Heading
Sub-heading







9 results found
Insights, trends, and practical guidance for teams running on real-time data.
WHITE PAPER
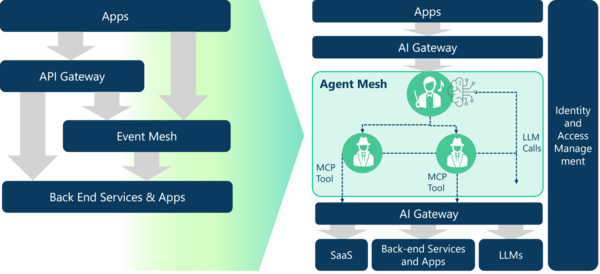
Don’t miss the agentic revolution. Get an in-depth look at the real-time data requirements for building agentic systems while exploring use cases and reference architectures.

Connect with us
Creating Event Driven Applications is hard. There is a lack of tooling to discover, create, share and manage events. There’s no easy way to govern events. DIY solutions are brittle, complex and take up too much of your time. If these are familiar challenges, Solace Platform is going to make your life infinitely better.