As per the flume.apache.org: “Flume is a distributed, reliable, and available service for efficiently collecting, aggregating, and moving large amounts of log data. It has a simple and flexible architecture based on streaming data flows. It is robust and fault tolerant with tunable reliability mechanisms and many failover and recovery mechanisms. It uses a simple extensible data model that allows for online analytic application.”
So why would you need anything other than the already available components of Flume to transfer data into your Big Data infrastructure? Why not just use existing Flume Source and Flume Sinks to connect Flume to your enterprise messaging solutions?
Well the next picture starts to show the problem. To scale Flume you need to stitch together several Flume Agents in varying hierarchical ways with point-to-point TCP links. If your data has high value, next you will need to add fault-tolerance and high availability meaning you will need to add disk access and redundancy at each level. So the high level picture:
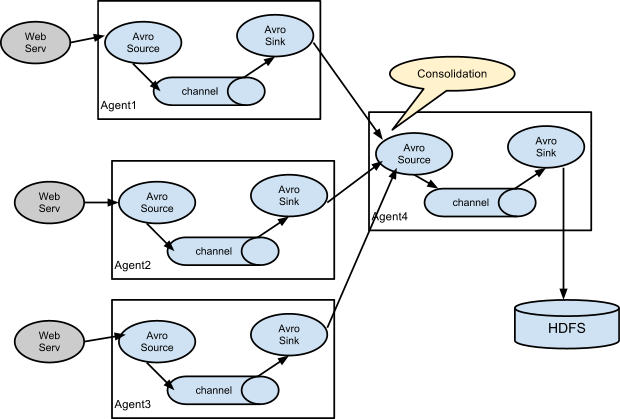
…Would actually need to look like this for each of Agent1, Agent2, and Agent3:
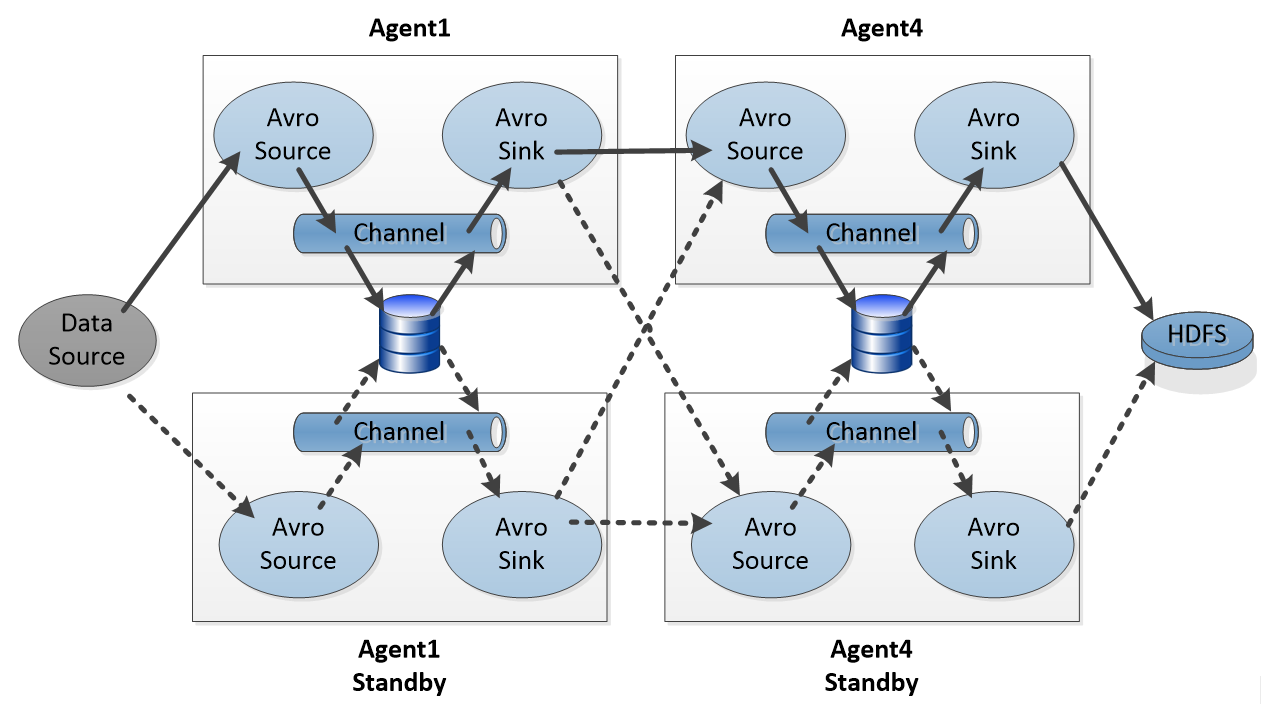
This would mean 4 sets of shared disk partitions and 4 redundant links. This would be costly to set up and maintain both in configuration effort and disk space. Also hop by hop disk writes in the data path will cause significant latency overhead. In this diagram there is still no solution for disaster recovery as any single failure in the shared disks could cause data loss.
As the architecture increases in complexity with the addition of fault tolerance this solution becomes increasingly harder to manage. There is limited ability to monitor traffic flows and queuing points to understand exactly what is happening and where bottlenecks may be occurring. It could become a security and compliance issue with disperse disk writes of your data with limited authentication of users.
However, the main problem with this architecture isn’t the Flume source or Flume sink components as they provide very appropriate and reusable functions. The architectural problem stems from the typical Flume channels which are either a disk or memory based FIFO – that’s the root of the problem.
If instead of trying to do data distribution with Flume channels, you use Flume Source for Data ingestion and Flume Sink to feed into HDFS and use Solace as the data distribution layer or Channel, then many of the problems above go away and other advantages emerge.
The use of a Solace channel would take advantage of Flume on the edge of your network and allow your applications to continue to use Flume Sources and Flume Sinks as before. But now, instead of trying to stitch together Flume agents to make a network or distribution layer, Solace would replace the memory or file channels and add a true network messaging layer. This would overcome the disadvantages of Flume memory channels which are potentially lossy or Flume file channels which inflict disk write latency overhead on messages without making changes to the way current applications send and receive data.
The Solace channel itself is a simple transactional bridge that efficiently moves Flume events from the Flume Source into Solace messaging router; and then again out of the Solace messaging router into the Flume Sink. The channel itself does not persist messages to disk and only has context on the active transaction. All of the persistence and reliability functionality is inside the Solace message router.
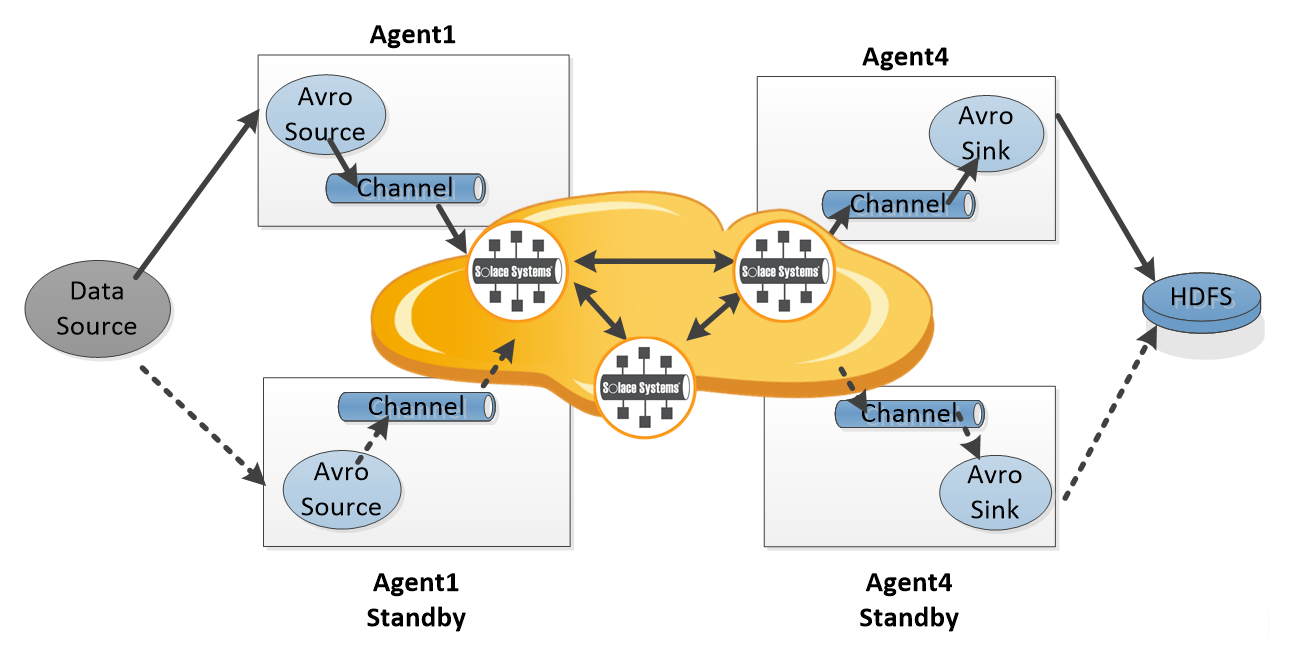
Beyond adding a fault tolerant data path with high availability and disaster recovery with low latency, this message pattern also opens up the Flume data to the ESB allowing new uses for the data, and allows non-flume data to write directly to the Flume channel queues from the ESB.
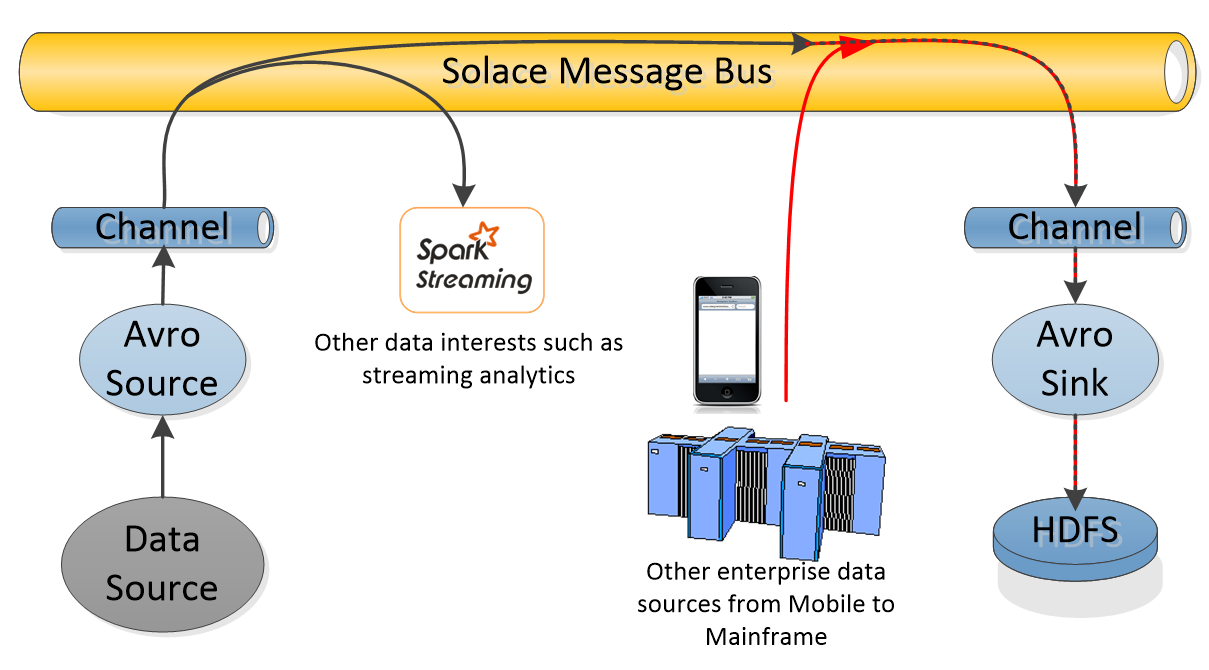
Looking at the Sink side. It is highly likely that there is not a single consumer of data going into HDFS. For example in the Big Data Lambda architecture, data needs to be consumed by the Batch Layer and Speed Layer. These different data consumers behave differently, in that the Speed Layer is looking for high throughput with low latency, while the Batch Layer needs buffering as a slower consumer and will take data in large batches. The right side of the diagram below shows how this would be done with existing Flume components, while the left side show how this would be done with a Solace channel.
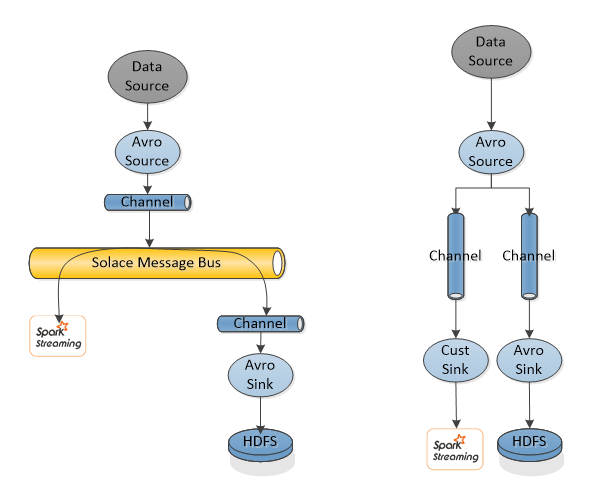
The important thing to notice here is that without Solace the fanout occurs within the Flume Source. This means that the data being sent to the Spark connected channel will take a latency hit while the data is being sent to the HDFS connected channel as well. Also you have to make the choice on the Spark connected channel to either accept the potential loss lousiness of a memory channel or the latency of disk channel. Using a disk channel would have the knock on effect of double disk writes for each flume event, once for the HDFS connected channel and once for the Spark connected channel.
The use of Solace as a channel on the left side of this picture is architecturally similar but has some key differences. First the fanout is not done in the Flume Source but instead in the Solace message router. This means the Flume Source is able to publish very fast with an optimized single channel to write to. Second the queueing and disk writes in the Solace message router are optimized for performance, no double writes here no matter how many fanout consumers.
It is also worth noting that for some time now, Solace users have already integrated their Solace message bus with Flume using the JMS Flume Source as described here to push their enterprise events into HDFS for analysis (btw – those wanting streaming analytics using Spark Streaming can integrate as described here)
From the Flume Sink side, there is a complete de-coupling of data source and the processes consuming the data. This allows other data sources that existed prior to the Big Data infrastructure creation to participate in enriching your data lake.
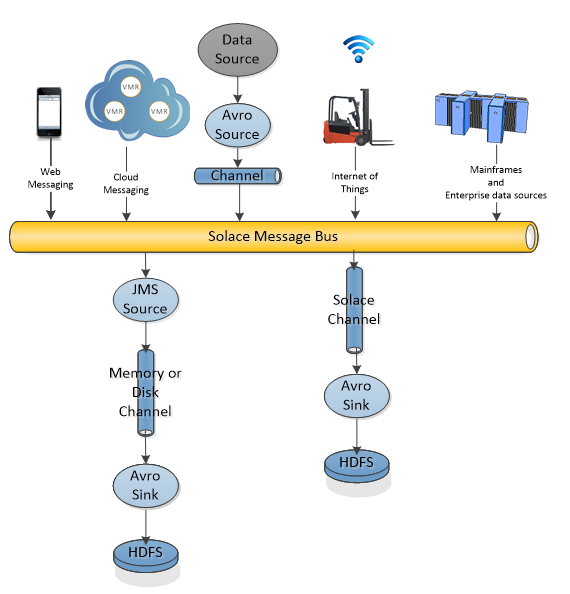
So looking at this picture from a little wider perspective and it becomes easier to see that using Solace channels not only benefits the Flume data work flows, it enables easy access to the actual data across all connected application types. Notice here that now the streaming analytics engine has access to the raw data source in a reliable manner without taking the latency hit and storage complexity of having disk writes in the data path. This simplifies the overall data flow and with Solace monitoring capabilities as seen here, the rates and capacity of the data flow becomes visible.
The Solace message bus could provide a rich set of messaging features such as WAN optimization, compression, transport level security, fault tolerance and configurable exclusivity of data access. This allows geographical distribution between data sources and the big data infrastructure.
The next blog I will explain the technical details on how such a solution works.
To learn more about the features and functionality of Solace message routers as the core products in an enterprise message bus see the overview of Solace technology.
Explore other posts from category: DevOps



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.