Introduction
Nowadays, enterprises’ digital systems are increasingly distributed across clouds, datacenters and edge environments, and made up of many purpose-specific microservices instead of a few massive monolithic applications. Event-driven architecture (EDA) is an application design model that enables asynchronous publish/subscribe communication between all of these highly distributed components.
The term “event driven” was coined by Gartner in 2017, but and in the last few years, EDA has developed into a mature technology that integrates very well with hyper-automation, multiple-experience and distributed cloud environments. Today numerous vendors such as AWS, Azure, Confluent, Google, IBM, Red Hat, SAP, Solace and VMware actively support EDA. More and more organizations, including HKJC, ANZ, Citibank, IKEA, RBC and SCB, have also started implementing EDA.
Note: the EDA Summit virtual conference has been taking place for the past three years, and their site contains over 100 videos like these for reference.
It’s important to use EDA correctly to avoid potential issues that can transform its advantages into disadvantages, slow its adoption, and disrupt your entire system. This article aims to provide a governance guideline on how to effectively build events and seamlessly pass them through different systems, ensuring the secure execution of specific business operations.
Why Do We Need Event Governance?
No matter what type of digital transformation your organization is undergoing, there is one thing all digital transformations have in common: they’re producing massive amounts of events. The event mesh helps route these events between different systems and environment.
Any real-time activity occurring within an enterprise can be classified as an “event.” These events can be initiated by user actions, systems, other preceding events in the data flow, or physical objects / things. For instance, at the Jockey Club, the physical device used by the starter at the jump (services need not be limited to code) could be associated with multiple events, such as opening the gates; close the racing pools; commence the race timer; sound the starting bell; and any other services related to the jump. Downstream services must have the ability to process these events in real-time, which can harness the power of events to create new business value.
It’s important to emphasize that events are not isolated entities. Multiple events are interconnected to execute a complete business operation, and the same event can be shared by multiple event flows. The quality of an event plays an important role in the overall design, performance, management and governance of the event-driven architecture, considering the event mesh handles tens of thousands of events in real-time every second.
Establishing a well-defined governance rule is crucial to guide architects and developers in defining, transmitting, processing, auditing, tracing, and reusing events throughout the entire event life cycle.
Event Governance
Event Identification
Identifying an event is the first critical step when discussing EDA. The quality of events you identify will greatly influence the performance and decoupling of your systems. In this section, we will focus on four key areas of event identification governance: event signature, event schema, event versioning, and event payload.
By governing these four areas of event identification, you can establish a solid foundation of event structure for your event-driven system to provide effective communication and integration between different systems.
Event Signature
The topic name is the event’s logical signature with a one-to-one mapping. The well-defined naming standard should be based on the organization’s conceptual data model, which attempts to outline high level business concepts and objects (e.g. product, account, arrangement) from the organization’s core business process and operations perspective.
Data Model
A data model is the representation of structure and relationship of data under a specific business domain. The data flows between systems are built on the definitions of the data model, while systems are the identities to process such data from end to end.
To illustrate, let us define a simple data model which can be applied to different business functions. And then, we will map the data model to the naming standard.
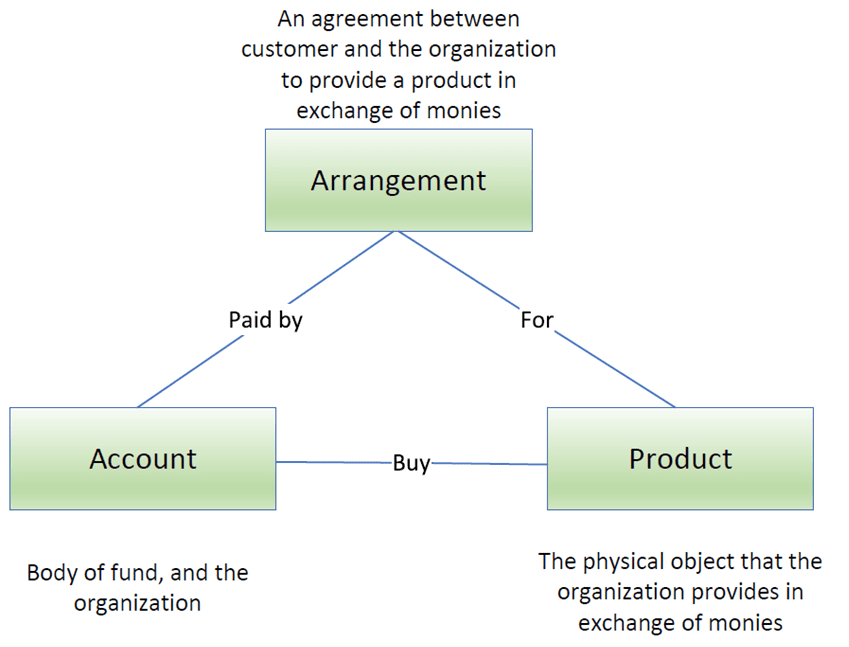
Regardless of whether your organization is providing a product or service to the customer, it must include three major entities: Account (individual customer or company), Product (physical object or service) and Arrangement (transactions involving payments). Each entity will include one or multiple subcategories. For example entity “Customer” will have an account statement and balance.
| Entity (Business Domain) | Subcategory (Business Subdomain) |
| Arrangement | Transactions (txn) etc. |
| Account | Statement, Balance, History, Status etc. |
| Product | Electronics, Clothing, Food, Service etc. |
Event Topic Names
An event is a snapshot of the Data. In the EDA paradigm, events are packaged as messages transmitted among systems via event mesh or data mesh. This means that event is a reflection of data by time.
The design of event topic names is hierarchical, and individual levels of the topic name are separated by delimiters. The consumer endpoint can subscribe to events by an exact topic name, or using wildcard filtering at a specific topic level. Formats for the delimiter and wildcard vary by event bus product (also called the event brokers) and protocols with no specific standard, so these must be carefully decided when switching between different products. Some examples per product and protocol are listed below for reference.
| Product / Protocol | Delimiter | Wildcards |
| Active MQ | Dot (“.”) | * (single-level), > (multi-level) |
| Amazon SQS | Dot (“.”) | * (single-level), ?(single character) [Only for the queue subscription] |
| Azure Queue Storage | Dash (“-“) | * (single-level), ?(single character) [Only for the queue subscription] |
| IBM MQ | Slash (“/”) | + (single-level), # (multi-level) |
| Kafka | Dot (“.”) | * (single character), ** (multi-characters) |
| MQTT | Slash (“/”) | + (single-level), # (multi-level) |
| Rabbit MQ | Dot (“.”) | * (single-level), # (multi-level) |
| Solace | Slash (“/”) | * (single-level), > (multi-level) |
| Tibco | Dot (“.”) | * (single-level), > (multi-level) |
Event Topic Naming Standard
The Topic Naming standard provides a set of guidelines that ensures the consistency and reliability of all events within the organization. It helps to promote interoperability between different systems and products, making the events easier to replicate, process, reuse and log. Form the governance perspective, event topic name design must be aligned with the naming standard.
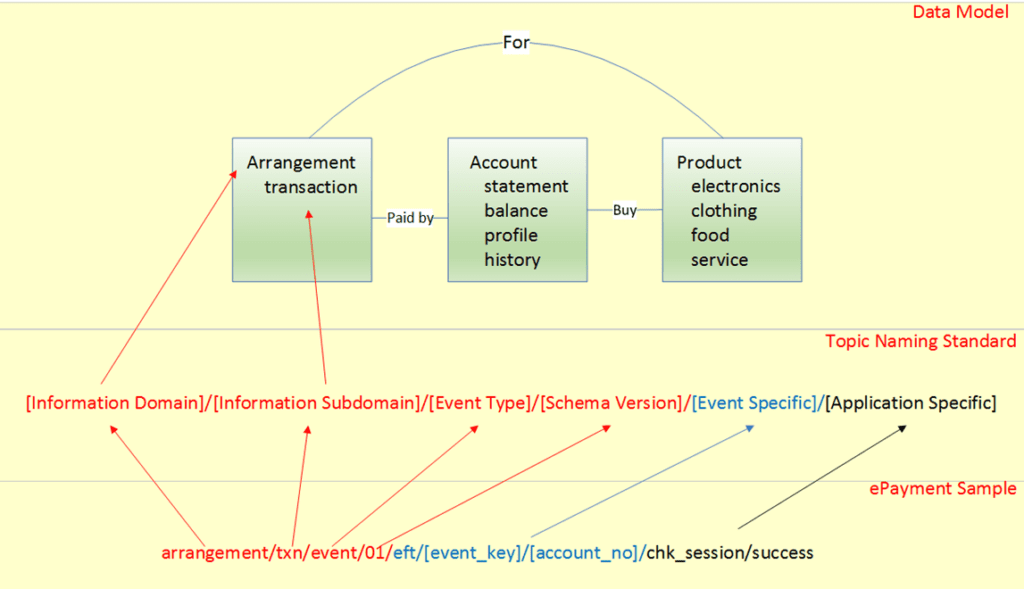
A well-defined naming standard should include two parts: a mandatory and an optional part. The mandatory part should include at least four fields: information domain, information subdomain, message type, and schema version.

The following diagram illustrates an example on the ePayment service (EFT), and demonstrates how this sample naming standard could be mapped to the data model.
Tips for Defining a Naming Standard
Most of messaging product companies provide best practices to guide users to define topic names. You can also refer to the following tips:
- Topic name hierarchical structures are developed from high-level to low-level;
- Only add necessary fields to the topic. These fields should be used for routing, or security purposes;
- Use consistent, widely understood short names or acronyms to reduce the length of topic names;
- Use lower-case for alphabetic characters rather than mix the capital letters with lower-case together;
- Use standard ASCII-range alphanumeric characters; and
- Do not use special characters except underscore (“_”).
Event Schema
In EDA, the event schema plays a critical role in ensuring consistency and data synchronization between different components. It serves as a contract between these components, defining the structure and format of events. Having a well-structured schema is important to minimize dependencies between publishers and subscribers, and to adhere to the decoupling principle in EDA design.
When transmitting events between components, they are packaged as messages. The message header contains additional information for pre-processing, such as filtering and routing, before the event is decoded. This information may include the message type, publish time, and other relevant labels.
The event itself is the payload of the message, providing detailed information in a modularized structure. This includes elements, attributes, descriptions, patterns, and other relevant components of the event.
Unlike traditional remote procedure call (RPC) and user datagram protocol (UDP) calls that often use ASCII code in their payload, EDA typically utilizes schemas tailored for event-driven systems. One popular choice for defining event schemas is AsyncAPI. AsyncAPI provides a specification and tooling for designing, documenting, and communicating event-driven APIs. You can find more information about AsyncAPI on their official website at https://www.asyncapi.com.
Event Versioning
The concept of event versioning primarily focuses on the evolution and modification of the event schema, rather than alterations to the event content itself. The event schema can be viewed as a contract agreement between the publisher and consumer. As a result, cataloging and versioning are crucial for clear ownership of events and well-documented event schemas.
It is not feasible to create a single event schema that can cater all future requirements and changes. Therefore, in on and off systems, it is necessary to upgrade the event schema during different releases. This may involve adding or removing data fields or modifying the definition of existing fields. However, it is important to note that any changes made to the schema may impact all corresponding consumers, and they will need to make corresponding adjustments to accommodate the changes. Versioning is commonly used to indicate changes in the event schema, and it is essential to establish a clear definition and control over versioning changes.
The new version of event should be convertible without any version conflicts. The new version of event can either be breaking change, backward compatible, or forward compatible.
A breaking change necessitates that all consumers make corresponding changes simultaneously. Alternatively, the publisher can trigger different versions of the event within a short period until all consumers have updated their software. However, it’s important to note that a breaking change creates a semantic coupling between different components, which conflicts with the decoupling principles of Event-driven architecture (EDA). In such cases, it may be more appropriate to consider using a new event instead of a versioning upgrade to maintain the desired decoupling.
Backward compatible and forward compatible scenarios involve minor changes to the schema, such as adding an additional attribute. For instance, consider the example of adding the ‘book size’ field to a purchase order event. While the backend system or finance system may not require this extra field, it proves valuable for calculating warehouse physical capacity on a logistic management system.
Regardless of whether it’s a breaking change or a minor change, we need to assign a new version number to the event. The version number consists of two numbers separated by a dot. The first number represents the breaking change, while the second number represents the minor change, which is backward compatible.
We will include the major version number in the topic name. This indicates that it’s a “new” event and requires all corresponding consumers to update their subscription role before they can receive it.

The full version number will be included in the message header and payload. The message header allows the consumer to validate the version number before decoding the payload.
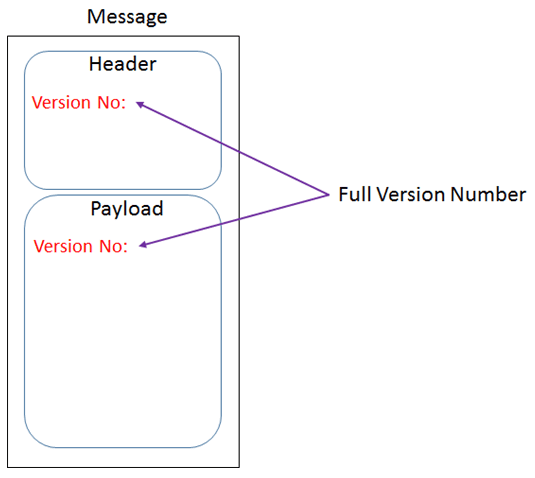
The payload is primarily used for logging and troubleshooting purposes when written to the event log and persistent storage.
Event Payload
The concept of message (multiple records) and event (single record) is often confused by many developers when they apply EDA or data-driven architecture (DDA) to their solution, and this will cause significant impact on the overall system performance. We need to provide a clear definition on the single record, cross check the event payload during the design stage, and set the maximum event size on the event broker.
The traditional Request-driven architecture (RDA) has request/reply pattern, so every message is a snapshot of a series of record regardless of whether they have been changed or not, and are processed by batch. For EDA and DDA, the event is triggered right after it just happened, and processed in real-time. So the event payload just caters to the change at that moment. This will be a single record with necessary data and the size should be very small. The publisher and consumer can use less resources and bandwidth to process the event in real-time. This will change the traditional system behaviors to provide better user experience.
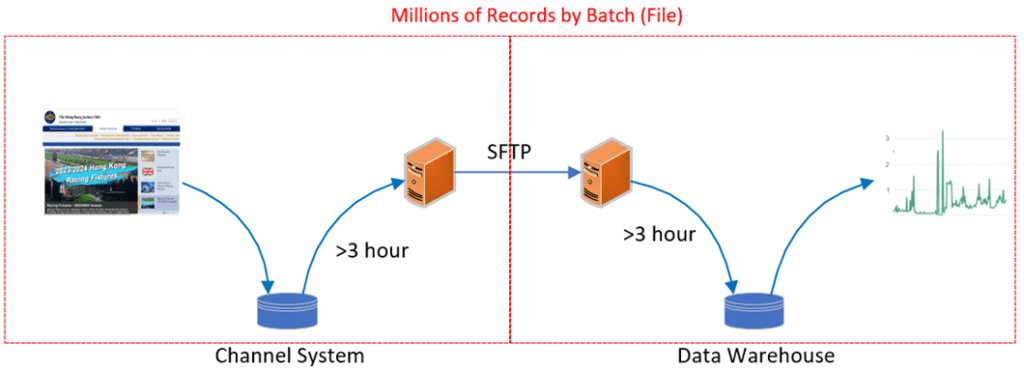
Let’s use the login static analyze as an example. The traditional solution will scan the previous day’s channel server database to collect customer login and logout time information after an end of day process, and then send it to the data warehouse for customer behaviors analysis in file format via SFTP. This file will include dozens of millions of records, and the size is always more than 5 GB. These huge rows of records’ need several hours to process even with a powerful server, and it will impact network bandwidth, database performance and other parallel processes on the same server. There is one day delay of statistical report.
Under EDA design, the login and logout event will be real-time published to the data warehouse in async mode, and stateless microservices can insert these records into the database within 1 second even if there are a hundred dozen login or login activity per second. It mitigates the limitation of batch processing, which is not easily scalable.
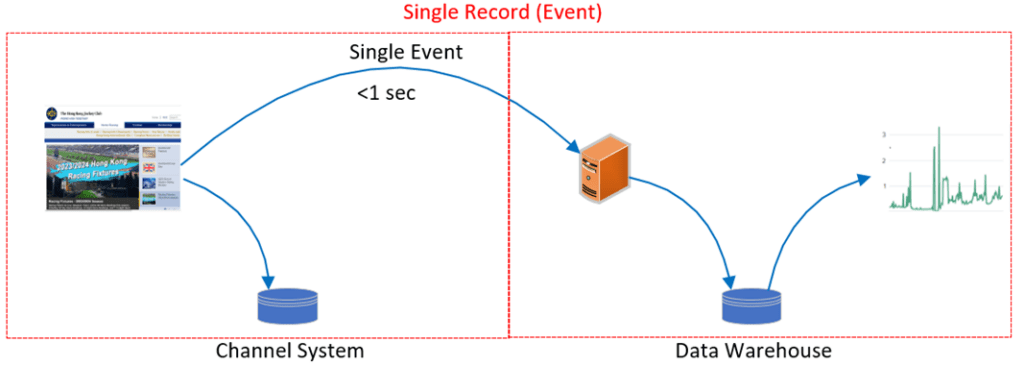
The Definition of Single Record
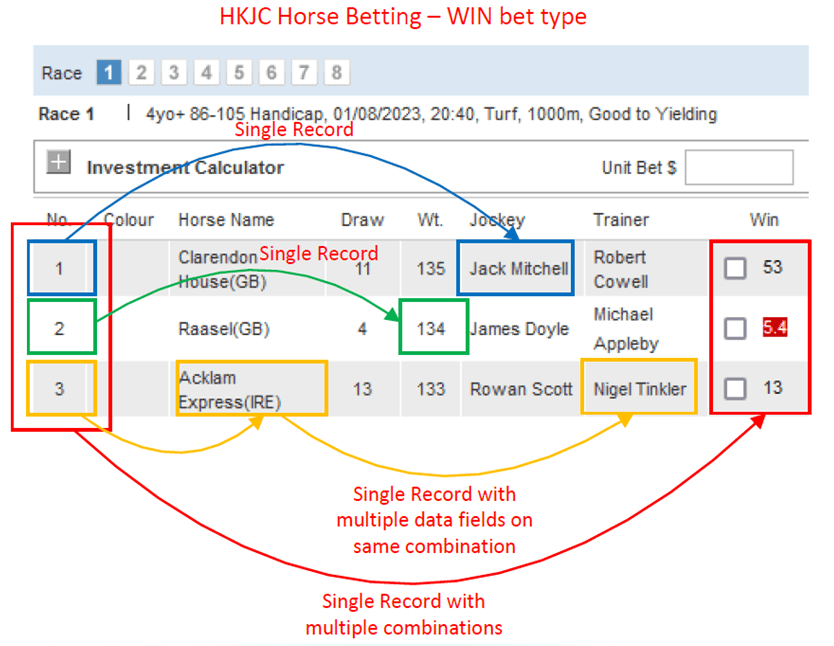
We must have a clear definition on what a single record is before we try to limit the size of an event. A single record is a set of tightly coupled data fields which are changed at the same time. It can be the phone number of a customer record, or a stock value on the exchange market.
For example, WIN is a very popular racing bet type for Club customers. One WIN bet type includes multiple combinations, and each combination will be mapped to separate Combination No, Horse Name, Jockey Name, Trainer Name and Odds value. The Combination No + Horse Name + Trainer Name or Combination No + Wt. (Weight) can be looked at as an individual event because these information’s changes are separated, and in-dependent from other records. However, the Combination No + Odds values of all combinations will be grouped as a single record because these Odds will be changed at the same moment.
Network Transmission
System performance refers to the amount of data that can be transmitted and processed per unit of time, and the size of redundant data block is fixed. A bigger message with multiple data blocks take up more bandwidth and memory, and process slowly, which reduces the overall process flow. We will now explain it from the network point of view.
Most of the event broker libraries (layer 7 application layer) are built on top of TCP/IP protocol (layer 4 transport layer). When the Publisher sends the event or the event broker pushes the event to the consumer, the TCP will break the event down to small packages, and forward it toward the Internet protocol (IP) layer. The packages are then sent to the destination in sequence through different firewalls, switches or routers. The destination must acknowledge the package before the source sends out the next one. The TCP will handle the error recovery when the package is missing, and the source will re-transmit the missing part until successful or the connection is terminated.
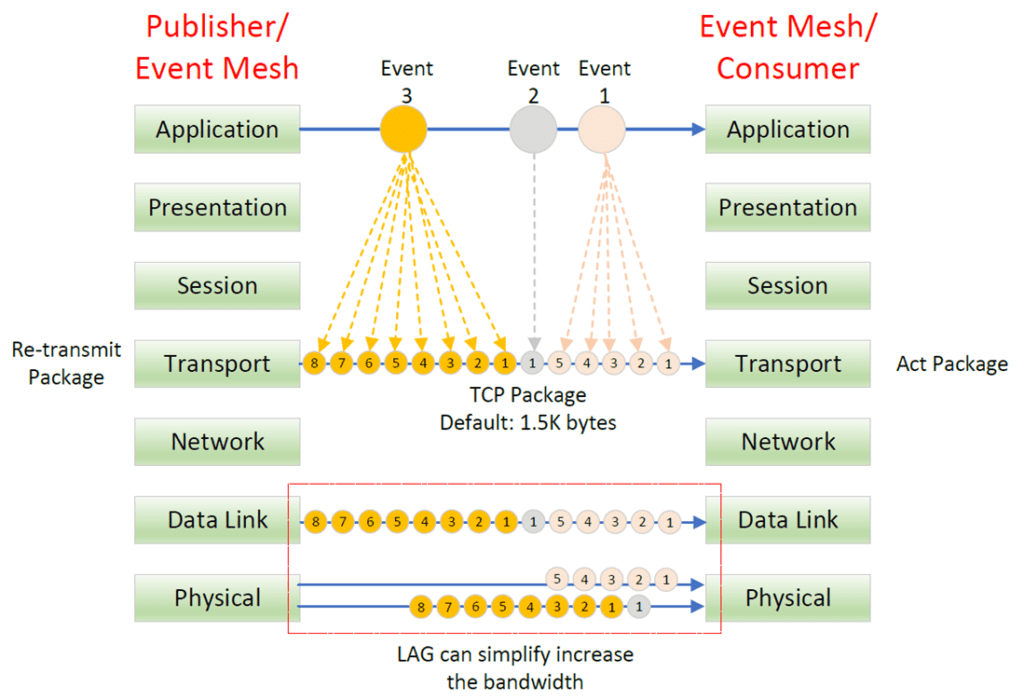
The default TCP package size is 1,500 bytes, and the first 20 bytes is the mandatory TCP header which define the source/destination port, sequence no, offset etc. The single package event will be more effective than the multiple package event because it doesn’t need to handle multiple acknowledgements and re-transmission roundtrip processes.
More and more event bus support link aggregation (LAG) which combines multiple physical data links to form a single, virtual link layer for the network transmission. This can simplify the increase of network bandwidth based on existing cable connection to provide more efficient bandwidth utilization. Referring to the diagram above, a small event can provide better utilization because only the same file can be transmitted via the same physical link.
Computing Power
Traditional three-tier architecture design requires a powerful server to handle all traffics from a single place, but the technical trend in the past few years is to move to a stateless and serverless architecture design to provide high throughput, cost-optimization, faster development, and greater solution flexibility. The system decoupling and server scaling are more important than computing power improvement.
A less powerful server has limited capability to handle the message, so we need to limit the message size with necessary data elements only.
Tips:
- The definition of single record depends on your organization’s business nature
- Event size can only be than 1KB 5% of the time, and most of event hovers around 1MB.
- Splitting a large file into smaller parts and transmitting them to the destination via an event bus has been proven to be a more effective approach compared to using SFTP (Secure File Transfer Protocol). Additionally, leveraging an event bus enables the possibility of fanning out the same file to multiple consumers simultaneously.
- The solution must provide support for both files (batch of records) and events (single record) as they serve different purposes and have distinct usage scenarios.
Event Flow Control
Once the event has been identified, the subsequent crucial step is to govern the flow of the event, ensuring that it can be transmitted effectively and reliably across various systems. This supports system decoupling and enables choreography-based flow control, enhancing the event’s effectiveness and manageability.
In traditional design, applications use a central control which may sometimes be perceived by the user as being conducive to lag in time or in performance, whereas in EDA, applications use a choreography control. With an EDA design, we do not need to know how an event will be routed, or what information will be needed by subsequent steps. The event bus can dynamically routes tens of thousands of events every second between various systems.
However, events are not akin to a scattered pile of sand, as they do not occur in isolation. For example, a business flow like a customer requesting the transfer of $100 from a bank to his/her account via FPS needs to be completed by a series of actions called event processes: validation of the login session, checking available balance, updating the database, and triggering a notification service (via SMS or e-mail). The process flow builds a relationship between different events to complete separated business operations.
To ensure effective linkage and reusability of these events, it is essential to have a clearly defined event flow guideline that guides architects and developers.
Leveraging the Naming Standard or Event Flow Guideline based on the Naming Standard
We have established the following naming standard during our previous section, and mentioned that each event must define the value referred to the mandatory part of the naming standard, and the optional parts’ values will be dependent on event behaviors. In this section, we will clarify the process of applying a naming standard to establish meaningful connections between different events within an event flow.

Events might pass through various systems during its lifetime where it could mean different things to different systems or applications, but the topic that represents the event message must remain constant. From a topic naming perspective, the event’s data component values (the mandatory part, and event specific of optional part) should be solely based on the definition of the original purpose of where the event originated from.
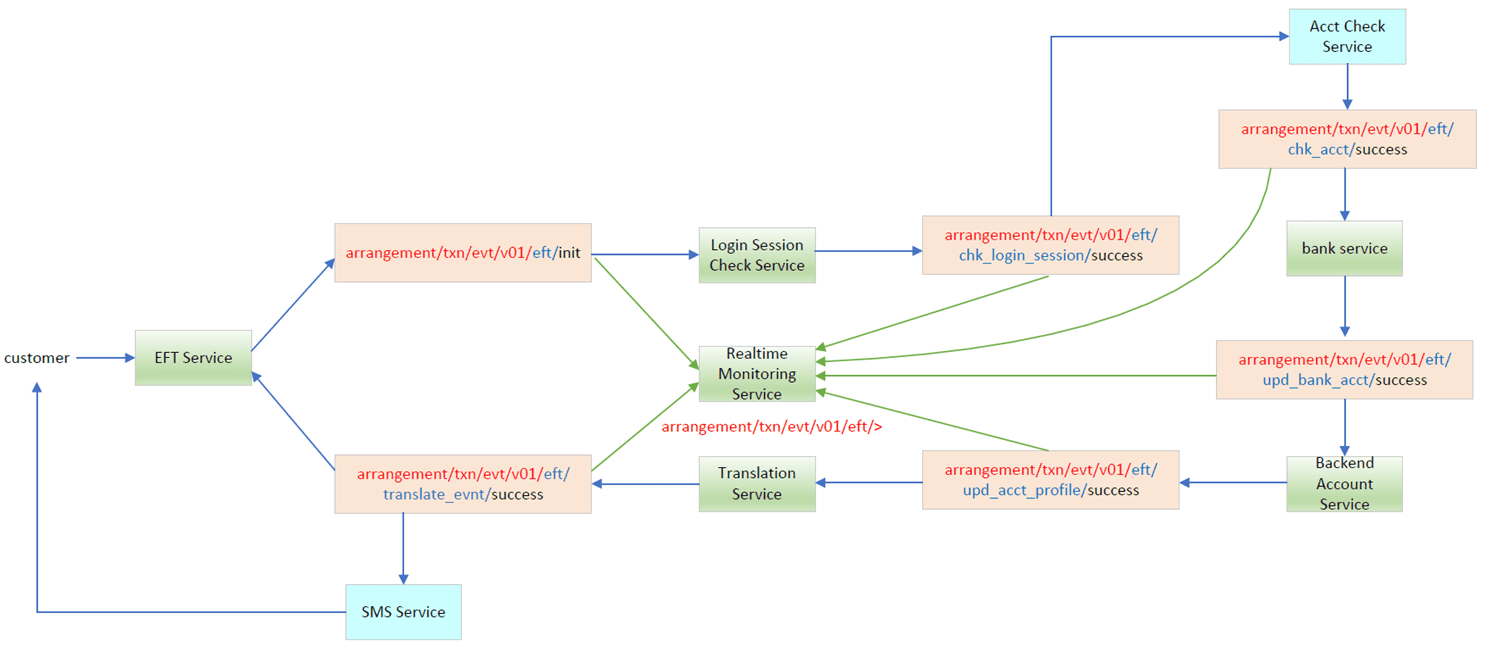
Let us use the ePayment service as an example. ePayment requests are triggered on different channels (web, mobile, ATM and bank), and then sent to the corresponding payment services via separate event flows. In the following diagram, the first three event flows are for EFT, PPS and FPS, while the last one is the fund transfer from the bank.
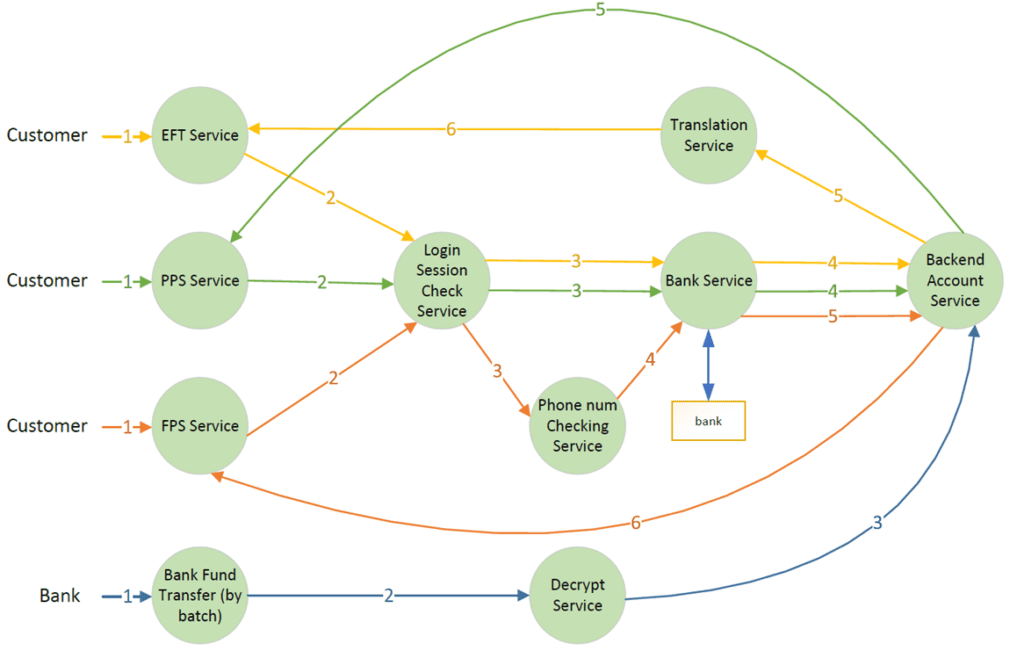
| Event Flow | Topic pattern |
| EFT Service | arrangement/txn/evt/v01/eft/{component}/{status} |
| PPS Service | arrangement/txn/evt/v01/pps/{component}/{status} |
| FPS Service | arrangement/txn/evt/v01/fps/{component}/{status} |
| Bank Fund Transfer | arrangement/txn/evt/v01/bank/{component}/{status} |
On each event flow, the mandatory parts (red and blue colors) are placed in the message header, and brought forward to all subsequent messages in the flow. This part should not be changed throughout the lifetime of the event flow. For each component, the output topic will be the input messages’ mandatory part plus this component function, plus the process status. It is very easy to subscribe to all corresponding events within the same event flow by using a wildcard. The following is an example of the EFT transaction flow.
Benefits
- Flexibility to add or remove any components. You don’t need to code anything in the topic routing logic to change subscriptions of individual components. For example, in the backend account service, different payment event flows to update customer balance is easily handled, and the status is returned to the corresponding topic.
- Easily subscribe to all corresponding events from specific event flow via wildcard
- Effectively collect all related events based on specific condition; for example, checking all activities of account 12345 (product selling, account operation, statement enquiry and ePayment, etc.)
- No built in logic for application routing. In the context of handling multiple event flows, the application does not inherently possess any pre-defined or hardcoded logic specific to these flows.
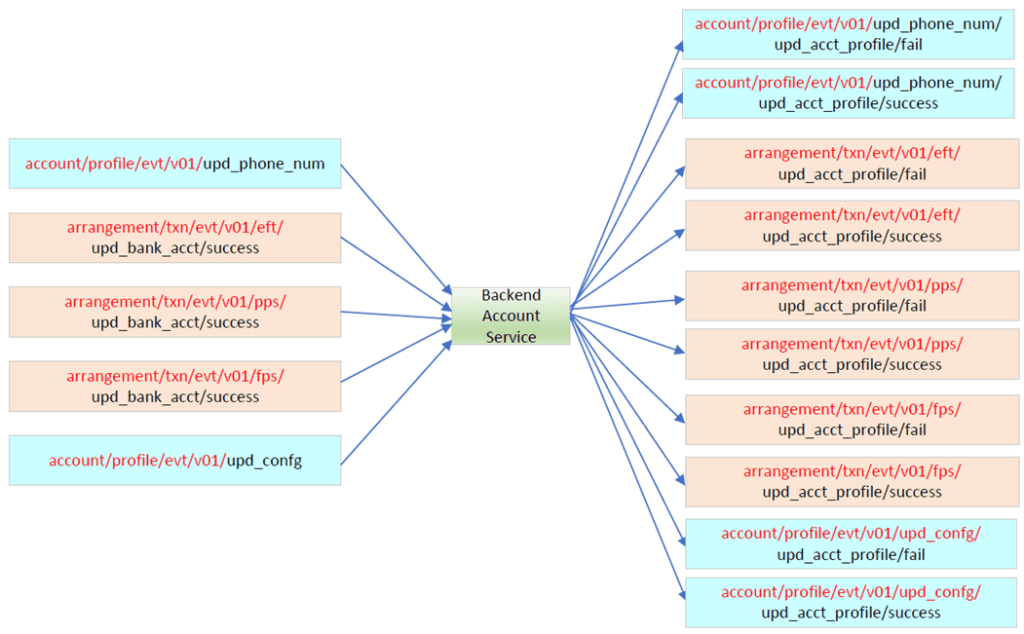
For example on the following backend account service, requests for updating customer profiles (like phone number) or system configurations (e.g., timeout value) should also be catered. As such, the header for incoming messages has to cater for the mandatory part of the topic name, while the consumer (backend account service) just needs to process the message and post the result back to the corresponding topic. The same thing will happen on every individual component, because the mandatory part of topic name will bring forward on the whole event flow; it will not be changed!

Tips:
- Implementing an end-to-end EDA solution becomes challenging when it involves interacting with legacy systems or systems with negative responses. As a result, many solutions opt to combine elements of both orchestration flow and choreography flow to achieve the desired outcomes.
- Currently, over 70% of the data flow follows a request/reply pattern. However, it is possible to implement a choreography-based publish/subscribe pattern to handle this data flow more efficiently.
- EDA offers the advantage of decoupling components, allowing for greater flexibility and scalability. Nevertheless, to fully capitalize on this advantage, it is imperative to establish a robust central logging platform and define a clear and comprehensive event mesh.
- The size of the event will increase significantly within the same event flow due to the necessity of propagating the data across the entire event flow.
Event Security Control
Events are significant digital assets, often containing personal and confidential information. For instance, an event may include sensitive details such as account numbers, balances on account statements, or personal information stored in customer profiles. We should implement appropriate event control to protect these digital assets. Ensuring proper event control is essential to securely transmit the event within a protected environment and restrict access based on specific permissions. Event control can be summarized using the following categories:
| Event Control Category | Governing Role |
| Event Mesh Control |
|
| Event Routing and Filtering |
|
| Event Accessibility |
|
Event Audit
The Event audit is an important process in Event-driven architecture (EDA) to ensure that implementation aligns with the design and guidelines. It helps identify any non-compliant items or bugs that may have been overlooked during the architecture, development, and testing phases. There are two areas where event audit checks can be performed: the platform event log and the event topics in production.
Platform Event Log
The platform event log captures various activities related to the event bus, such as connecting to the event bus, opening a flow to publish events, binding to a queue to subscribe to messages, and disconnecting from the event bus. These activities are logged on the event mesh and provide valuable information for troubleshooting and audit checks. By using business intelligence (BI) tools or log analysis tools, you can analyze the application behavior and identify non-compliant items. Some common mistakes that can be identified through event log analysis include:
- Using end-of-life operating system (OS), or framework (e.g., Java) or API Lib
- Making REST-style calls instead of following the specified event-driven style.
- Forgetting to call the unbind API when disconnecting from the event bus.
- Frequent reconnection to the event mesh, which can impact performance.
- Insufficient processing power to handle high-volume transactions.
- Using expired tokens due to programming bugs.
Event Topic in the Production
In Event-driven architecture, event topics play a crucial role in routing events to the appropriate subscribers. Organizations typically configure the event mesh and set the event topic names through continuous integration and continuous deployment (CICD) processes. However, there can be a disconnect between the configured topic names and the actual implementation in the application’s configuration file. This mismatch can lead to production incidents. To identify such issues, an agent can be employed to listen to all topics in the system, both in testing (SAT) and production environments. The agent then compares the observed topic names with the original design to identify any non-compliant items. Common issues that can be detected through this process include:
- Using wildcards in publish topics, which can result in unintended missing message.
- Deviating from the original design in the wording or structure of topic names.
- Adding unnecessary levels to the topic hierarchy, which can complicate event routing.
Event Reusability
Events are linked together to complete a business function via an event process flow, and various services can subscribe to the same event for different purposes. Event-driven architecture (EDA) enables real-time event collection from the event mesh without affecting performance or adding extra logic to the application. For instance, data scientists can analyze millions of similar events to create different campaigns for promoting best-selling products, removing unwanted products or pages, optimizing system capacity based on timeslot usage statistics, or providing personalized promotions based on customer activities.
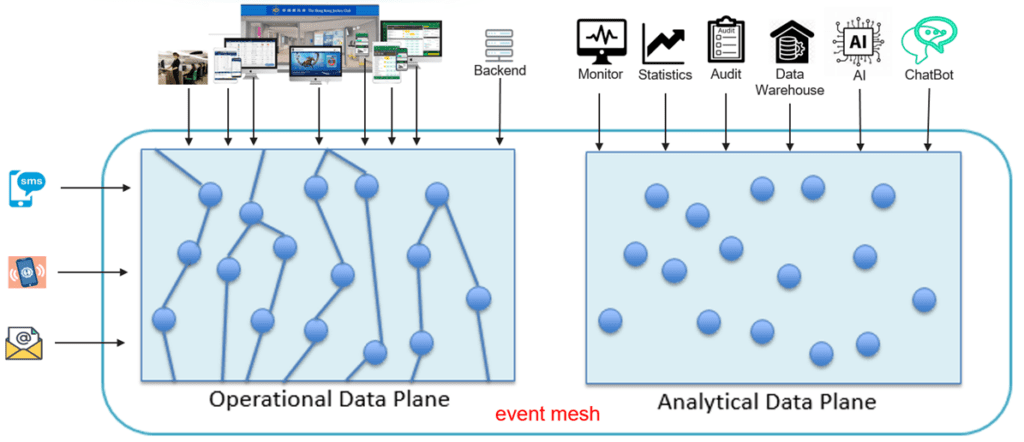
One of the key advantages of Event-driven architecture is the reusability of events, maximizing their value as digital assets without any performance impact. To achieve this, it is necessary to document all the events available on the event mesh in a centralized location and ensure proper collaboration among teams.
Documentation
Although you can create flow diagrams using drawing tools, MS Word to create schemas and queue configurations, or MS Excel to build topic names, and share these documents in Confluence or SharePoint, this is not the most convenient or easy way to manage, review, share, search, reuse, or maintain versioning. It is important to have dedicated tools for Event Cataloguing to better document events and their corresponding flows.
Most of organizations develop customized portals or use vendor solutions, usually referred to as Event Portals, to maintain this information in a unified space. Event Portals are not only for event management and reusability, but also provide event lifecycle management. They offer different views, such as event flow view or list view, to easily visualize applications, events, and schemas. Consumers can use the search function to find corresponding events (topic name) and directly download the latest schema for their coding needs, and publishers can quickly find all consumers for specific topics within seconds.
In the market, products related to event portals have been launched to facilitate event management within the Event-driven architecture (EDA) design, and their functionality has significantly improved over the past two years. This trend is expected to continue and become a strategic direction in the market.
Collaboration of Teams
Team collaboration is essential in this context. The event mesh enables dynamic routing of events within the Event Mesh, while the event portal provides a platform for visualizing events and facilitating easy sharing. However, not all events can be freely accessed by all authorized clients. The display system cannot access transactions or customer personal information, and the data warehouse does not have permission to store complete customer information. Therefore, it is crucial to establish well-defined guidelines and processes to enforce architecture and development teams’ compliance, aiming to enhance the effectiveness of team collaboration.
Tips:
- During the event registration period, the sensitivity level of the event should be defined in alignment with the data architect. Top-down sensitivity levels can cater to multiple sensitivity levels, from personal or highly confidential information to public information. Different sensitivity levels will require corresponding approval levels.
- Solution Architects should review any new data flow to ensure they meet data and security compliance requirements.
Event Tracing
EDA choreography design is a decentralized approach that allows for asynchronous processing and provides the flexibility to add or remove steps as needed. However, these advantages become a nightmare for tracing and troubleshooting when a significant number of events are dynamically routed and processed in parallel on the same event mesh. Providing granular real-time status about message and events delivery to observability tools is part of successfully implementing an EDA.
Currently, many organizations combine EDA and RDA designs within the same event flow. They employ different technologies, protocols (e.g., REST and messaging), and vendor solutions (e.g., APIM, CIAM) in their designs. Therefore, a comprehensive end-to-end tracing solution is required to handle increasingly complex situations beyond the EDA flow. Open Telemetry, which is open standard, fulfills all of these requirements. It is necessary to have a tool which can quickly debug problems, optimize complex architecture environments for performance and cost, and enable proof-of-delivery and audit.
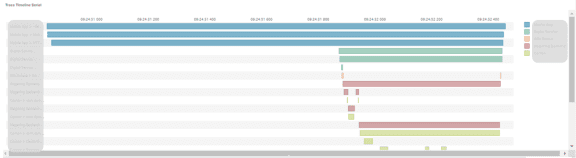
Let us use the following example to use Open Telemetry to implement an end-to-end tracing solution. The trigger point (mobile app) generates a 16-byte trace ID and then propagates it throughout the entire flow via different protocols (e.g., REST, Messaging, etc.) Each operation in the flow generates a separate span ID and writes the span ID, along with the input/output time and trace ID, to the application performance monitoring (APM) solution.
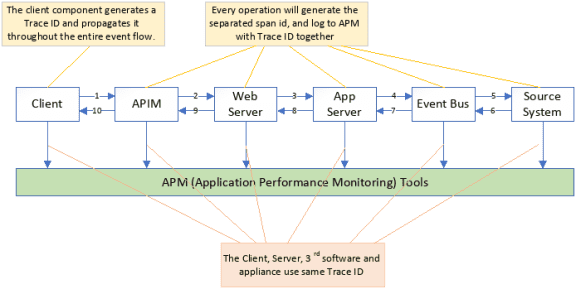
The APM tools links these logs together based on the trace ID and presents the entire flow as a bar chart on the dashboard.
Summary
Event-driven architecture has the capability to integrate with various technologies and methodologies, including software development life cycle (SDLC), data-driven architecture (DDA), and DevOps. By leveraging these approaches, we can significantly reduce product delivery cycles from 12 months to just 2 weeks, enabling organizations to meet rapidly evolving user demands within close proximity to market trends. Additionally, the implementation of event governance within EDA can contribute to enhancing the overall quality of events.
Explore other posts from categories: For Architects | For Developers | Solace Scholars



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.