An organization’s system of record is the living memory of that organization, telling the story of where it has been, and potentially where it is headed. Yet, while data is very important for modern enterprises, it is rarely managed well. This has significant associated cost, especially in capital markets. Capital markets is an exchange marketplace where buyers and sellers trade financial securities and assets. As such, there are often multiple sources of record/data which lead to issues like:
- Systems of record that are out-of-sync and misaligned
- Downstream applications getting duplicate data or incorrect schemas, causing outages
- Potential latency and data structure mismatch
- Lost data lineage information during source normalization
- Integration issues when data comes from unrelated vendors
- Regulatory compliance risks and expensive fines
- Manual reconciliation of data semantics across internal and external sources
A typical tier 1 banking enterprise’s data management is often tied to legacy infrastructure, so it responds slower than the trading desks which cannot afford to wait days and weeks to onboard vital initial public offering (IPO) and know-your-customer (KYC) data. Not wanting to wait, the front office IT will end up with their own reference data in order to fast track the onboarding process – while the corporate master data system plays catch up. There are more reasons why there can be several reference data masters in a bank. Duplication may be the result of mergers between companies or acquisitions of whole trading units that have never been fully integrated.
What Reference Data Means to Financial Markets
Reference data in financial markets is a catch all term used to describe both static and dynamic data which is used to classify and describe the individual characteristics of each financial instrument. It covers counterparty and security identifiers and indices used when making a trade. As reported by Refinitiv, a major financial data vendor, their contribution has curated upwards of 80+ million securities, investment instruments, and stocks listed on 200+ key venues across 100 nations. It includes various industry-wide and proprietary coding systems to identify instruments such as ISIN, CUSIP, SEDOL, and vendor specific codes – Refinitiv has RIC codes and PermID, while Bloomberg offers Open Symbology. Corporate actions data tracks capital changes, dividends, nominal values, public equity offerings, shares and voting rights going back 50+ years. Regulatory compliance related data sets cover holdings disclosure information like shares, voting rights, and reference facts.
A financial institution would normally buy this curated data from a reputable data vendor and import it into their corporate data warehouse as structured data in several ways, such as APIs and bulk file access. More recently, cloud-based data lakes are gaining popularity because of their ability to simplify onboarding and the ability to store semi-structured and unstructured content from a much wider range of sources.
How a Modern Post-Trade System Unlocks the Value of Reference Data
Over the past 20+ years, intraday changes in the market structure have often been treated as static end-of-day events. As observed during the recent March 18, 2020 market volatility, the middle and back office systems were the choke points in post-trade processing that materialized in sustained outages when market events in the front office were not processed fast enough, leaving customers exposed to financial risk as market volatility continued to unfold throughout the day. Reports have shown that a more agile deployment of processing power and access to data from current market events in post-trade could have compensated for the bottleneck. My colleague discusses the impact of the COVID-19 induced market volatility in this video – Keeping Trading Platforms Performing During Extreme Volatility.
One way to unlock the value of reference data and modernize post-trade is to relocate bottleneck processes to the edge of the business flow from the front office to the back office, from order execution to settlement. While 70% of all data used in financial transactions is reference data, the corporate data management system does not need to sit on the critical path of enterprise infrastructure.
Post-trade predominantly relies on end-of-day pricing for trade processing and settlement. To bridge the post-trade cadence gap, a modern platform needs to be real-time to adapt to a rapidly changing and unpredictable environment such as extended periods of high volatility. It must be able to keep up with traffic bursts coming from the front office as well as add on-demand resources as needed without pausing the critical path. To become evolved, the modern post-trade system platform should be:
- Customer-centric
- Adaptable
- Automated
- Smart and simple
- Discoverable
- Flexible/agile/elastic
- Collaborative
- Governed and secure
- Resilient
Basically, it comes down to an event driven architecture. When a new entity data set is created or updated, or when a corporate actions dividend structure is updated, such a change is an event. When change logs publish in real-time to an event broker, consumers could then register interest on a channel and receive the updates on events they care about. This approach works well for capturing data as they are being persisted to a data store and are made available on the network in the form of real-time events.
A modern post-trade system that utilizes an event broker to event-enable reference data, making it streaming and routable, would transfer real benefits to clients, including:
- Shorter intraday updates, from 15 mins to almost real-time
- Decreased settlement rates, from three days (T+3) to instantaneous (T+0)
- Near real-time trade processing
- Real-time assessment of market risks
The shortening of historical data snapshot intervals is driven by interest from customers for faster response times to shifting market conditions. Anti-money laundering (AML) and know-your-customer (KYC) automation are great examples of advancements in post-trade where artificial intelligence and up-to-date public data are used to detect fraud in near real-time transactions.
Changes are also happening in the back office. SWIFT recently announced it plans to enhance its platform to enable financial institutions to deliver instant and frictionless end-to-end transactions. Given the ability for instantaneous settlement, the validation process leading up to settlement needs to be sped up to near real-time and streaming.
The Benefits of Decoupling in Post-Trade Systems Architecture
In banking, the term “coupling” when referring to reference data comes in many flavours, but there are two that are worth mentioning. Static sourcing is when functions that change data (e.g. bulk file uploads, top-up APIs, SQL write/update) are commingled with functions that query data (SQL read) in the same application context. This makes it difficult to capture state changes and use them as legitimate data sourcing events. Consistency is when downstream business unit-level (operational/local) masters depend on the corporate-level master for a subset of the reference data it needs.
In both cases, the information exchange is synchronous and request/reply. Intelligence is usually embedded in the middleware ESB/BPEL processes that orchestrate the workflows from sourcing to cleansing to distribution. When changes happen, it is usually a “Houston we have a problem” kind of deal.
A good example of the dangers of coupling is the August 31, 2020 split of TSLA and AAPL stocks on the same day. These are the most traded stocks, so the event was well publicized ahead of the split. When stock splits occur, prices get divided while volumes get multiplied. Major data vendors and data warehouses needed to adjust all historical market data related to the securities. In a situation where there are multiple reference data masters, the changes must be made in multiple places. For situations where operational reference data depends on the corporate reference data, effective notification and automated update mechanisms must be functioning. As it turned out, that was not the case in many situations. There were outages. Many premium vendors transitioned correctly and worked with their customers to make the necessary changes. Others did not. Many internal systems reacted after the failure.
The architectural benefits of decoupling range from enhanced simplicity to improved performance and have a major impact on business processes. Here is a list of the technical benefits:
- Simplicity: Handle all the major types of messaging (reliable, guaranteed, JMS, WAN and IPC) in a single platform.
- Performance: Eliminate the drawbacks of point-to-point synchronous software serving business logic and messaging running on the same servers. Decoupling producers from receivers to enable the delivery of massive amounts of information at higher rates and with less latency and less latency variations than other solutions.
- Stability: Leverage purpose-build messaging with deterministic performance characteristics even when processing millions of messages per second and in the face of misbehaving client applications.
- Scalability: Allow the flexibility to position data closer to compute resources both on-premises and in the cloud so that workloads can be scaled on-demand.
- Centralized filtering and unicast distribution: Perform message routing centrally per topic/symbol and remove the operational challenges of multicast, the approach still used in banks to achieve high message rates and low, predictable latency.
- Throttling: Allows message delivery to be rate-controlled on a per-topic/symbol basis. This feature reduces the amount of traffic to a remote client.
- Topic-based access controls: Enforce publish and subscribe access controls per-topic/symbol, thereby ensuring that only authorized applications publish into certain topics and only authorized application subscribe to certain data feeds. This is an entitlement mechanism to control who gets access to what data.
In terms of business benefits, decoupling enables: faster onboarding of new and alternative data sources; easier migration to the cloud using event-enabled messaging, change data capture (CDC) and WAN bandwidth optimization; and the ability to elastically scale risk calculations and adapt to new regulations with less retooling.
Converting Static Reference Data to Dynamic (synchronization and enrichment) in Financial Markets
Rationalizing event-driven architecture for reference data may seem like a tough sell because reference data is generally understood to be non-real-time. Its content does not change throughout the course of a trade. However, it is beneficial to adopt an event-driven mindset and enable events on your systems of record (such as your static reference data) to synchronize with downstream systems more efficiently.
In broad terms, reference data in financial markets provides three essential pieces of information: financial product information, entity information, and pricing information. Below is a mapping of this information to their respective event types and support systems:
| Reference Data Provides | Description | Category | Event Type | Managed By |
| Financial Product Information | Security asset type, symbolic identifiers, maturity date, etc. | Corporate Action | Static | Security Master |
| Entity Information | Counterparty information, financial institutions | Legal Entity Identifier | Static | Security Master/Entity Master |
| Pricing Information | Financial product or instrument pricing, time bound valuations | Pricing | Dynamic | Price Master |
In the above table, the names of counterparties, legal entity identifiers, and securities that take part in a transaction do not change during the trade. This is static data. Once you event-enable this type of data in the corporate data management system, it becomes dynamic. Downstream business operations solutions are reactive and can dynamically process updates from the corporate master data in a decoupled fashion. This process also lends itself extremely well to automation and CI/CD pipeline integration.
How PubSub+ Event Portal and an Event Mesh Can Help You Build a Modern Post-Trade System.
As mentioned in the section above, the static, slow changing nature of financial markets reference data has historically tied it to the static data warehouse camp. So how can sleepy reference data be made real-time?
When organizations decide to modernize their data platform, they start with liberating data from silos constrained by legacy infrastructure (ESBs, databases, tedious batch processes). They begin to think of interactions in the business environment as events, not just data. Next, they identify candidates for real-time conversion. This could be the bottleneck process of onboarding new data to the security master or tackling the issue of reconciliation because the equity business maintains a separate reference data system because the corporate master takes too long to query.
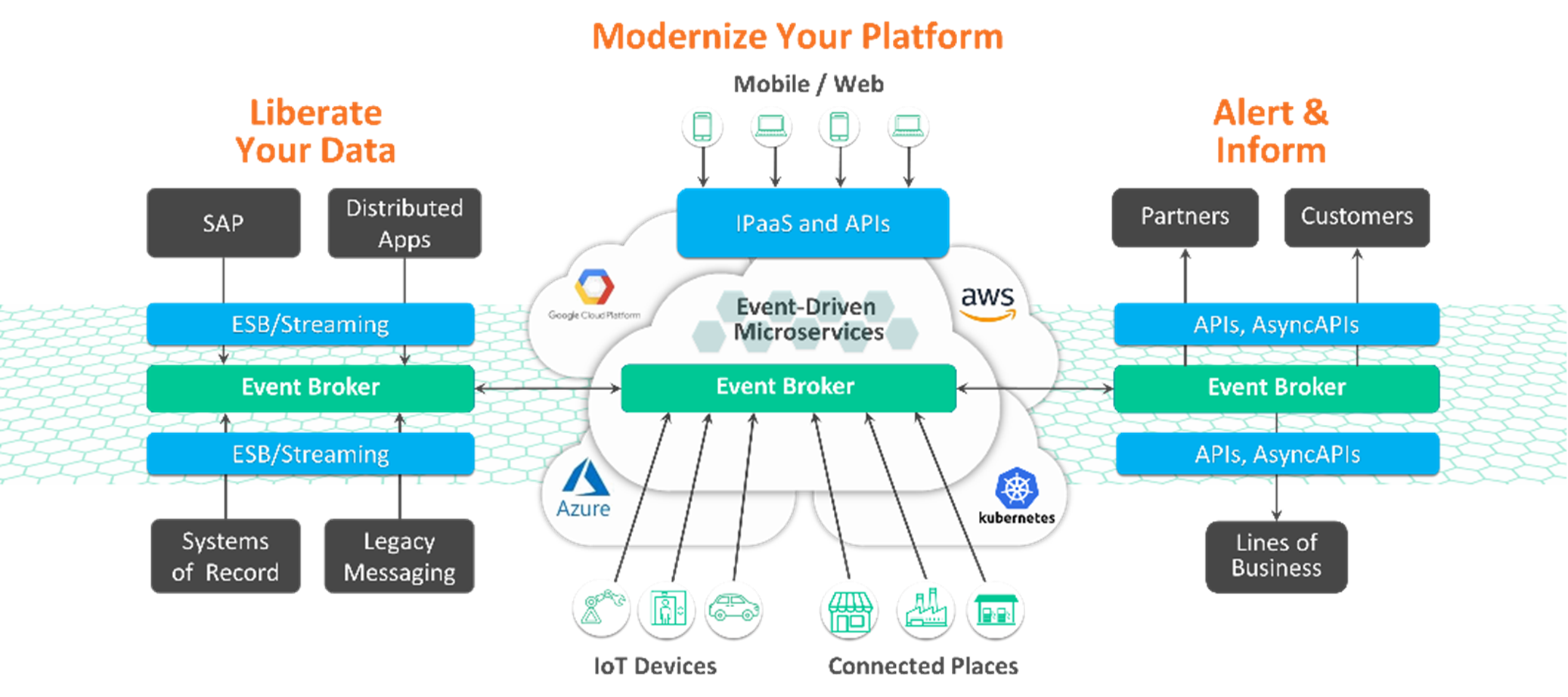
Steps to modernize the enterprise platform
Using an event streaming and management platform, like PubSub+ Platform, can deliver unmatched value to solve the growing data movement challenges in the following concrete ways:
- Event-enable static data assets and making middle and back office processes real-time
- Isolate slower middle and back office applications from market volatility
- Liberate data from silos to reduce cost and allow better discovery of data
- Extend enterprise data management governance and transparency via event-driven architecture lineage and audit trail across applications, events, and schemas – visualizing how they inter-connect and communicate via topic hierarchy and taxonomy management
- Enable fine-grained filtering and access control to help answer questions about who gets to see the data, where the data is going (through dynamic message routing), including when (queues) and how (open protocols and APIs).
As more real-time candidates are discovered, complexity inevitably begins to weigh in. Which repository will you use to track all the information you are gathering? Will you use Visio or Excel? This is where PubSub+ Event Portal (offered as part of PubSub+ Platform) can help.
PubSub+ Event Portal gives architects and developers tools to design, share, and discover events within their system, and see the relationships between applications and events. In summary, it makes event-driven applications and microservices easier to design, deploy, and evolve.
With these tools, a modern, real-time post-trade and data analytics platform can take shape!
You can map out the application domain and the events or messages applications need to exchange with each other. The diagram can be updated at any time, and each update is versioned so you can revert changes and introspect on where and why certain changes were made.

Events and payload schemas are linked to the publish and subscribe client
When you are done laying out the data flow diagram in PubSub+ Event Portal, the information can be shared with developers and data scientists. The developer can then generate code stubs using AsyncAPI templates and the data scientist can visualize data relationships throughout the organization and make better use of data for their machine learning or artificial intelligence models. PubSub+ Event Portal is a live, agile, and consistent way to visually capture and communicate applications, events, schemas, and interactions between applications via events.
The next step is to democratize the data from legacy ESB/MoM and SOA/RESTful APIs by collapsing static/batch flows in your existing data lakes and data warehouses into a real-time stream of event-driven flows. This is how you will make events discoverable anywhere in the organization.
An event mesh is formed when event brokers are connected in a network across sites, including on-premises and public/private clouds. With an event mesh, you get uniform connectivity, dynamic routing, WAN optimization, high performance, high availability, security, and governance. Clients can publish data on topics or subscribe to topics from anywhere on the event mesh. Only topics of interest will be dynamically routed from the publishing broker to the consuming one, saving bandwidth.
Below, I will provide a diagram and set of steps for a modern post-trade system with an event mesh.
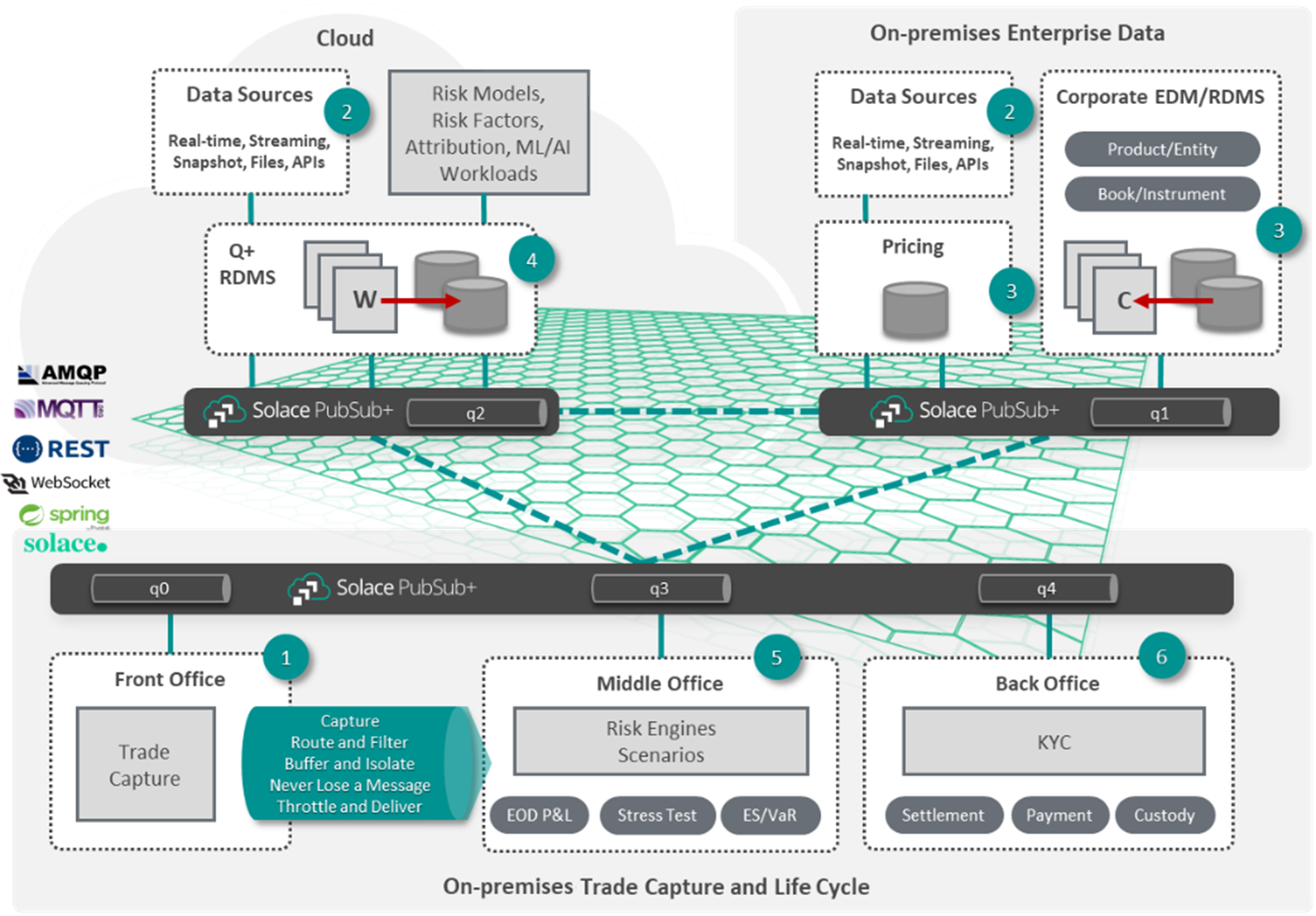
In this example,
- The front office executes trades and publishes transacted trade events on topics. It consumes real-time market data, operational reference data (Q+), and corporate-wide master data (EDM/RDMS).
- External data sources publish data on topics to brokers on-premises and in the cloud.
- Corporate enterprise data management system publishes change log events (C).
- Q+ is reactive to updates from corporate EDM/RDMS (W).
- The middle office is a firehose; it subscribes to data from most sources to perform risk calculations.
- The back office processes post-trade for settlement, payment, and custody. It takes from a variety of data sources.
- Systems that cannot afford to lose data use queues to implement eventual consistency, asynchronicity, and shock absorption from market volatility. In the image, queues are labeled from q0 to q4.
Conclusion – Reference Data in Financial Markets is a Good Place to Start
Post-trade systems need to evolve. The ongoing volatility in the market, regulatory headwinds, and the opportunity to harvest and leverage historical and real-time data can all be addressed by a modern post-trade system. A good place to start building consensus around this is by utilizing the reference data in your financial markets ecosystem. With a firm handle on the quality, governance, and real-time accessibility of this data, your business will be well set to drastically cut re-conciliation costs, reduce manpower, decrease system overheads, and ace regulatory audits.
PubSub+ Platform and PubSub+ Event Portal can be instrumental in this journey of envisioning and implementing a modern post-trade system that harnesses the power of reference data.
Related Reading:
- Blog Post: Event-Enabling Post-Trade Transaction Processing for Capital Markets
- Solution Brief: Modernize and Future-Proof Post-Trade Processing with an Event Mesh
- White Paper: How to Modernize Your Payment Processing System for Agility and Performance
- Success Stories: C3 Post Trade and Grasshopper
Explore other posts from categories: For Architects | Use Cases



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.