Why Your Event Mesh Isn’t Complete Without Excellent Monitoring
Read More

Two weeks ago, Google announced Anthos – an enterprise hybrid and multi-cloud platform – to great fanfare. Powered by Kubernetes, Anthos aims to make it easier to run cloud-based apps in any cloud and on-premises. To do this, Anthos enhanced the capabilities of its service mesh to extend beyond a single GKE cluster to span on-premises and multiple clouds – while also managing all of these services from a single pane of glass.
It looks to me like Google is pushing GKE everywhere – RESTful microservices spanning hybrid and multi-cloud. I think it’s a great strategy because it means developers won’t have to write apps multiple times to run in different clouds.
Up to now, distributing applications across hybrid and multi-cloud environments meant having to deal with different runtime systems. Each application deployment means you have to build and test your applications several times. Once the applications are deployed, how do you manage them across all these environments each with their own tools and operational procedures? Needless to say, it’s COMPLEX.
Anthos solves this complexity problem by providing a federated cluster of GKE Kubernetes clusters that use an Istio/Envoy-based service mesh – a web-friendly, REST-based interface for connecting various components of applications deployed across the datacenter, GCP, and other clouds.
Service mesh has existed for some time in Kubernetes, but with Anthos Google is providing some new capabilities and functionality via Traffic Director. Traffic Director is a managed service that routes between microservices and can route between clouds. It uses Istio Pilots and Envoy load-balancers across the distributed GKE deployments to allow the service mesh to span multiple cloud environments and route traffic around microservice outages in any specific location or cloud.
For example, consider a scenario where you have a microservice application running in the US West region and you have a cache outage. The Traffic Director will route any requests to the cache in the US East region and the replies will come from the live cache. Now let’s say the database within that microservice goes down. Now the Traffic Director must route data requests to its alternate database microservice which is in the US East Region. This means the data is not in one place and may need to be replicated across geographies, on-premises and clouds.
But when you have real-time event-driven applications, latency and data replication become issues This is where I see the concept of an event mesh being a great companion to service mesh; an event mesh routes the real-time events with application multicast or application anycast across all interested services both locally and geographically dispersed. To further explore this relationship, see Service Mesh, Meet Event Mesh.
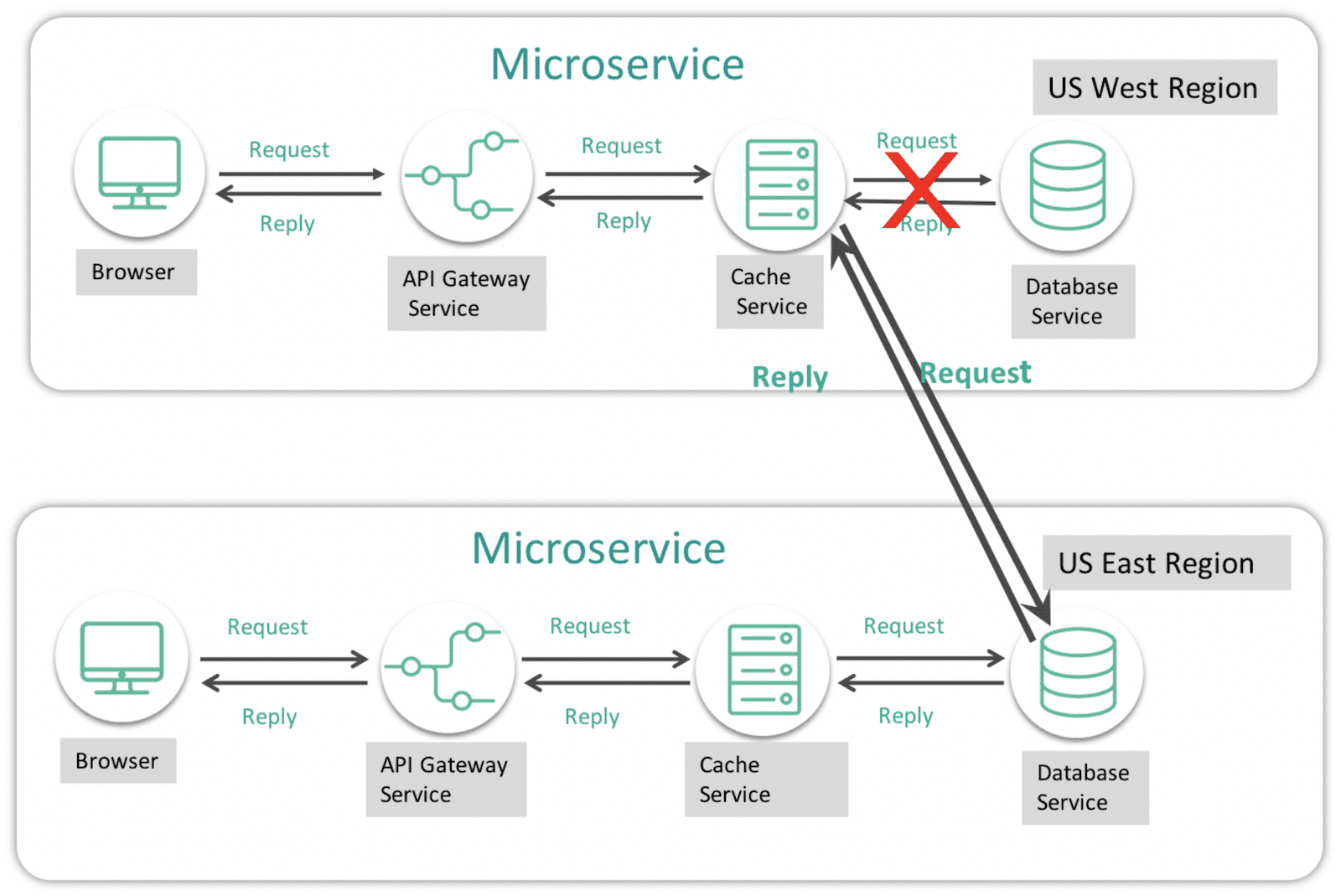
Figure 1: This diagram shows how Traffic Director routes requests between microservices which may require data to move.
An event mesh is to your event-driven applications what a service mesh is to your RESTful applications: an architecture layer that enables events from one application to be dynamically routed and received by any other application, no matter where these applications are deployed (no cloud, private cloud, or public cloud). An event mesh is created and enabled by a network of interconnected event brokers and provides all the benefits of a service mesh (Discovery, Routing and Security), along with throughput, latency, and the WAN replication optimization that your event-driven applications need.
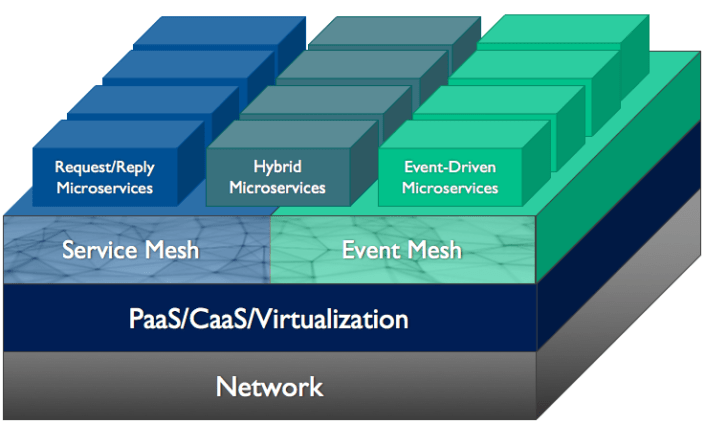
This diagram shows where an event mesh fits in an application stack relative to other technologies such as service mesh.
Anthos using a service mesh architecture with single pane of glass management definitely fills the need for enterprises to run Request/Reply microservices applications across hybrid and multi-clouds. And an event mesh makes the same promise for modern event-driven applications; the best part is that they work side-by-side to provide a consistent eventing infrastructure across the enterprise.
To solve this distributed problem, the event mesh must also be federated across sites and managed from a single pane of glass.
Explore other posts from category: For Developers



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.