Scaling Microservices with Kubernetes Event-Driven Autoscaler (KEDA) and Solace PubSub+
Event-driven microservices architecture poses unique challenges for scalability, and to realize the full potential of
Microservices scaling allows organizations to flexibly meet demand without over-provisioning resources by parallelizing computation. This is referred to as consumer scaling. It is noted that not all organizations do automated scaling, but manual scaling is common. The solution I’ll describe below can help solve problems in both scenarios.
In decoupled environments it can create potential problems when events that occur are sent to different consumers in a group where order may not be maintained due to network, application congestion, or other issues. It can also lead to queue problems as volume increases or as some services publish or consume at different rates. One solution to the problem can be feeding services from the same data-lake which requires replicating data across clouds or physical locations and will introduce latency, egress and storage overhead. This defeats the point of scaling services, especially for operational workloads and, “no shared databases” is often thought of as a golden rule for microservice development.
So how do you configure an event driven architecture for scalable microservice deployments? With a tool like Kafka you would use consumer groups. In this scenario, consumers are organized as groups via keys and each consumer reads from a partition. A nuance is that each consumer is responsible for advancing and remembering the last read offset but the end result is that the group as a whole consumes the entire topic.
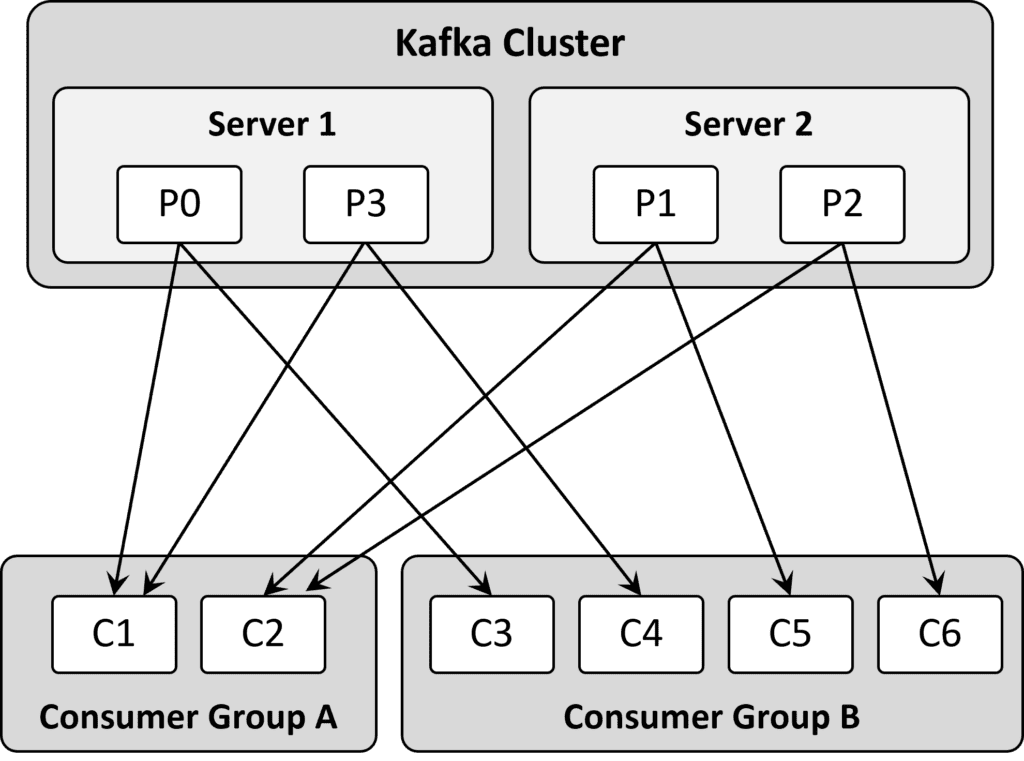
Figure 1 How Kafka Consumer groups are look in practice.
Shared and persisted? Sure. Is it a database? Well, in the case of Kafka that can depend on who you talk to. Regardless, as new consumers join the group you need to add partitions or the consumers sit idle. It works, but for operational use cases, it comes at a cost. Kafka partitions are implemented as log files which puts a practical limit on the number of partitions. It also introduces latency when the system is repartitioned as it scales up and down. There is another way.
If you want to learn about the various types of queues, this video is a great introduction.
With a partitioned queue, developers can allow for more dynamic up and downscaling of their environments. It starts similarity in that a partition key is added to the event. All these events are run through a hash function so it routes all related events to the same consumer based on the hashed value. If an event doesn’t have a key, then it is randomly assigned a hash value and load balanced across queues. As the applications scale automatically, they receive the events routed in real time. As they scale down, traffic only stops to the partitions that are being rebalanced and only for a short (and configurable) time while all the others keep moving.
This image shows that a consumer can receive events from different partitions, but a partition is only mapped to one consumer and this means that events with the same key get the same hash (i.e. related), stay together, and in order, based on the hash value.
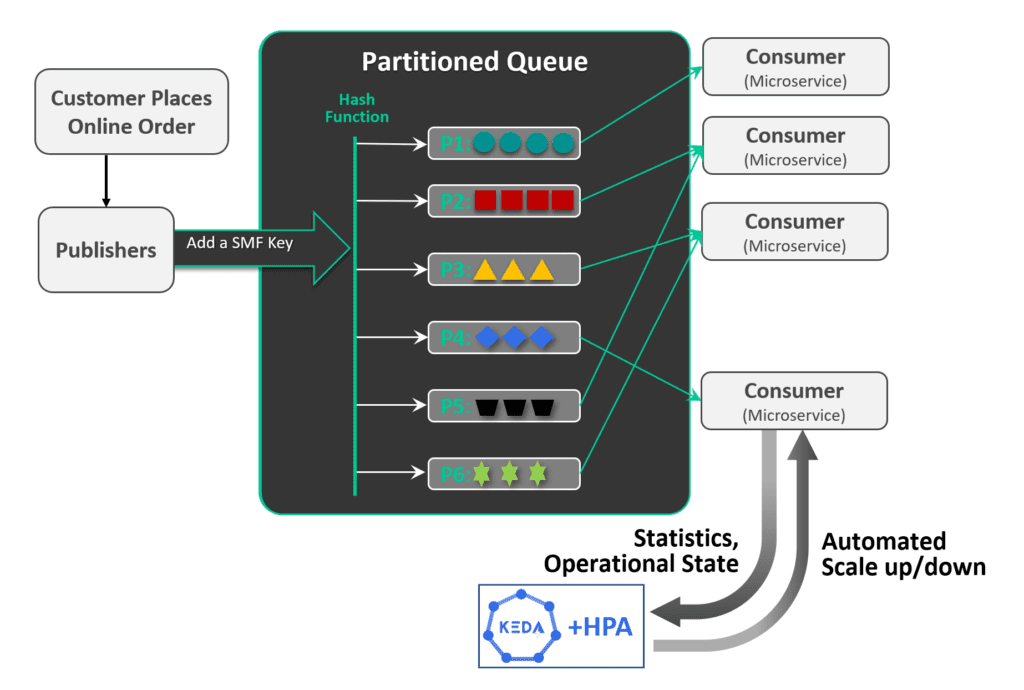
The image above introduced KEDA, which stands for Kubernetes Event-driven Autoscaling. It is an excellent CNCF project for horizontal scaling. Consumer autoscaling is triggered by external events and these are defined by the developers and operations teams when they are optimizing their systems. A Solace PubSub+ Event Broker queue can be a trigger for adding consumers with KEDA, and you can read about that over in the KEDA documentation.
Let’s consider how this benefits organizations with a simple example for a checkout procedure. During checkout the user makes mistake and must back out of one of the steps and make a change in credit card information. This change needs to be received by the microservice that has already began the order processing, already sent the cart data to other tools (for instance a retargeting engine for display advertising or an analytics tool for monitoring product popularity). It is this microservice that needs to consume the change in order versus the change being processed before the original data had exited its queue. “In order” is harder to visualize – but consider that maybe the checkout microservice takes longer to run than it takes for the change to arrive and the event queue needs to be maintained.
This example is pretty easy to visualize, but at scale with many concurrent microservices running, scaling up and down, and crossing different application development teams and services you can quickly see the need for automated queue partitioning.
We’re now going to dig into a lot of technical detail that does require some knowledge of event driven architectures so if you want to conclude at this point, we have put together a fun demo based off the video game, “Portal” where you solve puzzles by opening portals to different locations. In this case the puzzle being pieced together is the in-order delivery of related events as they teleport around the board. Check it out here:
Enabling partitioned queues using a partition key is done at the publisher. For Solace, the APIs will allow the key to be added and are done with the JMSXGroupID – that was developed for exactly this purpose. It hashes into the partition versus just passing the key along in the event via a group ID. The hash function returns the same number based on receiving the same key and allows for values to be determined based on the number of consumers and not fixed to a specific key – meaning developers don’t need to track and maintain such things across functions.
Across consumers it is automatically balanced so as you add consumers it begins to distribute the load evenly and automatically across the queues. For instance, if an organization is using KEDA (Kubernetes Event Driven Autoscaling) for autoscaling then new consumers bind and the partitioned queue recognizes the new consumers. The size of each queue is shared across the partitioned queue with the partitioned queue automatically scaling each of the partitions independently.
Solace events are delivered on a first-in-first-out basis to maintain order. So, when a new consumer binds to a partition it is binding to an inactive flow. It then becomes active and the delivery order is maintained with the key across existing events while new ones begin filling the queue for the new service. Moreover, as you are adding consumers the system will hold down for configurable period of time to determine if multiple consumers are being added. As a consumer is taken down it will drain the consumer and send to another.
This also works in reverse if you take down a consumer gracefully or via a crash or failure the system will hold down for a (configurable) period of time to see if the consumer returns, if it doesn’t it will automatically route messages in queue to the other consumers. While this can result in a mismatch, this is better than losing the message altogether in a failure scenario.
If a queue fills up because its consumer(s) are slow then it will tell the publisher that it can’t accept new messages and tells the publisher to republish. This ensures in-order delivery and like-event delivery.
While partitioned queues deliver a similar benefit to Kafka consumer groups you also get the benefit of not feeding the same topic across multiple partitions in consumer groups. This means you can create as many subscription topics (and wildcards) as you want and you save operational overhead in the form of ingress, egress and storage, but also in managing the complexity. Moreover, every queue can attract multiple topics for better scaling and fine-grained filtering so your messages are only routed where you want and to only the consumers that should have them. There is no need to filter at the consumer.
Solace partitioned queues also include benefits inherent to Solace topics and subscriptions that are fed into the queue. This includes guaranteed delivery, queuing, wildcard filtering, dynamic message routing, distributed tracing, in-order delivery, re-delivery, event acknowledgement, high-performance, ultra reliability and ease of scaling partitions up and down without the challenges that occurs with Kafka.
Solace Partitioned Queues solve problems related to decoupled, load-balanced and even auto-scaled microservices by ensuring events flow correctly as consumer groups scale up and down. This lets organizations save costs, reduce operational complexity, and improve customer and user experiences.
Explore other posts from category: For Architects



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.


