TL;DR: Reliable industrial IoT depends on more than a connectivity protocol — it needs a broker platform that offers guaranteed delivery, rapid recovery, and message replay from end-to-end, not a stack assembled to fake those properties. The MQTT broker + Kafka pattern is the workaround that emerged because no single broker could do it all, but Solace Platform does it all, unifying AI agents, events, and SAP data with one fabric.
Where Should Reliability Live?
Industrial IoT architecture discussions create interesting debates, e.g. MQTT vs. AMQP, publish/subscribe vs. streaming, and MQTT QoS 0, 1or 2. At heart of these debates is the desire to create reliable systems and workflows that work well under real-world conditions.
Reliability will always be shared to an extent by applications and brokers/infrastructure, but architecturally, it is preferable to ensure reliability in the infrastructure.
For a while the most common way to build a reliable foundation for industrial workflows has been MQTT and Kafka. This article focuses on that pattern – its origins, challenges, and ways to improve upon it.
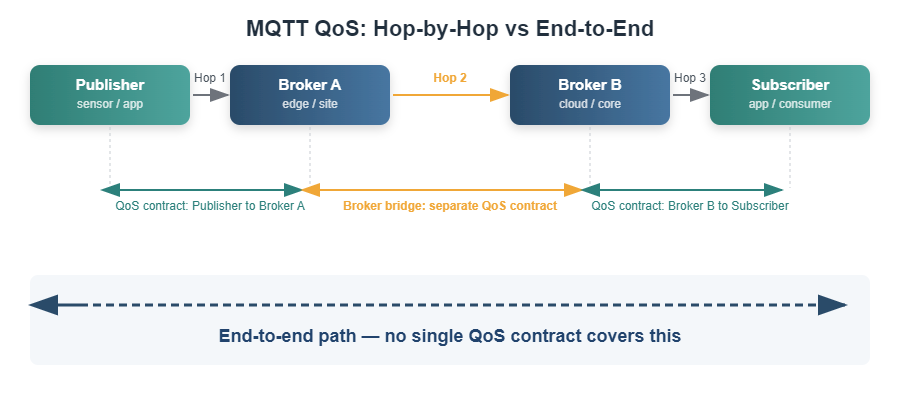
MQTT is a well-designed connectivity protocol. Its QoS semantics are hop-scoped by design (client to broker, broker to subscriber), which is the right design for a lightweight pub/sub protocol intended for constrained devices. The question is what sits above the protocol layer, and whether the common pattern of pairing an MQTT broker with Kafka to handle reliability and replay is the architecture you would choose knowing what you know about how your system has to behave in production.
This is worth working through carefully, because the decision affects operational cost, security posture, and the foundation the system will rest on for years.
What the Broker Platform Owes You
The protocol gets you connected, but the broker platform is responsible for everything that makes the connection useful. That responsibility surfaces as a handful of common scenarios — each one a question the broker, not the protocol, has to answer:
- Message Arrival: What happens when a consumer is unavailable when a message arrives?
- Message Rejections: What happens when a consumer rejects a message after receiving it?
- Outage Recovery: What happens when a downstream system comes back online and needs to reconstruct state?
- Replay Required: What happens when a late-joining analytics system needs 90 days of historical events?
- Lack of Acknowledgement: What happens when a command is retried three times and still not acknowledged?
These are broker platform design questions, and where MQTT brokers differ from each other. A standalone open-source broker, an enterprise MQTT broker with persistent sessions and bridging extensions, and a full multi-protocol enterprise event broker occupy very different positions on this spectrum. Lumping them together as “MQTT brokers” obscures the differences between them, and clouds the decision of which one is right for your situation and system.
A Note on QoS and What “Guaranteed” Means in Production
The MQTT specification defines three QoS levels: 0, 1 and 2. Senior practitioners know them well, and the production reality is this: QoS governs the behavior between two adjacent nodes. It defines a delivery contract at each hop — between a client and its broker — and not an end-to-end contract between a publisher and a downstream application consumer. However, in conditions like both sides using QoS 1 with persistent sessions, these hops can compose into at-least-once delivery.
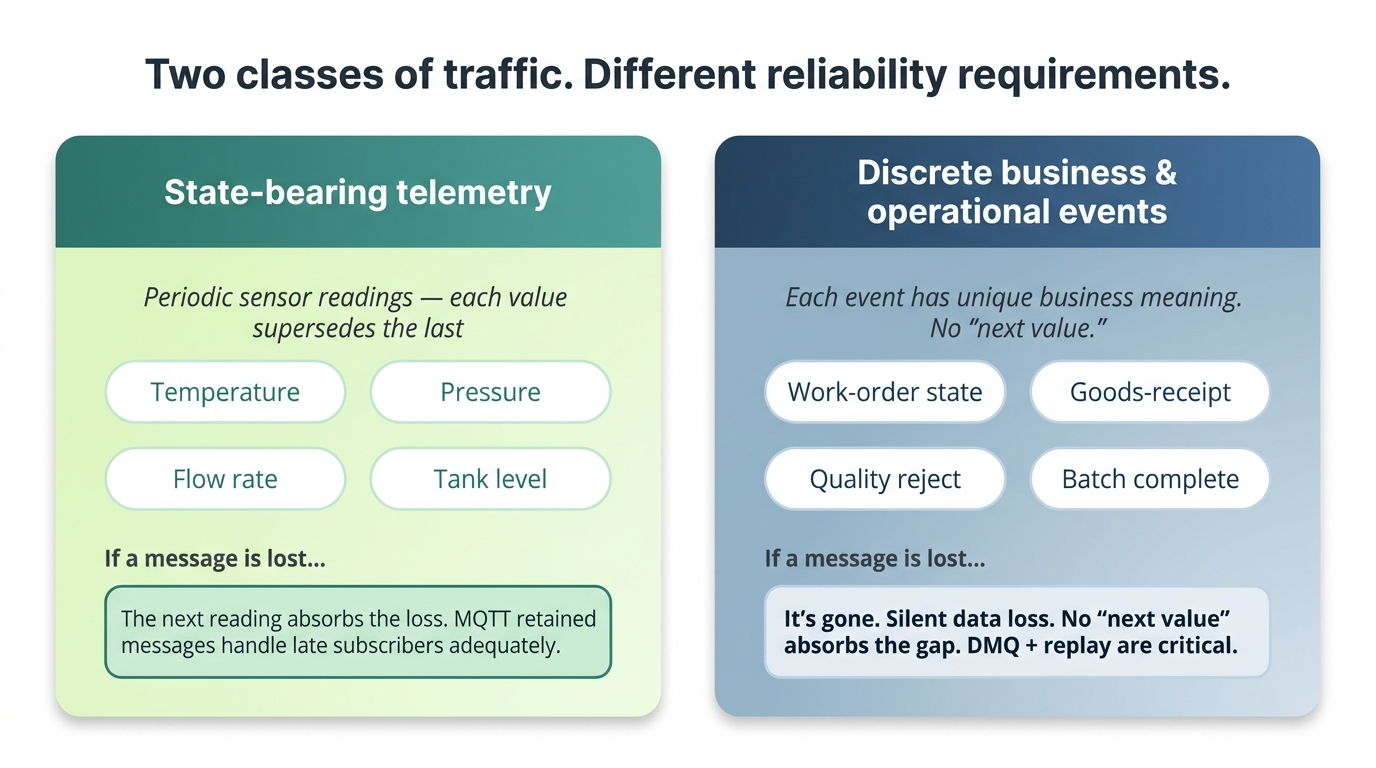
A clarification on workload type before continuing. Some MQTT traffic is state-bearing telemetry like periodic sensor readings where each new value supersedes the last, and a missed message is ‘absorbed’ by the next one a second later. For that class of workload, the production cost of a dropped message is low, and MQTT’s retained-message mechanism might handle late subscribers adequately.
The workloads where the ceiling matters are discrete business and operational events: work-order state transitions, goods-receipt postings, quality reject signals, alarm conditions, batch-completion records. Each of these carries a unique business meaning. There is no “next value” that absorbs a loss — a missing goods-receipt event is a missing posting to ERP, not a stale temperature reading. For these workloads, the questions below determine whether your platform is production-ready.
What QoS alone does not address:
- Whether a consumer application accepts and successfully processes the message after receiving it
- What happens to a message the consumer explicitly rejects
- Whether a message that could not be delivered is captured for inspection or silently discarded
- Whether a late-arriving consumer can reconstruct missed state
QoS level is not a proxy for application-level reliability. A QoS 1 message delivered to a broker with no dead message queue and no retry framework offers weaker production guarantees than a message delivered to a broker with full guaranteed-delivery semantics at the application layer. In other words, the burden to guarantee delivery is passed onto the application layer if the broker layer does not offer a DMQ and retry framework.
Two Mechanisms for Handling Failure: DMQ and Replay
They solve different problems, and production systems need both.
Dead Message Queue (DMQ): Surgical Recovery
A dead message queue (also referred to as a dead letter queue, or DLQ) is a broker-level construct where messages are automatically routed when normal delivery fails. It defines:
- Maximum redelivery attempts exceeded
- Message TTL expired before consumption
- Destination queue overflowed
- Consumer explicitly rejected the message: validation failure, schema mismatch, or application error
Example
A goods-receipt signal from the MES posts to a Solace queue feeding SAP. SAP’s integration layer returns errors during a rolling maintenance window. After the configured Max Redelivery Count is exceeded, the message moves to a pre-configured DMQ (assuming the message was published with DMQ-Eligible set and a DMQ is configured on the source queue). When SAP recovers, an automated workflow consumes from the DMQ and triggers redelivery to the original endpoint. No data loss. No manual re-entry.
Without DMQ configuration (or without DMQ-Eligible on the publish), the message is deleted at retry exhaustion. The failure is silent unless external monitoring is in place to catch it.
Message Replay: The Time Machine
Replay is a different mechanism. The broker retains a log of successfully delivered messages and allows any authorized consumer to rewind and re-consume from a specified point: a timestamp, a message ID, or the beginning of the retained log.
A note on scope before the example: Broker replay is not a substitute for a process historian. Historians (AVEVA PI, Aspen IP.21, Canary, and others) remain the system of record for high-frequency continuous process tags. Their compression, time-range query, and interpolation capabilities are purpose-built for that job and are not what a broker log is designed to replace. Broker replay complements the historian by handling the discrete business and operational events that the historian is not designed to carry: work-order lifecycle transitions, quality reject signals, goods-receipt postings, and other event-sourced state transitions.

Example
A new MES analytics platform is deployed. It needs to reconstruct the last 30 days of work-order lifecycle events to populate its operational state: order creation, release, start, completion, scrap, rework. Instead of a custom ETL job against the ERP and MES databases, the consumer subscribes to the relevant endpoint and requests replay from 30 days ago. The broker streams events in order. The platform is operational with full state context within hours, with no coupling to the source systems.
Replay capacity is bounded by retention configuration and storage: Within configured retention, any authorized consumer can rewind the log and reconstruct operational state without querying the systems that originally produced it.
Why You Need Both DMQ and Replay for Reliable IIoT
As covered earlier, some MQTT traffic is state-bearing telemetry — periodic sensor readings where each new value supersedes the last, and MQTT’s retained-message mechanism handles late subscribers adequately. The reliability ceiling matters less for this class.
The workloads to which that ceiling matters very much are discrete business and operational events: work-order state transitions, goods-receipt postings, quality rejects, alarm conditions, batch completions. Each carries unique business meaning, and there is no “next value” that absorbs a loss. For these workloads, the combination of DMQ and re-delivery/replay is critical.
| Scenario | Right Mechanism |
|---|---|
| SAP offline 2 hours, missed goods-receipt signals | DMQ / triggered redelivery / reconnect behavior |
| New MES needs historical work-order event state to initialize | Message replay |
| PLC command failed max retries, must not be silently dropped | DMQ |
| Regulatory audit of discrete quality or safety events | Message replay / dedicated audit queues |
| New SCADA instance needs current device state after cold start | Message replay |
| Late-joining analytics consumer reconstructing operational state | Message replay |
DMQ is surgical: it catches what broke and holds it for targeted recovery. Replay is temporal: it gives any consumer access to history. Production industrial systems need both, and ideally need them to be broker-native, not assembled from external components.
The 2am Scenario, Steeped in Reality
It is 2am on a Tuesday. An edge gateway completes a QoS 1 handshake with the MQTT broker for a reject signal from a vision system on a packaging line. The message is delivered to the broker. Confirmed.
Then the downstream quality-management system goes unavailable mid-processing. On a broker without persistent sessions, the message disappears. On a broker with persistent sessions but no DMQ, the message sits in the queued session until the consumer returns. If the consumer then rejects the message three times because of a schema mismatch during a rolling migration, there is nowhere for it to go.
By 6am, the defective unit has shipped. The audit trail has a hole. The protocol did its job. The broker platform did not, because it was asked to carry reliability responsibilities that require more than session persistence.
This is the failure mode that matters. The failure is: what happens when the consumer is reachable but cannot accept the message, and there is no DMQ to route it to. That scenario is invisible in most deployments and the burden is passed onto the application to build resiliency against such scenarios.
The MQTT Broker + Kafka Pattern: Rational but Costly
To close the gap between what MQTT provides and what production systems require, many architects reach for Apache Kafka alongside their MQTT broker with the goal of adding reliability. The reasoning is:
- The MQTT broker handles device-facing connectivity at the OT edge
- Kafka provides the event log, replay, and high-throughput fan-out for IT-side consumers
- Together, they cover the reliability surface neither covers alone
This is a legitimate architecture, but the operational cost should be accounted for:
- Two platforms to operate. Kafka requires broker tuning, partition management, consumer-group coordination, and retention governance. KRaft has simplified operations (ZooKeeper was removed in Kafka 4.0), but the operational surface area is still significant. Two distributed systems, two failure models, two upgrade cycles, two on-call rotations. Now, it’s common for organizations to use Kafka for data processing use cases (covered later), but to extend the same practices and infrastructure for durable industrial integration creates huge overheads.
- Two monitoring stacks. Broker metrics and consumer-lag metrics use different tooling and different alerting thresholds. End-to-end message tracing across the bridge requires correlation logic neither system provides natively.
- Schema governance overhead. Kafka deployments typically require a schema registry. Adding schema governance for industrial telemetry (where firmware updates can change payload structure) is another operational layer.
- Latency at the bridge. Every message crosses an additional network hop. For time-sensitive use cases, the added latency is a real consideration.
None of these are dealbreakers in isolation. They are complexity paid for in engineering hours, on-call rotations, and potential failure surfaces, particularly at the bridge, which is a single point of translation between two systems with different delivery semantics.
What It Looks Like When the Broker Owns the Reliability Stack
Solace Platform includes a multi-protocol enterprise event broker. It speaks MQTT, AMQP, JMS, and HTTP (including RESTful APIs) natively and simultaneously on the same broker instance, with consumers on any protocol able to receive the same published message — and with WebSocket available as a transport for browser and firewall-traversal use cases.
A Siemens PLC publishing via MQTT (directly or through an edge gateway) and an SAP system consuming via JMS are first-class participants on the same broker. No bridge. No additional latency hop.
The more important distinction is what Solace puts inside the broker itself.
Native Dead Message Queue
Solace’s DMQ is a broker-native construct. When a message exceeds its configured maximum redelivery attempts, its TTL expires, or it is rejected by the consuming client, the broker automatically routes the eligible message to its configured DMQ. The original message and its publication metadata are preserved. Operators can inspect the DMQ through Broker Manager or CLI, monitor it through broker statistics, and trigger redelivery directly. No external tooling. No custom retry framework. No Kafka topic designated as a dead-letter sink.
Built-in Message Replay
The Solace platform supports point-in-time replay natively on queues and topic endpoints. Consumers can request replay from a specific timestamp, a specific message ID, or the beginning of the retained log. Retention is configurable; replay depth is bounded by storage, not an unbounded “everything forever” promise. But within configured retention, replay is a broker-native capability rather than a Kafka cluster operated as the replay layer.
Multi-Protocol Without a Bridge
Because Solace speaks MQTT, AMQP, JMS, and HTTP natively, a single broker instance serves a modern industrial protocol landscape:
- Edge gateways and MQTT-capable devices publish via MQTT
- SAP systems consume via AMQP or JMS
- REST microservices publish alerts via HTTP POST
- Operator dashboards connect via SMF or MQTT over WebSocket
The same guaranteed-delivery semantics and the same DMQ apply across every protocol — and replayed messages are delivered transparently to any consumer, regardless of whether they use MQTT, AMQP, JMS, HTTP/REST, or SMF. Replay can also be initiated directly by SMF-based clients or centrally managed via the Broker Manager, CLI, or SEMPv2, giving operators full control over event rehydration across the entire protocol landscape.
No bridge to maintain, no translation service to monitor, and no seam between these OT and IT layers where messages can fall through.
Is Kafka Still Relevant?
Yes, in the context explained above, Kafka is the right tool for specific use cases thanks to these capabilities and in these scenarios:
| Kafka Strength | Why It Matters |
|---|---|
| Petabyte-scale event log retention | Kafka is optimized for long-term, high-volume log storage with retention measured in weeks or months |
| Native stream processing | Kafka Streams and ksqlDB provide in-platform stream processing without external frameworks |
| High-throughput parallel consumption | Partitions enable parallelism across large consumer groups at very high throughput |
| Data engineering pipelines | Kafka Connect has a broad ecosystem for databases, data lakes, and analytics platforms |
| Existing Kafka investment | Mature Kafka operations should not be ripped and replaced without clear justification |
When Kafka Needs Complementary Capabilities
Solace can replace the MQTT broker + Kafka pattern as the messaging, guaranteed delivery, and replay layer for most industrial IoT and enterprise integration use cases. For organizations with heavy Kafka Streams or Kafka Connect investment, Kafka remains a strong fit for the data engineering layer.
In that scenario, Solace owns the protocol-diverse, latency-sensitive, guaranteed-delivery surface, and Solace’s Kafka Bridge allows existing Kafka producers and consumers to interoperate with Solace through connector-based configuration rather than application rewrites, making the transition incremental rather than a hard cutover.
Comparing Approaches: Standalone MQTT, MQTT+Kafka, and Solace
The table below puts the three approaches alongside each other on the capabilities that determine production behavior — not protocol support, but what the broker layer actually delivers when a consumer rejects a message, an analytics platform needs 30 days of history, or SAP comes back online. Each row is a question this article has worked through; each column is how a different architecture answers it.
| Capability | Standalone MQTT Broker¹ | Enterprise MQTT + Kafka | Solace Platform |
|---|---|---|---|
| Device Connectivity (MQTT) | Yes | Yes | Yes |
| Persistent Sessions / Queued Delivery | Limited | Yes | Yes |
| Multi-Protocol (AMQP, JMS, HTTP, REST) | No | Limited (via extensions/bridge) | Native |
| Dead Message Queue (broker-native) | No | External / partial | Native |
| Message Replay (broker-native) | No | Yes (via Kafka) | Native |
| Unified Security Model Across Protocols | No | No | Yes |
| SAP Architectural Alignment | No | No | Yes (Advanced Event Mesh) |
| Agentic AI Integration on Same Fabric | No | No | Yes (Solace Agent Mesh) |
| Operational Platforms to Manage | 1 | At least 2 | 1 |
¹ Lightweight or open-source MQTT broker without enterprise persistence, DMQ, or bridging features.
Conclusion: The Advantages of a New Approach to Industrial IIoT Infrastructure
The pairing of MQTT and Kafka is a rational response to a real gap: MQTT brokers that were not designed to own the full reliability stack. For teams with existing Kafka expertise and a clear data engineering mandate, it is a defensible architecture.
But it is two systems to operate, two security models to enforce, and two failure domains to manage. In environments where a silent message drop can mean a missed safety event, a compliance gap, or a production line that should have stopped and did not, that cost lands where it matters most.
The more productive question for architects is not “which MQTT broker should I use” but “at which layer should reliability live, and do I want that layer to also be my integration fabric, my replay system, and the foundation for the AI agents that will eventually act on this data?”
When the answer needs to be a single coherent platform for real-time operational eventing and integration, MQTT + Kafka starts to look like an architecture assembled from what was available, rather than designed for what is required.
Kafka’s role in data engineering and analytics remains valid. The question is whether it should also be responsible for the operational reliability and integration layer that runs the plant — or whether that layer should be a single platform that feeds Kafka, instead of depending on it.
Explore other posts from category: For Architects



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.