Executive Summary
The enterprise integration landscape is evolving in response to the capabilities and requirements of real-time data and agentic artificial intelligence (AI). Modern systems must now do two fundamentally different things: execute with certainty and reason under uncertainty. Traditional approaches—centered on APIs, point-to-point connectivity, and middleware-based orchestrations—worked well when systems were predictable, data was structured, and workflows followed deterministic patterns. But today’s organizations operate across hybrid and multi-cloud environments, rely on SaaS ecosystems, process vast streams of real-time events, and increasingly depend on AI to interpret unstructured data and automate decisions.
As the complexity, intelligence and automation of digital operations grows, enterprises must shift their thinking along with their architecture, to a more flexible, layered integration model that not only supports both deterministic execution and probabilistic reasoning but enables them to work together.
This whitepaper builds on a common architectural pattern that separates connectivity from integration, while introducing a fundamental shift within the integration layer itself—one that redefines how modern systems execute and reason. Rather than operating as a single, uniform layer, the integration layer now supports two distinct but complementary modes: deterministic execution, where workflows follow explicit logic and produce predictable outcomes, and probabilistic reasoning, where AI-driven systems interpret context, infer meaning, and make adaptive decisions.
The connectivity layer continues to provide universal access to data through APIs, events, and files, but it is this bifurcation within integration that enables systems to combine precision with adaptability—allowing deterministic workflows and probabilistic agents to work together in coordinated, real-time processes.
Together, these layers form a modern integration fabric capable of reacting in real time, reasoning with context, and executing with confidence. This paper explains how to leverage and operationalize this model, when to apply deterministic versus probabilistic tooling, and how to combine APIs, events, files, and agentic AI into a unified architecture.
Organizations that adopt this layered approach will be positioned to build systems that can react instantly, think intelligently, and continuously adapt—unlocking new levels of automation, insight, and operational resilience.
The future of integration is not a single pattern, but a system of interacting capabilities—where APIs execute, events inform, and AI agents reason, working together to enable both deterministic execution and probabilistic intelligence.
This paper:
- Explores how the connectivity and integration layers work together to meet the evolving needs of modern digital business.
- Presents a forward-looking model for using existing and new APIs, events, and files as core data connectivity primitives
- Examines the role of deterministic and probabilistic integration engines; and explains how agentic AI unlocks entirely new automation patterns.
- Provides a roadmap for how organizations can combine these architectural approaches into a cohesive, future-ready integration strategy—one capable of reacting in real time, reasoning intelligently, and executing reliably at scale.
The Three Goals of Integration
As architects, we need to design systems that enable enterprise applications and agents to:
- React instantly
- Decide intelligently
- Execute reliably.
In the past, our focus as architects has been largely focused around reliable, deterministic execution. That remains foundational to all critical business systems, but modern integration must now also support real-time responsiveness and intelligent, context-aware reasoning. It is important for architects and developers to understand, internalize and rigorously follow the following key fundamental goals of integration:
React Instantly
Modern enterprises increasingly operate in a real-time, distributed world where business value depends on reacting the moment something happens. Whether it’s IoT sensors reporting environmental changes, supply chain systems detecting inventory shifts, financial platforms responding to new market signals, or digital applications adapting to user behavior, immediacy is now a competitive requirement. Event-driven architecture (EDA) enables this responsiveness by moving information the instant it is created—without waiting for polling cycles, batch jobs, or manual triggers.
This real-time fabric dramatically improves user experience, allowing systems to feel “alive” as they update interfaces, push notifications, or adjust workflows instantly. In distributed business ecosystems, reacting instantly isn’t a luxury; it is foundational for keeping systems synchronized, customers engaged, and operations optimized.
Think Intelligently
Many modern integration scenarios involve information that cannot be processed through deterministic logic alone—emails, documents, logs, conversations, screenshots, customer messages, or historical data patterns. Traditional systems struggle to interpret this unstructured or semi-structured data, but LLM-powered AI agents excel in this space. They can understand language, summarize context, extract insights, dynamically incorporate real-time signals, and generate reasoned, context-aware recommendations. This enables AI-enhanced orchestration that unlocks new capabilities such as intelligent case handling, autonomous decision support, dynamic workflow adaptation, and pattern recognition across vast historical datasets.
AI doesn’t just process data; it interprets it, contextualizes it, and transforms it into actionable outcomes. When systems must “think,” rather than merely execute predefined instructions, agentic AI becomes essential.
Execute Reliably
Despite the rise of AI and probabilistic reasoning, many business operations still require strict determinism—where every input must produce a predictable, guaranteed, and verifiable outcome. Payment processing, account updates, inventory adjustments, compliance workflows, and transactional system-of-record operations cannot tolerate ambiguity.
APIs – of both the RESTful and event variety – meet this need by providing controlled, and authoritative mechanisms for reading and writing data. Their predictable nature ensures consistency, auditability, and reliability across mission-critical workflows. In these scenarios, the enterprise must operate with unwavering precision, and deterministic integration—often API-centric—is the only appropriate tool.
The Evolution of Integration:
The New Enterprise Reality
As mentioned, integration challenges are increasing in scope due to:
- Hybrid and multi-cloud adoption
- Exploding data volumes from IoT and mobile
- Demand for real-time personalization
- Proliferation of unstructured data
- AI-driven decision-making
The Abundance of Alternatives
The modern enterprise operates in a landscape defined by variety, specialization, and choice—an unprecedented variety of applications, intelligent agents, platforms, clouds, data systems, architectural models and data exchange patterns. This shift is not just about scale or speed—it reflects a fundamental change in how systems operate: they must now support both deterministic execution and probabilistic reasoning.
Hybrid and multi-cloud adoption has become the norm, with workloads distributed across AWS, Azure, Google Cloud, on-prem data centers, and edge environments. Each environment offers its own integration patterns, security models, networking challenges, and operational tools. At the same time, enterprise teams are increasingly autonomous, choosing the technologies that best suit their needs: some build microservices, others rely heavily on SaaS platforms, and still others implement event-driven systems or AI-enhanced applications. Some interactions still require precise, predictable execution, while others require systems to interpret context, infer meaning, and adapt under uncertainty.
This diversity accelerates innovation but dramatically complicates integration. The result is an ecosystem where connecting systems is no longer a simple matter of linking A to B—it’s about integrating hundreds of heterogeneous components that all speak different languages, follow different lifecycles, and live in different infrastructure domains.
The As-a-Service Economy of Enterprise Systems
Compounding this challenge is the shift in how SaaS platforms like Salesforce, SAP, Workday, and ServiceNow behave—acting not just as hubs of applications, but of information, integration and agents.
These systems offer APIs, event streams, embedded automation, workflow engines, and even AI assistants. The line between “data storage,” “application,” and “integration layer” has blurred. Enterprises must now integrate not only the data within these platforms but also the business logic, triggers, and AI-driven workflows they provide. This creates a new level of architectural entanglement: changes made in one SaaS platform can ripple across dozens of dependent systems, requiring integration strategies to account for both data consistency and cross-platform process orchestration.
The Explosion of Event-Driven Data
At the same time, data proliferation is exploding at a scale that legacy integration approaches simply cannot absorb. IoT and edge devices continuously generate real-time telemetry; mobile apps push and pull data as users interact via apps and dashboards; logs, metrics, and traces accumulate at staggering volume; and AI systems rely on constant data intake for training and inference.
This shift from occasional, human-driven interactions to constant, machine-generated data flows is transforming integration from a transactional problem into a real-time streaming challenge. Data now arrives not just in large quantities, but in more formats—from structured records to text documents, PDFs, images, messages, and sensor readings. Integrating this diversity requires more than APIs; it requires event-driven patterns, scalable brokers, and AI systems capable of interpreting unstructured information.
The Rise of AI-Driven Decisions and Operations
Overlaying all of this is the emergence of AI decision-making and autonomous workflows, which generate a new kind of integration demand. AI agents and LLM-powered automation rely heavily on external context pulled from enterprise systems, and in turn, they produce new outputs—insights, summaries, recommended actions—that must be fed back into operational workflows.
This creates a bidirectional dependency between operational systems and intelligent agents, requiring integration architectures that support both deterministic and non-deterministic processes. Integrations must not only move data—they must understand it, contextualize it, and trigger the right actions across distributed systems.
Integration is the Infrastructure
The new enterprise reality is therefore defined by complexity, scale, and diversity unlike any previous era of IT. Integration is no longer a back-office plumbing exercise; it is the operational fabric that connects clouds, teams, data, systems, and intelligent processes.
Organizations that succeed will be those that acknowledge this new reality and adopt architectures flexible enough to embrace it—APIs for precision, events for real-time responsiveness, and AI for intelligence.
The New Trifecta of Integration
Modern enterprises are now operating at a scale and complexity where a single integration paradigm is no longer sufficient. Business processes increasingly blend deterministic and probabilistic behaviors, each with fundamentally different requirements on data, latency, reliability, and execution semantics.
Ultimately, the modern enterprise needs to think about integration as building blocks and layers. These building blocks fundamentally assist in componentizing, conceptualizing and defining of how the integration system will function. Below is a diagram depicting the future of integration – layering deterministic and probabilistic integration on top of the connectivity layer we know and love.
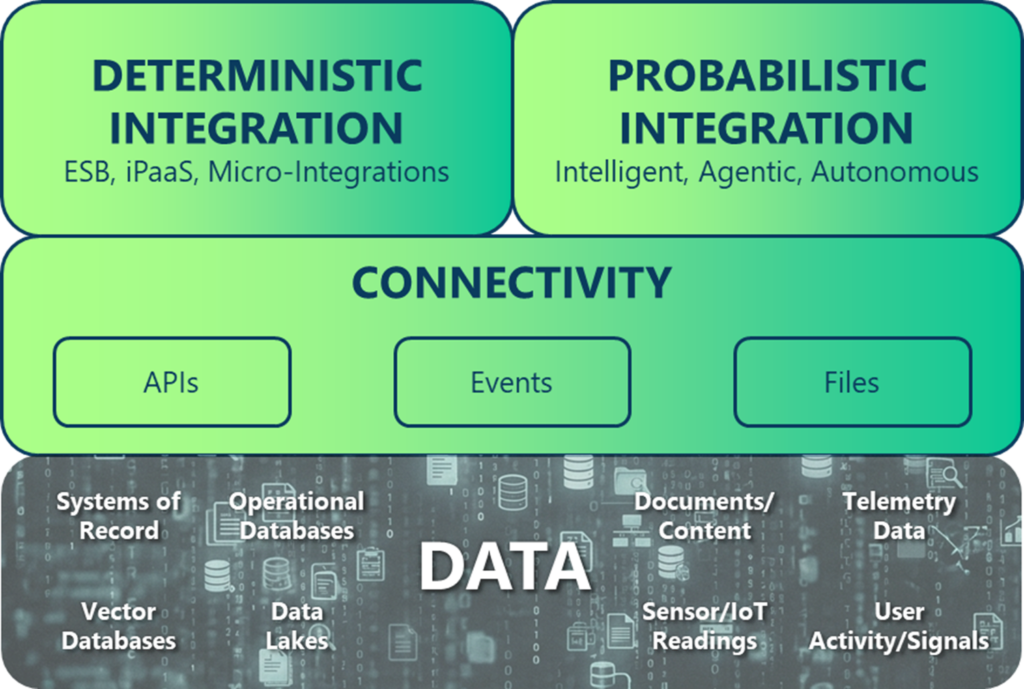
It All Starts with Connectivity
Connectivity is the foundational layer of all modern integration because it provides the raw access paths through which systems exchange information. Regardless of industry or architecture style, every integration ultimately depends on a reliable way to access data whether it’s at rest or in motion.
The connectivity layer is built from three primary primitives—APIs, events, and files—each serving a distinct and complementary purpose.
- APIs offer synchronous, on-demand access to structured data and controlled operations.
- Events provide real-time, asynchronous streams of state changes that enable low-coupling and reactive behaviors.
- Files—from batch extracts to documents to flat-file transfers—remain essential for high-volume payloads, regulatory reporting, inter-organization exchange, and systems that cannot expose APIs or real-time feeds.
Together, these modes of connectivity form the universal backbone of integration, ensuring that data can be accessed, shared, synchronized, and consumed across the entire enterprise, regardless of the higher-order processing or intelligence applied above them.
As previously discussed, enterprises leverage the data and connectivity layer for higher order business processes which can be deterministic or probabilistic or a blend of the two. It is important to understand each of these workflow styles.
Deterministic Workflows…Still a Critical Component of Business
Deterministic integration workflows—those in which incoming data leads to a guaranteed, predictable output—still form the backbone of core business operations. Examples include payment processing, inventory adjustments, safety-critical IoT telemetry, compliance-driven data flows, and transactional processing. These systems demand strict ordering, exactly-once semantics, and verifiable end-to-end delivery.
Traditional integration platforms were designed primarily for this category, where logic is predefined, outcomes are repeatable, and errors must be eliminated—not tolerated or “interpreted.” This is historically the world in which we as integration and/or system architects have lived in for decades. It is comfortable but that comfort comes at a price (time, money and effort).
The AI-Centric Advent of Probabilistic Workflows
However, modern enterprises are increasingly embracing probabilistic workflows, where data is ingested, processed and results in an interpreted output, shaped by AI reasoning, historical patterns, and unstructured inputs. These include LLM-powered document extraction, customer intent detection, fraud scoring, predictive maintenance, and dynamic content generation.
These workflows do not guarantee a single correct answer; instead, they produce the best possible answer given the available context. They require access to large volumes of historical data, embeddings (representations of real-world data like text, images, or audio), vector stores, and contextual signals spread across cloud systems, SaaS platforms, devices, and enterprise data lakes. The lack of contextual signals will reduce the probability of a correct, relevant result, as does dirty or incorrect data. Thus, while this is an incredibly exciting and promising capability, it, itself requires rigorous data management and integration controls.
Many probabilistic workflows are autonomous, which introduces an entirely new operational model. Here, software agents and AI systems not only interpret data, but decide the next action, plan multi-step tasks, and execute workflows end-to-end. These systems require event-driven triggers, real-time context, policy-based control, and the ability to coordinate across distributed systems and clouds.
Unlike deterministic systems, autonomous workflows need freedom to explore. And unlike many probabilistic systems, they must take action; and unlike traditional integration, they do not follow fixed data mappings, workflows, or BPMN diagrams. They operate continuously, learn from feedback, and adapt to evolving business conditions—often without human intervention.
Why Integration Needs to Evolve
Traditional integration tools—ESBs, iPaaS platforms, ETL pipelines, and point-to-point APIs—were not built to simultaneously support the three fundamentally different paradigms of APIs, events and files. They tightly couple logic to endpoints, assume synchronous request/response patterns, and cannot elastically scale to real-time, data-rich, agent-driven environments. They excel at deterministic processing but struggle with probabilistic reasoning and are incompatible with autonomous agents that require asynchronous, event-driven, dynamic orchestration.
This is why the integration layer must evolve to accommodate
- Deterministic integration for reliability, ordering, and transactional guarantees. This requires the use of the data and connectivity layer, along with traditional integration workflow capabilities
- Probabilistic integration for unstructured data processing, prediction, and agentic AI for multi-step decision-making and action execution. It also leverages the data and connectivity layer in order to gain access to data for context.
Together, these layers create an enterprise capable of reacting instantly, thinking intelligently, and executing reliably. Events spark real-time reactions and helps to keep data context up to date. APIs ensure precise ad-hoc query results and predictable updates. AI-driven interpretation unlocks understanding and contextual awareness. agentic AI unifies all three—listening to events, invoking APIs, leveraging AI reasoning, and coordinating complex business processes. This architecture enables the modern enterprise to function not simply as a collection of integrated systems, but as an intelligent, responsive, and adaptive ecosystem.
Data Access and Connectivity;
APIs, EDA and Files
APIs – On Demand, Controlled
APIs form the structural foundation of deterministic integration by enabling systems to communicate through explicit, contract-defined interfaces. Architecturally, an API represents a callable endpoint—typically exposed through a gateway—that either:
- Performs an operation
- Retrieves data
- Enforces a business rule
Behind the scenes, APIs route requests to microservices, serverless functions, or backend systems that contain the logic and authority required to validate and process the request. This request–response pattern forms a predictable, synchronous exchange in which the caller depends on the provider to perform an action and return a definitive result.
The evolution of API technologies reflects the broader transformation of enterprise integration. Early models such as CORBA and SOAP/WS-* attempted to create universal standards with strict schemas, service definitions, and rigid typing. While powerful, they were often complex and difficult to scale across heterogeneous environments.
More recent innovations have emerged to address modern needs. Each of these protocols remains relevant today because each solves a distinct problem.
- REST revolutionized this landscape by embracing simplicity—leveraging HTTP verbs, lightweight JSON payloads, and stateless calls to create a flexible, developer-friendly model. It remains the de facto standard for public and partner-facing interfaces due to tooling maturity and readability.
- GraphQL provides client-driven data shaping for front-end efficiency. GraphQL shines in complex data retrieval scenarios where clients benefit from specifying exactly what they need.
- gRPC enables high-performance binary communication for internal service-to-service interactions. gRPC excels in distributed, latency-sensitive application architectures.
Even SOAP, though older, continues to power mission-critical legacy systems in finance, government, and telecom due to its strong schema enforcement and historical legacy. The modern API landscape is therefore pluralistic, optimized around specific performance, flexibility, or compatibility constraints.
However, the consistent characteristic across all API models is endpoint coupling. APIs create a direct, synchronous dependency between the caller and provider, as both parties must:
- Be available
- Agree on the schema
- Evolve in lockstep
- Maintain aligned expectations regarding performance, behavior, and error handling.
This point-to-point communication model can scale poorly as integrations proliferate. Each new integration adds operational overhead—versioning coordination, backward compatibility constraints, dependency management, and lifecycle governance. While API gateways, service meshes, and schema registries help mitigate these challenges, they cannot eliminate the intrinsic coupling created by synchronous invocation.
Therefore, APIs continue to excel in deterministic, transactional operations, but they also highlight why enterprises need architectures beyond the API exclusive paradigm. As systems become more distributed, event volumes rise, and AI-driven non-deterministic reasoning becomes essential, APIs remain critical but insufficient on their own.
This reinforces the strategic need for a comprehensive data and connectivity approach:
- APIs for ad-hoc queries and commands
- Events for communication of changes and real-time scale
- Files for large, binary and unstructured data along with integration with legacy systems.
When to Use APIs
Use APIs when you need determinism, explicit authorization, and immediate confirmation. Typical scenarios include payments, account updates, inventory adjustments, reads/writes that require ACID-like reasoning or idempotent semantics, and UI-driven fetches that must return a fully-formed response. APIs are also the right choice when you must apply centralized policies (authn/authz, quotas, request validation) at a single enforcement point.
When to NOT Use APIs
Avoid (or complement) APIs when you face high fan-out distribution, many independent subscribers, or extremely high-velocity telemetry data where synchronous polling would create bottlenecks. APIs are poorly suited as the only pattern when multiple consumers need the same state change simultaneously (fan-out), when downstream availability must not block producers, or when you need durable stream processing and replay semantics. In those cases, an event stream or file-based bulk transfer (for large payloads or batch reconciliation) is a better primitive; APIs can remain available for contextual enrichment or authoritative queries.
Finally, keep in mind operational coupling: APIs create runtime dependencies (availability, latency, schema) between client and provider. As your number of APIs grows, so does the need for strict versioning, contract governance, backward compatibility, test harnesses, and observability. For UI-driven use cases, consider GraphQL or backend-for-frontend patterns to reduce over/under-fetching; for high-throughput internal RPC, prefer gRPC and optionally complement it with a service mesh for resiliency.
Vendor Landscape
When evaluating vendors, split your requirements across functional areas: API gateway & management and runtime gateway/proxy. Below are these categories and representative vendors you should solicit from:
API Management & Gateway
For full lifecycle API management (catalog, developer portal, policy enforcement, analytics):
- Gravitee, Apigee (Google)
- MuleSoft (Salesforce)
- Kong
- Tyk
- WSO2
- IBM API Connect
- AWS API Gateway / Azure API Management for cloud-native footprints.
Runtime Proxies and High-Performance Gateways
If raw throughput and low-latency processing are critical, solicit NGINX/NGINX Plus, Envoy-based edge proxies, or vendor gateways built atop these technologies. These are often paired with control planes (e.g., Kong control plane) to separate policy from data path.
Event-Driven Architecture – React in Real-Time
Event-driven architecture (EDA) is a distributed integration pattern in which systems communicate through the production, brokering, and consumption of events rather than through direct synchronous calls.
Where APIs enforce synchronous, deterministic interactions, by enabling systems to react to change without tight coupling or coordination, EDA enables systems to operate beyond deterministic execution—supporting real-time responsiveness and the flow of context required for probabilistic reasoning.
An event represents a state change—something that happened—such as OrderCreated, DeviceStatusUpdated, or CustomerPreferenceChanged. Producers publish these events to an event broker, which reliably routes them to any number of subscribers without the producer needing awareness of the consumers. This eliminates point-to-point coupling and enables horizontal scale, geographic distribution, and true asynchronous behavior.
From an architectural standpoint, EDA centers around the event broker (often an event mesh composed of many event brokers), which routes information across cloud, on-prem, and edge environments. Consumers can process data, as events, in real time, enrich them, trigger workflows, invoke APIs, or generate new downstream events. This architecture is especially effective in distributed systems where latency, fault tolerance, and runtime decoupling are critical. A mature EDA ecosystem typically includes interface specification schemas (AsyncAPI), governance processes, event catalogs, replay or persistence capabilities, and guaranteed delivery semantics depending on the broker.
When to Use EDA
EDA is the optimal pattern when your use case requires real-time responsiveness, loose coupling at runtime, or multi-consumer data fan-out. Use EDA when:
- State changes need to be propagated instantly across many systems.
- IoT devices must stream telemetry at scale.
- Microservices require decoupling to avoid API dependency chains.
- Workflows begin from events rather than from requests (reactive architectures).
- Systems must continue functioning even when downstream components are unavailable.
- You need to support global distribution or edge-to-cloud messaging.
- You require replay, temporal analytics, or streaming patterns.
When to Not Use EDA
However, EDA is not well-suited for scenarios requiring synchronous confirmation or where a single, authoritative response must be returned. Do not use EDA when:
- A client needs immediate success/failure acknowledgment.
- Integrating with legacy systems incapable of consuming asynchronous messages.
- End-to-end business process requires sequential execution.
EDA complements but does not replace APIs or synchronous workflow orchestration. It excels at notification, distribution, streaming, and decoupling, while APIs handle synchronous commands and queries and AI handles interpretation and reasoning.
Vendor Landscape
The EDA ecosystem includes several categories of vendors: enterprise-grade event brokers, streaming platforms, message queues, and event mesh technologies. Integration architects evaluating options should consider delivery guarantees, performance, geo-distribution, topic scalability, protocol support (MQTT, AMQP, REST, JMS, WebSocket), governance capabilities, and operational maturity.
Enterprise Event Brokers
- Solace – High throughput, enterprise-grade event mesh, strong multi-protocol support (MQTT, REST, AMQP, JMS), event governance tooling, and advanced routing (including ordering guarantees). Ideal for hybrid and global architectures.
- IBM / Confluent (Apache Kafka ecosystem) – Strong for event streaming and log-based persistence; ecosystem includes schema registry, ksqlDB, and connectors. Best for analytics pipelines and durable streams.
- Redpanda – Kafka API–compatible, high-performance, cloud-native streaming platform. Simplifies Kafka operational overhead.
- Pulsar (Apache Pulsar, StreamNative) – Segment-based storage, multi-tenancy, and geo-replication built-in. Suitable for distributed systems where long term event retention and replay is needed.
Traditional Messaging / Queuing Systems
- RabbitMQ – Versatile, lightweight AMQP-based broker. Strong routing, but not ideal for very high throughput or large event meshes.
- ActiveMQ / Artemis – Enterprise queuing with JMS support; more appropriate for message queue use cases than large-scale, distributed event distribution.
Cloud-Native Event Services
- AWS SNS/SQS & EventBridge – Good for cloud-native pub/sub and integration with AWS services. Limited in cross-cloud/hybrid scenarios.
- Azure Event Grid / Event Hubs – Suitable for Azure-centric architectures; Event Hubs focuses on streaming.
- Google Pub/Sub – Scalable cloud messaging for GCP workloads.
Integration architects should choose the event platform based on latency, throughput, delivery guarantees, topology (mesh vs. centralized), governance, and hybrid-cloud capability. The right broker becomes the backbone of a responsive, decoupled enterprise integration strategy.
Files – Primitive yet Useful
File-based integration remains one of the most pragmatic and widely used means of connectivity in enterprise landscapes. At the user level, we all use files in order to document things using all sorts of freeform text.
At its simplest, a file is a self-contained payload (CSV, XML, JSON, fixed-width, PDF, image, archive, etc.) that is written by a producer (human or system) and later read by a consumer (human or system).
Architecturally, from a system integration perspective, file flows typically follow a small set of common patterns:
-
- Producers write to a landing zone (FTP/SFTP, AS2 mailbox, cloud object store, or an MFT endpoint)
- An ingestion layer (pollers, event notifications, or managed-transfer agents) detects the file and either:
- pushes it into downstream processing (ETL, streaming conversion, an integration engine)
- stages it for batch consumption.
Files can be sent directly between partners (B2B), exchanged via secure drop zones, or deposited into cloud object stores (S3/Blob) where downstream services pick them up on change notifications. Because files are durable and self-describing, they are ideal for large payloads and batched workloads where transactional semantics are achieved through control files, manifests, or compensating processes rather than synchronous commits.
Increasingly, unstructured text, in a variety of file formats are used and ingested into AI systems to provide additional context (this will be discussed more in later sections).
When to Use File-Based Integration
Use file-based integration when:
- Large payloads or binary assets (media, high-volume extracts, imagery) must be transferred efficiently.
- Batch processing/ETL is appropriate (nightly reporting, bulk imports, wholesale data syncs).
- Legacy partners or systems cannot expose APIs or event streams and require FTP/SFTP/AS2.
- Regulatory or archival workflows require immutable, auditable artifacts.
- Intermittent connectivity exists (edge devices, remote branches) where offline writes are synchronized later.
- Unstructured Data is key in order to provide AI systems context, provided by human created file documents.
When to Not Use File-Based Integration
Avoid using files as the primary integration primitive when:
- Low-latency, real-time responses are required; events or APIs are better suited.
- Fine-grained, transactional operations demand immediate acknowledgment or atomic commits.
- Many consumers must react in real time to state changes; an event stream (EDA) scales better and avoids polling-based inefficiency.
Integration Workflows:
Deterministic and Probabilistic
Above the foundational layer sits the integration layer, where data is processed, transformed, enriched, and orchestrated into meaningful outcomes. This layer is now composed of two distinct modes of integration, each essential in the modern enterprise. These are described as deterministic workflow integrations and probabilistic workflow integrations. Each will be further discussed, defined and analyzed in the sections below.
Deterministic Workflow Integrations
Deterministic workflow integrations (sometimes referred to as orchestrated, process-centric or prescriptive integrations) consist of steps, decisions, and outcomes that are explicitly defined, centrally managed, and predictably executed.
Although deterministic workflow integrations are often associated with centrally orchestrated processes—ESBs, iPaaS flows, service orchestrators, BPM engines—the definition of “deterministic” is broader. Determinism refers to the predictability of outcomes given a fixed set of inputs and rules. That predictability can be achieved not only through orchestration but also through event-driven choreography, where distributed services each follow predefined rules in response to events.
At their core, deterministic workflow engines execute a directed or asynchronous flow:
- Trigger: API call, schedule, file drop, event
- Transformation & Routing: data mapping, branching logic
- System Interactions: REST/SOAP calls, database ops, message broker actions, file operations
- Compensation or Recovery: rollbacks, retries, error subprocesses
- Auditing & State Management
Event-driven systems are sometimes mistakenly perceived as “less deterministic” because they are asynchronous and distributed. In reality, EDA supports deterministic workflows through choreography rather than orchestration:
- Each service reacts to events based on predefined behavioral rules.
- The overall workflow emerges from these independent but predictable reactions.
- The system remains asynchronous, with no central controller.
- Outcome is deterministic, but timing and ordering may be governed by eventual consistency rather than synchronous execution.
In other words:
- Orchestration: deterministic sequencing controlled by a central engine
- Choreography: Deterministic sequencing distributed across event-driven services
Both patterns can achieve the same functional result. The difference lies in how the steps are coordinated:
- Orchestration: “Do step A → then B → then C — I control the process.”
- Choreography: “When an order is created, publish Created; fulfillment reacts automatically, billing reacts automatically, notifications react automatically.”
Both are deterministic; choreography simply embraces loose coupling, parallelism, and eventual consistency.
Evolution of the Pattern in the Enterprise
The deterministic workflow pattern has evolved alongside shifts in integration technology:
- ETL (1990s–2000s): Early integration was dominated by batch ETL tools (Informatica, DataStage, Ab Initio). These provided deterministic flows, but mostly for data movement rather than system-to-system process orchestration. Still, their visual mapping and job pipelines laid foundational patterns.
- ESB Era (2005–2015): Enterprise Service Buses (Mule ESB, TIBCO BusinessWorks, IBM Integration Bus, WSO2) formalized the concept of centrally managed, deterministic service orchestration. ESBs embedded workflow-like constructs—mediation flows, sequential processors, error paths—while promoting service reuse across the enterprise.
- iPaaS (2014–Present): Integration Platform-as-a-Service (Boomi, MuleSoft Anypoint, Workato, SnapLogic) democratized workflow automation in cloud environments. These platforms provided drag-and-drop flows, API-led connectivity, lifecycle management, and hybrid deployment patterns.
- Framework-Based Integration (Ongoing): Software-based integration frameworks (Spring Integration, Apache Camel, Micronaut, Node.js workflow libraries) brought deterministic flows into application code. They offered fine-grained control, programmability, and microservices alignment—appealing for teams consolidating away from large ESBs/iPaaS in favor of cloud-native architectures.
Today’s Enterprise Reality
Most enterprises now have multiple overlapping integration platforms—an ESB still running core flows, an iPaaS for SaaS connectivity, Event Brokers/Event Mesh for choreography between information systems, code-based integrations embedded in microservices, and automation platforms used by business teams.
This creates:
- Redundant orchestration engines
- Duplicated connectors
- High licensing costs
- Governance sprawl
- Difficulty standardizing patterns
As cost and tool consolidation accelerates, deterministic workflows remain a core architectural capability, but the implementation platform is increasingly under scrutiny. Many organizations now evaluate whether to centralize deterministic workflows into a modern integration platform, replace them with more event-driven patterns, or embed them into domain-focused microservices.
When to Use Deterministic Workflows
Use deterministic workflows when the integration scenario requires:
Explicit Control Over Sequence, State, and Decisions
If the business process requires step-by-step ordering, conditional logic, and guaranteed execution paths, deterministic orchestration is ideal. Examples:
- Account provisioning (create CRM → assign ID → create IAM record → send welcome email)
- Billing lifecycle flows involving multi-system validation
- Back-office operational sequences
Transactional Coordination Across Systems
When multiple systems must succeed or compensate together (pseudo-distributed transactions):
- Order capture + payment + fulfillment
- HR onboarding workflows
- Multi-step data enrichment operations
High Degrees of Observability, Auditability, and Compliance
Deterministic workflows provide:
- Flow instance history and end to end traceability
- Step-level success/failure
- Input/output payloads
- SLA tracking
- This is essential for regulated industries, SOX traceability, and mission-critical operations.
Low-Variance, Repeatable Processes
If a process consistently follows the same path—daily, weekly, or triggered by a specific API—deterministic flows enforce consistency and reduce operational drift.
Gatekeeping and Orchestration for Legacy Systems
For systems lacking APIs, real-time eventing, or the ability to manage state, deterministic workflows provide the “glue” logic that modernizes how they interact.
High-Volume, Low-Latency Processing is Required
Event based, Choreographed workflows can help you with:
- extremely high throughput
- sub-second latency
- massive parallelism
When to Not Use Deterministic Workflows
Avoid deterministic workflows when:
- Explorative decision making is needed.
- There’s a tolerance for “creative” out of the box result.
- A need to react to changing contexts dynamically without intervention
Process Logic Belongs in the Domain (DDD)
If the workflow represents core domain logic, it often belongs in the domain service itself, implemented with frameworks like:
- Spring Boot + State Machine / Spring Integration
- Apache Camel routes
- Microservice orchestrators in code
This is especially true in cloud-native architectures where domain ownership is emphasized.
Heavy Vendor Lock-In or Licensing Concerns Exist
Central workflow platforms (ESBs/iPaaS) can drive high recurring costs. If financial consolidation is a priority, embedding workflows in services—or shifting simple flows to event-driven models—may reduce dependency on expensive tooling.
Be Mindful: The Enterprise Is Shifting Toward “Choreography Over Orchestration”
Modern distributed architectures increasingly prefer decentralized intelligence. Over orchestrating can create:
- Bottlenecks
- Single points of failure
- Coupling at the wrong layer
Probabilistic Workflow Integrations
Probabilistic integrations introduce AI-driven reasoning, interpretation, and decision-making into workflows. Instead of strict, predefined rules, these workflows rely on LLMs and AI agents to evaluate unstructured inputs, generate insights, and choose actions.
Probabilistic workflow integrations extend traditional deterministic models by incorporating AI reasoning, historical patterns, and unstructured data interpretation. Unlike deterministic workflows—which guarantee a single, predictable output—probabilistic workflows ingest inputs and produce outputs that reflect the most likely or optimal outcome given the available context. Typical use cases include:
- LLM-powered document extraction and summarization
- Customer intent detection and dynamic personalization
- Fraud scoring and risk assessment
- Predictive maintenance and anomaly detection
- Dynamic content generation
Probabilistic workflow integration relies on three deeply interconnected capabilities that collectively enable intelligent, adaptive, and context-aware automation. It requires:
- Real-time contextual data, delivered through the data access and connectivity layer, so that AI systems can reason not just on historical patterns but on what is happening right now.
- LLM and AI model providers—including text, multimodal, embedding, and predictive models—that together form the Probabilistic Reasoning Engine, capable of interpreting unstructured inputs, inferring intent, generating insights, and making best-effort predictions rather than deterministic outputs.
- Agentic AI layer which transforms data (or prompts) into actions through reasoning by selecting next steps, generating multi-step plans, coordinating tasks, and interacting with downstream systems using APIs and events.
These three components—contextual awareness, probabilistic reasoning, and agentic execution—combine to create AI-driven workflows that can understand, adapt, and act within complex enterprise environments.
Contextual Data
Probabilistic workflows rely heavily on large-scale contextual data such as business events, historical transaction logs, enterprise data lakes, vector embeddings, SaaS platform data, and IoT telemetry. Accuracy depends on the completeness, cleanliness, and recency of this data (thus a strong driver for increasing real-time, event-driven data). Poor quality or missing signals reduce the probability of achieving relevant outcomes.
Contextual data enters the AI ecosystem through the Data Access and Connectivity Layer, which exposes enterprise information through APIs, events, and files. In modern architectures, real-time events are the most valuable source of context because they reflect what is happening now: a customer action, a system change, a device reading, or an operational milestone.
These events—along with API responses and scheduled file drops—flow into a Data Ingestion Layer that normalizes, enriches, and prepares data for downstream AI use. The ingestion layer acts as the bridge between raw enterprise information and AI-ready semantic representations, handling structured data (transaction records, telemetry, profile attributes), semi-structured data (JSON events, logs), and unstructured content (documents, emails, call transcripts, images).
Once ingested, data is routed to the vectorization and embedding layer, where large language models and multimodal encoders convert both structured and unstructured inputs into dense vector embeddings that capture meaning, relationships, and intent. These embeddings allow AI systems to reason across data sources, correlate historical and real-time signals, and understand context far beyond what deterministic mappings can support.
The quality and timeliness of data from the data access and connectivity layer directly influences the performance of probabilistic workflows: real-time events keep the AI aware of what is happening now, while historical API-fetched data and document-based context ensure it knows what has happened before. Together, this creates a continuously updated semantic foundation upon which intelligent, agentic workflows can operate.
Probabilistic Reasoning Engine
The probabilistic reasoning engine (PRE) is the intelligence core of modern AI-driven integrations. It is composed of one or more LLMs, multimodal models, embedding models, and domain-specific AI systems that collectively interpret inputs, infer meaning, and generate probabilistic outputs. Unlike deterministic logic engines, which rely on fixed rules, this layer produces context-dependent best-effort answers—summaries, classifications, recommendations, extractions, or predictions—based on both real-time signals and historical data.
Accessing these models is increasingly standardized through APIs defined by organizations such as OpenAI, Anthropic, Google, AWS, and open-source model vendors. These standards allow enterprises to flexibly invoke models, chain reasoning steps, and integrate outputs into larger orchestrated or agentic workflows without being locked into a single provider.
Enterprises determine how they want to use this reasoning layer based on their governance, security, and data-sovereignty requirements. Some organizations choose to consume commercial models as cloud services, benefiting from continuous improvements, multimodal reasoning capabilities, and global scalability. Others adopt a hybrid approach, running smaller models locally for sensitive data while accessing models in the cloud for higher-value reasoning tasks.
Highly regulated industries—such as finance, healthcare, and defense—may adopt a fully self-hosted or fine-tuned model strategy, training internal LLMs on proprietary datasets to maintain strict control over model behavior, guardrails, and data privacy. Regardless of deployment choice, enterprises must establish clear governance around model selection, access rights, safety policies, auditing, and ongoing evaluation to ensure the Probabilistic Reasoning Engine remains trustworthy, compliant, and aligned with business objectives.
Decision & Action Layer
The decision and action layer is where probabilistic insight becomes operational reality. Sitting above the PRE, this layer interprets AI-generated insights and transforms them into action plans, multi-step workflows, and real-world system interactions. It is responsible for orchestrating the next best actions, invoking downstream systems via APIs, emitting events to trigger additional processes, and coordinating across distributed cloud environments. In its full capability, this layer powers autonomous workflows, where agentic AI systems continuously observe the environment, reason over contextual signals, and execute actions end-to-end—adapting dynamically as conditions change. This is the core of agentic AI: the ability to act autonomously, not just analyze.
To operate effectively, the decision and action layer requires event-driven situational awareness, policy-based control frameworks, and well-defined guardrails that ensure every action adheres to enterprise rules, safety constraints, and compliance standards. Events provide the real-time triggers—such as a customer request, a system change, or an operational anomaly—that activate agents and contextualize their decisions. Policy engines define what an agent may or may not do, specifying acceptable actions, data scopes, escalation paths, and rollback procedures.
Additionally, organizations must implement rigorous testing, evaluation, and validation methodologies to ensure that each agentic decision meets the necessary probabilistic accuracy and safety threshold before executing in production systems. This includes sandbox testing, simulation environments, human-in-the-loop approval patterns, and ongoing performance monitoring through continuous benchmarking and the use of advanced evaluation frameworks.
A key concept in this layer is the difference between dynamically generated task plans and prescriptive agentic workflows.
- Dynamically generated task plans allow agents to receive stimuli in the form of a prompt and break it down to construct multi-step workflows based on context, real-time data, available tools, and reasoning. These plans are fluid, adaptive, and capable of handling novel or highly variable situations.
- Prescriptive agentic workflows, in contrast, provide a structured, predefined sequence of steps. The agent still uses AI for reasoning—such as selecting options, interpreting documents, or making recommendations—but must operate within a fixed workflow shell. This model is ideal for use cases requiring higher control, more predictable outcomes, and firmer compliance boundaries. They can also drastically increase result consistency and correctness as it reduces the surface in which AI could act and ultimately hallucinate.
In today’s solution landscape, enterprises have multiple approaches to implementing this decision & action layer. Cloud-based platforms like OpenAI’s Agent APIs, Anthropic’s tool-use agents, Google’s Vertex AI Agents, and AWS’s Agents for Bedrock offer turnkey decision and action orchestration. Open-source frameworks such as LangChain, LangGraph, Semantic Kernel, and Microsoft Autogen provide customizable runtimes for building tailored in-house agents.
Uniquely positioned in this ecosystem is Solace Agent Mesh, which brings a data-centric and event-driven perspective to agentic AI. Rather than treating agents as isolated reasoning units, Agent Mesh focuses on real-time data movement, contextual awareness, and distributed agent coordination across hybrid and multi-cloud environments.
By leveraging an event mesh built with Solace Event Brokers as the underlying substrate, Agent Mesh enables agents to publish, subscribe, and react to live business events with extremely low latency—ensuring that decision-making is based on the most current information available. It natively supports rich event-driven triggers, distributed session state, policy-controlled inter-agent communication, and backpressure-aware data flows. This makes it highly suited for autonomous workflows where agents must continuously receive signals, collaborate, and take action across multiple systems and clouds.
Solace’s emphasis on data governance, observability, and ordered event delivery gives enterprises the confidence that agentic decisions are backed by reliable, interpretable, and well-managed data—an essential requirement for safe and effective autonomous operations.
When to Use Probabilistic Workflows
Use probabilistic workflows When:
- Inputs are unstructured (text, documents, images, audio) or highly variable
- Outcomes depend on inference, prediction, or interpretation
- Systems must summarize, recommend, or detect patterns from historical and contextual data
- Multi-step decisions require AI-driven reasoning or dynamic prioritization
- Autonomous agents need to plan and execute distributed workflows
When to Not Use Probabilistic Workflows
Avoid probabilistic workflows When:
- Deterministic, transactional consistency is required (payments, system-of-record updates)
- Workflows demand a single, fully predictable outcome
- Inputs are minimal, structured, and easily mapped using traditional API or ETL pipelines
- Real-time latency constraints prevent iterative reasoning or multi-step planning
- Regulatory or audit constraints prohibit probabilistic reasoning without verifiable outcomes
Probabilistic workflows complement deterministic and event-driven workflows but do not replace them. Integration architects must carefully balance reliability, interpretability, and AI-driven flexibility.
Vendor Landscape
The ecosystem for probabilistic workflow integration includes AI platforms, LLM providers, agent orchestration tools, and supporting infrastructure:
LLM & AI Model Providers:
- OpenAI (GPT models)
- Anthropic (Claude)
- Google (Gemini/PaLM)
- Cohere, Mistral, LLaMA (open weights)
Agentic & Autonomous Workflow Platforms:
- Solace Agent Mesh (orchestrates AI agents across events and APIs)
- AWS Agent Core (runtime for autonomous AI agents)
- LangGraph (framework for LLM-based agent orchestration)
- CrewAI
- AutoGen
- Reflex
Vector, Embeddings, and Knowledge Stores:
- Pinecone, Weaviate, Milvus (vector DBs for embedding storage)
- FAISS (open-source vector search)
- Redis Vector
- Vespa.ai
The Synergy of Deterministic and Probabilistic Workflows
Modern enterprise integration requires more than choosing between deterministic or probabilistic processing. The reality is that both paradigms must work together, each contributing distinct strengths to end-to-end business workflows. Deterministic workflows excel at precision, transactional updates, governance, and repeatability; probabilistic workflows thrive in ambiguity, unstructured data, contextual interpretation, and AI-driven reasoning. When combined, they form a hybrid architecture capable of delivering both rigid operational consistency and flexible cognitive intelligence.
At the foundation of both models is the data and connectivity layer, composed of APIs, events, and files. This layer provides the raw materials—data access, system connectivity, and real-time signals—that both deterministic and probabilistic systems depend on. Deterministic systems consume data through synchronous APIs, event subscriptions, or scheduled file ingestion to drive well-defined workflows. Probabilistic systems use the same sources, but require deeper context: historical data, embeddings, metadata, logs, documents, and real-time signals to reason effectively. In this sense, the data and connectivity layer serves as the single, shared substrate that enables both workflow types to operate and collaborate.
Importantly, deterministic workflows will increasingly invoke probabilistic workflows when encountering unstructured inputs or tasks that require interpretation. For example, a deterministic order-processing workflow may call an LLM-powered service to classify an inbound customer request, generate a compliance report, evaluate sentiment, extract fields from a PDF, summarize contractual obligations, or interpret natural-language instructions. Here, deterministic processes act as orchestrators, delegating “cognitive sub-tasks” to probabilistic services before returning to the governed, predictable path.
Conversely, probabilistic workflows and autonomous agents will increasingly invoke deterministic systems—especially when actions must be executed reliably, safely, and traceably. agentic AI systems can interpret complex scenarios, decide what needs to be done, and plan multi-step tasks. But when it comes time to update a system of record, submit a transaction, create a case, trigger a fulfillment workflow, or perform a state-changing operation, these agents will call deterministic integration endpoints (API workflows, iPaaS orchestrations, micro-integrations, or event-driven services). This ensures that even though the reasoning may be probabilistic, the resulting actions adhere to enterprise standards for data integrity, consistency, and compliance.
This interplay creates a closed-loop architecture: deterministic workflows invoke probabilistic reasoning to interpret the world; probabilistic workflows invoke deterministic engines to act on that interpretation. Both rely on the same underlying data and connectivity Layer to acquire the signals they need to operate. Together, they form a resilient and adaptive integration ecosystem—combining the precision of traditional system integration with the intelligence and autonomy of modern AI systems.
Reference Architecture – Airline Flight Delay
The following airline flight delay scenario illustrates how this architecture operates in practice. A single operational event—a delayed flight—triggers both deterministic and probabilistic workflows, each playing a distinct role. Deterministic integrations handle the authoritative, regulated, and transactional actions required to keep operations safe and compliant, such as crew legality checks, flight plan updates, and booking changes.
In parallel, probabilistic and agentic workflows interpret broader context—passenger itineraries, connection risk, loyalty status, baggage state, and historical patterns—to assess impact, prioritize responses, and recommend next-best actions. Together, these layers show how modern integration architecture can combine real-time responsiveness, intelligent reasoning, and reliable execution in a single end-to-end business process.
High-Level Business Flow
- A carrier system (aircraft telemetry / ops) publishes a FlightDelayed event into the event mesh (Data and connectivity layer).
- Deterministic workflows consume the event immediately to ensure regulatory and safety obligations are met: update crew duty scheduling (must verify crew legal hours), produce and file an amended flight plan with the FAA, and lock critical operational changes. These steps must be reliable, auditable, and verifiable.
- In parallel, a probabilistic workflow (agentic AI) ingests the event plus historical/contextual signals (passenger itineraries, connection risk, loyalty status, spend, baggage info) to determine overall customer impact: who is most affected, who requires prioritized rebooking, best alternative routing suggestions, and personalized compensation offers.
- The agent generates rebooking plans and communications; for any rebooking action the agent invokes deterministic workflows (book new flight, cancel old reservation, return seat inventory, notify baggage system, and issue credits or certificates).
- All operations use the data and connectivity layer (APIs for synchronous operations, Events for distribution and state change notifications, Files for batch manifests or regulatory filings where necessary). Observability, audit logs, and guardrails are enforced across both layers.
Core Components
Here, and described below, are the components I’ll discuss in this example:
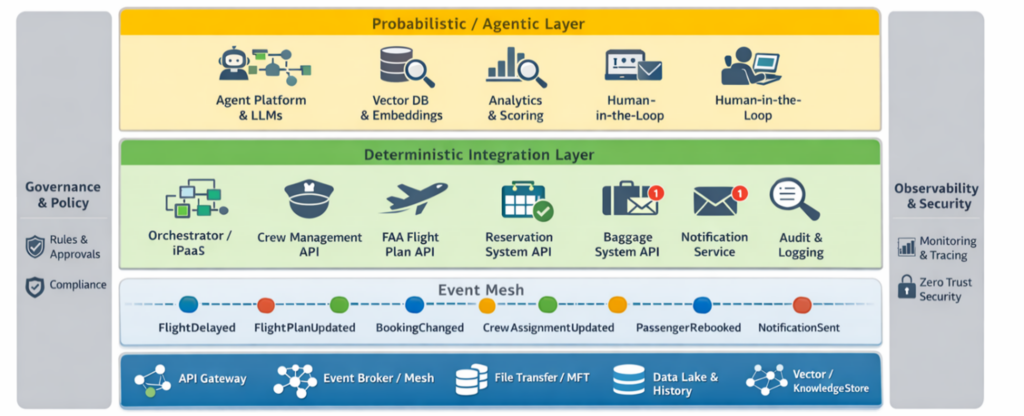
Data and connectivity Layer (shared substrate):
- Event Broker / Event Mesh: With topics such as
FlightDelayed,FlightPlanUpdated,BookingChanged,NotificationSent - API Gateway: Secure, authenticated endpoints for booking, crew scheduling, FAA submission
- File Exchange / MFT: FAA manifests or large passenger manifests, if required
- Data Lake & Historical Store: Flight history, connection statistics, customer transaction history
- Vector/Knowledge Store: Embeddings of customer interactions, policy texts, or prior resolutions
Deterministic Integration Layer (authoritative, transactional):
- Orchestrator / iPaaS: Boomi / MuleSoft-like flows or cloud workflow engine: Multi-step deterministic processes (FAA filing, crew scheduling updates, booking transactions
- Crew Management System (CMS) API: Authoritative for duty hour checks and crew assignments
- FAA Flight Plan Filing System (API): Needs guaranteed submission & receipt
- Reservation System / PSS (Passenger Service System) API: Deterministic booking/cancellation and seat inventory management
- Baggage System API / Interface: Update baggage routing instructions
- Notification Service (SMS/Email): synchronous send APIs or event-based notification engine
- Audit & Compliance Logging: immutable logs, message tracing
Probabilistic / Agentic Layer (Reasoning & Orchestration):
- Agent Platform + LLMs: Agentic AI runtime that can reason across signals, produce ranked rebooking plans, draft personalized messages
- Embeddings & Vector DB: Pinecone/Weaviate/Redis Vector) and RAG retrieval connectors (to pull past passenger behavior, rules, and prior rebooking decisions
- Analytics & Scoring Services: Connection risk scoring, priority scoring based on loyalty & spend
- Human-in-the-loop dashboard: For low-confidence decisions or policy overrides
Cross-cutting:
- Governance & Policy Engine: Safety policies: crew duty limits, FAA rules, approval thresholds
- Observability: Distributed tracing, event lineage, SLA monitors, model-performance dashboards
- Security: Zero-trust auth, fine-grained roles, signed events, encryption
Sequence of Events & Flows (step-by-step)
A flight delay triggers both deterministic operational workflows and AI-driven customer impact analysis, with authoritative systems executing final changes and outcomes feeding back into the architecture for continuous improvement.
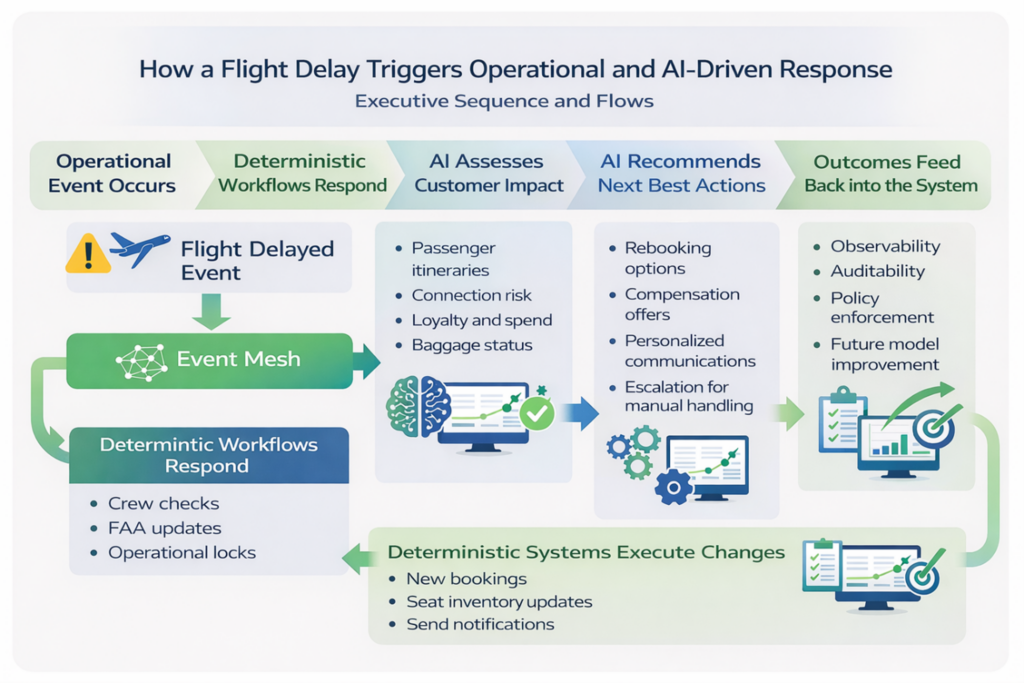
Phase A: Immediate operational response (Deterministic-first)
- Producer (flight ops system / aircraft telemetry) publishes FlightDelayed
- Event payload minimal: flight_id, scheduled_dep, new_est_dep, reason_code, location, timestamp.
- Deterministic Consumer #1 — Ops Orchestrator subscribes and triggers an orchestrated flow:
- Call Crew Management API: fetch assigned crew, evaluate duty hours (synchronous deterministic check). If crew cannot legally operate:
- Trigger crew re-assignment flow (reserve & notify replacement crew) — this is deterministic and must succeed before confirming flight continuation.
- Call FAA Filing API (or drop file to MFT if required by the FAA): create & submit amended flight plan, verify acknowledgment (receipt REQUIRED). This is regulatory-critical and must be logged with audit trail.
- Call Crew Management API: fetch assigned crew, evaluate duty hours (synchronous deterministic check). If crew cannot legally operate:
- While steps above are happening, the orchestrator publishes intermediate events (CrewCheckComplete, FAAFileSubmitted) so downstream systems know progress.
Constraint note: Crew availability and FAA filing are non-negotiable deterministic constraints — the flight cannot depart without satisfying these operations.
Phase B: Customer impact analysis (Probabilistic)
- Agentic AI subscribes to FlightDelayed and reads contextual data via the data and connectivity layer:
- Pull passenger manifest (API or file from PSS).
- Retrieve each passenger’s itinerary, connections, fare class, loyalty status and recent spend via APIs.
- Retrieve baggage routing status via baggage API and last-mile status.
- Query historical data (data lake) for typical rebooking latency impacts and rebooking success rates.
- Optionally retrieve CRM notes (unstructured), prior contacts, and sentiment embeddings.
- AI Agent performs probabilistic reasoning:
- Score each passenger’s connection risk and priority (e.g., top-tier loyalty, high-spend, medical needs).
- Generate a ranked list of rebooking strategies for groups: rebook on next available flight, rebook through partner carrier, issue vouchers, or manual handling.
- Prepare personalized templates for emails/SMS with computed offers.
- Compute confidence for each automated action. Low-confidence items are flagged for human review.
- AI Agent publishes decision events (
RebookingRecommendationCreated,HighImpactPassengerList) and provides payloads with recommended deterministic actions (e.g., book flight XXX for passenger Y).
Phase C: Action execution — deterministic calls by agents
- For each recommended rebooking with acceptable confidence, AI Agent calls deterministic booking APIs (PSS) to create new reservations:
- Call BookFlight API (synchronous) — ensure idempotency tokens to avoid duplicate bookings.
- If booking succeeds call CancelOldReservation and ReturnSeatInventory workflows (these are deterministic multi-step operations), update baggage system (reassign tags), and create a record in audit logs.
- Emit events BookingConfirmed, OldBookingCancelled, BaggageReassignmentRequested.
- For edge cases (no automated rebooking possible), the AI agent opens a task for a person (aka “human in the loop” or HITL) with suggested options and an SLA.
- After bookings are done, the system issues personalized notifications (deterministic or event-driven notifications) and publishes CustomerNotified events for downstream reporting, lounge access, or voucher issuance flows (files/APIs as needed).
Phase D: Feedback & learning
- All outcomes (successful rebook, failed rebook, customer satisfaction scores) are fed back into the event mesh and ultimately into the data lake and vector store. Models are retrained or evaluated for drift. Agent confidence calibration is updated to reduce future false positives/negatives.
Examples of Data and connectivity primitives used
FlightDelayedevent published to topicflight.status(Event)GetPassengerManifest(flight_id)(API) → returns list of PNRs and itinerariesFAASubmitAmendment(payload) (API or File to MFT) → returns ack token (deterministic)CrewDutyCheck(crew_id)(API) → returns legal/illegal to fly (deterministic boolean)BookFlight(pnr, route)(API) → returns booking reference (deterministic)RebookingRecommendation(Event) → consumed by booking engine or human ops- Passenger notification templates (Files or templated API payloads) → Notification API or Event to Notification Service
Failure Modes, Compensation & Guardrails
- FAA Filing Failure: orchestrator retries with exponential backoff; if no ack, triggers emergency ops with manual human intervention and marks flight as delayed/cancelled in systems. All actions are recorded (immutable audit).
- Crew Not Available: fallback to reserve relief crew; if none available, deterministic flow marks flight non-flyable and agent escalates rebooking to high priority.
- Booking API transient failures: use idempotency tokens and retry. If booking ultimately fails, agent marks passenger for manual handling and issues provisional notification.
- Agent Low Confidence: block automatic action; create HITL ticket in operator console with suggested actions.
- Data Quality Issues: if required contextual signals are missing (e.g., missing itinerary, corrupted manifest), agent uses conservative policy (prioritize safe operations, escalate to human). Data completeness affects probability & confidence—capture and surface this info.
Governance, Observability & Compliance
- Traceability: every event and API call includes correlation IDs to trace end-to-end from
FlightDelayedthroughBookingConfirmed. - Policy Enforcement: Governance engine enforces legal requirements (crew duty, FAA rules) and organizational policies (who can approve credits over $X).
- Model Explainability: agent stores reasoning & decision provenance (RAG passages, scores) to support contested customer service cases.
- SLA Monitors: monitor time-to-notify, time-to-rebook, FAA-ack latency, and crew re-assignment time.
- Security: secure event channels (mutual TLS), signed events for non-repudiation where needed (FAA), and strict role-based access for agent actions.
Design Rationale
We use deterministic integration methods to create purely predictable outcomes where regulations and organizational policy strictly apply. We augment those capabilities with probabilistic reasoning to handle uncertainty and complex decision making within specific domains when data inputs are unstructured and context variables are vast.
- Safety & Regulation First: Crew legal checks and FAA filings are deterministic and must be authoritative—no probabilistic replacements permitted for these steps.
- Scale & Personalization: Customer impact is complex and benefits greatly from probabilistic reasoning given many variables (connections, fares, loyalty). Agents can reason across these and produce prioritized rebooking options.
- Closed-Loop Guarantees: AI Agents produce suggested actions but invoke deterministic APIs to perform authoritative changes; this preserves auditability and prevents agents from performing untracked state changes.
- Resilience & Decoupling: Using Events for state changes and Notifications decouples consumers and keeps the system resilient if some components are slow or offline.
- Continuous Learning: Feedback from actual outcomes improves future agent decisions—crucial for reducing manual handling over time.
Practical Recommendations for Implementation
- Design idempotent deterministic APIs (booking, cancel) to allow safe agent retries.
- Emit events at every state transition so probabilistic systems have fresh signals without polling.
- Require explicit ack for regulatory submissions (FAA) and treat failures as blocking for departure.
- Define confidence thresholds for agent-auto-action vs human-handling. Log full reasoning for audit.
- Include a governance policy store accessible to agents so they can consult rules before action (e.g., max voucher amount).
- Instrument feedback loops (outcome -> model retraining) and ensure data quality processes for the data and connectivity layer.
Conclusion
Modern enterprises are undergoing a tectonic shift in how they integrate systems, coordinate business processes, and operationalize data. The explosive growth of cloud services, SaaS applications, IoT devices, real-time data streams, and AI-driven automation has pushed traditional, single-pattern integration approaches to their breaking point.
No single architecture—whether APIs, events, files, deterministic integrations, or AI-driven probabilistic workflows—is sufficient on its own to support the complexity, scale, and intelligence expectations of today’s digital businesses.
This whitepaper builds on the familiar architectural pattern:
- A data and connectivity layer composed of APIs, events, and files, which provides universal access to data across clouds, systems, and applications; and
- An integration layer that governs how work gets done.
This foundation remains intact and essential, but a fundamental shift is underway within the integration layer itself –a bifurcation into two complementary modes:
- Deterministic integration workflows, which provide reliability, precision, and compliance; and
- Probabilistic integration workflows, which bring intelligence, interpretation, and adaptability.
Together, these modes enable enterprises to both execute with certainty and reason under uncertainty. But the real power emerges when these layers operate as a unified, closed-loop architecture. Deterministic systems call probabilistic services when human-like interpretation is needed; probabilistic systems call deterministic services when real-world actions must occur safely and predictably. Both rely on the same data and connectivity layer for secure, consistent access to the enterprise’s information fabric. This creates a mesh of capabilities where structured and unstructured data, synchronous and asynchronous interactions, rule-based and AI-driven logic all coexist and reinforce each other.
The airline example demonstrates this clearly: a single FlightDelayed event cascades through deterministic workflows for crew management and FAA updates, probabilistic workflows for customer impact modeling and personalized communication, and agentic AI calling deterministic booking engines to reassign passengers and update operational systems. This is the future of enterprise integration—not a single architecture, but an ecosystem of complementary patterns working in concert.
As enterprises continue to adopt AI, automation, and distributed cloud architectures, the organizations that thrive will be those that use each of these tools for their ideal and intended purpose:
- APIs for access
- Events for awareness
- AI for understanding—and deterministic & probabilistic workflows for execution.
The integration landscape is no longer about pipes, mappings, and single-purpose platforms. It is now the operational backbone of the intelligent, autonomous enterprise. Companies that invest in this new architecture will unlock resilience, speed, personalization, and automation at a level previously impossible. Those that do not risk falling behind as data volumes surge, processes fragment, and AI-driven competitors accelerate.
The path forward is clear: build a composable integration foundation, pair deterministic reliability with probabilistic intelligence, and empower systems to react in real time, think with context, and execute with confidence. Integration is no longer a back-office IT concern—it is the engine of enterprise transformation.
