 Have you ever measured the failover time of your message broker? By that I mean the time from when you pull the plug on the server where your primary broker is running to when all your applications are happily sending and receiving messages again connected to a new broker? Have you measured it with varying amounts of messages stored to disk to see how this impacts your recovery/outage time? If you’ve done this you know where I’m going. If you haven’t, try the test I show below — the results might surprise you.
Have you ever measured the failover time of your message broker? By that I mean the time from when you pull the plug on the server where your primary broker is running to when all your applications are happily sending and receiving messages again connected to a new broker? Have you measured it with varying amounts of messages stored to disk to see how this impacts your recovery/outage time? If you’ve done this you know where I’m going. If you haven’t, try the test I show below — the results might surprise you.
Message brokers that provide persistent messaging (i.e. store messages to disk so they are never lost) exist in your architecture specifically to decouple publishers and subscribers. So it is expected and normal that there is message accumulation in the broker whenever one or more consumers are too slow or offline. If this weren’t the case, why would you need persistence? The amount of data stored depends on things like input message rate, number of slow/offline consumers and how long they are slow/offline.
What if you found out that the failover/recovery time of software brokers increases proportionately with the amount of data stored by the broker? What if this time varied from several 10’s of seconds to several 10’s of minutes or more — is that level of outage OK for your application?
This is the second articles/video about Solace messaging appliances and their high availability functionality. If you aren’t already familiar with Solace’s failover capabilities you might want to check out this post which explains Solace HA and shows some fast failovers at high message rates.
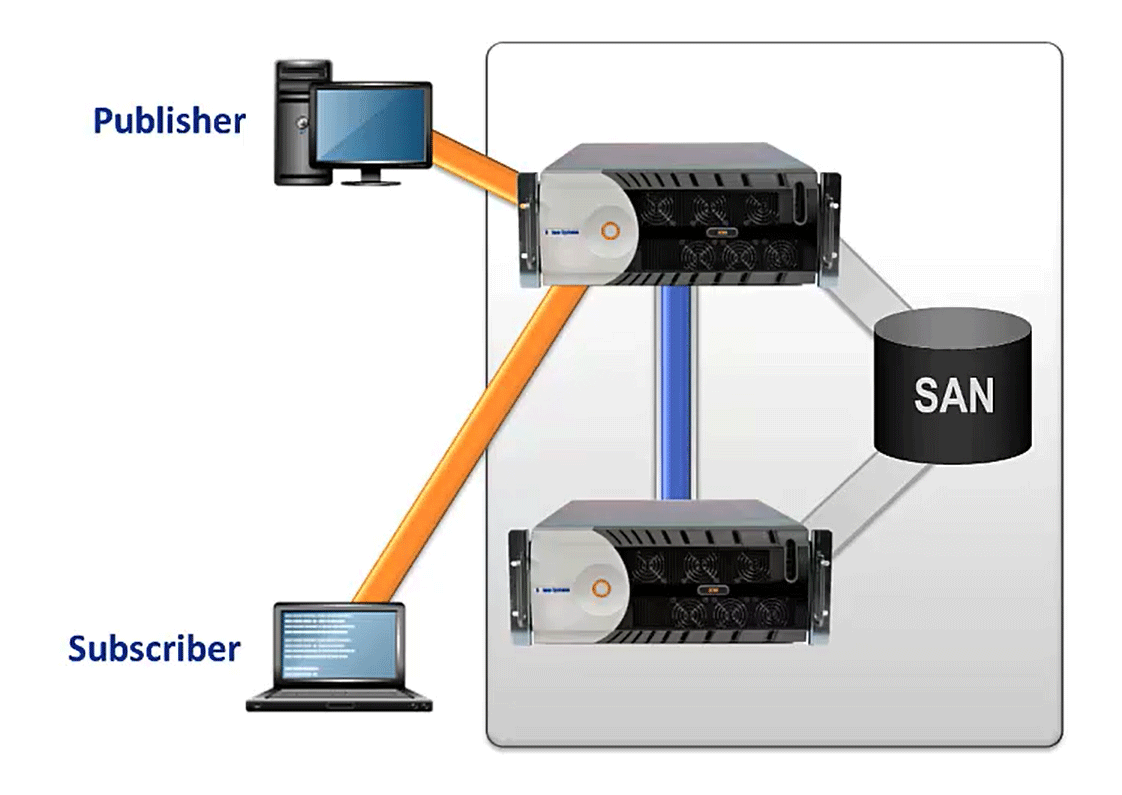
This video builds on the previous demos and looks at the effect on failover time of having large amounts of messages spooled for offline consumers at the time of failover. Most messaging solutions depend on retrieving all message state from disk in the event of a failover. This makes the messaging solution failover times highly dependent on the volume of messages spooled at the time of failover and the performance of the disk.
We’ll contrast the disk-based approach with the Solace solution which completely avoids disk reads on failover by synchronously keeping the hot-standby appliance in sync at all times. The scenario you will see is a failover with over 700 GB of messages spooled across a total of more than 350 million messages. Additionally there are online clients sending persistent messages at 100K msgs/sec. With all of this message spool and live traffic, the failover time is still amazingly low. How low? Checkout the video.
Explore other posts from category: Products & Technology



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.