GO-JEK is one of the big names in the South East Asia technology start-up scene. It started off with a ride-hailing service and continues to grow into many areas. With so many services and a huge user base, the engineering behind its services should be an interesting case study. In this article, I will look at GO-JEK’s Kafka ingestion architecture and try to provide an alternative to it.
GO-JEK’s Existing Architecture
A couple of GO-JEK engineers have written articles around GO-JEK’s engineering work. One of them explains how they do their event ingestion into a Kafka cluster. As the figure below shows, GO-JEK’s existing architecture starts with the Producer App and ends with the Mainstream Kafka cluster.
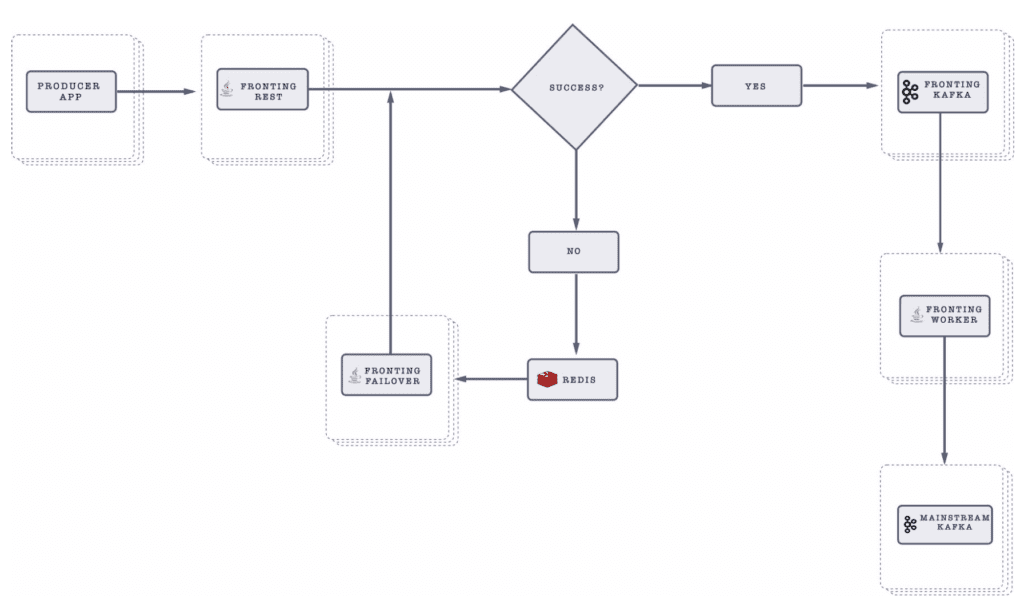
According to the blog post, GO-JEK has solved a few problems and made the following improvements in the architecture:
- Producer application developers don’t need to learn a new API , namely the Kafka client API, since they can just use REST API calls.
- Messages are now acknowledged back to the producing applications.
- No buffering technique or storage is required for the producer applications when the Kafka cluster is not available.
Why an Alternative Architecture
Looking at the existing architecture, I can’t help but think that there can be a simpler architecture with fewer components to solve the same set of problems. As an external party looking at only a blog post, I may have missed some details or made incorrect assumptions. But, the beauty of it is that this would be a fresh point of view and hopefully it will offer some value to the owner of this architecture.
So why is an alternative architecture necessary? Because having a couple of Kafka clusters, Java applications, and a cache to move data shouldn’t need so much setup and overhead. I would like to take a stab at providing a simpler architecture, one that hopefully has fewer moving parts, is built more as an infrastructure rather than part of the business applications, and can avoid additional complexities.
The Proposed Architecture lterations
All we want to do is to get the events from the producer applications across the Kafka cluster. How hard could it be? Well, for starters, the producer applications now need to be able to “talk” to Kafka.

Proposed Architecture Iteration 1
So, REST is what the applications use? That’s totally fine. Then we should have a thing between the applications and the Kafka cluster that connects REST to the applications and talks to Kafka on the other end. And it must be a centralized, shared thing so new applications can just get onboard without the need to keep adding this new thing. This new “REST to KAFKA Thing” must be able to give acknowledgements back to the producing applications as well as buffer the events when the Kafka cluster is not accessible.
Back to the original blog post, there was a comment that suggested the writer use Kafka REST Proxy and Mirror Maker. One of the reasons why the writer did not accept the suggestion is because this suggestion would lack the ability to buffer and retry the event publishing to Kafka. This is where the “Fronting Failover”, “Fronting Worker”, and Redis came into the picture. It looks like a lot of new moving parts being added to deal with the fact that Kafka cluster can be unavailable at times.
Are there any other ideas? Of course.
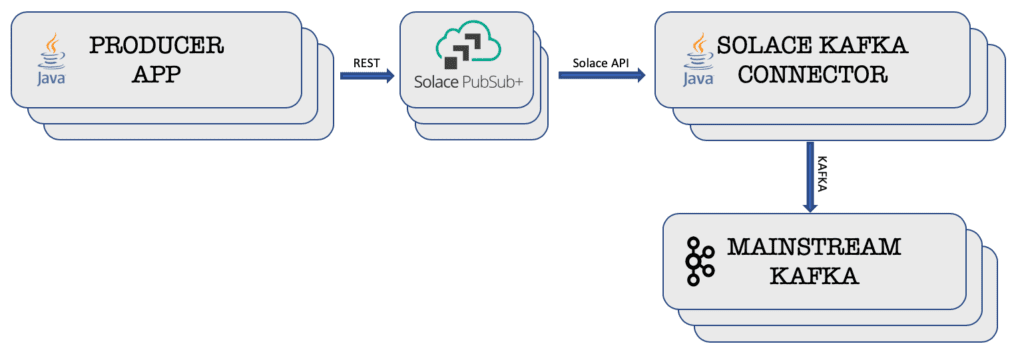
Proposed Architecture Iteration 2
This time two components are added: a Solace PubSub+ Event Broker and a Solace PubSub+ Connector for Kafka Source. Solace PubSub+ Event Broker gives you the REST interface as well as the guaranteed messaging feature with acknowledgement. So, the producer applications don’t need to worry about losing their events. It also leverages the Solace Messaging API and the Solace PubSub+ Connector for Kafka Source as the source connector to stream the events directly to the Kafka cluster using the Kafka Connect API.
As an enterprise-grade event broker, PubSub+ provides high-availability and replication features without any dependency on other software or technology. This surely helps in terms of fewer moving parts to manage by the operation team. This PubSub+ Event Broker will also queue up the events in case the connector is not able to pass through the events into Kafka. This is where the guaranteed messaging feature comes into play.
The question that may arise is how big of a buffer the message broker could handle if the Kafka cluster is unavailable. No problem. PubSub+ event brokers handle slow consumers in such a way that they do not impact the performance of the producers or fast consumers. For guaranteed messaging, publishers and fast consumers are identified and prioritized over slow or recovering consumers even as message storage to slow consumers continue to increase.
The Solace PubSub+ Event Broker Appliance currently supports up to 6 TB of message spool for this buffering need, while the software allows around 800 GB of message spool. It’s basically a matter of sizing and deployment choice.
Conclusion
Solace PubSub+ fits the bill as an infrastructure thing that does not really need a lot of attention. It is more like your network equipment that just needs to be set up once and can be left untouched most of the time. But the Solace PubSub+ Connector for Kafka is still a piece of software! It is still the better option to integrate with Kafka using the Kafka Connect API. When Kafka or whatever your event store natively supports open standards such as JMS and MQTT, there will be no need for such additional connectors.
So, use REST, checked; message acknowledgement, checked; buffering, checked!
Visit the Solace website to get more information about the Solace PubSub+ Platform and the Solace PubSub+ Connector for Kafka. Share your developer experience and ask questions at Solace Community.
Explore other posts from category: For Developers



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.