Introduction
Traditional forms of integration are being challenged by an ever-changing ecosystem, customers who demand new experiences faster, the need for personalized interactive communication, and an increase in the amount of connectivity brought about by modern technologies.
With this article, I will explore how these variables impact the flow of information, and what you need to do to ensure that new integration architectures can withstand the impact of these changes, enable application developers to respond quickly and help enterprise architects to plan for these changes. I will then explore how event-driven integration is the solution to these new challenges and allows for the growth and scaling needed by them. As you will see, event-driven integration inverts the way we do integration by clearing the data path and putting processing at the edge of an event-driven core.
This is the first in a series of articles in which I will clarify and explain the challenges, solutions, and benefits of taking an event-driven approach to integration.
The Need for Speed
An old adage says the only constant is change, and that’s been true in the enterprise IT space over the last few decades as new technologies like the cloud, internet of things and artificial intelligence have caused the rate of change to increase exponentially. Our expectations and demands have increased almost as much as our patience to see them addressed has decreased.
Technology connects us to each other and the world around us, and there are countless examples of how technology has improved and accelerated our lives. Over the last two decades, digital communications have evolved from email to social media, shopping from in-store and/or online shopping to omnichannel, and preventive health from in-person checkups to sensor-based AI diagnostics. We used to operate at the speed of nature, now we operate at the speed of technology.
The number of interactions we have with each other and the companies we buy from has multiplied exponentially as well. One simple action can have multiple consequences and impact many people and systems. There is a need to have broader visibility into all correlated actions and events in real-time, i.e. for increased “situational awareness”. For instance, say you are travelling, and you are in transit, and your flight is delayed due to inclement weather. These days such an event can lead to the alerting of gate crews, baggage handling, reservations, and potentially an inquiry to see what nearby hotels are available in case you need to stay overnight.
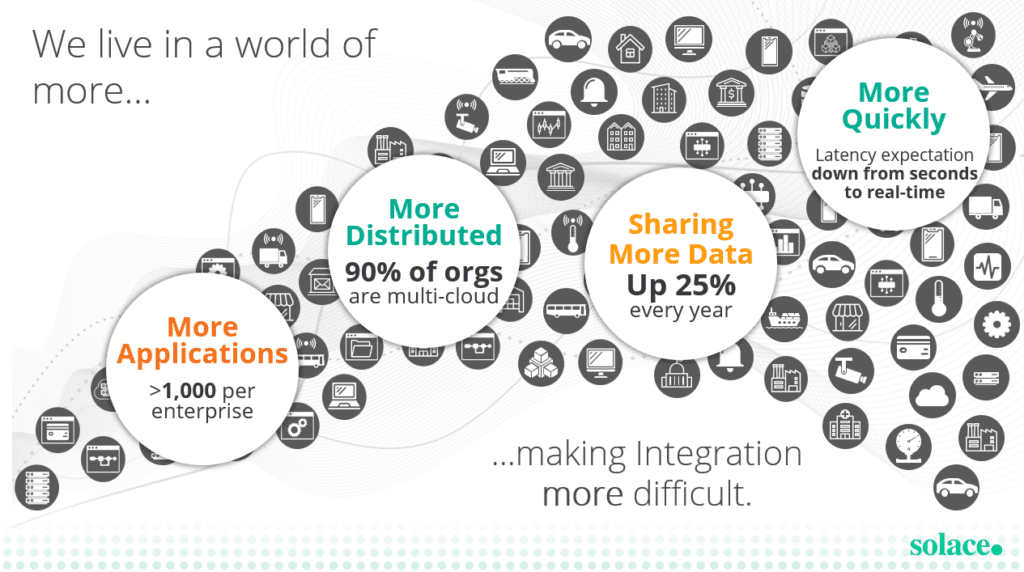
This proliferation of technology in our day-to-day lives, and in the enterprise, has led to an ever-increasing volume, complexity, variety, and unpredictability of transactions. Most large enterprises have upwards of a thousand applications they need to manage, spread across on-premises environments, a variety of cloud infrastructures, and IoT/edge environments such as stores, distribution centers, factories, connected vehicles etc. The generation of data from this hyper-connectivity is increasing by over 25% every year.
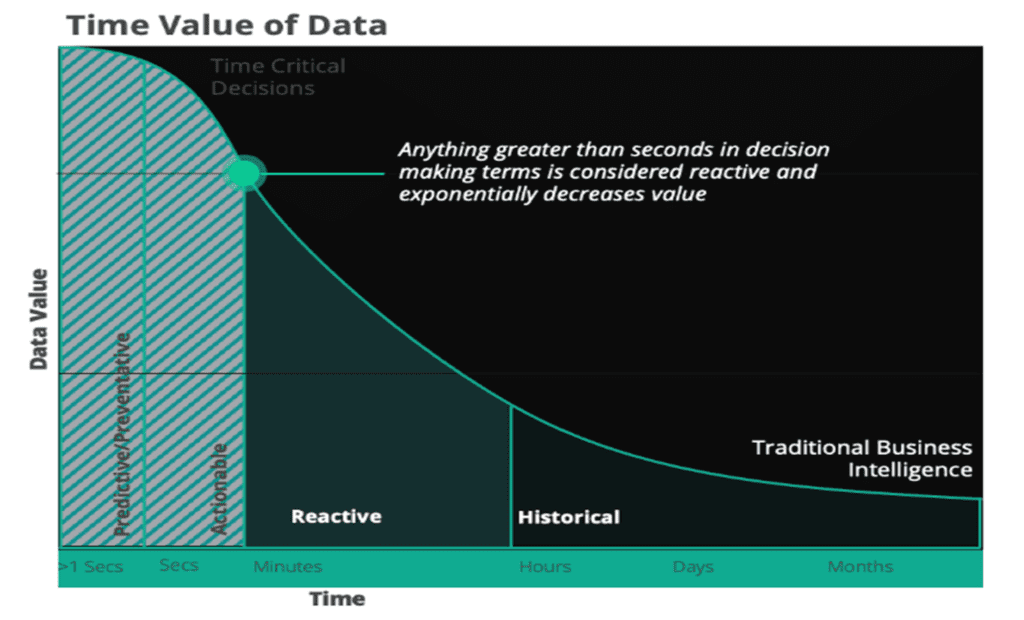
Lastly, the value of data exponentially decreases over time. If you don’t act at the right moment, there could be dire consequences, or at least poor user experiences. As I mentioned earlier, our expectations to receive contextual data/information in real time have drastically increased.
One of the challenges associated with achieving unified and relevant context is the fact that much of the current enterprise data-scape is dispersed across many silos. It thus becomes paramount to break down these silos and make data accessible in real-time to provide the correct information that can enable correct decisions. Having access to the correct information at the right time can make the difference in something as serious as preventing fraud, or as benign as paying full price for an item versus getting a discount! Essentially, real-time data in context can help you identify opportunities and threats so you can capitalize on or prevent them.
Modern integration platforms and architectures need to be versatile and flexible, and:
- Maximize data flow
- Decouple endpoints
- Scale (nearly) linearly
- Be fault tolerant
- Support a wide array of connectivity destinations (apps, systems, devices)
- Have comprehensive governance across both synchronous and asynchronous services
- Encourage self-service
- Facilitate composability through asset discovery and reuse.
Integration Landscape Challenges
The latest trend in integration strategies (microservice orientation), together with domain-driven design, has led to a significant change in the way distributed software is designed and built. Some of the more attractive aspects of APIs and microservices based architectures were:
- Reuse through discoverability of digital assets (APIs)
- Composability of “coarser” grained microservices from “finer” grained ones
- Change minimization through integration to a contract/interface and not directly to code
- Governance
The ability to discover and reuse digital assets (e.g. APIs) in a self-service manner reduces duplication of effort and accelerates development. The ability to combine and compose those reusable assets in new and interesting ways gives an enterprise agility and leads to a shorter time to value.

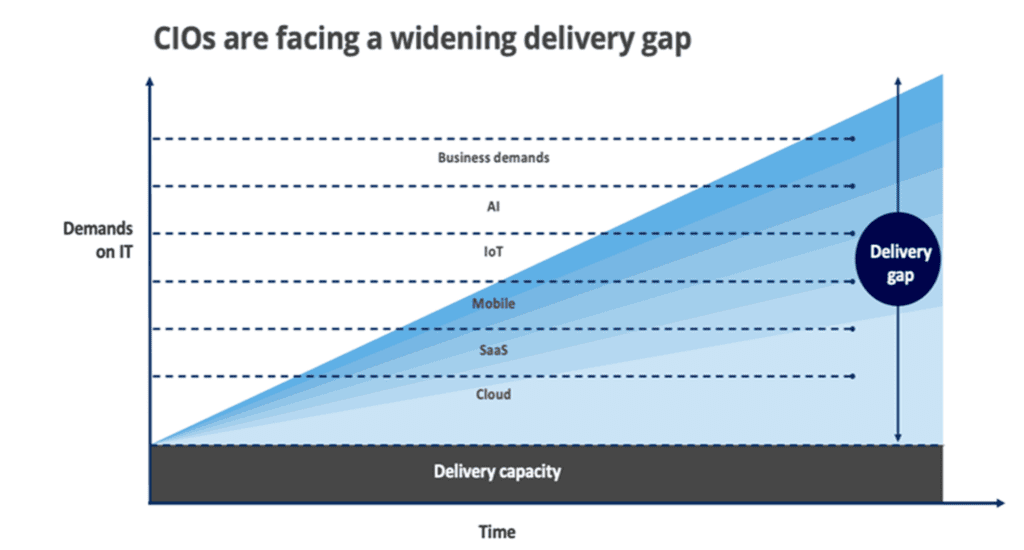
Thus, self-service and re-use reduce the asset delivery gap that plague most enterprises. By delivery gap I mean the often-considerable delta between the business’s demand for new capabilities and IT’s ability to meet those needs because of limited resources, inaccessible information, inflexible architecture, etc.
Despite the great benefits that microservices-based integration has brought, implementations are often fraught with challenges in the areas of both architecture and infrastructure. For instance, one of the key value propositions of a REST-based architecture is the ubiquitous protocol, HTTP. The fact that all services “speak” HTTP simplifies interactions, but this can lead to a great degree of coupling because, for instance, there are limits to how much you can do in each microservice/API because of time boundaries that must be respected (i.e. timeout risks). This is especially true when:
- You are trying to cram too much logic into that microservice
- There are multiple dependencies (i.e. a sequence of API calls)
- The service needs to interact with other services that are geographically dispersed.
Additionally, scaling REST-based systems can be challenging because you need to add components such as gateways, load balancers and policies like circuit breakers, throttling, and rate limiting. These add overhead in both cost and operational complexity, and the complexity can make the system more fragile.
To say it more simply, microservice-based integration is plagued by rigid plumbing that impacts the adaptability of the architecture. This remains true whether the implementation is done via an integration platform (i.e. an iPaaS), custom code, or a combination of the two.
Rigidity is manifested in:
- Point-to-point coupling
- Time-bound operations
- Changing route paths (i.e. change API A->API B to API A -> API C) requires intervention and redeployment
For instance, one of the key challenges with orchestrations is the limited number of steps they can include to fit within the response time period of the HTTP protocol. Another challenge is the depth of the “dependency tree” (API A calls API B calls API C etc.). The deeper the tree, the higher the impact on performance (and the risk of timeout) and the more tightly coupled (ergo brittle) the architecture. With regards to scaling across geographies in many cases (and due to the limitations of HTTP), API/microservice instances are often duplicated in different geographies to minimize latency. This duplication leads to more complex versioning and upgrading procedures, and often requires global load balancers.
Most integration tools/platforms will allow you to build just about any type of integration, but what goes into that integration project can hamper the flexibility and agility of the overall architecture. In the simple example where you pull data from one database, transform it, and store it in another database, developers will often put all three components (source connector, transformer, destination connector) into the same deployable artefact, creating a high degree of coupling. That is not to say that the tooling won’t allow you to create three separate projects (one component per project) and deploy them separately, but developers will usually co-locate integration logic into one deployable artefact to save on deployment costs, and resources, thus violating some of the key guiding principles of microservices-based integration, such as independent deployment, single purpose, and loose coupling.
In short, to keep up with increasing transaction volumes, organizations are exploring alternatives. Transforming the core tenet of microservices architectures of “smart endpoints and dumb pipes” into a new tenet of “smart endpoints and smart pipes” will require the addition of “intelligent infrastructure”.
We thus need to find a solution that solves for:
- Performance, which is often impacted by having processing components in the data path which can slow down the data flow. The inability to scale properly can also impact performance as typically there is an inversely proportional relationship between the increase of data volumes and the ability to handle/process those volumes. The new solution needs to be able to maximize data flow by removing any unnecessary processing components from the data path.
- Robustness, which has to do with the resilience of a given system, i.e. how well it can handle stress. There is a high degree of volatility in data flow, and you often have situations in which certain consumers cannot process the data at the speed at which it is generated, or conversely the demand on certain data producers is so high that it may impact the generation ability. Either can lead certain system components to be idle, and unnecessarily consume costly resources. The new solution needs to ensure that the architecture is resilient, no data loss occurs, and resources are optimally used.
- Scalability, which is required when there is an increase in transaction volumes. Inability to scale will adversely impact performance. Scalability can be impacted by an inability to rapidly add more processing capacity to handle an increase in volumes in a given region – i.e. adding more consumers to a given resources, an inability to grow geographically and handle traffic over greater distances – i.e. data generated in NA needs to make its way into EMEA and APAC in real time, and increased connectivity – i.e. adding more stores, factories, warehouses etc. . A new solution would need to address both scalability challenges.
- Complexity, which is one of the key factors impacting scalability, governance and manageability. Complexity in integration often arises when dealing with 1-to-many scenarios, like when a transaction needs to invoke many services to fulfill its mission, when you need to aggregate data from multiple sources into one message, and when an event needs to get to multiple consumers. The other aspect to complexity ensues when one needs to operate over different environments, such as cloud to cloud or cloud to on-premises or vice versa. The new solution needs to accommodate all complexity models.
- Flexibility, which relates to the ability of a given architecture to withstand change with minimal impact and risk. In some cases, this is also referred to as “evolvability”. Highly coupled microservices make change difficult due to the high degree of dependency and impact. Following one of software designs oldest tenets, one needs to have high cohesion within a service but loose coupling between services. If services adhere to some type of contract (API specification) it also makes changes within the service easier if the contract is not modified; thus, consumers of that service are not affected by internal changes to the service. The new solution needs to be able to support loose coupling, and contract-based development.
- Agility, meaning the speed with which enterprises can launch products and capture market share. Agility is based on the ability to discover existing assets and “assemble” them into new business offerings, and conversely decompose existing offerings and recompose them into new ones. Discoverability leads to shorter development cycles, less duplication of logic and by and large leads to a higher degree of self-service and efficiency.
Current approaches to integration do not often adhere to general distributed architectures principles, and the design of integration architectures often do not take into consideration certain infrastructure constraints. As such, most architectures are not able to properly handle the increase in transaction volumes and the speed at which they occur which often leads to outages and poor user experience, which ultimately impacts the bottom line. The low degree of flexibility and agility of these architectures also adversely impacts an enterprise’s competitive advantage and its ability to easily evolve over time.
In the next section I will look at a different approach to integration — an approach that can solve most if not all the challenges outlined in this section.
The Shift to Event Centricity
Gartner identified a trend in the evolution of IT systems architecture, specifically as it pertains to integration architecture. The trend was underpinned by a shift in mindset that moved from looking at IT systems as being “data (centric) custodians” to a mindset that looked at IT systems as constituting the enterprise’s “nervous system”; a view that looked at “data in motion” as opposed to “data at rest” as the source of decision making.
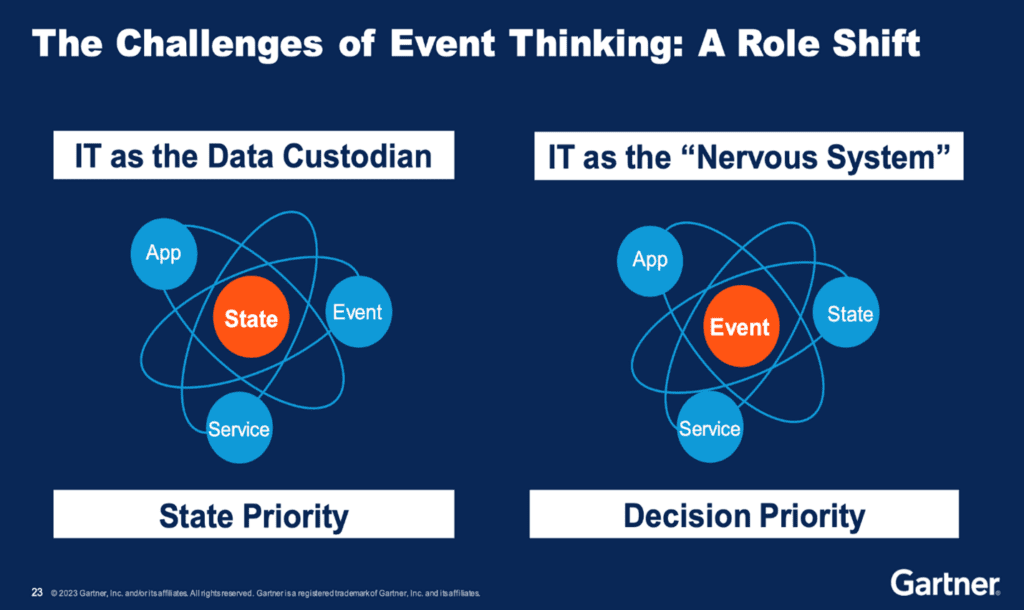
An event centric perspective changes the way we perceive impact. A data centric model focuses primarily on the state of the data as it is right now, whereas an event centric model not only does the same, but it also enables systems and people to react to events as they occur, leading to a more accurate real-time decision-making capability. An event-centric model also adds a chronological/historical dimension that can allow one to identify and understand the root cause of a given state, i.e. the impact of change.
Event orientation also makes for a more flexible and decoupled “core” architecture. REST-based architectures support the data-centric model in that they govern access to data at rest, whereas EDA puts the emphasis on decoupling, resilience, and adaptability. It is important to note that this is not an argument about which model is better, but rather how do we combine the two models to achieve a more agile, flexible and resilient architecture.
Turning Integration Inside Out
Studies have shown that the best designs of physical network architectures suggest that “complexity belongs at the network’s edge”.
To quote the IETF paper RFC-3439, Some Internet Architectural Guidelines and Philosophy: “ In short, the complexity of the Internet belongs at the edges, and the IP layer of the Internet should remain as simple as possible.”
So, how does this relate to integration? Current integration approaches have placed integration components in the data path, i.e. at the core. Integration, whether real-time or batch, requires connectivity and transformation. The challenge with centralized integration approaches is that they couple connectors, transformations, mappings, and potentially transactional context into one deployable asset, through which all data must flow. As such, the integration component can become a bottleneck and a single point of failure. The more such components exist in the data path (i.e., orchestration, data enrichment etc.), the slower processing becomes.
Today’s use cases demand an integration architecture that can handle traffic bursts and slow/offline consumers without impairing performance, can scale to handle an increase in both consumers and producers, and can guarantee delivery of data even to temporarily unavailable consumers. It also demands an architecture that lets you easily plug in processing components and distribution mechanisms without impairing the overall design. i.e., we need to have an evolvable architecture!
How do you arrive at such an architecture? I’ll start by posing a question: what if we turn integration inside out? What if we follow the RFC-3439 recommendation and place integration complexity at the edge while keeping the core simple?
The Impact of Decoupling
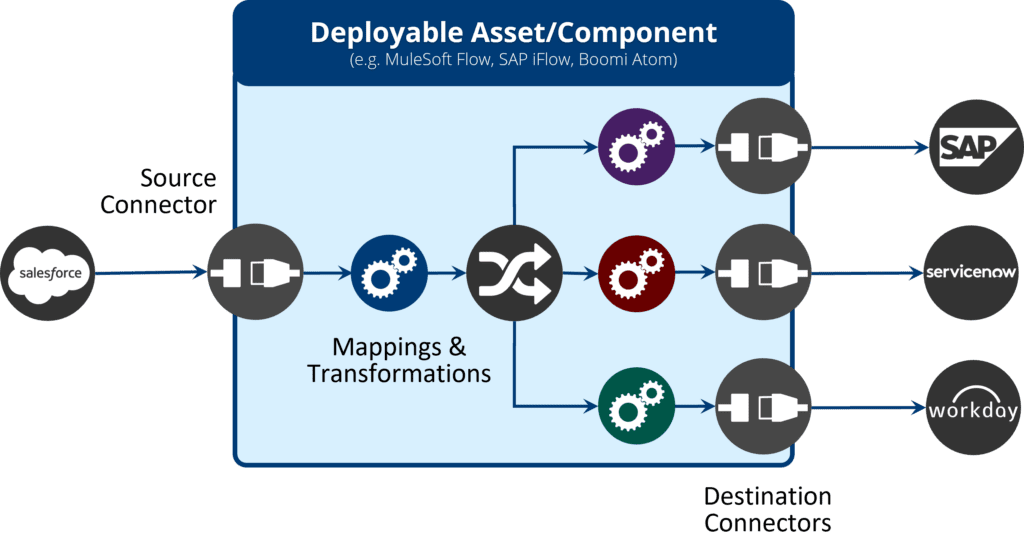
Let’s look at a simple example of an integration that will take data from one database and route it to two systems in different regions. Traditional integration platforms (e.g. ESB, iPaaS), would typically implement this by having a data source connector (e.g. a JDBC or CDC mechanism) retrieve the data, followed by a choice/router component that would route the data to the respective processing endpoints.
The routing paths would terminate into connectors to the respective data sink systems in their respective regions. Essentially you would have 4 components bundled together into one deployable artefact. If you needed to add more distribution points you would have to modify this integration, update the routing rules, and add the necessary destination connectors. This would make the integration component heavier and more difficult to maintain over time, and every time you make a change you would impact all the other destinations as you would have to take the component offline, make the change, and redeploy.
A better approach would be to break apart the integration component into individual units at the edge and have an “event mesh” at the core route information to the necessary destinations with its built-in routing and filtering capabilities.
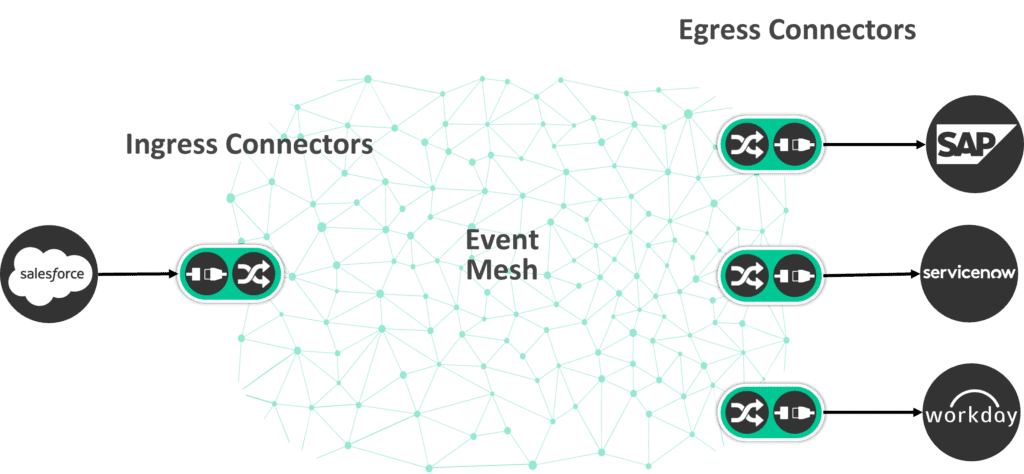
This approach has the following benefits:
- Clears the data path by removing the integration component from that path. Trusting the event mesh to do the routing and decoupling all other components ensures that each integration “path” is as fast as it can be based on the end systems and is not coupled to any other performance-impacting systems.
- Eliminates the need to write complex routing rules by leveraging the event mesh’s native capabilities.
- Delegates processing (and deployment) at the edges; the connectors (and if necessary, transformations) thus leverage the resources in their respective regions.
- Lets you add consumers in different regions with no downtime or modifications to the existing integration architecture.
- Enables individual scaling of each deployed node.
- Absorbs the shock of increased volumes from the source.
- Scales to a virtually infinite number of target systems without any performance impact.
- Eliminates the impact of faults, errors, slow or unavailable target systems on other integration flows.
- Lets you use different integration technologies at the edge, such as: traditional ESB, iPaaS, cloud frameworks, custom code etc.
It is important to note that this approach does not take away any capabilities an iPaaS/ESB might offer. Rather it complements those capabilities and allows for better scaling and the fulfillment of more extensive integration scenarios.
Generally speaking, this approach also optimizes data flow which improves performance, reliability and scalability. The decoupling of smaller integration components also promotes agility by reducing time to market and development costs.
Conclusion
Tectonic changes in data volumes, connectivity levels, consumption models and customer expectations are changing the way you architect the flow of information. Current integration paradigms can’t meet this need, making a new approach necessary. By shifting complex integration processes to the edge while keeping the core fluid and focused on decoupled, event-driven data movement, integration becomes more adaptable, scalable, and robust.
This is the first in a series of articles that will delve deeper into event-driven integration. In future articles, we will explore what it takes to implement event-driven integration with an event mesh.
Explore other posts from categories: Event-Driven Integration | For Architects



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.