
Solace’s architecture integrates all capabilities into Solace PubSub+ message broker and uses lightweight APIs, whereas Apache Kafka adopts a distributed approach of having a lightweight broker, heavier APIs and different functions implemented in separate runtime components.
Below is a summary table which compares various aspects of PubSub+ and Apache Kafka. The next section provides further detail and explanation.
| Feature | Apache Kafka | Solace |
|---|---|---|
| Broker | Simple broker that takes a log file approach to storage and replay. Offers high performance for simple pub/sub, struggles to support features that require knowledge of state or changes to published message format. | Sophisticated broker aware of all publishers, subscribers, queue and message state. Broker available as hardware appliance or software – functionally equivalent. |
| Deployment Dependencies | Requires 3x (dedicated) Zookeeper to store configuration data and message state. | None. All capabilities deployed as one executable in PubSub+. |
| Replication for disaster recovery | Synchronous replication is not supported, asynch requires MirrorMaker | Built in synchronous or asynchronous DR replication at topic/queue granularity. |
| Multi-protocol support | Requires external gateways for REST, MQTT upload. Full MQTT/AMQP likely not possible due to lack of message routing capabilities. | MQTT, REST, Websockets, COMET supported by the message broker along with interoperability between them – no proxies required. |
| Inter-cluster communication | Requires another component (MirrorMaker) to move data between clusters. | Built-in via bridging and multi-node dynamic routing. |
| APIs | Proprietary, thick API makes consumer responsible for consumer state, connectivity to many brokers, finding partition leaders. | Wide variety of lightweight standard APIs (JMS, JCA) and proprietary APIs for server, web and IoT applications. All APIs supported and frequently updated by Solace. |
| Backward Compatibility | Frequent major changes limits availability of backward compatible APIs in many languages. | PubSub+ supports backward compatibility of all APIs and between Solace brokers. |
Apache Kafka Architecture
As described by its creators, “Apache Kafka is publish-subscribe messaging rethought as a distributed commit log”. This log-based design principle, described by Jay Kreps one of Apache Kafka’s creators, has guided many design choices in the Apache Kafka architecture.
A good overview of the Apache Kafka architecture can be found here. Below is a summary.
At a system level, a minimal Apache Kafka deployment involves at least 6 (3x Apache Kafka + 3x Zookeeper) to 10 (add 2x MirrorMaker and 2x REST proxies) runtime processes:
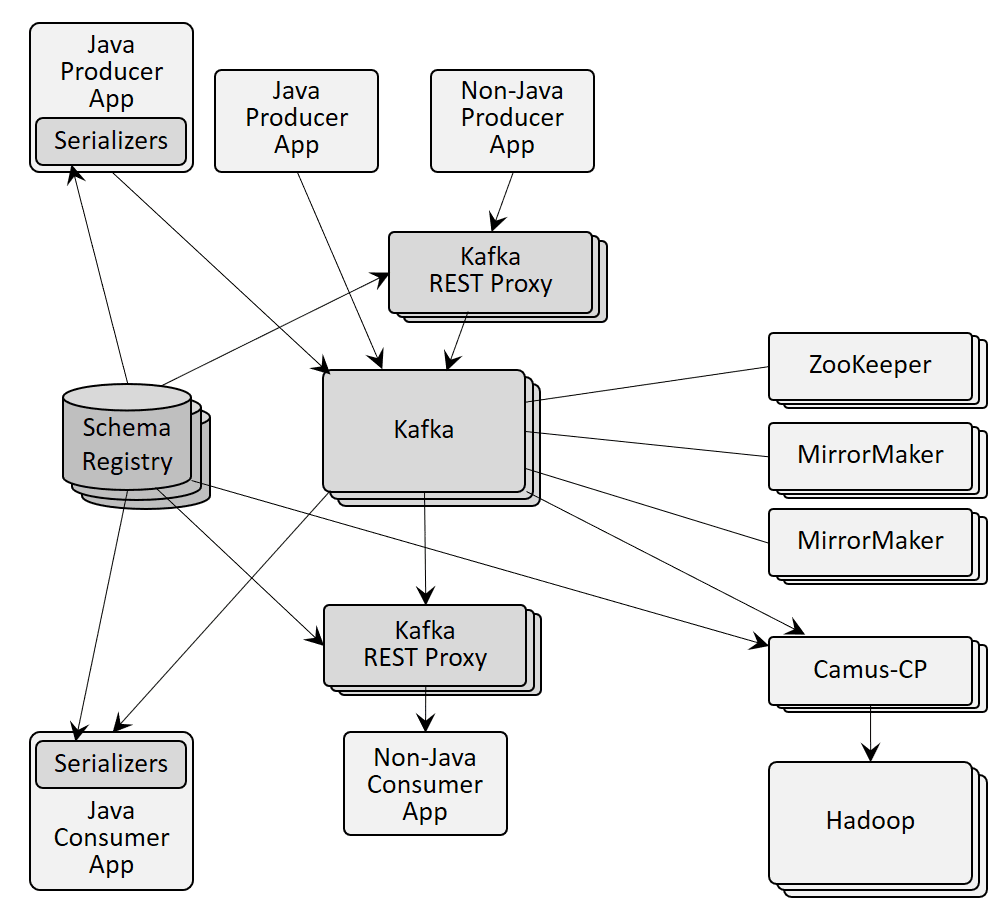
- Apache Kafka brokers – typically 3 are deployed due to the use of asynchronous writes to disk
- Zookeeper cluster – 3 Zookeeper nodes dedicated to this Apache Kafka cluster are required to store configuration and state associated with the Apache Kafka cluster
- MirrorMaker – to move data from one cluster to another such as from one datacenter to another, several MirrorMaker nodes are required. Due to the asynchronous nature of the message forwarding, MirrorMaker can’t provide synchronous replication for disaster recovery purposes. To overcome the functional and stability limitations of MirrorMaker, Confluent has introduced a proprietary licenced product called Replicator which adds features like new partition detection and infinite loop detection.
- REST Proxy –The REST Proxy often depicted with Apache Kafka converts from REST to Apache Kafka’s Java API but is not available from Apache. If you need a REST interface, you’ll need Confluent proxies or you need to build it yourself. A key reason that REST is often shown is due to the lack of APIs in other languages so REST provides an integration method all languages can use. However, in addition to deployment complexity, use of REST via a separate gateway provides poor performance for streaming data.
Drilling into applications accessing the cluster of Apache Kafka brokers looks like this:
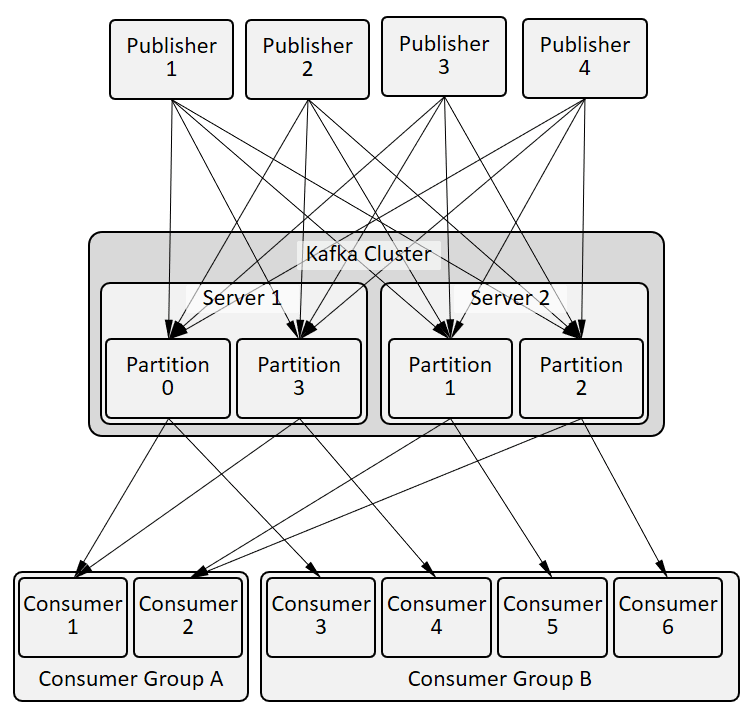
Each topic partition (P0..P3 above) is a directory of files containing the messages for that particular topic+partition. Partitions can be distributed among Apache Kafka brokers in the cluster. More topics or partitions means more directories. The system is very much a “distributed commit log” architecture:
- Messages from publishers are appended sequentially to the log files based on the (topic + partition) of the message – not based on any consumer subscription. Log files are rolled over based on size and deleted based on time or size.
- Consumers of a particular topic+partition read from this set of log files by asking the broker to play out the next bytes from a given position in the log. The consumer is responsible for remembering where it is in the log stream and which broker is leader of a partition. It’s like each consumer is actively tailing a log file.
This means publishers connect via a Apache Kafka API to all brokers hosting the topics that the publisher is publishing to which they discover via Zookeeper. On each message publish, the publishing application provides the topic, key and payload. The key is hashed to a partition within the topic and the message is sent to the broker hosting that topic + partition. A key can be, for example, a customer ID or orderID to provide partitioning but not filtering.
Consumers discover which broker is leader for which partitions and connect to the brokers for the topics/partitions they are interested in and basically “tail” the file for the topic/partition sets they want to subscribe to. Multiple instances of an application (for horizontal scaling) are grouped into a Consumer Group and different instances consume from different partitions – more on this in Message Routing, Filtering, Ordering.
With this architecture:
- The use of multiple components increases the complexity for monitoring, engineering, and upgrades due to the (minimum) 6-10 processes required – more as you scale.
- Consumers can only see message order within a subset of a topic, or within a single topic if it’s not partitioned, which means that fine-grained message routing/filtering is not possible for EDAs, post-trade distribution systems, gaming platforms.
- If you want to implement open protocols such as REST you need to deploy proxies to terminate the external protocol and connect to all the Apache Kafka brokers. Similar to what MirrorMaker must do for inter-cluster messaging.
- You can’t implement features such as message priority, filtering within a topic or synchronous replication, or at best can only do so by jumping through some serious hoops.
Solace PubSub+ Architecture
Solace PubSub+ was designed from the very beginning with three guiding principles to satisfy the many data movement needs of applications:
- Use networking concepts and technologies to provide a high performance, robust, scalable real-time data movement fabric
- Provide the features, functions, APIs application designers need so that they can focus on their application tasks rather than on the plumbing
- Provide it in an integrated simple-to-use-and-deploy form factor.
Our customers can choose from traditional software that’s deployable into many clouds and containers, unique hardware appliances, and a fully managed service called Solace PubSub+ Cloud.
Hardware appliances are deployed in pairs for high availability and scale either by adding more appliances, which is rarely required due to their performance, or by upgrading to faster cards within the same appliance.
PubSub+ message brokers are multi-threaded and implemented in C for efficiency and real-time control. PubSub+ message brokers are deployed in 3s for quorum consensus and scale vertically by adding more cores to an instance or horizontally in groups of three. Unlike Apache Kafka, we intentionally separate the concepts of high availability and horizontal scaling in order to provide a more predictable, easy to engineer system.
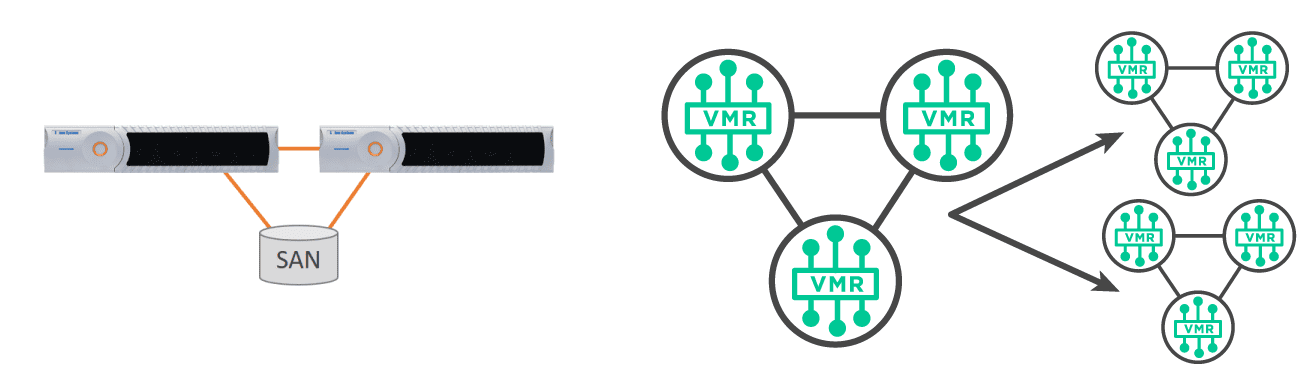
All functions such as multiple protocol support, inter-cluster communication, replication for disaster recovery, configuration replication, leader election are implemented as components in the PubSub+ message broker – not as separate runtimes.
Consumers connect to a PubSub+ message broker with whatever API or protocol they like, subscribe to the topics they want to receive (including wildcard subscriptions) and the published messages are queued to the consumer (with either persistent or non-persistent QoS), converted from the publisher’s transport and delivered to the consumer by the PubSub+ message broker. On a per client basis, TLS or compression can be used. Publishers and consumers can connect to different message routers and messages flow from publisher message router to subscriber message router based on the subscriber’s interest.
Conclusion
Solace’s integrated architecture uses fewer runtime components and provides message delivery state management in the message router whereas the Apache Kafka architecture is the opposite. The result is PubSub+ is easier to deploy, enables lighter weight clients (with heavier broker), superior DevOps visibility, and more messaging functionality than Apache Kafka.