The ability to replay previously-published data to some set of consuming applications is a common requirement of many enterprise messaging and data movement backbones. Often people think about replay in these narrow terms. They look at product capabilities and fit their needs into the functionality offered, instead of thinking holistically about the actual, frequently multiple, replay requirements of their business.
For example, I have heard discussions around using the Kafka broker as an enterprise message replay server because of its ability to replay messages. Apache Kafka is a write ahead commit log server that has been successful in aggregating typically low value data for ingestion into Big Data solutions. While Kafka technically supports replay, its capabilities are only a subset of the typical needs and you need to build tooling around it to make it useful.
In this blog I will discuss the many use cases and requirements for replay in an enterprise and compare Apache Kafka’s capabilities to those of a purpose built enterprise replay server, specifically Tradeweb’s Replay for Messaging for which Solace has a tight integration in the Replay for Solace edition.
If you want to “cut to the chase” and just see the comparison, jump to here.
Background
A replay service can be a key component in a messaging architecture where it is not feasible to request the message source (producer) to re-publish any lost or missing messages so that one or more downstream consumers can back-fill any missing messages. Replay servers are also commonly used in QA or UAT to replay production data into a UAT environment at controlled message rates, and other data test scenarios.
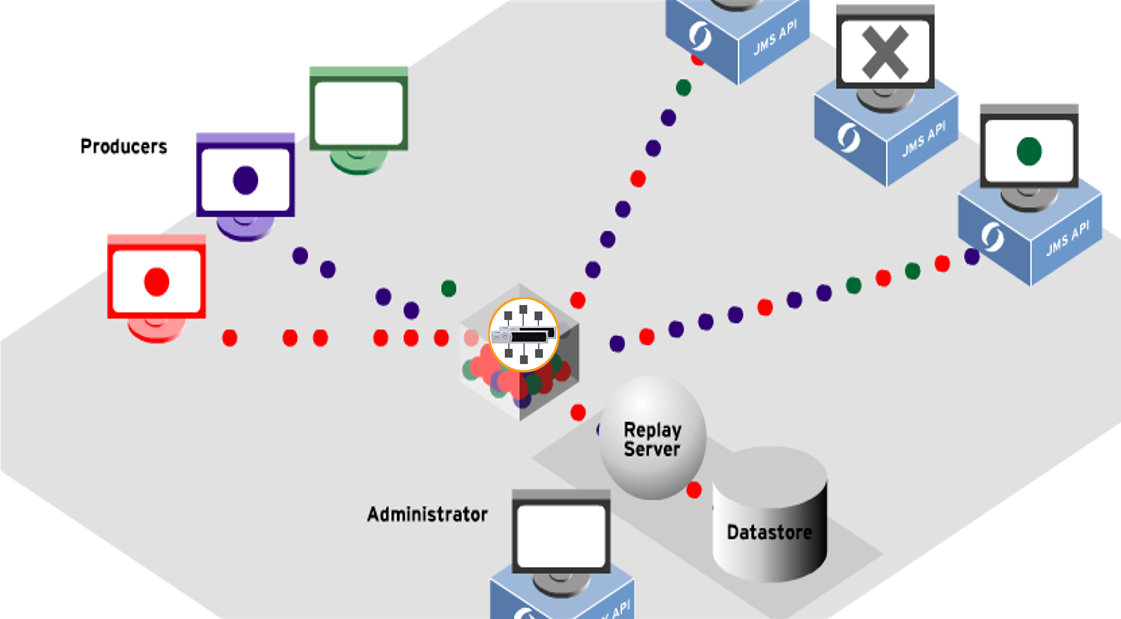
Use Cases
Here are some typical example use cases for message replay:
- Recovery of lost data. In this case clients have previously consumed and acknowledge messages from a message broker, but now have a requirement for replay of the messages due to data store corruption. The replay can either be initialed via an administrative request for replay or programmatically through the Message Broker/Replay server API. Examples would be if data is written from the message bus into a database or in-memory grid and then after data is written, the database itself becomes corrupted. From this point the database administrator would recover the database as much as possible then request a replay of data for the time period, or message sequence number to recover lost data and get the database back into the correct state.
- Late joiner. When a new consumer application comes online and needs to build up its knowledge or state to the same level as existing applications. Similar to the previous use case the consumer will need to either administratively or programmatically request a replay to back-fill a date range, or message sequence range, to bring the consumer up to date. Examples would be an application that would always request a replay from “start of day” each time it comes up. In normal operation it would come up before start of day and receive nothing from the replay and, then cut over to live data. Any new instance of the application that is started mid-day would do the same thing, request replay from the start of the day.. The replay request would backfill missing messages, then the application API would cut over to live data.
- Systemic or long term client outage. In this case, clients are offline for long periods of time and consuming resources on message brokers that are tuned for fast persistent message delivery. It might be advantageous to persist the large number of undelivered messages out to a replay server that has cheaper/slower data stores that can handle larger volumes of data. Then replay the messages when the offline consumers come back online. They may receive the messages at a slower rate than originally published, but this type of data is no longer real-time or near real-time. Examples would be an application that is across a WAN link that experiences day long outages, or a regional office that shuts down for the weekends. In these cases the data cannot be lost, but can be recovered in an off hours request to a replay server.
- Delayed Feeds. In some systems the fee for use of data is lifted after a period of time. If the messaging system can prove that it can quarantine data for the fee liable expiry time, then the data can be freely distributed after the expiry time is reached. The replay server needs to be able to replay the data to new destinations only after a configured delay interval has expired for the message. Example would be fee liable market data where there is a cost associated for every consumer of the data unless the data is withheld for 20 minutes, and then delivered.
- Correct Subscription Errors. In this use case the consumer was mis-configured to only receive a part of the message traffic that it requires. Adding the subscriptions and receiving all missing data before cutting over to new live traffic is required to re-integrate the missing data into the data flow. An example is an analytics engine that compares different values such as market data symbols where part way through the day it is determined the scope of the analytics needs to be increased by adding new symbols to watch. An administered or programmatic replay request could be issued to pick up the missing data and expand the scope of the analytics.
- Correct Data flow error. There are cases where poison messages will cause downstream applications to fault or crash. Simple replay is not enough to resolve this issue and there are use cases where individual messages will have to be identified and eliminated from the replay so that applications can successfully process all the correct data.
- Replay for test. There are many test scenarios where replay is valuable. Examples include:
- End consumer might want to receive the data from previous days, in original form, so that they can test new algorithms or procedures in the application and compare them to an original. This data would likely, but not always, be replayed to a test/uat copy of the application in a different network.
- Test groups would want to replay data in original form but at increased rates to test capacity capabilities of the system
- Test groups or application development groups will want to inject faults into the data flow to test system fault recovery.
Requirements
In all the above high level cases, the requirements of the replay server seem simple and not too onerous. Simply receive message from a message broker, persist to disk, then replay to end client upon request. But as with most things, the details of the requirements will really start to show where the architectural trade-offs will make a difference.
Data Capture
The primary requirements for data capture are to be lossless and preserve message order across the defined data sets. To be lossless means that a failure of any component cannot cause message loss. Also to achieve lossless capture the replay server likely needs horizontal scaling to keep up with the ingress message rate while servicing replay requests. This leads to the second point, the message traffic must be divisible in a flexible enough fashion that you can easily build shards of the data that contain order dependent data.
Data Filtering and Retrieval
To do proper filtering and retrieval of messages to republish, the replay server needs to be publish time and message id aware. This allows for replay based on something meaningful to the user such as time frames, for example: replay all messages from beginning of day until now. Also messageId aware replay servers can replay specific messages or exclude specific messages. Being able to replay from a certain byte offset in a stream, for example, is not particularly useful to users.
Along with being topic, time and message aware. There is often a need to further inspect messages for header fields that add context to a message, for example: replay all messages related to a specific transaction. This content aware, application-specific filtering may require “and|or|not” logic, such as: replay all messages related to a series of transactions that were produced from a specific publisher.
Data Publishing
Once the correct replay filtering has been applied it is often required to be able to control replay rates as well as control destinations. The overall network, or consumer applications, might not be engineered for full rate replay, as this could be a 2x increase in network traffic, so rate limiting of replays is valuable to ensure network engineers understand the total impact of replay traffic during production. As well, replay messages will often be replayed into a new destination set up specifically for the purpose of the specific replay so as to not interfere with the ongoing original traffic, in these cases there might be requirement to replay traffic as fast as possible or again at a controlled rate independent of the original rate. Replay for test purposes has many requirements such as reply at original publish rate or 2x or 5x the original rate (which then simulate realtime burst behaviors) for system stress testing; it may require the ability to corrupt messages to generate negative test conditions on consumer applications; it may require that live traffic be delayed by specific amount of time, or exclude certain data.
Alerts and Monitoring
There are several key resources that need to be monitored within a replay system. Eventing needs to be in place to indicate the replay server is falling behind realtime traffic before conditions such a publisher backpressure or message loss occurs. There needs to be health monitoring of individual message consumption flows as well as overall disk health checks before issues such as disk overflow occurs.
There needs to be the ability to provide replay job monitoring that includes capturing the start/end times of the job, job progress, average message throughput, average publish time, average message size and other statistics that seems appropriate; replay pause/restart/cancel control.
Security
It must not be possible to defeat any kind of access control to real-time data by simply requesting a replay of that data. Unless otherwise defined the same restrictions on access to real-time data must apply to the replayed data, therefore it is important that the replay server be integrated into your overall data access authorization strategy. This means any programmatic requests must come from authenticated users and all replays must be subject to the messaging systems access control mechanisms.
User Interface
The replay server is a message store that will assist in actual message management. As previously mentioned you will likely need to be able to search for messages based on time and message id, the user interface should also allow you to delete or modify specific message. Also the ability to view complete messages in the gui will help in building filters based on additional header properties.
The gui needs to also be able to present state of replays in progress as previously mentioned
Comparison
Now that we understand some standard use cases and requirements, let’s next look at a feature comparison chart to see how well Tradeweb’s ReplayService for Solace server meets these requirements vs Apache Kafka. The reason to do this comparison is that Kafka is popular in the big data messaging space and developers are looking at this technology to solved messaging problems in the enterprise including message broker and message replay work.
![]() Supported by replay server
Supported by replay server
![]() Supported with additional tools or requires custom code by the customers.
Supported with additional tools or requires custom code by the customers.
![]() Not supported
Not supported
| Feature | TradeWeb Replay | Kafka |
|---|---|---|
| Capture from production replay into UAT | ||
| Able to efficiently use large amounts of cheap storage | ||
| Data capture losslessly | ||
| Data capture in publish order | ||
| Programmatic replay data with topic filtering | ||
| Programmatic replay data with hierarchical topic filtering | ||
| Programmatic replay data with header field filtering | ||
| Programmatic replay data with “and|or|not” header filtering | ||
| Programmatic replay data with publish time filtering | ||
| Programmatic replay data with new directed destinations | ||
| Handle multiple replay requests at the same time | ||
| Alert when ingress queues hits Warning and critical levels | ||
| Replay job monitoring | ||
| Start/Stop time | ||
| Percent complete | ||
| Avg replay rate | ||
| Administration UI to inspect messages | ||
| Administration UI to search/remove messages | ||
| Administratively control replay destination | ||
| Administratively control replay rates | ||
| Require authentication for programmatic replay | ||
| Apply access control rules to publish and receipt of replay data |
Conclusion
Apache Kafka is popular in use cases where consumers require all the data from the producer un-filtered, such as big data ingestion. The reason that these servers are popular is that they can make efficient use of disk I/O because of the sequential nature of data access. But, the requirement for replay in modern data movements systems is much larger than simple log replay, and require a full set of access controls, filtering and monitoring of data movement similar to what is provided by the Tradeweb ReplayService
Explore other posts from category: Products & Technology



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.