Recapping EDA Summit Series Webinar “Best Practices for Event Enabling your Enterprise Integration Platform”
Yesterday EDA Summit kicked off a series of free educational webinars called
EDA Summit recently held the second free educational webinar in their EDA Summit Series called “Data Mesh Meets Event Mesh” featuring Matt Aslett, VP and research director at Ventana Research as well as Jesse Menning, an architect in Solace’s office of the CTO. With this post I’ll summarize what they covered.
Matt Aslett went straight into the definition of a data mesh, as outlined by the idea’s originator Zhamek Dehghani in her forthcoming book: “Data Mesh is a sociotechnical approach to sharing, accessing and managing analytical data in complex and large-scale environments – within or across organizations.”
He then outlined the 4 main principles or defining characteristics of a data mesh:
Aslett then outlined what he saw as the main benefits of a data mesh, i.e. that it can:
Aslett then outlined some of the challenges faced when implementing a data mesh, like the need for technological and cultural evolution; data governance; the need to build a tailored solution for your specific needs; and finally, technology investments.As Zhamek Dehghani notes, effective use of data mesh requires potentially significant organizational and cultural change. It can be challenging to move from centralized control to decentralized; from a monolithic to a distributed architecture; from top-down governance to federated governance; and from treating data as an asset to data as a product.
Data mesh also requires very disciplined data governance and continual monitoring and enforcement of data quality service levels. It is important to note that governance is federated, not distributed and ideally should be codified and potentially even automated. Each business domain also needs to take data quality ownership of their own data.
Data mesh adopters may also run into challenges around strict enforcement of interoperability standards, which is required for successful adoption, as well as technology vendors pushing for a specific platform, when, by definition, data mesh is meant to be platform agnostic.
Aslett made it clear in his presentation that there is no quick fix. Data mesh is not an “off the shelf” product, so you should be concerned if any vendor claims they can provide you a complete data mesh.
One of the key considerations in adopting a data mesh is how you will provide access to the domain owned data products. There are two main approaches: push and pull.
Consider this example to explain the two approaches: Master customer data might be owned by a single department and changes to customer data can be critical to many other business functions. Ideally, any changes to customer data should be pushed in real-time to reliant consumers via something like an event mesh, but if the data is less critical or timely the data consumers can pull (or query) the data when it needs it.
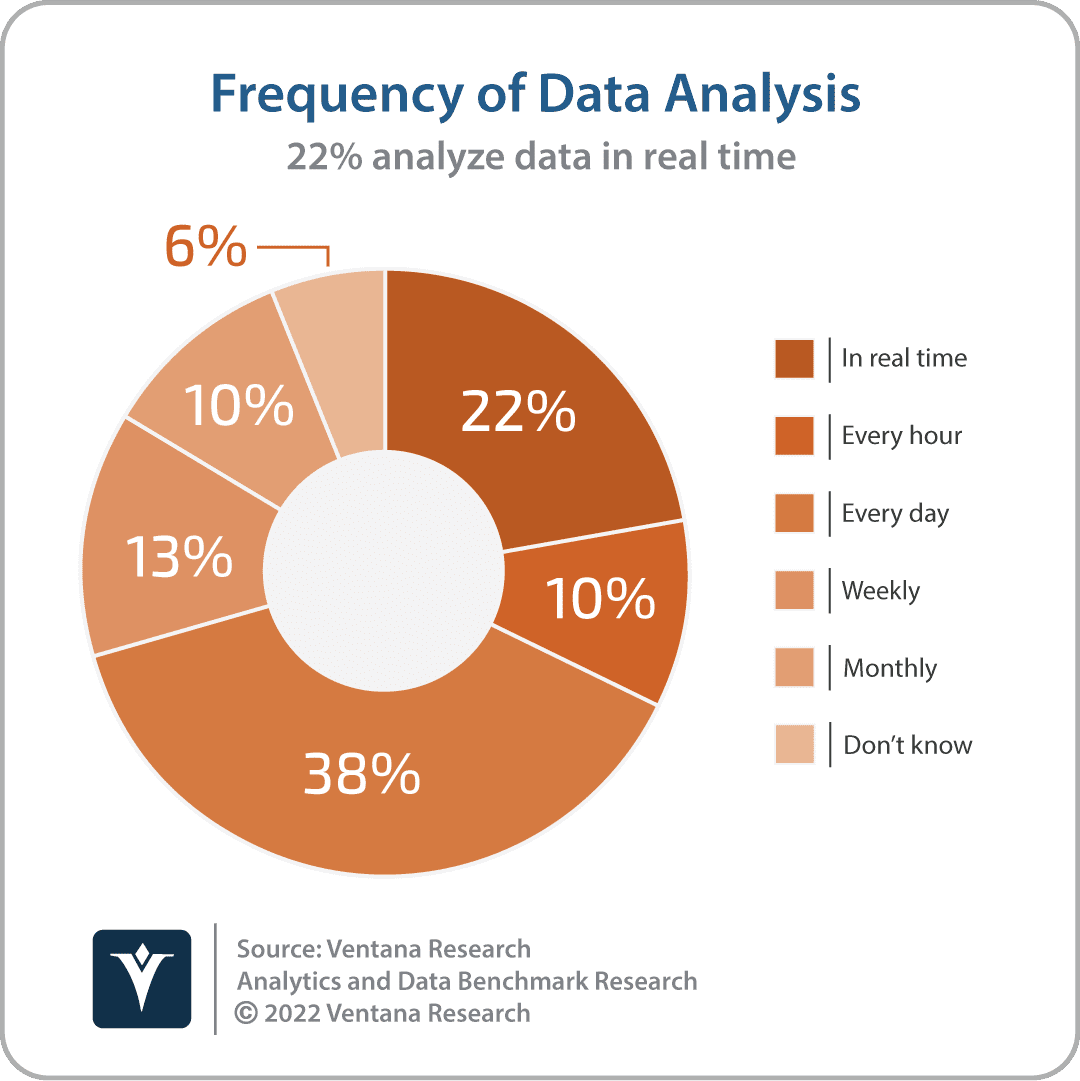
Frequency of analysis of data is one way organizations should think about this push or pull approach. Ventana’s own research shows that 22% or organizations have a requirement to analyze data in real-time.
Aslett also Dehghani as noting that, “Business facts are best presented as business domain events, and can be stored and served as distributed logs of time-stamped events for any authorized consumer to access.” Aslett believe events and event-driven architecture have significant roles to play in implementing a data mesh.
In closing, Aslett recommended considering both the business benefits and the technology requirements of data mesh and suggests that all organizations should consider the potential advantages in adopting a data mesh approach, but also be aware of the significant organizational and cultural changes that are associated with its adoption.
The EDA Summit Series session then turned to Jesse Menning, a senior architect in the office of the CTO at Solace. Menning aimed to explain what capabilities of an event-driven data mesh are mature, emerging, and are on the horizon.
For mature capabilities, he felt real-time analytics, large-scale data collection, platform agnostic connectivity, and support of open standards are all well-handled today.
For event-driven data mesh capabilities that are emerging, Menning looked to capabilities that were pioneered in the synchronous data world and should be replicated in the world of asynchronous event-driven interactions.
Lastly, Menning covered event-driven data mesh capabilities that he views as “on the horizon”, which he explains go hand-in-hand with data policies and asking oneself the question, “Can we get sued for this?”
Menning explains that if the answer is yes, an enterprise-level data policy is required, which includes features/capabilities like access control, regulations (ie. GDPR), confidentiality (like PII and PHI), redactions, and encryption.
If the answer to the question is no, then the policies can be viewed differently. Examples of capabilities might include mandatory header meta-data (contextualizing the data), observability requirements, topic structures (for routing), and data quality through schema validation and other tools.
Menning asserts that “policy-as-code” is an ideal end state for governance. You want consistent use of policies across domains, and you don’t want them to be bypassed. An emerging open-source standard called Open Policy Agent (OPA) is his recommended approach with its parallels to infrastructure-as-code.
During the webinar event, live attendees completed a survey on their use and adoption of data mesh. The results showed that data mesh is still very much an emerging concept, with only 2% of respondents currently using data mesh in production, vs 17% who have pilot implementations. Half of the respondents (48%) plan to implement data mesh in the next 1-2 years whereas 31% currently have no plans at all.
Explore other posts from category: For Architects



Subscribe to Our Blog
Get the latest trends, solutions, and insights into the event-driven future every week.