed and deallocate where they are not. As hours and days pass, demand for any specific service is likely to fluctuate. Capacity should be rebalanced to reflect changing demand. But demand fluctuations depend on usage, not time. So, we need a way to detect and adjust capacity automatically for each service as demand fluctuates. This capability is called auto scaling.
Horizontal vs. Vertical Scaling in Microservices Architecture
Scalability can be achieved in two different ways, namely horizontal and vertical scaling. The difference between horizontal and vertical scaling is in how computing resources are added to your infrastructure. In a nutshell, vertical scaling involves augmenting the capacity of your servers (virtual or physical) and horizontal scaling is when you add and subtract server instances to manage capacity. Naturally, there are pros and cons to each approach.

Vertical scaling is more difficult to execute without loss of availability. Adding CPU and memory is generally a design decision, and usually requires a system re-start, even with virtual machines in a cloud environment. Also, scaling down is typically more difficult.
With horizontal scaling, there are often application complexities that must be managed, but it is generally much easier (in the right environment) to manage capacity elastically. Moreover, horizontal scaling is better suited for microservices. If each container contains a single microservice, then we can more easily scale out that microservice by replicating the container.
If you’re looking for more on the differences, advantages, and disadvantages of horizontal and vertical scaling, check out this blog post. https://www.section.io/blog/scaling-horizontally-vs-vertically/
Why is Scaling Event-Driven Microservices Important?
Event-driven microservices process events, and the number of these events over time characterizes demand. The demand at any given instant is rarely consistent for real-world systems, so events may be temporally concentrated at some intervals and sparse during others.
Some real-world examples of this include:
- Transactions in a 9 to 5 business may be concentrated during business hours
- Large numbers of events may be created at intervals as a result of batch processes
- Spikes in retail activity due to product launches and sales

In addition to regular ebbs and flows, event generation may also randomly fluctuate due to human and environmental causes outside of anyone’s control. As a result, your microservices should scale so that the capacity you’re paying for is used as efficiently as possible while maintaining the expected quality of service.
What are the Benefits of Horizontal Scalability of Event-Driven Microservices?
The benefits of scalability depend on the platform architecture and the purpose of a given microservice. Some specific benefits are discussed here.
Better Performance and Data Quality
By horizontally scaling out microservices you can improve performance by adding capacity to match spikes in demand. Event-driven microservices are characterized by asynchronous processing, which implies that event handling is decoupled from the event producer, thereby reducing the importance of timing when the event is processed. However, the reduced criticality of timing does not mean it is unimportant. Microservices process events that move, transform, enrich, and maintain data critical to operations. Events often must be processed quickly and efficiently or risk becoming stale. Maintaining scale for performance is therefore an important ingredient for data quality.
Improved Cost Efficiency
Reducing or eliminating unused capacity saves money. Compute resources aren’t free, and you want to allocate them as efficiently as possible. Reducing capacity by scaling down unused resources helps to achieve this goal. In a way, scaling for efficiency is the foil to scaling for performance. Scaling for performance implies that we want to scale out to meet demand. Scaling for cost efficiency means we want to scale down when demand is low or non-existent. Ideally, we allocate the minimum capacity necessary to meet demand without sacrificing performance. In a cloud environment, if resources aren’t allocated, you don’t pay for them. In an on-premises Kubernetes cluster, resources that you don’t allocate for one process can be allocated to another, reducing the aggregate capacity requirements for the enterprise and therefore the cost.
Healthy Event Brokers / Keeping Resource Utilization in Check
One of the benefits of an event-driven architecture is the ability to use the event broker as a buffer for spikes in demand. With event brokers, a message spool is the space events occupy prior to being processed by all consumers. However, the resources are finite. One or more lagging consumers on a topic mapped to a queue can cause messages to remain on the message spool.
But that’s a what a queue is for, right?
This is true, to a point. What if some slow consumers lack the capacity to catch up over time? If consumers lack the capacity to catch up with demand, then the message spool may grow and grow, eventually exhausting its allocation or physical limits, causing subsequent messages to reject.
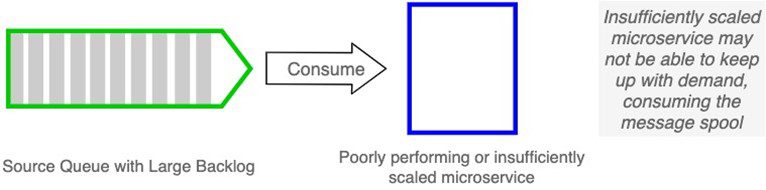
This situation may impact a single microservice or worse, the entire broker. By adding the ability to scale lagging consumers, you can improve performance, which in turn improves the ability to keep message spools nominal and the event broker healthy.
Better Performance for Streaming Brokers
Even with streaming brokers such as Kafka with very large storage capacity, there is still an issue with consumers affecting broker performance. On a streaming broker with a topic actively read by multiple consumer groups, lagging consumers may lead to performance degradation. The underlying cause is a mixed workload condition, where a lagging consumer group is effectively performing catch-up reads (but never catching up) with concurrent publish and tailing reads.
In contrast to an event broker, the message stream is a static log where messages are read by offset and are not deleted by the actions of a consumer. Under optimal conditions, consumers read from the log tail, at or near the maximum offset. When consumers read at or near the same offset, the burden on the broker is lower because data is retrieved from the file system cache, reducing the need to retrieve data from disk. When a consumer sufficiently lags more performant consumers on the same topic, then disk operations must take place to retrieve data from the lagging offset.
Consider the following diagram. Two consumers are reading from a topic: Consumer A is not performant and lags the tail (maximum offset), Consumer B is performant and reads at the tail. Consumer A is at an offset far enough behind that its data can no longer be served from the file system cache, forcing reads from the disk subsystem. This condition adds processing time to the streaming event broker, increasing latency and degrading performance.
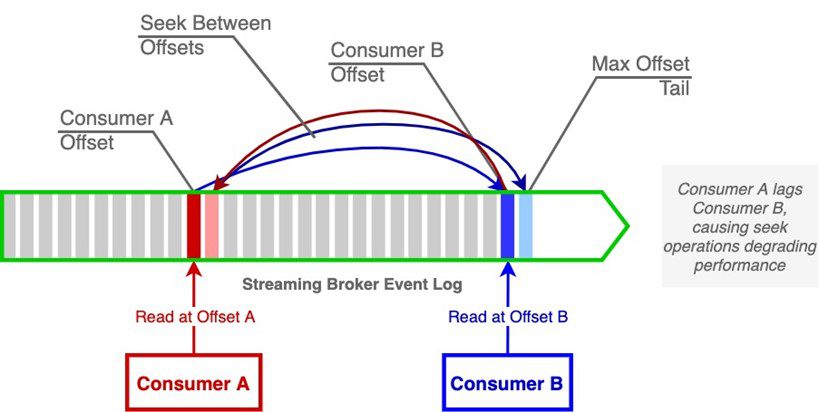
In this example, one or more consumers consistently reading at an offset behind the tail can impact broker performance. Providing sufficient capacity for consumer groups reading from a streaming broker topic, such as Kafka, can play a significant role in maintaining performance. See the following blog post for more information: Kafka Best Practices
Horizontal Scaling Event-Driven Microservices with Kubernetes
Most organizations now operate (at least in part) in Kubernetes, a framework which allows for the simple creation and removal of virtual server instances. Kubernetes provides the first thing you need for a scalable microservices framework: dynamically scalable architecture. It achieves this goal by enabling horizontal scaling.
Kubernetes also provides the tooling you need to effectuate your scaling requirements: the Horizontal Pod Autoscaler (HPA). It is a built-in sub-system designed precisely for this purpose. The HPA computes appropriate target replica counts of applications and adjusts to the desired state by creating and destroying instances. This goes a long way to solving the tooling problem but doesn’t solve it completely.
Up to this point, the path to scalability for event-driven microservices probably looks much the same as it does for RESTful microservices. But this is where it diverges. “Out of the box”, the HPA provides CPU utilization and memory as the available metrics for scaling decisions; unfortunately, these aren’t the best options for scaling event-driven microservices.
Scaling Metrics and Limitations of the Horizontal Pod Autoscaler
Kubernetes Horizontal Pod Autoscaler inherently provides the ability to scale applications based on CPU and memory utilization of workloads. CPU and memory utilization at a given time are the metrics used by HPA to compute desired number of replicas for scaling.
HPA computes the number of replicas required to achieve the user-defined target utilization, and then creates or destroys replicas to achieve that target. It does a good job of scaling using this method. But there is an implied assumption: that CPU and memory utilization track with demand. This is not always true and is more likely to be inaccurate for event-driven microservices than for synchronous microservices.
The reason is that that event-driven microservices are buffered by a broker and client software, which throttles events, thereby mitigating demand. Consequently, frequency of events from event producers (demand) does not necessarily equate to commensurate CPU and memory utilization in our event-driven microservices. At a more basic level, CPU and memory utilization are by-products of demand, not direct measurements of the demand itself. These metrics are therefore compromised as metrics for scaling event-driven microservices.
Why CPU is Not a Good Metric for Scaling Event-Driven Microservices
In this section, I detail the undesirable conditions that can arise from relying on CPU and memory utilization for horizontal scaling of event-driven microservices. These examples focus on CPU for simplicity, but also apply to the memory utilization metric as well.
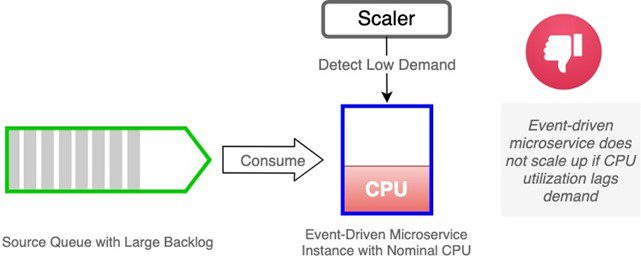
CPU Utilization lags demand
An event-driven microservice receives messages from a queue on an event broker. As the backlog of queued events increases, processing increases (assuming multiple threads are permitted) and CPU utilization increases. However, the backlog is abstracted from the consumer by the broker, preventing the consumer from being overwhelmed. If the CPU utilization does not cross the target threshold, the event-driven microservice will not scale out. In this situation, performance will be impacted due to insufficient capacity.
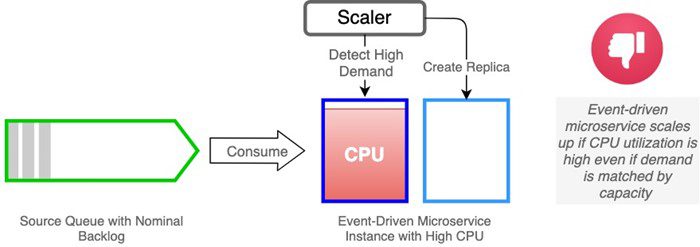
CPU Utilization outpaces demand
Replicas may run at high CPU but keep up with the demand. Do we really care if our Kubernetes pods run at or near 100% CPU utilization if they are keeping up with demand? The answer, of course, is No. It is in our interest to run our replicas at capacity to realize cost savings. But by using CPU utilization as our metric for horizontal scaling decisions, HPA will scale to maintain a nominal target level. Once that target threshold is crossed, the workload will scale out, regardless of whether capacity is sufficient with fewer replicas. The net effect is the potential to incur cost with no benefit.
Scaling to Zero Replicas
Ideally, we would have the ability to deactivate microservices that are idle for extended periods. In other words, we should be able to scale to zero replicas if there is no demand. CPU utilization is a property of an active workload instance; it cannot be measured unless there is at least one active replica. Therefore, the possibility of scaling our event-driven microservices to zero replicas is foreclosed if we track demand by CPU utilization. The cost of one idle microservice is probably negligible, but the cost of tens or hundreds of idle microservices can be significant. Our ability to manage our microservices efficiently is impaired.
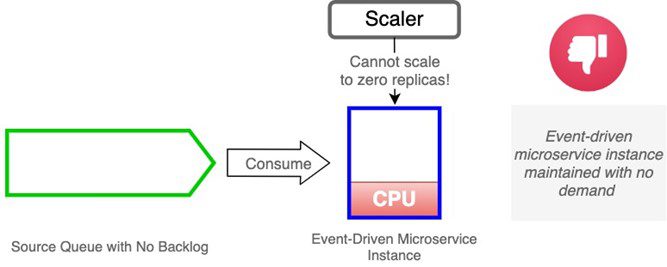
Look to the Event Broker for a Better Metric for Scaling Event-Driven Microservices
The Horizontal Pod Autoscaler may just supply the ability to scale based upon CPU and memory utilization but nothing else “out of the box,” but it also provides the ability to use any arbitrary metric through a metrics API interface.
So, if you could use a different metric for horizontally scaling your event-driven microservices, what would it be? First, look to the event broker.
Recall that in an event-driven architecture, our message broker is the buffer between producers and consumers. The broker is a resource that can provide metric values for scaling decisions. Specifically, if our microservices are receiving input from queues, then the queue backlog (message count) is an ideal metric.
The queue message count is a metric natural to the architecture that reflects the actual demand on an event-driven microservice rather than a demand by-product. As such, it is not subject to the errors in judgement associated with CPU utilization as described above. In addition, because the queue metrics are available externally to our workloads, the door is open to scale our services to zero replicas when demand is zero.
Consider the diagram below. If the scaler can poll for values such as the queue backlog, then these values can be used as scaling metrics that reflect accurate demand.
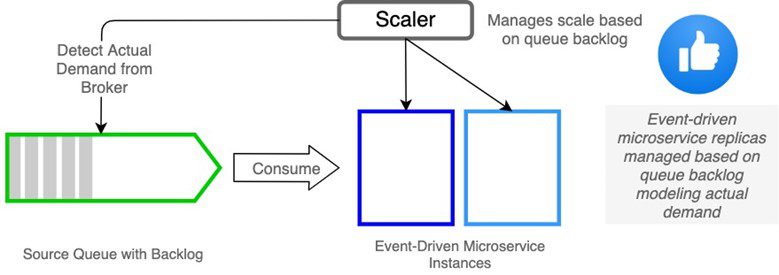
This approach eliminates the pitfalls of scaling using metrics based on demand by-products such as CPU and memory. You can therefore scale your microservices efficiently to provide cost-effective capacity that matches demand while offering the best quality of service possible and protecting the health of your brokers. Sounds terrific, right? So how do you make that happen with Kubernetes and the Horizontal Pod Autoscaler? Fortunately, there is a way.
Event-Driven Scaling with KEDA and Horizontal Pod Autoscaler
Remember the metrics API server that I mentioned earlier? The HPA can interface with a metrics API server to retrieve arbitrary metrics for scaling. In a nutshell, a metrics API server is an API that serves up scalability metrics and conforms to the requirements of HPA. If you can define a metrics API server, you can have it serve up any metrics you would like for HPA to use for scaling.
Scaling Microservices with Kubernetes Event-Driven Autoscaler (KEDA) and Solace PubSub+With the Solace Scaler, you can integrate KEDA and PubSub+ event brokers to realize the benefits of accurate event-driven scalability.
The Kubernetes Event-Driven Autoscaler (KEDA) provides the capability to utilize scaling metrics of your choosing. KEDA can interact with event sources to obtain metric values and make them available to HPA via a metrics API. KEDA is an open source, Cloud Native Computing Foundation (CNCF) project. It can be readily deployed to a Kubernetes cluster and configured for use with a variety of event-driven sources. It is important to note that KEDA does not replace HPA; rather, it augments HPA by providing the metrics API server and the framework to extract metric values from external sources such as event brokers. In other words, it works with HPA to satisfy scaling requirements of an event-driven architecture.
Conclusion
A strategy for scalability is critical for an event-driven microservices platform. Like any platform, you want it to be elastically scalable to maintain quality of service and cost-effective use of resources.
Kubernetes and the Horizontal Pod Autoscaler provide an ideal framework for elastic horizontal scaling of microservices. Event-driven architecture has key distinctions that must be understood and managed to implement your strategy successfully. These distinctions center around the use of an event broker in the architecture.
In conclusion:
- Properly scaling event-driven microservices can help protect the health of event brokers by reducing resource exhaustion and performance degradation.
- The default scaling metrics provided by Horizontal Pod Autoscaler, CPU and memory utilization, are insufficient for the needs of event driven architecture. These scaling metrics, which may not reflect real demand, can lead to under-allocated or over-allocated capacity for microservices.
- The inability to accurately scale for demand can compromise cost-effectiveness, quality of service, and health of the event brokers.
- The ability to use queue statistics as scaling metrics provides a more accurate state of demand and can improve automated scaling decisions.
- There are tools available, such as Kubernetes Event-Driven Autoscaler (KEDA) that can be used to enable event-driven scaling decisions.
For a deeper look at KEDA, including how it works and how you can use it as an effective open-source tool for scaling your event-driven microservices, check out my next blog post: Scaling Microservices with Kubernetes Event-Driven Autoscaler (KEDA) and Solace PubSub+ or start with this Solace-KEDA CodeLab.
Don’t forget to subscribe to our blog and keep up to date on other technologies and tools that can help you with your event-driven architecture.
Explore other posts from category: For Architects



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.