If you have been developing or been involved with application architecture in one way or another, then you have definitely seen a lot of changes in the last few years. So many different types of architectures and technologies have come and gone that sometimes it can be hard to keep track of them. However, when you reflect on them, they can tell a very interesting story not just about the past but where application architecture is heading.
In this post, I will discuss how application architecture has evolved in the last few years and what has been the driving factor for each evolution. We will talk about monolithic architecture, service-oriented architecture (SOA), microservices, and finally, event-driven architecture (EDA). Let’s begin!
Outgrowing Monolithic Architecture
Back in the day, everything used to be monolithic. Huge teams would work on one monolithic application which would be responsible for doing a lot of things. Monolithic architecture allows you to quickly put together a prototype with one application doing everything. There is less maintenance overhead since you don’t need to rely on any other team. However, as the application is pushed to production and continues to grow, things quickly get out of control.
For example, a typical monolithic application may comprise multiple layers, such as a user interface layer, business logic layer, data interface layer, and data store layer. This application would take in user input, process it, apply business logic to it, enrich it with some existing data, and then might store it in a relational database for additional processing later.
The Disadvantages of Monolithic Architecture
There are three main disadvantages of monolithic architecture:
- slow rollout
- poor scalability
- inter-dependency
Monolithic applications are much harder to debug and update. Large applications require a lot of time and effort to identify issues and roll out updates, and by the time these updates are rolled out requirements could have changed.
The second disadvantage of monolithic applications is poor scalability. There is only so much one application can do. In today’s world, where computational resources are way cheaper than they used to be, it has become much easier to parallelize our compute by simply throwing computational resources at them. A monolithic application that used to run on a powerful but extremely expensive server can now be easily run on commodity hardware as smaller applications in parallel. Furthermore, slower rollouts (which we discussed earlier) made it more difficult to scale rapidly.
Additionally, with a large application, every little change can possibly impact one or more other parts of the application. This increases the additional risk of potentially breaking an important feature. For example, a bug in the user interface layer can impact the entire application.
Agile vs. Waterfall Methodology
Companies were realizing that they needed to find a better way to architect their applications. Around the same time, agile methodology was becoming increasingly popular. Previously, companies used to mostly develop applications using the waterfall methodology which meant gathering a lot of requirements, extreme planning, covering all edge cases, and then carefully releasing the final product with all the features in one big bang.

Source: Dilbert
For some industries, this is the only way to do it because of the costs involved per iteration and/or regulatory requirements. For many others, agile methodology worked better. Agile methodology is all about releasing the minimum viable product (MPV) in quick iterations. The faster you fail and know what doesn’t work, the better it is. Agile methodology, which had been around for a while, became extremely popular around 2011 when the Agile Alliance (yes, that exists) created the Agile Practice Guide. Agile certifications and agile coaches became ubiquitous. No matter how hard you tried to hide, your scrum master would always find you for the daily scrum.
Service-Oriented Architecture
As agile methodology picked up, it became clear that there were valuable benefits to having smaller applications that could be easily updated and scaled. This brings us to service-oriented architecture. Whereas in monolithic architecture, one application did everything itself, in service-oriented architecture, an application was broken down into several smaller services based on their use-case. As mentioned in this article by Kim Clark:
The core purpose of SOA was to expose data and functions buried in systems of record over well-formed, simple-to-use, synchronous interfaces, such as web services.”
Going back to our example of a monolithic application, it can be broken down into multiple smaller services, including:
- user interface service
- business logic service
- data integration service
- data store service
Each of these services is responsible for one specific use-case. They all exist independently and communicate with each other via synchronous APIs based on Simple Object Access Protocol (SOAP). However, as the number of services would grow in your organization, it would become harder to write an interface for each service to communicate with every other service. This is when you would benefit from using an enterprise service bus (ESB). ESBs allowed developers to decouple their services (see the diagram below) and made the overall architecture more flexible.
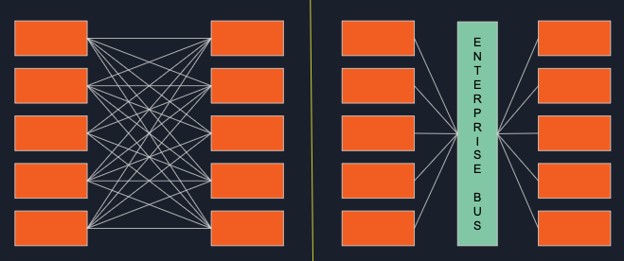
Decoupling your services
The benefits of service-oriented architecture include:
- quick rollouts
- easier to debug
- scalable
- clear assignment of responsibilities
- less dependency on other services/components
With such clear benefits, most companies started to adopt the service-oriented architecture along with agile methodology, but little did they know the cloud revolution was just around the corner.
Microservices Architecture
Distributed infrastructure on cloud is great but there is one problem. It is very unpredictable and difficult to manage compared to a handful of servers in your own datacenter. Running an application in a robust manner on distributed cloud infrastructure is no joke. A lot of things can go wrong. An instance of your application or a node on your cluster can silently fail. How do you make sure that your application can continue to run despite these failures? The answer is microservices.
Source: NGINX
A microservice is a very small application which is responsible for one specific use-case (just like in service-oriented architecture) but is completely independent of other services. It can be developed using any language and framework and can be deployed in any environment whether it be on-premises or on public cloud. Additionally, they can be easily run in parallel on a number of different servers in different regions to provide parallelization and high availability. For example, a small data application can be run on 5 instances in a compute cluster so that if one instance fails, the other 4 will make sure your data application continues to function.
Breaking down your services into multiple microservices meant they needed to communicate with each other. Unlike service-oriented architecture, which relies on enterprise service buses and synchronous APIs, microservices utilize message brokers – such as Solace’s PubSub+ Event Broker – and asynchronous APIs.
The Microservices Movement: Fueled by Containerization
Just like the transition of service-oriented architecture was fueled by agile methodology, the microservices movement was fueled by containerization. This article by Hackernoon describes containerization very well:
Containerization involves bundling an application together with all of its related configuration files, libraries and dependencies required for it to run in an efficient and bug-free way across different computing environments.”
Docker, which was initially released in 2013, is the most popular container platform. Almost every modern software these days can be run via Docker. With the rise of cloud infrastructure, Docker became extremely important to make sure you can run your software in new environments, especially on the cloud.
As microservices grew in popularity, so did the concept of a service mesh which allows services to stay connected mostly using the request/reply messaging pattern. NGINX has a great explanation of service mesh on their blog:
A service mesh is a configurable, low‑latency infrastructure layer designed to handle a high volume of network‑based interprocess communication among application infrastructure services using application programming interfaces (APIs).”
In 2014, Google open-sourced Kubernetes which allows you to orchestrate your microservices. With Docker and Kubernetes, it became much easier to deploy and manage distributed microservices on the cloud. In the last few years, these two technologies have only become more popular. Today, most new start-ups write cloud-native microservices that can be easily deployed via Docker and orchestrated via Kubernetes, and many large corporations are working with companies like Pivotal to easily transition their applications to the cloud.
The rise of cloud infrastructure and distributed microservices has led to the creation of numerous start-ups providing services for monitoring your microservices (how much memory are they consuming), automation (continuously deploying microservices across servers automatically), resource management (bidding for the cheapest AWS resources), etc. If you have ever attended AWS Summit then you know what I am talking about.
Event-Driven Architecture
As we continue to capture more and more data, we continue to find creative ways to use it. With the rise of IoT (i.e., Alexa microwave) and wearable devices (i.e., Apple Watch), there is an abundance of time-series data or events.
With so many screens available in front of us (smartphones, smartwatches, tablets, laptops, etc.), where notifications can be pushed instantly, companies are finding it extremely important to become more event-driven. Their users expect real-time notifications whenever important events occur. For example, my Delta Airline app notifies me in real-time when my flight is delayed or when boarding has started. It doesn’t wait for me to check manually or only check for events at a regular interval.
In this brave new event-driven world, microservices are designed around events. It is still quite new and is rapidly making its way across industries.
In this post, my goal was to show you how, in my opinion, application architecture has been influenced and evolved in the last few years by different technologies and requirements. As most companies try to embrace microservices and cloud, others are a bit ahead and already embracing event-driven architecture.
In my opinion, the foreseeable future will be microservices designed in an event-driven way.
Explore other posts from category: For Architects



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.