(Updated in April 2023 to reflect the introduction of partitioned queues)
The concept of message queues is fundamental in message-oriented middleware (MOM) and a constant topic of discussion for Solace users. Generally speaking, a queue is defined as a storage area where a message is stored until it is consumed by an application, or it expires. A queue provides the guarantee that the message will never be lost even if the consuming application is unavailable or if the message broker crashes.
Solace endpoints are objects created on the event broker to persist messages. There are two types of endpoints: a queue endpoint (usually just called a queue) and a topic endpoint. I detailed the differences between queue and topic endpoints here, and you can get a quick intro to queue types by watching this video:
In this post I’ll explain different consumer patterns used for traditional services with requirements ranging from guaranteed in-order delivery, load-balancing, and auto-scaling.
Solace Message Queue Access Types
In Solace PubSub+ Event Broker, a message from a queue can be consumed by only one consumer, even though multiple consumers can be bound to the queue. Based on the use case, a queue can have two access types for consumers: exclusive and non-exclusive. Within the category of non-exclusive queues, there are two classifications known as competing consumer and partitioned queues.
Exclusive Queue
When an application disconnects from the event broker, the endpoint it was connected to will buffer and save the messages destined for that application. If the application does not connect for a long period of time and the incoming message rate does not slow, the queue could run the risk of filling up. There is also the case where a consuming application cannot have downtime when processing time-sensitive data.
Using an exclusive queue, a developer could connect multiple instances of an application to the same queue to ensure messages are always processed. The first instance to connect, or bind, to the queue will receive all messages; should that instance of the application disconnect, the next instance that connected to the queue is prepared to take over activity and start consuming. This provides a fault tolerant method to consuming data from a queue without any downtime.
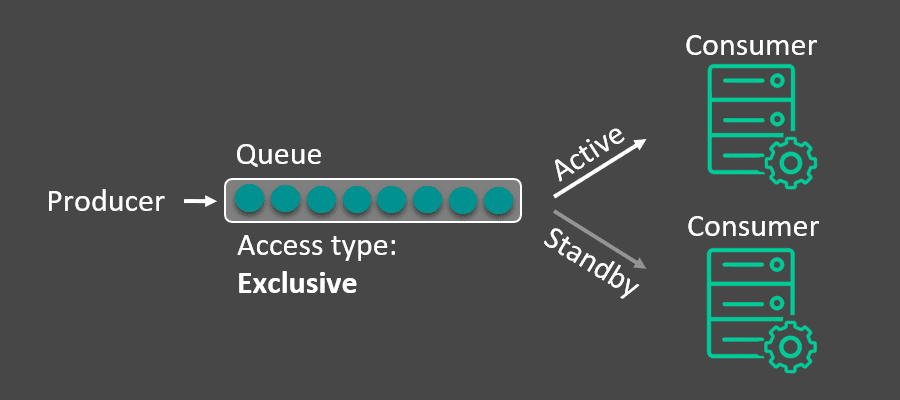
For the developers out there, it may be useful to know there is an Active Consumer Indication which indicates to a previously standby consumer they are now the active consumer. This can be useful for grouped applications to function properly in a fault tolerant consumer pattern.
The one to one nature of exclusive queues does not allow them to scale vertically. Instead, they scale horizontally with the context. By including the context in the Solace topic and mapping a context or group of context to a single exclusive queue through subscriptions, each context is delivered in order.
Non-Exclusive Queue (Competing Consumer)
For some use cases, the ingress rate (publish message rate) may be too fast for a single endpoint consumer to keep up. It may be required to have multiple instances of an application share an endpoint and consume data in a load-balancing manner.
A Solace non-exclusive endpoint allows multiple connections to bind to it and messages are round robin distributed to those connected applications. There is also a consideration for the speed of each consuming application, meaning that messages will be sent to the consumer based on how fast or slow the consumer is. Based on the acknowledgment rate from the consumer, the broker will deliver the messages at the appropriate rate. This is often referred to as a competing consumer pattern.
For example, in the below diagram, both Application A and Application B will get messages. If both applications are processing messages at the same rate, the broker will deliver an equal number of messages to both apps. However, if Application B slows down, then based on the acknowledgment rate back from Application B, the broker will be able to identify Application B as a slow consumer and send the messages at the appropriate rate to Application B. The broker takes care that consumer applications are never pressured, and therefore acts as a shock absorber.
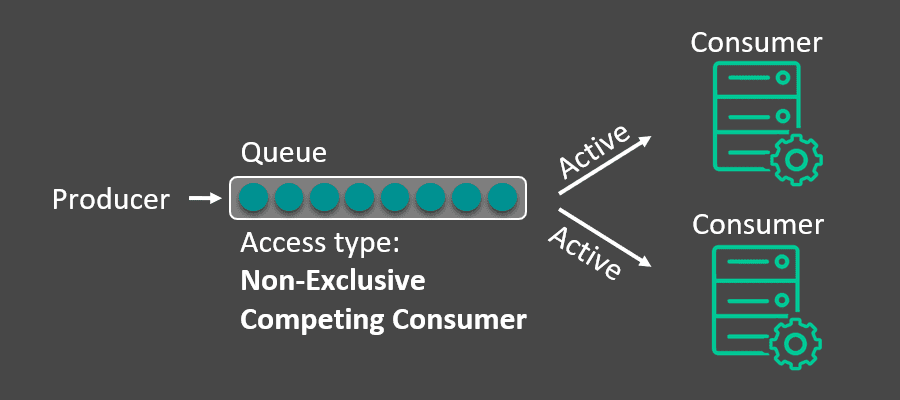
Both a queue and topic endpoint support this ability. While its default state is to support only one consumer, a non-exclusive topic endpoint can support multiple consumers.
Dynamic consumer auto-scaling using solutions like Kubernetes Event Driven Autoscaling (KEDA) works well with non-exclusive queues that dynamically adapt to the number of bound consumers and maintain the round robin and consumption aware behavior across all active consumers. However, with this queue type if message context is important it can be lost since context isn’t bound to a consumer. Context is used to identify related messages and ensure they are delivered in order.
Non-Exclusive Queue (Partitioned)
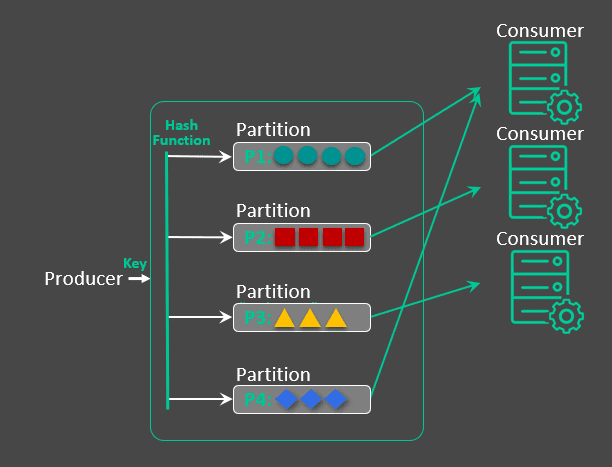
While non-exclusive queues solve the need for load balancing, the competing consumer pattern assumes that a message can be delivered to any microservice instance. This is great when your microservice is stateless. If the application requires in-order delivery for multiple contexts (e.g. orders, employees, flights, etc.), it requires access to a common data store amongst all auto-scaling consumers. At times, this common data store adds additional complexity, security concerns, and/or cost to the solution and it would be more effective to have messages with the same context be consumed by the same consumer.
This is where partitioned queues come in. By leveraging a key provided by the API to provide the context, the partitioned queue load balances amongst all active consumers while ensuring that messages with the same context go to the same consumer. This is similar to using multiple exclusive queues, but with a mechanism that dynamically maps context contained in a key to partitions as opposed to statically mapping in an exclusive queue. The key is hashed into partition number for all messages with that same key. So, all messages with the same key go to the same consumer microservice instance. Each partition maps to one and only one consumer. The partition to consumer mapping is managed dynamically as the number of consumers is auto-scaled. So, messages with the same key go to the same consumer.
Access Type Setup
The good news is that all this complex logic is done by the broker behind the scene without any manual intervention by the administrator. The only thing that an administrator must decide is whether the queue is exclusive or non-exclusive. This can be done while the queue is being created or can also be done at a later date.
When configuring non-exclusive queues, the broker will default to the competing consumer non-exclusive queue unless the number of partitions is changed from its default value of 0 to the desired number of partitions for the partitioned queue.
The access type to use will depend on the exact use case. Both access types have their benefits. The main deciding factors should be whether message ordering is important and whether load balancing amongst consumers with or without auto-scaling is required.
Conclusion
I hope this post has helped you understand the concept of access types, and how and when each access type should be used. In short:
- if you care about message order use an exclusive queue
- If you care about load balancing, choose a non-exclusive competing consumer queue.
- If you care about both, then choose a partitioned queue.
If you found this post useful, you can visit the queues section of our docs and our PubSub+ for Developers page for more information. You can also check out some sample code on Github.
You can also read more in my series about understanding Solace endpoints by visiting the posts below:
Explore other posts from categories: For Architects | For Developers



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.