In summary, Apache Kafka’s performance comes primarily from two design choices:
- The broker does not manage consumer state, each consumer does. This reduces the load on the broker, but also results in an inability for DevOps to monitor consumer behavior, deal with the “message of death”, be sure of message delivery, provide wildcard subscriptions and requires more complexity in each client API and application.
- The Apache Kafka broker’s use of the sendfile() system call to transfer messages to consumers is key to its performance, but it can only be used when consumers receive messages exactly as they are stored to disk – transport protocol and all. As a result, sendfile() cannot be used when TLS is used (resulting in 90% performance decrease) or where backward compatibility is required or if any filtering or modification is required to messages after they are stored. In these cases Apache Kafka loses its performance advantage.
Solace PubSub+ event brokers maintain consumer state by enqueuing and dequeuing messages to/from persistent queues which provides operational benefits that Apache Kafka can’t provide; as well as the ability to deliver to consumers exactly the messages they want. PubSub+ software uses various caching, batching and journaling techniques to optimize performance on commodity hardware. PubSub+ appliances use hardware cards purpose-built for high performance I/O, persistence and replication of both messages and consumer state for high availability.
Apache Kafka Datapath Architecture
There is more detail on Apache Kafka’s approach to efficiency and their design choices in the Apache Kafka design documents. Below is a summary of the Apache Kafka architecture sufficient to explain how these decisions may be appropriate for high volume log aggregation but not for most other messaging use cases.
How does Apache Kafka achieve its high performance?
Two significant and novel aspects of Apache Kafka’s design are both its strength for log aggregation and its weakness for general purpose messaging use cases:
- Consumer state management is done by the client not by the broker.
- The broker’s datapath design for message movement and storage which relies heavily on log file storage techniques and the sendfile() system call.
State Management
With Apache Kafka, messages from publishers are appended sequentially to a log file by the Apache Kafka broker based on the topic + partition of the message – messages are not queued to consumers based on their subscriptions.
Consumers of a particular topic+partition read from this set of log files by asking the broker to play out the next bytes from a given position in the log. Each consumer is responsible for tailing log files for the partitions it is receiving and managing its own state so the broker need not manage this. The impacts are listed below:
- Non-persistent messaging is not supported since delivery to consumers is always from disk logs. This makes Apache Kafka a poor choice for latency sensitive applications.
- You cannot interleave messages from different topics into a common, ordered stream. This is what makes true wildcard subscriptions and in-publish-order delivery across topics not possible.
- DevOps cannot be alerted to consumers falling behind the flow of realtime messages since the broker is not monitoring queue depth and backlog per consumer
- You can’t easily remove the “message of death” causing a consumer to crash from just that consumer’s list of messages
- You can’t really tell if a message has been processed by all consumers. You must keep log files around for “long enough” that all messages should have been consumed while also not running out of disk space.
Message Delivery
The next efficiency is using the Linux sendfile() system call, or transferTo() in Java to send stored messages to the consumers – the efficient “tailing” of the log file.
Most messaging brokers selectively read messages from disk (when needed) into user space and then send them out via a TCP connection to the consumer. The path of a message is depicted in the following diagram:
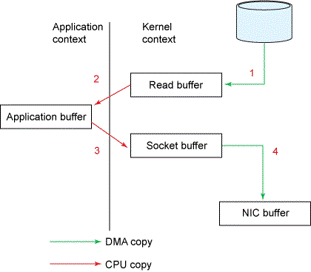
The path involves (1) reading messages from disk into the file system (2) copying data from the filesystem page cache into the application’s user space buffer (3) writing the message from user space into a TCP socket in the kernel (4) the kernel transferring the user data with TCP/IP headers to the NIC for transmission out the network. This path requires up to 4 data copies. This is the worst-case path.
Message brokers can do various things to optimize this path and reduce issues of data copies and context switching:
- the messaging system keeps its own message cache so that (1) and (2) are avoided
- the message already being in the filesystem cache (read buffer) so that (1) doesn’t happen
- batching messages at various points. There are many things message brokers do to optimize this path to reduce the issues of data copies and context switching.
With Apache Kafka, the best case scenario data path with sendfile() or transferTo() looks like this:
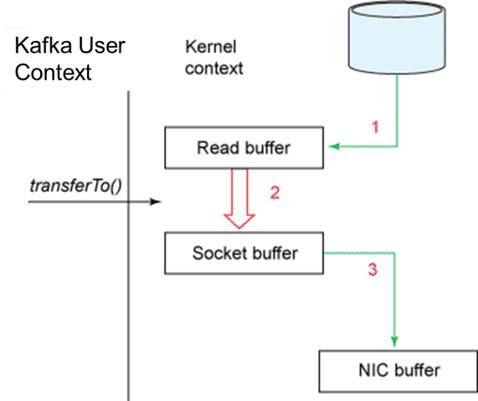
The key reason for developing transferTo(), is for web servers to efficiently send static content to web browsers: move the file as is directly from disk to a TCP socket.
With transferTo(), there is minimal data copying and minimal system calls – it is very efficient. However it also means that the Apache Kafka broker is not in the data path, so it cannot add value since messages sent to consumers must be in exactly the same format as they were sent by the publisher. If Apache Kafka needs to do anything to the stored data stream before sending it to a consumer, then it loses all of the performance advantage it gets from transferTo() and adds the inefficiencies of Scala/JVM object management to its datapath. For example:
- Using TLS for a consumer (TLS was added in Apache Kafka 0.9.0) results in a 12x CPU increase per-encrypted consumer over a non-encrypted consumer (this analysis is referenced here as part of the Apache work to assess the performance impact of TLS). This degradation is consistent with our customers’ experience of a 90% decrease in maximum throughput when TLS is enabled. This degradation is partially due to the additional CPU needed for TLS computations, but mostly because transferTo() cannot be used (the CPU increase for a publisher from non-encrypted to encrypted is only 2.5x vs 12x for a consumer). Confluent analysis show 90% CPU increase on broker by enabling TLS: https://www.slideshare.net/ConfluentInc/securing-kafka/10

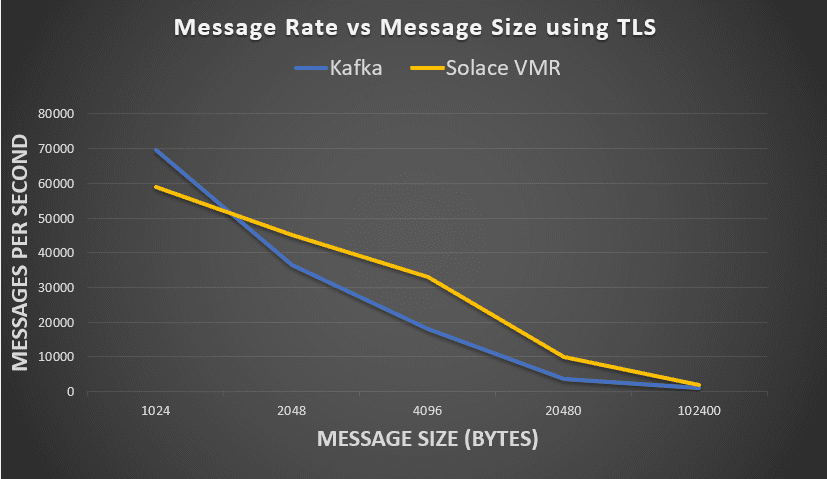
In all but the small message size use cases, Solace has better performance than Apache Kafka when TLS is enabled.

- If the publisher and consumer are not of the same version, typical in any reasonable size deployment, and changes to the stored message format/wireline are required, then transferTo() cannot be used.
- Adding messaging features such as filtering or priority or steaming compression also mean transferTo() cannot be used.

Solace PubSub+ Datapath Architecture
The Solace PubSub+ datapath architecture varies somewhat between the hardware appliance and the software version, and between persistent and non-persistent messaging. PubSub+ appliances have purpose-built cards that use FPGAs and Network Processors for high performance data movement, message and state storage. PubSub+ software uses the CPU, network and storage of its local host or attached storage as configured.
In all cases, messages arrive from a publisher, potentially with different topics, they are matched against consumer subscriptions, which may include wildcards, they are either enqueued onto a persistent queue or queued in RAM to a consumer’s connection or onto multiple queues of each type depending on whether the consumer’s subscription is a durable subscription or not. The ability to mix durable and non-durable consumers is very useful for many applications (e.g. monitoring or desktop apps using non-durable, server or database apps using durable subscriptions). Inter-message router messaging occurs in the same way: messages are enqueued to a connection or a persistent queue toward the remote message router and sent only once regardless of the number of consumers on the remote message router and without any external components.
For non-durable subscriptions, messages and consumer state are maintained in RAM within the PubSub+ message broker. For the appliance, the message never leaves the Network Acceleration Blade (NAB) and since the NAB has no operating system, the payload is never copied. It is stored in a buffer upon receipt from the hardware, referenced by queue entries in RAM for each consumer connection, then transferred via Direct Memory Access (DMA) over TCP to the consumer. If TLS encryption or streaming compression is required, the original message buffer is fed into on-chip hardware to encrypt or compress the message (with several other messages batched together) and this output is transferred via DMA over TCP to the consumer.
For durable subscriptions, both messages and consumer state are maintained in persistent storage by the Solace message router. In the software version of PubSub+, messages and delivery state are stored to disk on multiple software brokers for resiliency. Multi-threaded processing, batching of messages and state and journaling to disk are among the techniques used to maximize message storage performance. To deliver messages to consumers, the message could be retrieved from the message broker’s RAM cache, or the filesystem cache, or otherwise read from disk.
In the PubSub+ appliance, we use a specially-designed hardware card called the Assured Delivery Blade (ADB) to perform persistent storage of messages and state as well as propagation to the mate appliance without going over Ethernet. The ADB provides byte-level addressability (vs filesystem page sizes) and can transfer data at RAM speeds vs disk and filesystem speeds. This ensures extremely high rates and low consistent latency while also ensuring zero message loss. Watch this video for more information on the persistent messaging architecture of Solace appliances.
Conclusion
Solace PubSub+ offers efficient per-destination queuing for significant operational advantages and personalizes message delivery to meet the needs of each consumer. Some of the key performance advantages of Apache Kafka, namely how consumer state is managed and how messages are delivered to consumers, either produce negative trade-offs for messaging features and operational visibility or cannot be used in many cases, which then negates the performance advantage that made Apache Kafka attractive in the first place.