When it comes to event broker monitoring, it’s clear that there is no one tool to rule them all. While some of our customers use PubSub+ Monitor to monitor their event brokers, others build their own using tools such as ITRS Geneos, AppDynamics and Prometheus, just to name a few. For those building your own solution, the 5 considerations I’ll describe below will ensure that your event broker monitoring covers all the bases and sets you up for operational peace of mind.
To begin with, each monitoring tool will have its own method for collecting data from the systems and applications you wish to monitor. Then you create rules, alerts, and dashboards on top of that collected data. The examples in this post will be in the context of using ITRS Geneos, with the SolGeneos collector agent provided by Solace, but the ideas are transferrable to other monitoring tools.
1. Start Simple with Event Broker Status Monitoring
The first consideration is an easy one. The event broker itself has numerous status fields to inform on whether various aspects are enabled, running, and generally healthy. Leveraging what the event broker can report on through the SEMP protocol, your collection agent can query these fields and rules can be applied to give you a “green light” indicator.
For customers using SolGeneos, there are comprehensive out-of-the-box data views available to report on, such as ‘HBA status monitoring’.
An example is shown below of the event broker reporting on the status of each redundant fibre channel connection to the storage layer it relies on:

A data view showing one of the Fibre Channel links being in a ”Linkdown” state
2. Event Broker Activity Monitoring is Just as Important
This next consideration might not be an intuitive one — if an event broker is being used for its intended function, what is there to monitor activity-wise? There are two dimensions to this reasoning:
- Monitoring the usage activity can aid in detecting issues with the connected applications and services.
- If your broker is a service in a shared-tenancy manner, monitoring activity will help you notice “noisy neighbors” jeopardizing the service.
If a virtual broker’s message and byte rate for a particular application is tracked over a period of time, you’ll have a good idea of its steady state. While there can be gradual increases observed as usage grows, experience has taught me that sudden deviations from that profile indicates abnormal activity or misbehaving applications. Some examples are: component releases going awry, services getting stuck in a publishing loop, lossy subscribers triggering continual re-publishing, and so on.
Putting activity monitoring in place keeps you from being left in the dark when it comes time to troubleshoot a volume-related incident after an outage. If you’re operating a multi-tenancy service, volume in one application may have caused an issue for another, unrelated application. As a service owner it is very beneficial to have a data-led conversation with application owners when you need to migrate a noisy tenant.
Below is an example of a data view showing message and data rates on a per message VPN basis, as well as the aggregate view across the whole event broker:
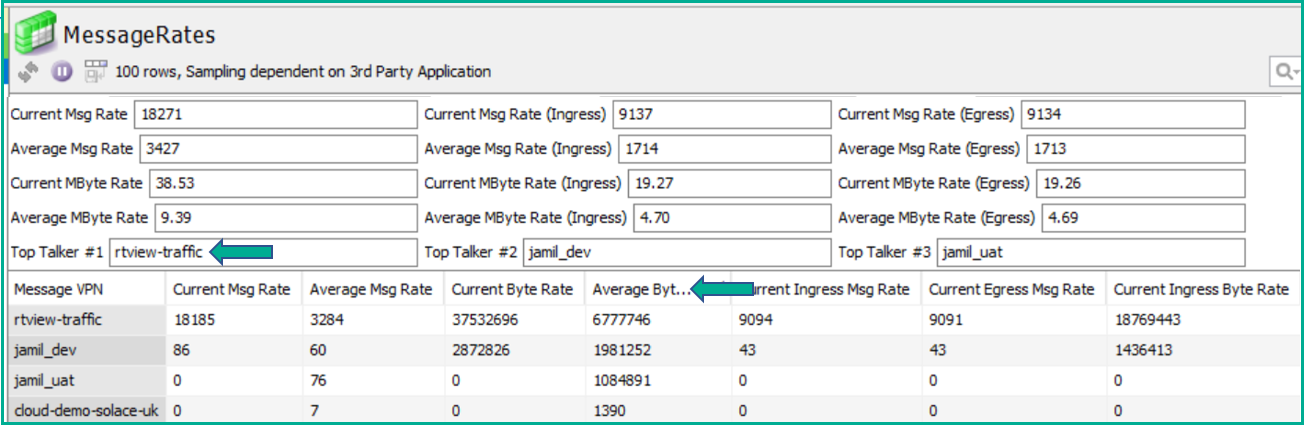
A data view showing metrics such as Average Byte Rate as well as the Top Talker VPN
The view above has been generated by a custom addition to the SolGeneos extensible framework for collecting data through SEMP. The code is available open source in the SolaceLabs GitHub repo.
When you’re collecting data on these rates, it is helpful to track the peaks in addition to currently observed rates. For example, if the data is being charted for a dashboard, the high-watermark can be the straight line on the graph alongside the currently observed rates.
The example below shows the highest rate observed specifically for “Egress Message Rate” across the event broker, along with recording the top 3 VPNs by traffic generation at the time. There is an ‘all time high’ rate, as well as watermarks that reset on a daily, weekly, monthly, and yearly basis.

A data view with a search filter applied to show captured high water mark values for the Current Egress Message Rate metric
These high watermark rates are also useful when it comes to capacity management to ensure the peak rates have enough headroom to grow with the current infrastructure.
3. Keep a Close Eye on Your Capacity
After you have made sure the event broker is operating as expected and there is good ongoing activity of the service, your next concern is managing the various resource limits and proactively monitoring for high utilization. There are two dimensions to consider here:
- For an application tenant using the event broker, what is the size of the virtual slice (i.e., message VPN) that has been created for them, and how is it being utilized?
- Cumulatively speaking, what has been allocated to different message VPNs and how does that compare to the event broker’s hard limits?
Once again, the SEMP protocol makes it easy to query for each resource’s current usage and max limits, and create a monitoring view like this:

A data view showing each message VPN limit as well as its current usage value
The format of “Current” vs. “Max” for each metric makes it easy to construct general purpose rules too. The rule can access both values to calculate a percentage and dynamically alert/trigger across the different resource types and max limit values.
For the second dimension of ensuring the event broker limits are not being exceeded by the cumulative allocations at each message VPN, you can create a view like this:
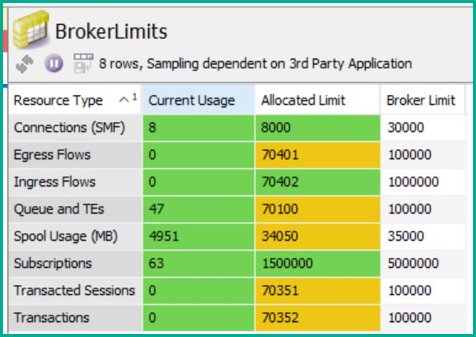
A data view showing the broker-wide limits, current usage and current allocation.
Another way of considering this particular message VPN limits allocation point is this: if all airline passengers show up for a flight, were there more seats sold than the available capacity of the aircraft?
4. Make Alerts Meaningful and Actionable
Sending alerts from the monitoring tool is a key aspect of the whole solution, because whether you’re generating an email, triggering the creation of a ticket, or posting to a chat channel, the alert is an interruption by design. Having served in an operational role where alerts woke me in the middle of the night, I can attest to the fact that everybody involved will appreciate it if you make alerts as informative and actionable as possible.
Take, for example, an alert just telling you that a message queue is filling up. The workflow could be to receive the alert, log into your administration tooling to gather more information and context to the alert, and then eventually take some action. How much more useful would it be for the alert to contain the information you’d need to triage the situation without logging into your administration tool? If a queue is filling up, questions you might want to answer could be:
- Is there an application currently bound to the queue, or is the expected application down?
- If it fills up, is the queue of the type that will block upstream publishers and therefore needs more urgent attention?
Below is an example of an ‘enhanced’ queue alert that was sent to a Slack channel. Note the extra information that helps with triage, like the fact that the queue’s high watermark level is the same as the current backlog level, which tells you this is an unprecedented situation for this application and queue.
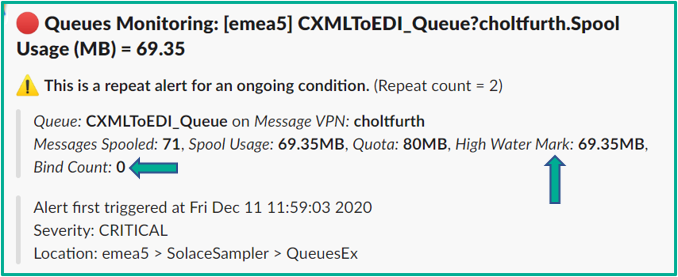
An example alert for queue usage being high, enhanced with additional information such as high-watermark level and bind count
Some of the logic behind triaging an alert could also be baked into rule logic, so recipients can determine the severity of the situation based on other pieces of data already factored in. The summary here is that the data collection agent needs to be comprehensive enough to capture and supply as much information as possible to drive this kind of triage, whether it is automated within the rule logic or done manually upon receipt of the alert.
A custom SolGeneos monitor for displaying a rich set of queue information is also included in the GitHub repository mentioned earlier.
5. Consider Synthetic Monitoring for a Holistic Approach
Last but not least, my favorite recommendation. Relying on metrics and other collected data only goes so far to provide peace of mind for the health of the event broker as a service. For most deployments, there is a lot of other supporting infrastructure involved. At the very least you may have a DNS alias for your event broker’s connection URI, so the DNS service and the entries within it need to be correct and responding. You may also be fronting your event brokers with a load balancer, so that needs to be responding well and routing the traffic appropriately.
Synthetic monitoring is the idea of testing a service by actually trying to use it for its purpose. Loading a website to validate that your webserver is working is one such example of synthetic monitoring. To that end, the code for a ‘Messaging Tester’ monitor has been made available in the GitHub repository where the monitoring data pushed by the SolGeneos agent is actually the result of performing a message send and receive test to a topic and queue destination. The ‘Message Tester’ monitor produces a view like this when the tests pass as successful, and will provide detailed information about the cause of failures when they don’t:
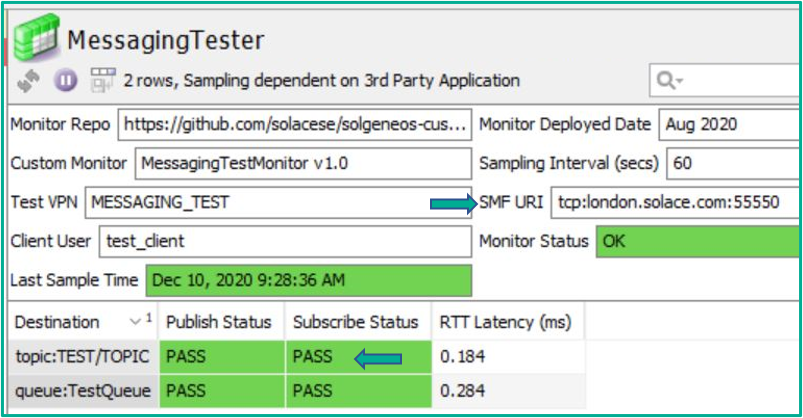
A dataview showing a successful publish and subscribe test against the broker at URI: london.solace.com
As a side effect of the published test messages also being subscribed to by the same process, it allows for round-trip latency to be calculated too. It should be stressed that this latency number will certainly not be the lowest latency messaging that can be achieved by the event broker; this is because the monitoring host, nor the process, would have been tuned for low-latency. However, the number you get is still a good indicator of some baseline performance that can be achieved by the monitor acting like a real messaging client. Monitoring how that baseline latency number changes between test samples can be informative in an operational sense too. Furthermore, logging the value to a time-series database can provide a view of this changing over time.
Synthetic monitoring like this does not only validate that messaging is working end-to-end, but it can also validate that performance is within an expected tolerance and that issues like network congestion or packet loss are not impacting the experience of messaging clients connected to the event broker.
Conclusion
I hope these 5 recommendations give you peace of mind that if the monitoring dashboard is green, the service is healthy. Please review the GitHub repository for more detail around the open-source monitor samples.
Explore other posts from categories: For Architects | For Developers



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.